
Selección del modelo bayesiano
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Importaciones
import numpy as np
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
from tensorflow_probability import distributions as tfd
from matplotlib import pylab as plt
%matplotlib inline
import scipy.stats
Tarea: detección de puntos de cambio con múltiples puntos de cambio
Considere una tarea de detección de punto de cambio: los eventos ocurren a una velocidad que cambia con el tiempo, impulsados por cambios repentinos en el estado (no observado) de algún sistema o proceso que genera los datos.
Por ejemplo, podríamos observar una serie de recuentos como el siguiente:
true_rates = [40, 3, 20, 50]
true_durations = [10, 20, 5, 35]
observed_counts = tf.concat(
[tfd.Poisson(rate).sample(num_steps)
for (rate, num_steps) in zip(true_rates, true_durations)], axis=0)
plt.plot(observed_counts)
[<matplotlib.lines.Line2D at 0x7f7589bdae10>]
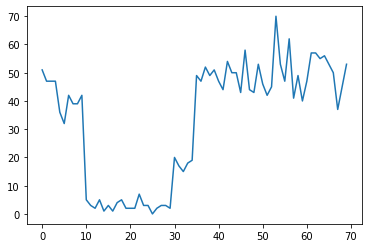
Estos podrían representar la cantidad de fallas en un centro de datos, la cantidad de visitantes a una página web, la cantidad de paquetes en un enlace de red, etc.
Tenga en cuenta que no es del todo evidente cuántos regímenes de sistemas distintos existen con solo mirar los datos. ¿Puedes decir dónde ocurre cada uno de los tres puntos de conmutación?
Número conocido de estados
Primero consideraremos el caso (quizás poco realista) en el que el número de estados no observados se conoce a priori. Aquí, supondríamos que sabemos que hay cuatro estados latentes.
Modelamos este problema como un proceso de Poisson de conmutación (no homogénea): en cada punto en el tiempo, el número de eventos que se producen es la distribución de Poisson, y la tasa de eventos se determina por el estado del sistema no observada \(z_t\):
\[x_t \sim \text{Poisson}(\lambda_{z_t})\]
Los estados latentes son discretos: \(z_t \in \{1, 2, 3, 4\}\), por lo \(\lambda = [\lambda_1, \lambda_2, \lambda_3, \lambda_4]\) es un vector simple que contiene una tasa de Poisson para cada estado. Para modelar la evolución de los estados con el tiempo, vamos a definir un modelo simple de transición \(p(z_t | z_{t-1})\): digamos que a cada paso nos quedamos en el estado anterior con alguna probabilidad \(p\), y con probabilidad \(1-p\) que la transición a una diferente estado uniformemente al azar. El estado inicial también se elige de manera uniforme al azar, por lo que tenemos:
\[ \begin{align*} z_1 &\sim \text{Categorical}\left(\left\{\frac{1}{4}, \frac{1}{4}, \frac{1}{4}, \frac{1}{4}\right\}\right)\\ z_t | z_{t-1} &\sim \text{Categorical}\left(\left\{\begin{array}{cc}p & \text{if } z_t = z_{t-1} \\ \frac{1-p}{4-1} & \text{otherwise}\end{array}\right\}\right) \end{align*}\]
Estos supuestos corresponden a un modelo de Markov oculto con las emisiones de Poisson. Podemos codificarlos en la PTF utilizando tfd.HiddenMarkovModel . Primero, definimos la matriz de transición y el uniforme previo en el estado inicial:
num_states = 4
initial_state_logits = tf.zeros([num_states]) # uniform distribution
daily_change_prob = 0.05
transition_probs = tf.fill([num_states, num_states],
daily_change_prob / (num_states - 1))
transition_probs = tf.linalg.set_diag(transition_probs,
tf.fill([num_states],
1 - daily_change_prob))
print("Initial state logits:\n{}".format(initial_state_logits))
print("Transition matrix:\n{}".format(transition_probs))
Initial state logits: [0. 0. 0. 0.] Transition matrix: [[0.95 0.01666667 0.01666667 0.01666667] [0.01666667 0.95 0.01666667 0.01666667] [0.01666667 0.01666667 0.95 0.01666667] [0.01666667 0.01666667 0.01666667 0.95 ]]
A continuación, vamos a construir un tfd.HiddenMarkovModel distribución, utilizando una variable entrenable para representar las tarifas asociadas a cada estado del sistema. Parametrizamos las tasas en el espacio logarítmico para asegurarnos de que tengan un valor positivo.
