| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Tổng quat
GPU và TPU có thể giảm đáng kể thời gian cần thiết để thực hiện một bước đào tạo duy nhất. Để đạt được hiệu suất cao nhất yêu cầu một đường dẫn đầu vào hiệu quả cung cấp dữ liệu cho bước tiếp theo trước khi bước hiện tại kết thúc. API tf.data giúp xây dựng các đường ống đầu vào linh hoạt và hiệu quả. Tài liệu này trình bày cách sử dụng API tf.data để xây dựng các đường ống đầu vào TensorFlow có hiệu suất cao.
Trước khi bạn tiếp tục, hãy xem hướng dẫn Xây dựng đường ống đầu vào TensorFlow để tìm hiểu cách sử dụng API tf.data .
Tài nguyên
- Xây dựng đường ống đầu vào TensorFlow
- API
tf.data.Dataset - Phân tích hiệu suất
tf.datavới TF Profiler
Thành lập
import tensorflow as tf
import time
Trong suốt hướng dẫn này, bạn sẽ lặp lại trên một tập dữ liệu và đo lường hiệu suất. Việc tạo ra các điểm chuẩn hiệu suất có thể tái tạo có thể khó khăn. Các yếu tố khác nhau ảnh hưởng đến khả năng tái lập bao gồm:
- Tải CPU hiện tại
- Lưu lượng mạng
- Các cơ chế phức tạp, chẳng hạn như bộ nhớ cache
Để có được một điểm chuẩn có thể tái tạo, bạn sẽ xây dựng một ví dụ nhân tạo.
Bộ dữ liệu
Bắt đầu với việc xác định một lớp kế thừa từ tf.data.Dataset được gọi là ArtificialDataset . Tập dữ liệu này:
- Tạo mẫu
num_samples(mặc định là 3) - Ngủ một lúc trước khi mục đầu tiên mô phỏng việc mở tệp
- Ngủ một lúc trước khi tạo từng mục để mô phỏng việc đọc dữ liệu từ một tệp
class ArtificialDataset(tf.data.Dataset):
def _generator(num_samples):
# Opening the file
time.sleep(0.03)
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
time.sleep(0.015)
yield (sample_idx,)
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_signature = tf.TensorSpec(shape = (1,), dtype = tf.int64),
args=(num_samples,)
)
Tập dữ liệu này tương tự như tập dữ liệu tf.data.Dataset.range , thêm độ trễ cố định ở đầu và giữa mỗi mẫu.
Vòng lặp đào tạo
Tiếp theo, viết một vòng lặp huấn luyện giả đo lường thời gian cần thiết để lặp qua một tập dữ liệu. Thời gian đào tạo được mô phỏng.
def benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
for sample in dataset:
# Performing a training step
time.sleep(0.01)
print("Execution time:", time.perf_counter() - start_time)
Tối ưu hóa hiệu suất
Để thể hiện cách tối ưu hóa hiệu suất, bạn sẽ cải thiện hiệu suất của ArtificialDataset .
Cách tiếp cận ngây thơ
Bắt đầu với một đường dẫn đơn giản không sử dụng thủ thuật, lặp lại tập dữ liệu như hiện tại.
benchmark(ArtificialDataset())
Execution time: 0.26497629899995445
Dưới đây là cách bạn đã sử dụng thời gian thực hiện:

Cốt truyện cho thấy rằng thực hiện một bước đào tạo bao gồm:
- Mở tệp nếu nó chưa được mở
- Tìm nạp một mục nhập dữ liệu từ tệp
- Sử dụng dữ liệu để đào tạo
Tuy nhiên, trong một triển khai đồng bộ ngây thơ như ở đây, trong khi đường ống của bạn đang tìm nạp dữ liệu, thì mô hình của bạn đang ở chế độ chờ. Ngược lại, trong khi mô hình của bạn đang được đào tạo, đường dẫn đầu vào sẽ không hoạt động. Do đó, thời gian của bước đào tạo là tổng thời gian mở, đọc và đào tạo.
Các phần tiếp theo xây dựng trên đường ống đầu vào này, minh họa các phương pháp hay nhất để thiết kế đường ống đầu vào TensorFlow hiệu quả.
