
本页面列出了一组使用 TensorFlow Hub 解决文本领域问题的已知指南和工具。如果您不想从头开始,而是使用预训练的 ML 组件来解决典型的 ML 问题,则本文是一个很好的起点。
分类
为给定样本(例如情感、毒性、文章类别或任何其他特征)预测其所属的类。

下面的教程将从不同的角度并使用不同的工具来完成相同的任务。
Keras
使用 Keras 进行文本分类 - 使用 Keras 和 TensorFlow 数据集构建 IMDB 情感分类器的示例。
Estimator
文本分类 - 使用 Estimator 构建 IMDB 情感分类器的示例。包含多个改进提示和模块比较部分。
BERT
使用 TF Hub 上的 BERT 预测电影评论情感 - 展示如何使用 BERT 模块进行分类。包括使用 bert 库进行分词和预处理。
Kaggle
Kaggle 上的 IMDB 分类 - 演示如何在 Colab 中与 Kaggle 竞赛轻松交互,包括下载数据和提交结果。
| Estimator | Keras | TF2 | TF Datasets | BERT | Kaggle API | |
|---|---|---|---|---|---|---|
| 文本分类 | ||||||
| 使用 Keras 进行文本分类 | ||||||
| 使用 TF Hub 上的 BERT 预测电影评论情感 | ||||||
| Kaggle 上的 IMDB 分类 |
使用 FastText 嵌入向量的孟加拉语任务
TensorFlow Hub 提供的模块目前不支持所有语言。下面的教程展示了利用 TensorFlow Hub 进行快速试验和模块化 ML 开发的方法。
孟加拉语文章分类器 - 演示如何创建可重用的 TensorFlow Hub 文本嵌入向量,以及如何用它为 BARD 孟加拉语文章数据集训练 Keras 分类器。
语义相似度
在零样本设置(无训练样本)中找出哪些句子之间具有相关性。
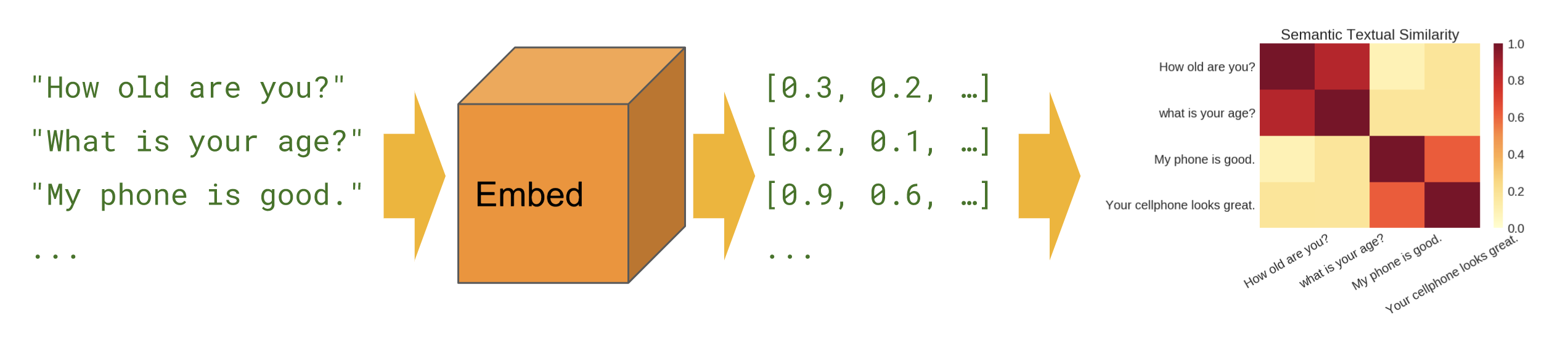
基础
语义相似度 - 展示如何使用句子编码器模块计算句子相似度。
跨语言
跨语言语义相似度 - 展示如何使用其中一种跨语言句子编码器跨语言计算句子相似度。
语义检索
语义检索 - 展示如何使用问答句子编码器为文档集合建立索引,以基于语义相似度进行检索。
SentencePiece 输入
使用通用编码器 Lite 计算语义相似度 - 展示如何在输入而非文本上使用接受 SentencePiece ID 的句子编码器模块。
模块创建
除了仅使用 tfhub.dev 上的模块外,您还可以创建自己的模块。这对提高 ML 代码库的模块化程度和进一步共享来说非常有用。
封装现有的预训练嵌入向量
文本嵌入向量模块导出程序 - 一种将现有的预训练嵌入向量封装到模块中的工具。展示在模块中包括文本预处理运算的方法。您可以通过这种方式从词例嵌入向量创建句子嵌入向量模块。
文本嵌入向量模块导出程序 v2 - 与上面的导出程序相同,但兼容 TensorFlow 2 和 Eager Execution。