
На этой странице перечислен набор известных руководств и инструментов, решающих проблемы в текстовой области с помощью TensorFlow Hub. Это отправная точка для всех, кто хочет решать типичные проблемы машинного обучения, используя предварительно обученные компоненты машинного обучения, а не начинать с нуля.
Классификация
Когда мы хотим спрогнозировать класс для данного примера, например настроения , токсичности , категории статьи или любой другой характеристики.

В приведенных ниже уроках одна и та же задача решается с разных точек зрения и с использованием разных инструментов.
Керас
Классификация текста с помощью Keras — пример создания классификатора настроений IMDB с использованием Keras и наборов данных TensorFlow.
Оценщик
Классификация текста — пример создания классификатора настроений IMDB с помощью Estimator. Содержит несколько советов по улучшению и раздел сравнения модулей.
БЕРТ
Прогнозирование настроений в обзорах фильмов с помощью BERT на TF Hub — показано, как использовать модуль BERT для классификации. Включает использование библиотеки bert для токенизации и предварительной обработки.
Каггл
Классификация IMDB на Kaggle — показывает, как легко взаимодействовать с соревнованиями Kaggle из Colab, включая загрузку данных и отправку результатов.
| Оценщик | Керас | ТФ2 | Наборы данных ТФ | БЕРТ | API-интерфейсы Kaggle | |
|---|---|---|---|---|---|---|
| Классификация текста | ||||||
| Классификация текста с помощью Keras | ||||||
| Прогнозирование настроений в обзорах фильмов с помощью BERT на TF Hub | ||||||
| Классификация IMDB на Kaggle |
Задача Bangla с встраиваниями FastText
TensorFlow Hub в настоящее время предлагает модуль не на каждом языке. В следующем руководстве показано, как использовать TensorFlow Hub для быстрого экспериментирования и модульной разработки машинного обучения.
Классификатор статей Bangla — демонстрирует, как создать многократно используемое встраивание текста в TensorFlow Hub и использовать его для обучения классификатора Keras для набора данных BARD Bangla Article .
Семантическое сходство
Когда мы хотим выяснить, какие предложения коррелируют друг с другом при нулевой настройке (без обучающих примеров).
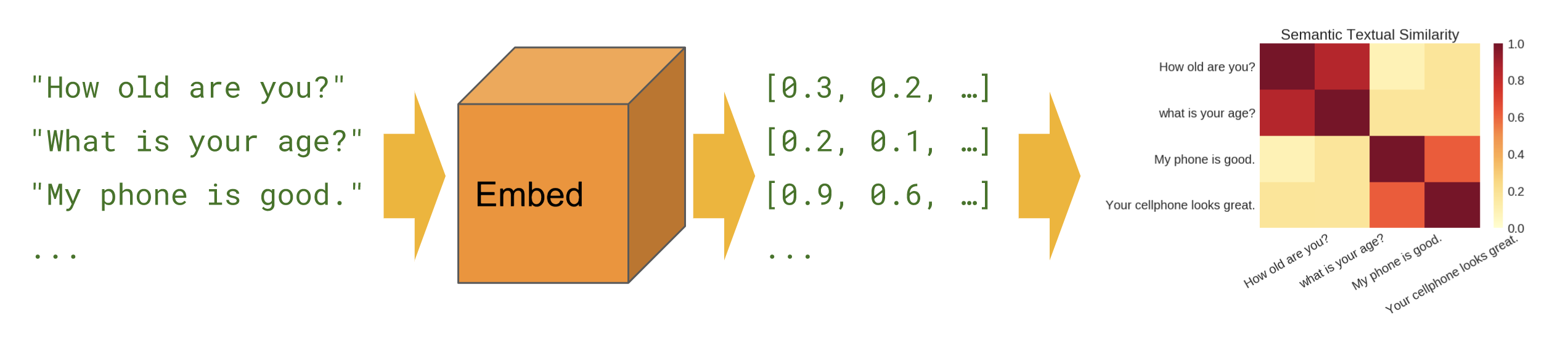
Базовый
Семантическое сходство — показывает, как использовать модуль кодировщика предложений для вычисления сходства предложений.
межязычный
Межъязыковое семантическое сходство — показывает, как использовать один из межъязыковых кодировщиков предложений для вычисления сходства предложений на разных языках.
Семантический поиск
Семантический поиск — показывает, как использовать кодировщик предложений вопросов и ответов для индексации коллекции документов для поиска на основе семантического сходства.
Ввод фрагмента предложения
Семантическое сходство с универсальным кодировщиком Lite — показывает, как использовать модули кодировщика предложений, которые принимают на входе идентификаторы SentencePiece вместо текста.
Создание модуля
Вместо использования только модулей на tfhub.dev есть способы создания собственных модулей. Это может быть полезным инструментом для улучшения модульности кодовой базы машинного обучения и дальнейшего обмена информацией.
Обертывание существующих предварительно обученных вложений
Экспортер модулей встраивания текста — инструмент для переноса существующего предварительно обученного встраивания в модуль. Показывает, как включить в модуль операции предварительной обработки текста. Это позволяет создать модуль внедрения предложений из вложений токенов.
Модуль экспорта модуля встраивания текста v2 — то же, что и выше, но совместим с TensorFlow 2 и обеспечивает быстрое выполнение.