Tìm nạp trước
Tìm nạp trước chồng chéo quá trình tiền xử lý và thực thi mô hình của một bước đào tạo. Trong khi mô hình đang thực hiện bước huấn luyện s , thì đường dẫn đầu vào đang đọc dữ liệu cho bước s+1 . Làm như vậy sẽ giảm thời gian từng bước xuống mức tối đa (trái ngược với tổng) của quá trình đào tạo và thời gian cần thiết để trích xuất dữ liệu.
API tf.data cung cấp chuyển đổi tf.data.Dataset.prefetch . Nó có thể được sử dụng để tách thời gian dữ liệu được tạo ra từ thời điểm dữ liệu được sử dụng. Đặc biệt, quá trình chuyển đổi sử dụng một chuỗi nền và một bộ đệm nội bộ để tìm nạp trước các phần tử từ tập dữ liệu đầu vào trước thời điểm chúng được yêu cầu. Số phần tử cần tìm nạp trước phải bằng (hoặc có thể lớn hơn) số lô được tiêu thụ bởi một bước đào tạo duy nhất. Bạn có thể điều chỉnh thủ công giá trị này hoặc đặt nó thành tf.data.AUTOTUNE , điều này sẽ nhắc thời gian chạy tf.data điều chỉnh giá trị động trong thời gian chạy.
Lưu ý rằng chuyển đổi tìm nạp trước mang lại lợi ích bất cứ khi nào có cơ hội trùng lặp công việc của "nhà sản xuất" với công việc của "người tiêu dùng".
benchmark(
ArtificialDataset()
.prefetch(tf.data.AUTOTUNE)
)
Execution time: 0.21731788600027357

Bây giờ, khi biểu đồ thời gian thực thi dữ liệu hiển thị, trong khi bước đào tạo đang chạy cho mẫu 0, thì đường dẫn đầu vào đang đọc dữ liệu cho mẫu 1, v.v.
Khai thác dữ liệu song song
Trong cài đặt thế giới thực, dữ liệu đầu vào có thể được lưu trữ từ xa (ví dụ: trên Google Cloud Storage hoặc HDFS). Đường dẫn tập dữ liệu hoạt động tốt khi đọc dữ liệu cục bộ có thể bị tắc nghẽn trên I / O khi đọc dữ liệu từ xa do sự khác biệt sau giữa lưu trữ cục bộ và lưu trữ từ xa:
- Time-to-first-byte : Đọc byte đầu tiên của tệp từ bộ lưu trữ từ xa có thể mất nhiều thời gian hơn so với từ bộ lưu trữ cục bộ.
- Thông lượng đọc : Mặc dù lưu trữ từ xa thường cung cấp băng thông tổng hợp lớn, nhưng việc đọc một tệp đơn lẻ có thể chỉ sử dụng được một phần nhỏ băng thông này.
Ngoài ra, khi các byte thô được tải vào bộ nhớ, cũng có thể cần giải mã hóa và / hoặc giải mã dữ liệu (ví dụ: protobuf ), việc này yêu cầu tính toán bổ sung. Chi phí này hiện hữu bất kể dữ liệu được lưu trữ cục bộ hay từ xa, nhưng có thể tồi tệ hơn trong trường hợp từ xa nếu dữ liệu không được tìm nạp trước một cách hiệu quả.
Để giảm thiểu tác động của các chi phí khai thác dữ liệu khác nhau, phép chuyển đổi tf.data.Dataset.interleave có thể được sử dụng để song song hóa bước tải dữ liệu, xen kẽ nội dung của các bộ dữ liệu khác (chẳng hạn như trình đọc tệp dữ liệu). Số lượng bộ dữ liệu chồng chéo có thể được chỉ định bằng đối số cycle_length , trong khi mức độ song song có thể được chỉ định bằng đối số num_parallel_calls . Tương tự như phép chuyển đổi prefetch , phép chuyển đổi interleave hỗ trợ tf.data.AUTOTUNE , sẽ ủy quyền quyết định về mức độ song song sẽ sử dụng cho thời gian chạy tf.data .