# Define variable to represent the unknown log rates.
trainable_log_rates = tf.Variable(
tf.math.log(tf.reduce_mean(observed_counts)) +
tf.random.stateless_normal([num_states], seed=(42, 42)),
name='log_rates')
hmm = tfd.HiddenMarkovModel(
initial_distribution=tfd.Categorical(
logits=initial_state_logits),
transition_distribution=tfd.Categorical(probs=transition_probs),
observation_distribution=tfd.Poisson(log_rate=trainable_log_rates),
num_steps=len(observed_counts))
Por último, se define la densidad total del registro del modelo, incluyendo un LogNormal débilmente informativa previa sobre las tasas, y ejecutar un optimizador para calcular el máximo a posteriori (MAP) ajuste a los datos recuento observado.
rate_prior = tfd.LogNormal(5, 5)
def log_prob():
return (tf.reduce_sum(rate_prior.log_prob(tf.math.exp(trainable_log_rates))) +
hmm.log_prob(observed_counts))
losses = tfp.math.minimize(
lambda: -log_prob(),
optimizer=tf.optimizers.Adam(learning_rate=0.1),
num_steps=100)
plt.plot(losses)
plt.ylabel('Negative log marginal likelihood')
Text(0, 0.5, 'Negative log marginal likelihood')
rates = tf.exp(trainable_log_rates)
print("Inferred rates: {}".format(rates))
print("True rates: {}".format(true_rates))
Inferred rates: [ 2.8302798 49.58499 41.928307 17.35112 ] True rates: [40, 3, 20, 50]
¡Funcionó! Tenga en cuenta que los estados latentes en este modelo son identificables solo hasta la permutación, por lo que las tasas que recuperamos están en un orden diferente y hay un poco de ruido, pero en general coinciden bastante bien.
Recuperando la trayectoria estatal
Ahora que hemos ajustar el modelo, lo que se quiere reconstruir qué estado el modelo cree que el sistema estaba en cada paso de tiempo a.
Esta es una tarea inferencia posterior: teniendo en cuenta los recuentos observados \(x_{1:T}\) y los parámetros del modelo (tasas) \(\lambda\), queremos inferir la secuencia de variables latentes discretos, después de la distribución posterior \(p(z_{1:T} | x_{1:T}, \lambda)\). En un modelo de Markov oculto, podemos calcular de manera eficiente los marginales y otras propiedades de esta distribución utilizando algoritmos estándar de paso de mensajes. En particular, el posterior_marginals método calculará de manera eficiente (utilizando el algoritmo de adelante-atrás ) la distribución de probabilidad marginal \(p(Z_t = z_t | x_{1:T})\) sobre el estado latente discreta \(Z_t\) en cada paso de tiempo \(t\).
# Runs forward-backward algorithm to compute marginal posteriors.
posterior_dists = hmm.posterior_marginals(observed_counts)
posterior_probs = posterior_dists.probs_parameter().numpy()
Al trazar las probabilidades posteriores, recuperamos la "explicación" de los datos del modelo: ¿en qué momentos en el tiempo está activo cada estado?
def plot_state_posterior(ax, state_posterior_probs, title):
ln1 = ax.plot(state_posterior_probs, c='blue', lw=3, label='p(state | counts)')
