
এই পৃষ্ঠাটি TensorFlow Hub-এর সাথে টেক্সট ডোমেনে সমস্যা সমাধানের জন্য পরিচিত গাইড এবং টুলের একটি সেট তালিকাভুক্ত করে। এটি এমন যেকোন ব্যক্তির জন্য একটি সূচনা স্থান যা স্ক্র্যাচ থেকে শুরু করার পরিবর্তে প্রাক-প্রশিক্ষিত ML উপাদানগুলি ব্যবহার করে সাধারণ ML সমস্যাগুলি সমাধান করতে চায়৷
শ্রেণীবিভাগ
যখন আমরা একটি প্রদত্ত উদাহরণের জন্য একটি শ্রেণির ভবিষ্যদ্বাণী করতে চাই, উদাহরণস্বরূপ অনুভূতি , বিষাক্ততা , নিবন্ধ বিভাগ বা অন্য কোনো বৈশিষ্ট্য।

নীচের টিউটোরিয়ালগুলি বিভিন্ন দৃষ্টিকোণ থেকে এবং বিভিন্ন সরঞ্জাম ব্যবহার করে একই কাজ সমাধান করছে।
কেরাস
কেরাসের সাথে পাঠ্য শ্রেণিবিন্যাস - কেরাস এবং টেনসরফ্লো ডেটাসেটের সাথে একটি IMDB সেন্টিমেন্ট ক্লাসিফায়ার তৈরির উদাহরণ।
অনুমানকারী
টেক্সট শ্রেণীবিভাগ - এস্টিমেটরের সাথে একটি IMDB সেন্টিমেন্ট ক্লাসিফায়ার তৈরির উদাহরণ। উন্নতির জন্য একাধিক টিপস এবং একটি মডিউল তুলনা বিভাগ রয়েছে৷
BERT
টিএফ হাব-এ BERT-এর সাথে মুভি রিভিউ সেন্টিমেন্টের পূর্বাভাস - শ্রেণিবিন্যাসের জন্য কীভাবে একটি BERT মডিউল ব্যবহার করতে হয় তা দেখায়। টোকেনাইজেশন এবং প্রিপ্রসেসিংয়ের জন্য bert লাইব্রেরির ব্যবহার অন্তর্ভুক্ত।
কাগল
Kaggle-এ IMDB শ্রেণীবিভাগ - ডেটা ডাউনলোড এবং ফলাফল জমা সহ একটি Colab থেকে Kaggle প্রতিযোগিতার সাথে কীভাবে সহজেই ইন্টারঅ্যাক্ট করতে হয় তা দেখায়।
| অনুমানকারী | কেরাস | TF2 | TF ডেটাসেট | BERT | Kaggle APIs | |
|---|---|---|---|---|---|---|
| পাঠ্য শ্রেণিবিন্যাস | ||||||
| কেরাসের সাথে পাঠ্য শ্রেণিবিন্যাস | ||||||
| TF হাবে BERT-এর সাথে মুভি রিভিউ সেন্টিমেন্টের পূর্বাভাস | ||||||
| Kaggle উপর IMDB শ্রেণীবিভাগ |
ফাস্টটেক্সট এম্বেডিংয়ের সাথে বাংলা কাজ
TensorFlow Hub বর্তমানে প্রতিটি ভাষায় একটি মডিউল অফার করে না। নিম্নলিখিত টিউটোরিয়ালটি দেখায় কিভাবে দ্রুত পরীক্ষা-নিরীক্ষা এবং মডুলার এমএল বিকাশের জন্য টেনসরফ্লো হাব ব্যবহার করতে হয়।