Xen kẽ tuần tự
Các đối số mặc định của biến đổi tf.data.Dataset.interleave làm cho nó xen kẽ các mẫu đơn từ hai tập dữ liệu một cách tuần tự.
benchmark(
tf.data.Dataset.range(2)
.interleave(lambda _: ArtificialDataset())
)
Execution time: 0.4987426460002098

Biểu đồ thời gian thực thi dữ liệu này cho phép thể hiện hành vi của phép chuyển đổi interleave , tìm nạp các mẫu thay thế từ hai tập dữ liệu có sẵn. Tuy nhiên, không có cải tiến hiệu suất nào được tham gia ở đây.
Song song xen kẽ
Bây giờ, sử dụng đối số num_parallel_calls của phép biến đổi interleave . Thao tác này tải song song nhiều bộ dữ liệu, giảm thời gian chờ đợi các tệp được mở.
benchmark(
tf.data.Dataset.range(2)
.interleave(
lambda _: ArtificialDataset(),
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.283668874000341

Lần này, như biểu đồ thời gian thực thi dữ liệu hiển thị, việc đọc hai tập dữ liệu được song song hóa, giảm thời gian xử lý dữ liệu chung.
Chuyển đổi dữ liệu song song
Khi chuẩn bị dữ liệu, các yếu tố đầu vào có thể cần được xử lý trước. Để đạt được điều này, API tf.data cung cấp phép chuyển đổi tf.data.Dataset.map , áp dụng một chức năng do người dùng xác định cho từng phần tử của tập dữ liệu đầu vào. Bởi vì các phần tử đầu vào độc lập với nhau, quá trình tiền xử lý có thể được thực hiện song song trên nhiều lõi CPU. Để thực hiện điều này, tương tự như phép biến đổi prefetch và phép biến đổi interleave , phép biến đổi map cung cấp đối số num_parallel_calls để chỉ định mức độ song song.
Việc chọn giá trị tốt nhất cho đối số num_parallel_calls phụ thuộc vào phần cứng của bạn, đặc điểm của dữ liệu đào tạo của bạn (chẳng hạn như kích thước và hình dạng của nó), chi phí của chức năng bản đồ của bạn và những xử lý khác đang diễn ra trên CPU cùng lúc. Một phương pháp đơn giản là sử dụng số lượng lõi CPU có sẵn. Tuy nhiên, đối với chuyển đổi prefetch và chuyển đổi interleave , chuyển đổi map hỗ trợ tf.data.AUTOTUNE sẽ ủy quyền quyết định về mức độ song song sẽ sử dụng cho thời gian chạy tf.data .
def mapped_function(s):
# Do some hard pre-processing
tf.py_function(lambda: time.sleep(0.03), [], ())
return s
Ánh xạ tuần tự
Bắt đầu bằng cách sử dụng phép biến đổi map không có song song làm ví dụ về đường cơ sở.
benchmark(
ArtificialDataset()
.map(mapped_function)
)
Execution time: 0.4505277170001136

Đối với cách tiếp cận đơn giản, ở đây, như cốt truyện cho thấy, thời gian dành cho các bước mở, đọc, xử lý trước (ánh xạ) và đào tạo cộng lại với nhau cho một lần lặp.
Ánh xạ song song
Bây giờ, sử dụng cùng một chức năng tiền xử lý nhưng áp dụng nó song song trên nhiều mẫu.
benchmark(
ArtificialDataset()
.map(
mapped_function,
num_parallel_calls=tf.data.AUTOTUNE
)
)
Execution time: 0.2839677860001757

Như biểu đồ dữ liệu minh họa, các bước xử lý trước chồng chéo lên nhau, giảm thời gian tổng thể cho một lần lặp.
Bộ nhớ đệm
Phép biến đổi tf.data.Dataset.cache có thể lưu vào bộ nhớ cache một tập dữ liệu, trong bộ nhớ hoặc trên bộ nhớ cục bộ. Điều này sẽ tiết kiệm một số hoạt động (như mở tệp và đọc dữ liệu) khỏi được thực thi trong mỗi kỷ nguyên.
benchmark(
ArtificialDataset()
.map( # Apply time consuming operations before cache
mapped_function
).cache(
),
5
)
Execution time: 0.3848854380003104

Ở đây, biểu đồ thời gian thực thi dữ liệu cho thấy rằng khi bạn lưu vào bộ nhớ cache một tập dữ liệu, các chuyển đổi trước tập dữ liệu trong cache (như mở tệp và đọc dữ liệu) chỉ được thực thi trong kỷ nguyên đầu tiên. Các kỷ nguyên tiếp theo sẽ sử dụng lại dữ liệu được lưu trong bộ nhớ cache bằng cách chuyển đổi cache .