ax.set_ylim(0., 1.1)
ax.set_ylabel('posterior probability')
ax2 = ax.twinx()
ln2 = ax2.plot(observed_counts, c='black', alpha=0.3, label='observed counts')
ax2.set_title(title)
ax2.set_xlabel("time")
lns = ln1+ln2
labs = [l.get_label() for l in lns]
ax.legend(lns, labs, loc=4)
ax.grid(True, color='white')
ax2.grid(False)
fig = plt.figure(figsize=(10, 10))
plot_state_posterior(fig.add_subplot(2, 2, 1),
posterior_probs[:, 0],
title="state 0 (rate {:.2f})".format(rates[0]))
plot_state_posterior(fig.add_subplot(2, 2, 2),
posterior_probs[:, 1],
title="state 1 (rate {:.2f})".format(rates[1]))
plot_state_posterior(fig.add_subplot(2, 2, 3),
posterior_probs[:, 2],
title="state 2 (rate {:.2f})".format(rates[2]))
plot_state_posterior(fig.add_subplot(2, 2, 4),
posterior_probs[:, 3],
title="state 3 (rate {:.2f})".format(rates[3]))
plt.tight_layout()
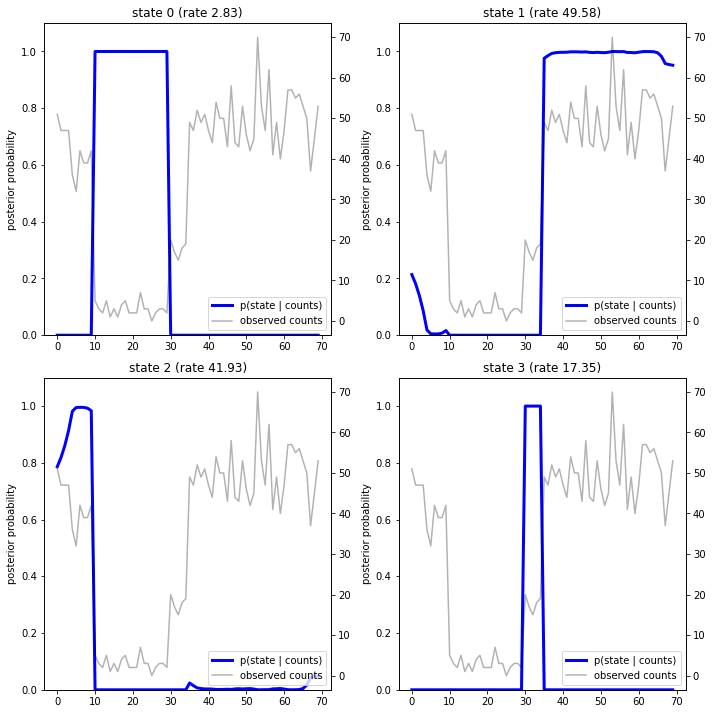
En este caso (simple), vemos que el modelo suele ser bastante seguro: en la mayoría de los pasos de tiempo asigna esencialmente toda la masa de probabilidad a uno solo de los cuatro estados. ¡Afortunadamente, las explicaciones parecen razonables!
También podemos visualizar esto a posteriori en función de la tasa asociada con el estado latente más probable es que en cada paso de tiempo, la condensación posterior probabilística en una sola explicación:
most_probable_states = hmm.posterior_mode(observed_counts)
most_probable_rates = tf.gather(rates, most_probable_states)
fig = plt.figure(figsize=(10, 4))
ax = fig.add_subplot(1, 1, 1)
ax.plot(most_probable_rates, c='green', lw=3, label='inferred rate')
ax.plot(observed_counts, c='black', alpha=0.3, label='observed counts')
ax.set_ylabel("latent rate")
ax.set_xlabel("time")
ax.set_title("Inferred latent rate over time")
ax.legend(loc=4)
<matplotlib.legend.Legend at 0x7f75849e70f0>
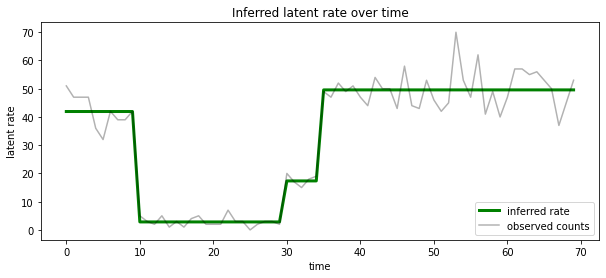
Número desconocido de estados
En problemas reales, es posible que no sepamos el número "verdadero" de estados en el sistema que estamos modelando. Esto puede no ser siempre una preocupación: si no le importan particularmente las identidades de los estados desconocidos, puede ejecutar un modelo con más estados de los que cree que necesitará el modelo y aprender (algo así como) un montón de duplicados copias de los estados actuales. Pero supongamos que le importa inferir el número "verdadero" de estados latentes.
Podemos ver esto como un caso de selección del modelo bayesiano : tenemos un conjunto de modelos candidatos, cada uno con un número diferente de estados latentes, y queremos elegir la que es más probable que hayan generado los datos observados. Para ello, calculamos la probabilidad marginal de los datos en virtud de cada modelo (también podríamos añadir un previo sobre los propios modelos, pero eso no será necesario en este análisis, la navaja de bayesiano Occam resulta ser suficiente para codificar una preferencia por modelos más simples).
