
Questa pagina elenca una serie di guide e strumenti noti per la risoluzione dei problemi nel dominio del testo con TensorFlow Hub. È un punto di partenza per chiunque desideri risolvere i tipici problemi di ML utilizzando componenti ML pre-addestrati anziché iniziare da zero.
Classificazione
Quando vogliamo prevedere una classe per un dato esempio, ad esempio sentiment , tossicità , categoria di articoli o qualsiasi altra caratteristica.

I tutorial seguenti risolvono lo stesso compito da diverse prospettive e utilizzando strumenti diversi.
Keras
Classificazione del testo con Keras : esempio per creare un classificatore di sentiment IMDB con Keras e TensorFlow Dataset.
Estimatore
Classificazione del testo : esempio per creare un classificatore di sentiment IMDB con Estimator. Contiene numerosi suggerimenti per il miglioramento e una sezione di confronto dei moduli.
BERT
Previsione del sentiment delle recensioni di film con BERT su TF Hub : mostra come utilizzare un modulo BERT per la classificazione. Include l'uso della libreria bert per la tokenizzazione e la preelaborazione.
Kaggle
Classificazione IMDB su Kaggle : mostra come interagire facilmente con una competizione Kaggle da un Colab, incluso il download dei dati e l'invio dei risultati.
| Estimatore | Keras | TF2 | Set di dati TF | BERT | API Kaggle | |
|---|---|---|---|---|---|---|
| Classificazione del testo | ||||||
| Classificazione del testo con Keras | ||||||
| Previsione del sentiment delle recensioni di film con BERT su TF Hub | ||||||
| Classificazione IMDB su Kaggle |
Attività Bangla con incorporamenti FastText
TensorFlow Hub attualmente non offre un modulo in ogni lingua. Il tutorial seguente mostra come sfruttare TensorFlow Hub per una sperimentazione rapida e uno sviluppo ML modulare.
Bangla Article Classifier : mostra come creare un incorporamento di testo TensorFlow Hub riutilizzabile e utilizzarlo per addestrare un classificatore Keras per il set di dati BARD Bangla Article .
Somiglianza semantica
Quando vogliamo scoprire quali frasi sono correlate tra loro nella configurazione zero-shot (nessun esempio di formazione).
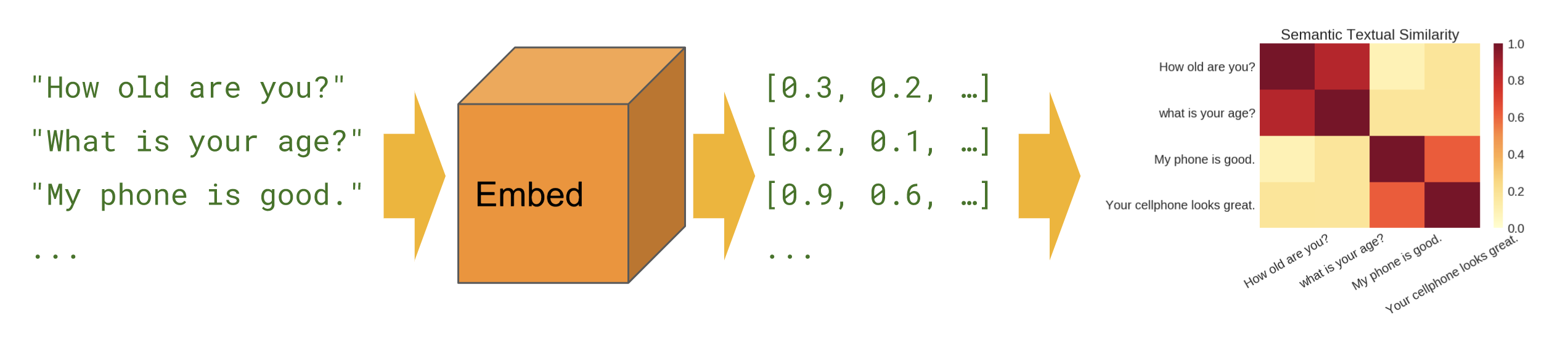
Di base
Somiglianza semantica : mostra come utilizzare il modulo di codifica delle frasi per calcolare la somiglianza delle frasi.
Multilingue
Somiglianza semantica interlinguistica : mostra come utilizzare uno dei codificatori di frasi interlinguistiche per calcolare la somiglianza delle frasi tra le lingue.
Recupero semantico
Recupero semantico : mostra come utilizzare il codificatore di frasi di domande/risposte per indicizzare una raccolta di documenti per il recupero in base alla somiglianza semantica.
Ingresso del pezzo di frase
Somiglianza semantica con Universal Encoder Lite : mostra come utilizzare i moduli di codifica delle frasi che accettano ID SentencePiece in input anziché nel testo.
Creazione del modulo
Invece di utilizzare solo i moduli su tfhub.dev , ci sono modi per creare i propri moduli. Questo può essere uno strumento utile per una migliore modularità della base di codice ML e per un'ulteriore condivisione.
Wrapping degli incorporamenti pre-addestrati esistenti
Esportatore di moduli di incorporamento del testo : uno strumento per racchiudere un incorporamento pre-addestrato esistente in un modulo. Mostra come includere operazioni di pre-elaborazione del testo nel modulo. Ciò consente di creare un modulo di incorporamento di frasi dagli incorporamenti di token.
Esportatore di moduli di incorporamento testo v2 : come sopra, ma compatibile con TensorFlow 2 ed esecuzione entusiasta.