Nếu hàm do người dùng xác định được truyền vào quá trình chuyển đổi map là tốn kém, hãy áp dụng chuyển đổi cache sau khi chuyển đổi map miễn là tập dữ liệu kết quả vẫn có thể vừa với bộ nhớ hoặc bộ nhớ cục bộ. Nếu chức năng do người dùng xác định làm tăng không gian cần thiết để lưu trữ tập dữ liệu vượt quá dung lượng bộ đệm, hãy áp dụng nó sau khi chuyển đổi cache hoặc xem xét xử lý trước dữ liệu của bạn trước công việc đào tạo để giảm mức sử dụng tài nguyên.
Lập bản đồ véc tơ hóa
Việc gọi một chức năng do người dùng xác định được chuyển vào chuyển đổi map có chi phí liên quan đến việc lập lịch và thực thi chức năng do người dùng xác định. Vectơ hóa chức năng do người dùng xác định (nghĩa là để nó hoạt động trên một loạt đầu vào cùng một lúc) và áp dụng chuyển đổi batch trước khi chuyển đổi map .
Để minh họa cho thực tiễn tốt này, tập dữ liệu nhân tạo của bạn không phù hợp. Độ trễ lập lịch là khoảng 10 micro giây (10e-6 giây), ít hơn nhiều so với hàng chục mili giây được sử dụng trong ArtificialDataset , và do đó khó có thể nhìn thấy tác động của nó.
Đối với ví dụ này, hãy sử dụng hàm tf.data.Dataset.range cơ sở và đơn giản hóa vòng lặp huấn luyện thành dạng đơn giản nhất.
fast_dataset = tf.data.Dataset.range(10000)
def fast_benchmark(dataset, num_epochs=2):
start_time = time.perf_counter()
for _ in tf.data.Dataset.range(num_epochs):
for _ in dataset:
pass
tf.print("Execution time:", time.perf_counter() - start_time)
def increment(x):
return x+1
Ánh xạ vô hướng
fast_benchmark(
fast_dataset
# Apply function one item at a time
.map(increment)
# Batch
.batch(256)
)
Execution time: 0.2712608739998359

Biểu đồ trên minh họa những gì đang diễn ra (với ít mẫu hơn) bằng cách sử dụng phương pháp ánh xạ vô hướng. Nó cho thấy rằng chức năng được ánh xạ được áp dụng cho mỗi mẫu. Mặc dù chức năng này rất nhanh, nhưng nó có một số chi phí ảnh hưởng đến hiệu suất thời gian.
Ánh xạ vector
fast_benchmark(
fast_dataset
.batch(256)
# Apply function on a batch of items
# The tf.Tensor.__add__ method already handle batches
.map(increment)
)
Execution time: 0.02737950600021577

Lần này, hàm được ánh xạ được gọi một lần và áp dụng cho một lô mẫu. Khi biểu đồ thời gian thực thi dữ liệu hiển thị, trong khi hàm có thể mất nhiều thời gian hơn để thực thi, chi phí chỉ xuất hiện một lần, cải thiện hiệu suất thời gian tổng thể.
Giảm dấu chân bộ nhớ
Một số phép biến đổi, bao gồm interleave , prefetch và shuffle , duy trì bộ đệm bên trong của các phần tử. Nếu hàm do người dùng định nghĩa được truyền vào phép biến đổi map làm thay đổi kích thước của các phần tử, thì thứ tự của phép biến đổi bản đồ và các phép biến đổi mà các phần tử đệm ảnh hưởng đến việc sử dụng bộ nhớ. Nói chung, hãy chọn thứ tự dẫn đến dung lượng bộ nhớ thấp hơn, trừ khi thứ tự khác nhau là mong muốn cho hiệu suất.