Desafortunadamente, la verdadera probabilidad marginal, que integra tanto sobre el estados discretos \(z_{1:T}\) y la (vector de parámetros de velocidad) \(\lambda\), \(p(x_{1:T}) = \int p(x_{1:T}, z_{1:T}, \lambda) dz d\lambda,\) no es manejable para este modelo. Para mayor comodidad, nos aproximamos usando uno de los llamados " Bayes empíricos " o "tipo II máxima probabilidad" estimación: en lugar de integrar totalmente los parámetros de velocidad (desconocido) \(\lambda\) asociada a cada estado del sistema, vamos a optimizar sobre sus valores:
\[\tilde{p}(x_{1:T}) = \max_\lambda \int p(x_{1:T}, z_{1:T}, \lambda) dz\]
Esta aproximación puede sobreajustarse, es decir, preferirá modelos más complejos que la verdadera probabilidad marginal. Podríamos considerar aproximaciones más fieles, por ejemplo, la optimización de un variacional límite inferior, o utilizando un estimador de Monte Carlo como el muestreo de importancia recocido ; estos están (lamentablemente) más allá del alcance de este cuaderno. (Para más información sobre la selección y aproximaciones modelo bayesiano, el capítulo 7 de la excelente máquina de aprendizaje: una perspectiva probabilístico es una referencia buena.)
En principio, podríamos hacer esta comparación de modelos, simplemente volviendo a ejecutar la optimización por encima de muchas veces con diferentes valores de num_states , pero eso sería mucho trabajo. Aquí vamos a mostrar cómo considerar varios modelos en paralelo, usando de la PTF batch_shape mecanismo de vectorización.
Matriz de transición y el estado inicial antes: en lugar de construir una única descripción del modelo, ahora vamos a construir un lote de matrices de transición y logits anteriores, uno para cada modelo candidato hasta max_num_states . Para facilitar el procesamiento por lotes, necesitaremos asegurarnos de que todos los cálculos tengan la misma 'forma': esto debe corresponder a las dimensiones del modelo más grande que ajustaremos. Para manejar modelos más pequeños, podemos "incrustar" sus descripciones en las dimensiones superiores del espacio de estados, tratando de manera efectiva las dimensiones restantes como estados ficticios que nunca se utilizan.
max_num_states = 10
def build_latent_state(num_states, max_num_states, daily_change_prob=0.05):
# Give probability exp(-100) ~= 0 to states outside of the current model.
active_states_mask = tf.concat([tf.ones([num_states]),
tf.zeros([max_num_states - num_states])],
axis=0)
initial_state_logits = -100. * (1 - active_states_mask)
# Build a transition matrix that transitions only within the current
# `num_states` states.
transition_probs = tf.fill([num_states, num_states],
0. if num_states == 1
else daily_change_prob / (num_states - 1))
padded_transition_probs = tf.eye(max_num_states) + tf.pad(
tf.linalg.set_diag(transition_probs,
tf.fill([num_states], - daily_change_prob)),
paddings=[(0, max_num_states - num_states),
(0, max_num_states - num_states)])
return initial_state_logits, padded_transition_probs
# For each candidate model, build the initial state prior and transition matrix.
batch_initial_state_logits = []
batch_transition_probs = []
for num_states in range(1, max_num_states+1):
initial_state_logits, transition_probs = build_latent_state(
num_states=num_states,
max_num_states=max_num_states)
batch_initial_state_logits.append(initial_state_logits)
batch_transition_probs.append(transition_probs)
batch_initial_state_logits = tf.stack(batch_initial_state_logits)
batch_transition_probs = tf.stack(batch_transition_probs)
print("Shape of initial_state_logits: {}".format(batch_initial_state_logits.shape))
print("Shape of transition probs: {}".format(batch_transition_probs.shape))
print("Example initial state logits for num_states==3:\n{}".format(batch_initial_state_logits[2, :]))
print("Example transition_probs for num_states==3:\n{}".format(batch_transition_probs[2, :, :]))
Shape of initial_state_logits: (10, 10) Shape of transition probs: (10, 10, 10) Example initial state logits for num_states==3: [ -0. -0. -0. -100. -100. -100. -100. -100. -100. -100.] Example transition_probs for num_states==3: [[0.95 0.025 0.025 0. 0. 0. 0. 0. 0. 0. ] [0.025 0.95 0.025 0. 0. 0. 0. 0. 0. 0. ] [0.025 0.025 0.95 0. 0. 0. 0. 0. 0. 0. ] [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. ] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0. ] [0. 0. 0. 0. 0. 1. 0. 0. 0. 0. ] [0. 0. 0. 0. 0. 0. 1. 0. 0. 0. ] [0. 0. 0. 0. 0. 0. 0. 1. 0. 0. ] [0. 0. 0. 0. 0. 0. 0. 0. 1. 0. ] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1. ]]
Ahora procedemos de manera similar a como se indicó anteriormente. Esta vez vamos a utilizar una dimensión extra en lotes trainable_rates para ajustarse por separado las tarifas para cada modelo en cuestión.
