
این صفحه مجموعه ای از راهنماها و ابزارهای شناخته شده را برای حل مسائل در حوزه متن با TensorFlow Hub فهرست می کند. این یک مکان شروع برای هر کسی است که می خواهد مشکلات معمولی ML را با استفاده از اجزای ML از پیش آموزش دیده حل کند نه از ابتدا.
طبقه بندی
وقتی میخواهیم یک کلاس را برای مثالی پیشبینی کنیم، مثلاً احساس ، سمیت ، دسته مقاله یا هر مشخصه دیگری.

آموزش های زیر یک کار را از دیدگاه های مختلف و با استفاده از ابزارهای مختلف حل می کنند.
کراس
طبقهبندی متن با Keras - مثالی برای ساخت طبقهبندی کننده احساسات IMDB با مجموعه دادههای Keras و TensorFlow.
برآوردگر
طبقه بندی متن - نمونه ای برای ساخت طبقه بندی کننده احساسات IMDB با برآوردگر. شامل نکات متعدد برای بهبود و یک بخش مقایسه ماژول.
برت
پیش بینی احساسات بازبینی فیلم با BERT در TF Hub - نحوه استفاده از ماژول BERT را برای طبقه بندی نشان می دهد. شامل استفاده از کتابخانه bert برای توکن سازی و پیش پردازش است.
کاگل
طبقه بندی IMDB در Kaggle - نشان می دهد که چگونه می توان به راحتی با یک مسابقه Kaggle از یک Colab تعامل کرد، از جمله دانلود داده ها و ارسال نتایج.
| برآوردگر | کراس | TF2 | مجموعه داده های TF | برت | API های Kaggle | |
|---|---|---|---|---|---|---|
| طبقه بندی متن | ||||||
| طبقه بندی متن با کراس | ||||||
| پیش بینی احساسات نقد فیلم با BERT در TF Hub | ||||||
| طبقه بندی IMDB در Kaggle |
کار Bangla با جاسازی های FastText
TensorFlow Hub در حال حاضر ماژول را به هر زبانی ارائه نمی دهد. آموزش زیر نشان می دهد که چگونه از TensorFlow Hub برای آزمایش سریع و توسعه ML مدولار استفاده کنید.
Bangla Article Classifier - نحوه ایجاد یک جاسازی متنی قابل استفاده مجدد TensorFlow Hub و استفاده از آن برای آموزش یک طبقه بندی Keras برای مجموعه داده مقاله BARD Bangla را نشان می دهد.
شباهت معنایی
وقتی میخواهیم بفهمیم کدام جملات در تنظیم صفر شات با یکدیگر مرتبط هستند (بدون مثال آموزشی).
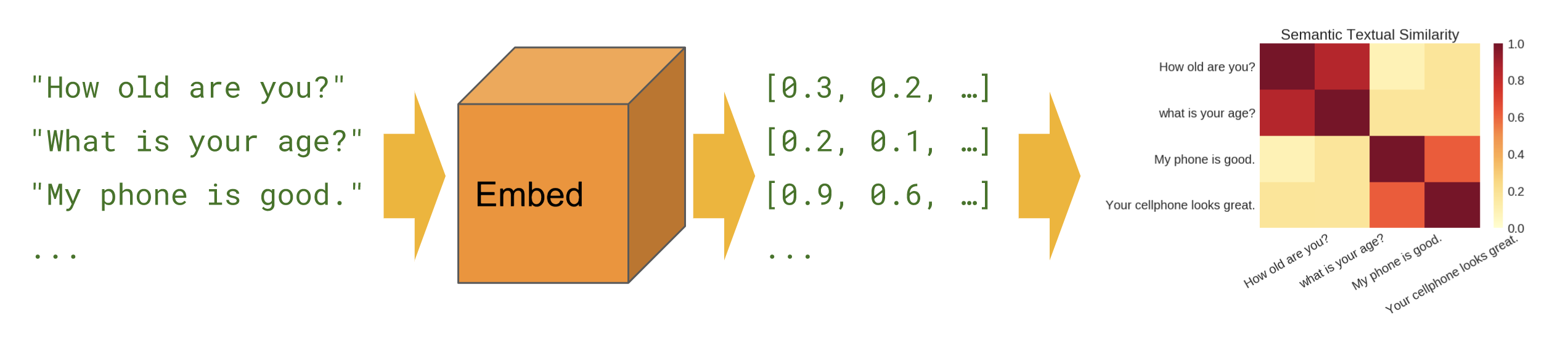
پایه ای
تشابه معنایی - نحوه استفاده از ماژول رمزگذار جملات را برای محاسبه شباهت جمله نشان می دهد.
چند زبانه
شباهت معنایی بین زبانی - نشان می دهد که چگونه می توان از یکی از رمزگذارهای جملات متقابل زبانی برای محاسبه شباهت جمله در بین زبان ها استفاده کرد.
بازیابی معنایی
بازیابی معنایی - نحوه استفاده از رمزگذار جمله Q/A برای نمایه سازی مجموعه ای از اسناد برای بازیابی بر اساس شباهت معنایی را نشان می دهد.
ورودی SentencePiece
شباهت معنایی با رمزگذار جهانی لایت - نحوه استفاده از ماژول های رمزگذار جملات را نشان می دهد که شناسه های SentencePiece را در ورودی به جای متن می پذیرند.
ایجاد ماژول
به جای استفاده از ماژولها در tfhub.dev ، راههایی برای ایجاد ماژولهای شخصی وجود دارد. این میتواند ابزار مفیدی برای ماژولار بودن بهتر پایگاه کد ML و اشتراکگذاری بیشتر باشد.
بسته بندی جاسازی های از پیش آموزش دیده موجود
صادرکننده ماژول جاسازی متن - ابزاری برای قرار دادن یک جاسازی از پیش آموزش دیده موجود در یک ماژول. نحوه گنجاندن عملیات پیش پردازش متن در ماژول را نشان می دهد. این اجازه می دهد تا یک ماژول جاسازی جمله از جاسازی های نشانه ایجاد کنید.
صادرکننده ماژول جاسازی متن v2 - مانند بالا، اما با TensorFlow 2 و اجرای مشتاق سازگار است.