Lưu vào bộ đệm các tính toán từng phần
Bạn nên lưu vào bộ nhớ cache tập dữ liệu sau khi chuyển đổi map , ngoại trừ trường hợp chuyển đổi này làm cho dữ liệu quá lớn để vừa trong bộ nhớ. Có thể đạt được sự cân bằng nếu chức năng được ánh xạ của bạn có thể được chia thành hai phần: một phần tốn thời gian và một phần tốn bộ nhớ. Trong trường hợp này, bạn có thể xâu chuỗi các phép biến đổi của mình như sau:
dataset.map(time_consuming_mapping).cache().map(memory_consuming_mapping)
Bằng cách này, phần tốn thời gian chỉ được thực thi trong kỷ nguyên đầu tiên và bạn tránh sử dụng quá nhiều dung lượng bộ nhớ cache.
Tóm tắt phương pháp hay nhất
Dưới đây là tóm tắt về các phương pháp hay nhất để thiết kế đường ống đầu vào TensorFlow hiệu quả:
- Sử dụng chuyển đổi
prefetchđể chồng chéo công việc của người sản xuất và người tiêu dùng - Song song chuyển đổi đọc dữ liệu bằng cách sử dụng chuyển đổi
interleave - Song song hóa chuyển đổi
mapbằng cách đặt đối sốnum_parallel_calls - Sử dụng chuyển đổi
cachenhớ cache để lưu dữ liệu vào bộ nhớ đệm trong kỷ nguyên đầu tiên - Vectơ hóa các chức năng do người dùng xác định được chuyển vào chuyển đổi
map - Giảm mức sử dụng bộ nhớ khi áp dụng các chuyển đổi
interleave,prefetchvàshuffle
Sao chép các số liệu
Để hiểu sâu hơn về tf.data.Dataset API, bạn có thể sử dụng các đường ống dẫn của riêng mình. Dưới đây là mã được sử dụng để vẽ các hình ảnh từ hướng dẫn này. Nó có thể là một điểm khởi đầu tốt, cho thấy một số cách giải quyết cho những khó khăn chung như:
- Khả năng tái tạo thời gian thực thi
- Các hàm được ánh xạ háo hức thực thi
- chuyển đổi
interleavecó thể gọi
import itertools
from collections import defaultdict
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
Bộ dữ liệu
Tương tự như ArtificialDataset , bạn có thể xây dựng một tập dữ liệu trả về thời gian dành cho mỗi bước.
class TimeMeasuredDataset(tf.data.Dataset):
# OUTPUT: (steps, timings, counters)
OUTPUT_TYPES = (tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32)
OUTPUT_SHAPES = ((2, 1), (2, 2), (2, 3))
_INSTANCES_COUNTER = itertools.count() # Number of datasets generated
_EPOCHS_COUNTER = defaultdict(itertools.count) # Number of epochs done for each dataset
def _generator(instance_idx, num_samples):
epoch_idx = next(TimeMeasuredDataset._EPOCHS_COUNTER[instance_idx])
# Opening the file
open_enter = time.perf_counter()
time.sleep(0.03)
open_elapsed = time.perf_counter() - open_enter
for sample_idx in range(num_samples):
# Reading data (line, record) from the file
read_enter = time.perf_counter()
time.sleep(0.015)
read_elapsed = time.perf_counter() - read_enter
yield (
[("Open",), ("Read",)],
[(open_enter, open_elapsed), (read_enter, read_elapsed)],
[(instance_idx, epoch_idx, -1), (instance_idx, epoch_idx, sample_idx)]
)
open_enter, open_elapsed = -1., -1. # Negative values will be filtered
def __new__(cls, num_samples=3):
return tf.data.Dataset.from_generator(
cls._generator,
output_types=cls.OUTPUT_TYPES,
output_shapes=cls.OUTPUT_SHAPES,
args=(next(cls._INSTANCES_COUNTER), num_samples)
)
Tập dữ liệu này cung cấp các mẫu hình dạng [[2, 1], [2, 2], [2, 3]] và kiểu [tf.dtypes.string, tf.dtypes.float32, tf.dtypes.int32] . Mỗi mẫu là:
(
[("Open"), ("Read")],
[(t0, d), (t0, d)],
[(i, e, -1), (i, e, s)]
)
Ở đâu:
-
OpenvàReadlà số nhận dạng các bước -
t0là dấu thời gian khi bước tương ứng bắt đầu -
dlà thời gian dành cho bước tương ứng -
ilà chỉ mục cá thể -
elà chỉ số kỷ nguyên (số lần tập dữ liệu đã được lặp lại) -
slà chỉ số mẫu
Vòng lặp lặp lại
Làm cho vòng lặp phức tạp hơn một chút để tổng hợp tất cả các thời gian. Điều này sẽ chỉ hoạt động với các tập dữ liệu tạo mẫu như đã nêu chi tiết ở trên.
