
यह पृष्ठ TensorFlow हब के साथ टेक्स्ट डोमेन में समस्याओं को हल करने के लिए ज्ञात गाइड और टूल का एक सेट सूचीबद्ध करता है। यह उन लोगों के लिए एक शुरुआती जगह है जो शुरुआत से शुरू करने के बजाय पूर्व-प्रशिक्षित एमएल घटकों का उपयोग करके विशिष्ट एमएल समस्याओं को हल करना चाहते हैं।
वर्गीकरण
जब हम किसी दिए गए उदाहरण के लिए किसी वर्ग की भविष्यवाणी करना चाहते हैं, उदाहरण के लिए भावना , विषाक्तता , लेख श्रेणी , या कोई अन्य विशेषता।

नीचे दिए गए ट्यूटोरियल एक ही कार्य को विभिन्न दृष्टिकोणों से और विभिन्न टूल का उपयोग करके हल कर रहे हैं।
केरस
केरास के साथ पाठ वर्गीकरण - केरास और टेन्सरफ्लो डेटासेट के साथ आईएमडीबी भावना क्लासिफायरियर बनाने का उदाहरण।
क़ीमत लगानेवाला
पाठ वर्गीकरण - एस्टिमेटर के साथ IMDB भावना क्लासिफायरियर बनाने का उदाहरण। इसमें सुधार के लिए कई युक्तियाँ और एक मॉड्यूल तुलना अनुभाग शामिल है।
बर्ट
टीएफ हब पर बीईआरटी के साथ मूवी समीक्षा भावना की भविष्यवाणी - वर्गीकरण के लिए बीईआरटी मॉड्यूल का उपयोग करने का तरीका दिखाता है। टोकनाइजेशन और प्रीप्रोसेसिंग के लिए bert लाइब्रेरी का उपयोग शामिल है।
कागल
कागल पर आईएमडीबी वर्गीकरण - दिखाता है कि कोलाब से कागल प्रतियोगिता के साथ आसानी से कैसे बातचीत की जाए, जिसमें डेटा डाउनलोड करना और परिणाम सबमिट करना शामिल है।
| क़ीमत लगानेवाला | केरस | TF2 | टीएफ डेटासेट | बर्ट | कागल एपीआई | |
|---|---|---|---|---|---|---|
| पाठ वर्गीकरण | ||||||
| केरस के साथ पाठ वर्गीकरण | ||||||
| टीएफ हब पर बीईआरटी के साथ मूवी समीक्षा भावना की भविष्यवाणी करना | ||||||
| कागल पर आईएमडीबी वर्गीकरण |
फास्टटेक्स्ट एम्बेडिंग के साथ बांग्ला कार्य
TensorFlow हब वर्तमान में हर भाषा में एक मॉड्यूल पेश नहीं करता है। निम्नलिखित ट्यूटोरियल दिखाता है कि तेज़ प्रयोग और मॉड्यूलर एमएल विकास के लिए टेन्सरफ़्लो हब का लाभ कैसे उठाया जाए।