বাংলা আর্টিকেল ক্লাসিফায়ার - কীভাবে একটি পুনঃব্যবহারযোগ্য টেনসরফ্লো হাব টেক্সট এম্বেডিং তৈরি করতে হয় এবং BARD বাংলা আর্টিকেল ডেটাসেটের জন্য কেরাস ক্লাসিফায়ারকে প্রশিক্ষণ দিতে এটি ব্যবহার করে তা প্রদর্শন করে।
শব্দার্থগত মিল
যখন আমরা শূন্য-শট সেটআপে কোন বাক্যগুলি একে অপরের সাথে সম্পর্কযুক্ত তা খুঁজে বের করতে চাই (কোন প্রশিক্ষণের উদাহরণ নেই)।
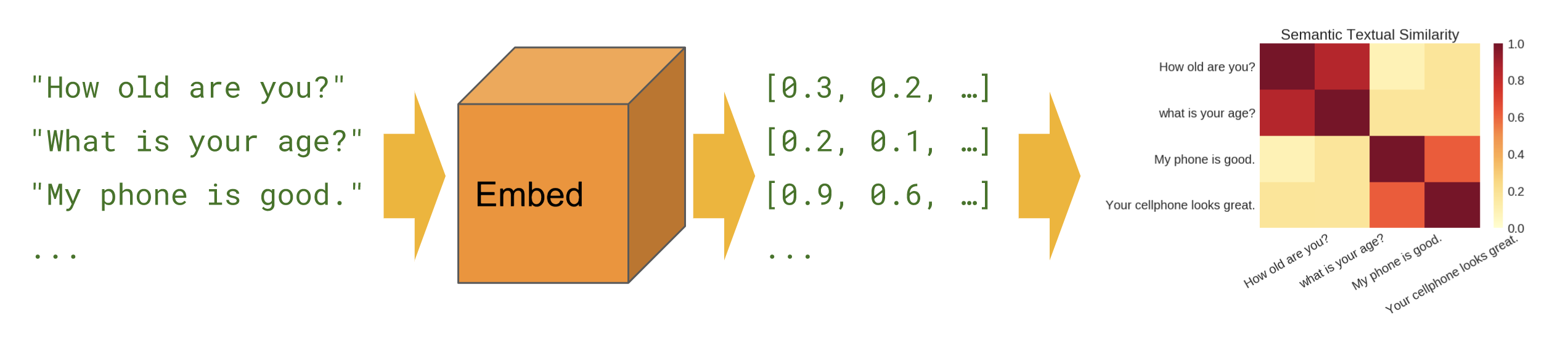
মৌলিক
শব্দার্থগত সাদৃশ্য - বাক্যের সাদৃশ্য গণনা করতে বাক্য এনকোডার মডিউলটি কীভাবে ব্যবহার করতে হয় তা দেখায়।
আন্তঃভাষিক
ক্রস-লিঙ্গুয়াল সিমান্টিক সাদৃশ্য - দেখায় কিভাবে ভাষা জুড়ে বাক্যের সাদৃশ্য গণনা করতে ক্রস-লিঙ্গুয়াল বাক্যের এনকোডারগুলির একটি ব্যবহার করতে হয়।
শব্দার্থিক পুনরুদ্ধার
শব্দার্থক পুনরুদ্ধার - শব্দার্থগত সাদৃশ্যের উপর ভিত্তি করে পুনরুদ্ধারের জন্য নথির একটি সংগ্রহকে সূচী করতে Q/A বাক্য এনকোডার কীভাবে ব্যবহার করতে হয় তা দেখায়।
সেন্টেন্সপিস ইনপুট
ইউনিভার্সাল এনকোডার লাইটের সাথে শব্দার্থিক সাদৃশ্য - কীভাবে বাক্য এনকোডার মডিউল ব্যবহার করতে হয় যা পাঠ্যের পরিবর্তে ইনপুটে সেন্টেন্সপিস আইডি গ্রহণ করে।
মডিউল তৈরি
tfhub.dev- এ শুধুমাত্র মডিউল ব্যবহার করার পরিবর্তে, নিজস্ব মডিউল তৈরি করার উপায় রয়েছে। এটি আরও ভাল ML কোডবেস মডুলারিটি এবং আরও ভাগ করার জন্য একটি দরকারী টুল হতে পারে।
বিদ্যমান প্রাক-প্রশিক্ষিত এম্বেডিংগুলি মোড়ানো
টেক্সট এম্বেডিং মডিউল রপ্তানিকারক - একটি মডিউলে একটি বিদ্যমান প্রাক-প্রশিক্ষিত এমবেডিং মোড়ানোর একটি টুল। মডিউলে টেক্সট প্রাক-প্রসেসিং অপ্স কিভাবে অন্তর্ভুক্ত করতে হয় তা দেখায়। এটি টোকেন এম্বেডিং থেকে একটি বাক্য এমবেডিং মডিউল তৈরি করতে দেয়।
টেক্সট এম্বেডিং মডিউল রপ্তানিকারক v2 - উপরের মতই, কিন্তু TensorFlow 2 এবং আগ্রহী সম্পাদনের সাথে সামঞ্জস্যপূর্ণ।