def timelined_benchmark(dataset, num_epochs=2):
# Initialize accumulators
steps_acc = tf.zeros([0, 1], dtype=tf.dtypes.string)
times_acc = tf.zeros([0, 2], dtype=tf.dtypes.float32)
values_acc = tf.zeros([0, 3], dtype=tf.dtypes.int32)
start_time = time.perf_counter()
for epoch_num in range(num_epochs):
epoch_enter = time.perf_counter()
for (steps, times, values) in dataset:
# Record dataset preparation informations
steps_acc = tf.concat((steps_acc, steps), axis=0)
times_acc = tf.concat((times_acc, times), axis=0)
values_acc = tf.concat((values_acc, values), axis=0)
# Simulate training time
train_enter = time.perf_counter()
time.sleep(0.01)
train_elapsed = time.perf_counter() - train_enter
# Record training informations
steps_acc = tf.concat((steps_acc, [["Train"]]), axis=0)
times_acc = tf.concat((times_acc, [(train_enter, train_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [values[-1]]), axis=0)
epoch_elapsed = time.perf_counter() - epoch_enter
# Record epoch informations
steps_acc = tf.concat((steps_acc, [["Epoch"]]), axis=0)
times_acc = tf.concat((times_acc, [(epoch_enter, epoch_elapsed)]), axis=0)
values_acc = tf.concat((values_acc, [[-1, epoch_num, -1]]), axis=0)
time.sleep(0.001)
tf.print("Execution time:", time.perf_counter() - start_time)
return {"steps": steps_acc, "times": times_acc, "values": values_acc}
Phương pháp lập kế hoạch
Cuối cùng, xác định một hàm có thể vẽ một dòng thời gian với các giá trị được trả về bởi hàm timelined_benchmark .
def draw_timeline(timeline, title, width=0.5, annotate=False, save=False):
# Remove invalid entries (negative times, or empty steps) from the timelines
invalid_mask = np.logical_and(timeline['times'] > 0, timeline['steps'] != b'')[:,0]
steps = timeline['steps'][invalid_mask].numpy()
times = timeline['times'][invalid_mask].numpy()
values = timeline['values'][invalid_mask].numpy()
# Get a set of different steps, ordered by the first time they are encountered
step_ids, indices = np.stack(np.unique(steps, return_index=True))
step_ids = step_ids[np.argsort(indices)]
# Shift the starting time to 0 and compute the maximal time value
min_time = times[:,0].min()
times[:,0] = (times[:,0] - min_time)
end = max(width, (times[:,0]+times[:,1]).max() + 0.01)
cmap = mpl.cm.get_cmap("plasma")
plt.close()
fig, axs = plt.subplots(len(step_ids), sharex=True, gridspec_kw={'hspace': 0})
fig.suptitle(title)
fig.set_size_inches(17.0, len(step_ids))
plt.xlim(-0.01, end)
for i, step in enumerate(step_ids):
step_name = step.decode()
ax = axs[i]
ax.set_ylabel(step_name)
ax.set_ylim(0, 1)
ax.set_yticks([])
ax.set_xlabel("time (s)")
ax.set_xticklabels([])
ax.grid(which="both", axis="x", color="k", linestyle=":")
# Get timings and annotation for the given step
entries_mask = np.squeeze(steps==step)
serie = np.unique(times[entries_mask], axis=0)
annotations = values[entries_mask]
ax.broken_barh(serie, (0, 1), color=cmap(i / len(step_ids)), linewidth=1, alpha=0.66)
if annotate:
for j, (start, width) in enumerate(serie):
annotation = "\n".join([f"{l}: {v}" for l,v in zip(("i", "e", "s"), annotations[j])])
ax.text(start + 0.001 + (0.001 * (j % 2)), 0.55 - (0.1 * (j % 2)), annotation,
horizontalalignment='left', verticalalignment='center')
if save:
plt.savefig(title.lower().translate(str.maketrans(" ", "_")) + ".svg")
Sử dụng trình bao bọc cho chức năng được ánh xạ
Để chạy hàm được ánh xạ trong một ngữ cảnh háo hức, bạn phải bọc chúng bên trong một lệnh gọi tf.py_function .