बांग्ला आर्टिकल क्लासिफायर - दर्शाता है कि एक पुन: प्रयोज्य टेन्सरफ्लो हब टेक्स्ट एम्बेडिंग कैसे बनाई जाए, और इसका उपयोग बार्ड बांग्ला आर्टिकल डेटासेट के लिए केरस क्लासिफायर को प्रशिक्षित करने के लिए किया जाए।
शब्दार्थ समानता
जब हम यह पता लगाना चाहते हैं कि शून्य-शॉट सेटअप (कोई प्रशिक्षण उदाहरण नहीं) में कौन से वाक्य एक-दूसरे से संबंधित हैं।
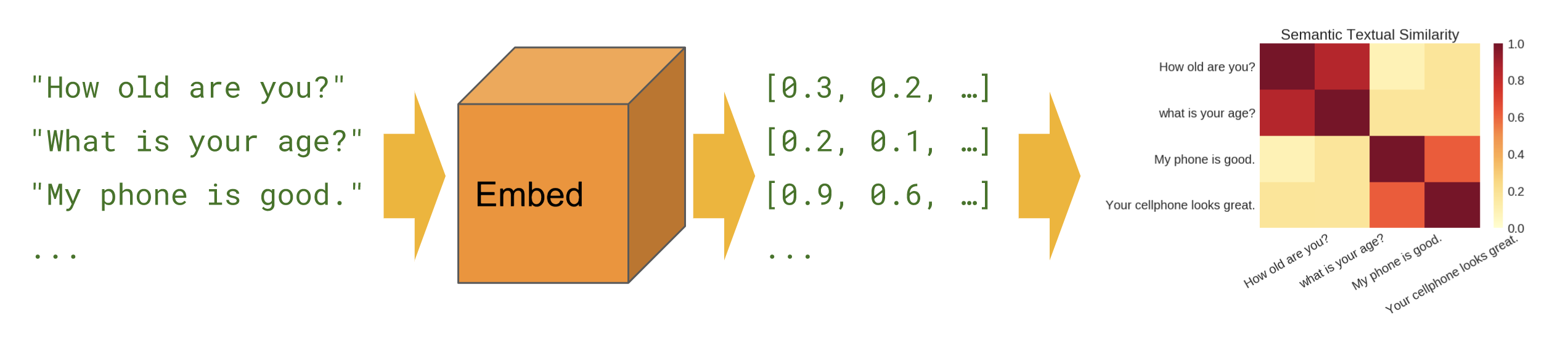
बुनियादी
सिमेंटिक समानता - दिखाता है कि वाक्य समानता की गणना करने के लिए वाक्य एनकोडर मॉड्यूल का उपयोग कैसे करें।
क्रॉस बहुभाषी
क्रॉस-लिंगुअल सिमेंटिक समानता - दिखाता है कि भाषाओं में वाक्य समानता की गणना करने के लिए क्रॉस-लिंगुअल वाक्य एन्कोडर्स में से एक का उपयोग कैसे करें।
शब्दार्थ पुनर्प्राप्ति
सिमेंटिक पुनर्प्राप्ति - दिखाता है कि सिमेंटिक समानता के आधार पर पुनर्प्राप्ति के लिए दस्तावेजों के संग्रह को अनुक्रमित करने के लिए क्यू/ए वाक्य एनकोडर का उपयोग कैसे करें।
सेंटेंसपीस इनपुट
यूनिवर्सल एनकोडर लाइट के साथ सिमेंटिक समानता - दिखाता है कि वाक्य एनकोडर मॉड्यूल का उपयोग कैसे करें जो टेक्स्ट के बजाय इनपुट पर सेंटेंसपीस आईडी स्वीकार करते हैं।
मॉड्यूल निर्माण
tfhub.dev पर केवल मॉड्यूल का उपयोग करने के बजाय, स्वयं मॉड्यूल बनाने के तरीके हैं। यह बेहतर एमएल कोडबेस मॉड्यूलैरिटी और आगे साझाकरण के लिए एक उपयोगी उपकरण हो सकता है।
मौजूदा पूर्व-प्रशिक्षित एम्बेडिंग को लपेटना
टेक्स्ट एम्बेडिंग मॉड्यूल निर्यातक - मौजूदा पूर्व-प्रशिक्षित एम्बेडिंग को मॉड्यूल में लपेटने का एक उपकरण। दिखाता है कि मॉड्यूल में टेक्स्ट प्री-प्रोसेसिंग ऑप्स को कैसे शामिल किया जाए। यह टोकन एम्बेडिंग से एक वाक्य एम्बेडिंग मॉड्यूल बनाने की अनुमति देता है।
टेक्स्ट एम्बेडिंग मॉड्यूल निर्यातक v2 - ऊपर के समान, लेकिन TensorFlow 2 और उत्सुक निष्पादन के साथ संगत।