def map_decorator(func):
def wrapper(steps, times, values):
# Use a tf.py_function to prevent auto-graph from compiling the method
return tf.py_function(
func,
inp=(steps, times, values),
Tout=(steps.dtype, times.dtype, values.dtype)
)
return wrapper
So sánh đường ống
_batch_map_num_items = 50
def dataset_generator_fun(*args):
return TimeMeasuredDataset(num_samples=_batch_map_num_items)
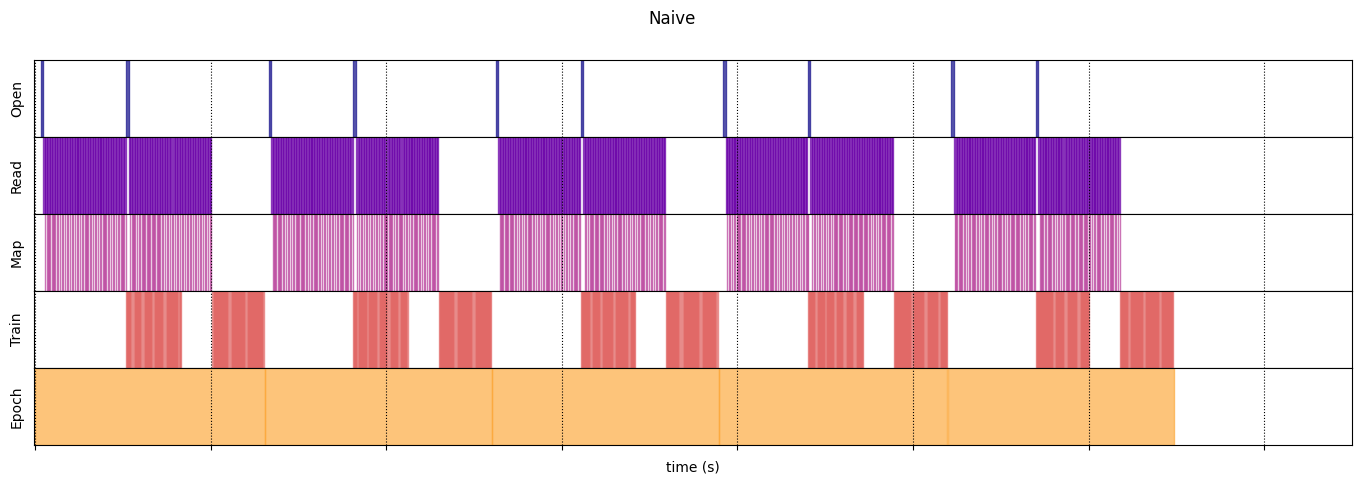
Ngây thơ
@map_decorator
def naive_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001) # Time consuming step
time.sleep(0.0001) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, [["Map"]]), axis=0),
tf.concat((times, [[map_enter, map_elapsed]]), axis=0),
tf.concat((values, [values[-1]]), axis=0)
)
naive_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.flat_map(dataset_generator_fun)
.map(naive_map)
.batch(_batch_map_num_items, drop_remainder=True)
.unbatch(),
5
)
WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_types is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead WARNING:tensorflow:From /tmp/ipykernel_23983/64197174.py:36: calling DatasetV2.from_generator (from tensorflow.python.data.ops.dataset_ops) with output_shapes is deprecated and will be removed in a future version. Instructions for updating: Use output_signature instead Execution time: 13.13538893499981
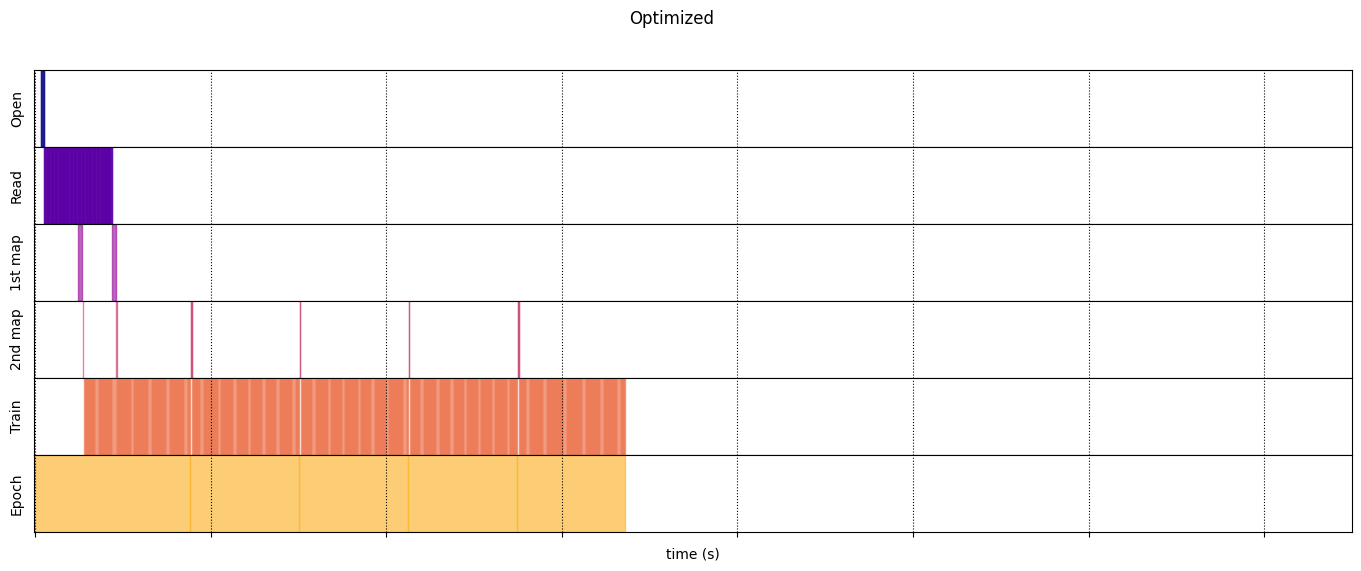
Tối ưu hóa
@map_decorator
def time_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.001 * values.shape[0]) # Time consuming step
map_elapsed = time.perf_counter() - map_enter
return (
tf.concat((steps, tf.tile([[["1st map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
@map_decorator
def memory_consuming_map(steps, times, values):
map_enter = time.perf_counter()
time.sleep(0.0001 * values.shape[0]) # Memory consuming step
map_elapsed = time.perf_counter() - map_enter
# Use tf.tile to handle batch dimension
return (
tf.concat((steps, tf.tile([[["2nd map"]]], [steps.shape[0], 1, 1])), axis=1),
tf.concat((times, tf.tile([[[map_enter, map_elapsed]]], [times.shape[0], 1, 1])), axis=1),
tf.concat((values, tf.tile([[values[:][-1][0]]], [values.shape[0], 1, 1])), axis=1)
)
optimized_timeline = timelined_benchmark(
tf.data.Dataset.range(2)
.interleave( # Parallelize data reading
dataset_generator_fun,
num_parallel_calls=tf.data.AUTOTUNE
)
.batch( # Vectorize your mapped function
_batch_map_num_items,
drop_remainder=True)
.map( # Parallelize map transformation
time_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.cache() # Cache data
.map( # Reduce memory usage
memory_consuming_map,
num_parallel_calls=tf.data.AUTOTUNE
)
.prefetch( # Overlap producer and consumer works
tf.data.AUTOTUNE
)
.unbatch(),
5
)
Execution time: 6.723691489999965
draw_timeline(naive_timeline, "Naive", 15)
draw_timeline(optimized_timeline, "Optimized", 15)