trainable_log_rates = tf.Variable(
tf.fill([batch_initial_state_logits.shape[0], max_num_states],
tf.math.log(tf.reduce_mean(observed_counts))) +
tf.random.stateless_normal([1, max_num_states], seed=(42, 42)),
name='log_rates')
hmm = tfd.HiddenMarkovModel(
initial_distribution=tfd.Categorical(
logits=batch_initial_state_logits),
transition_distribution=tfd.Categorical(probs=batch_transition_probs),
observation_distribution=tfd.Poisson(log_rate=trainable_log_rates),
num_steps=len(observed_counts))
print("Defined HMM with batch shape: {}".format(hmm.batch_shape))
Defined HMM with batch shape: (10,)
Al calcular el problema logarítmico total, tenemos cuidado de sumar solo los valores anteriores para las tasas realmente utilizadas por cada componente del modelo:
rate_prior = tfd.LogNormal(5, 5)
def log_prob():
prior_lps = rate_prior.log_prob(tf.math.exp(trainable_log_rates))
prior_lp = tf.stack(
[tf.reduce_sum(prior_lps[i, :i+1]) for i in range(max_num_states)])
return prior_lp + hmm.log_prob(observed_counts)
Ahora optimizamos el objetivo de lotes que hemos construido, encajando todos los modelos candidatos al mismo tiempo:
losses = tfp.math.minimize(
lambda: -log_prob(),
optimizer=tf.optimizers.Adam(0.1),
num_steps=100)
plt.plot(losses)
plt.ylabel('Negative log marginal likelihood')
Text(0, 0.5, 'Negative log marginal likelihood')
num_states = np.arange(1, max_num_states+1)
plt.plot(num_states, -losses[-1])
plt.ylim([-400, -200])
plt.ylabel("marginal likelihood $\\tilde{p}(x)$")
plt.xlabel("number of latent states")
plt.title("Model selection on latent states")
Text(0.5, 1.0, 'Model selection on latent states')
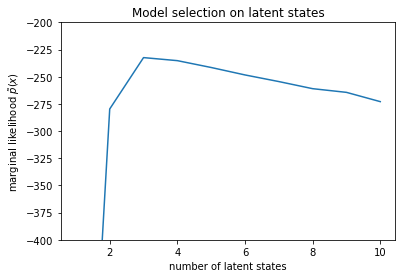
Al examinar las probabilidades, vemos que la probabilidad marginal (aproximada) tiende a preferir un modelo de tres estados. Esto parece bastante plausible: el modelo "verdadero" tenía cuatro estados, pero con solo mirar los datos es difícil descartar una explicación de tres estados.
También podemos extraer las tarifas que se ajustan a cada modelo candidato:
rates = tf.exp(trainable_log_rates)
for i, learned_model_rates in enumerate(rates):
print("rates for {}-state model: {}".format(i+1, learned_model_rates[:i+1]))
rates for 1-state model: [32.968506] rates for 2-state model: [ 5.789209 47.948917] rates for 3-state model: [ 2.841977 48.057507 17.958897] rates for 4-state model: [ 2.8302798 49.585037 41.928406 17.351114 ] rates for 5-state model: [17.399694 77.83679 41.975216 49.62771 2.8256145] rates for 6-state model: [41.63677 77.20768 49.570934 49.557076 17.630419 2.8713436] rates for 7-state model: [41.711704 76.405945 49.581184 49.561283 17.451889 2.8722699 17.43608 ] rates for 8-state model: [41.771793 75.41323 49.568714 49.591846 17.2523 17.247969 17.231388 2.830598] rates for 9-state model: [41.83378 74.50916 49.619488 49.622494 2.8369408 17.254414 17.21532 2.5904858 17.252514 ] rates for 10-state model: [4.1886074e+01 7.3912338e+01 4.1940136e+01 4.9652588e+01 2.8485537e+00 1.7433832e+01 6.7564294e-02 1.9590002e+00 1.7430998e+01 7.8838937e-02]
Y grafique las explicaciones que cada modelo proporciona para los datos:
most_probable_states = hmm.posterior_mode(observed_counts)
fig = plt.figure(figsize=(14, 12))
for i, learned_model_rates in enumerate(rates):
ax = fig.add_subplot(4, 3, i+1)
ax.plot(tf.gather(learned_model_rates, most_probable_states[i]), c='green', lw=3, label='inferred rate')
ax.plot(observed_counts, c='black', alpha=0.3, label='observed counts')
ax.set_ylabel("latent rate")
ax.set_xlabel("time")
ax.set_title("{}-state model".format(i+1))
ax.legend(loc=4)
plt.tight_layout()
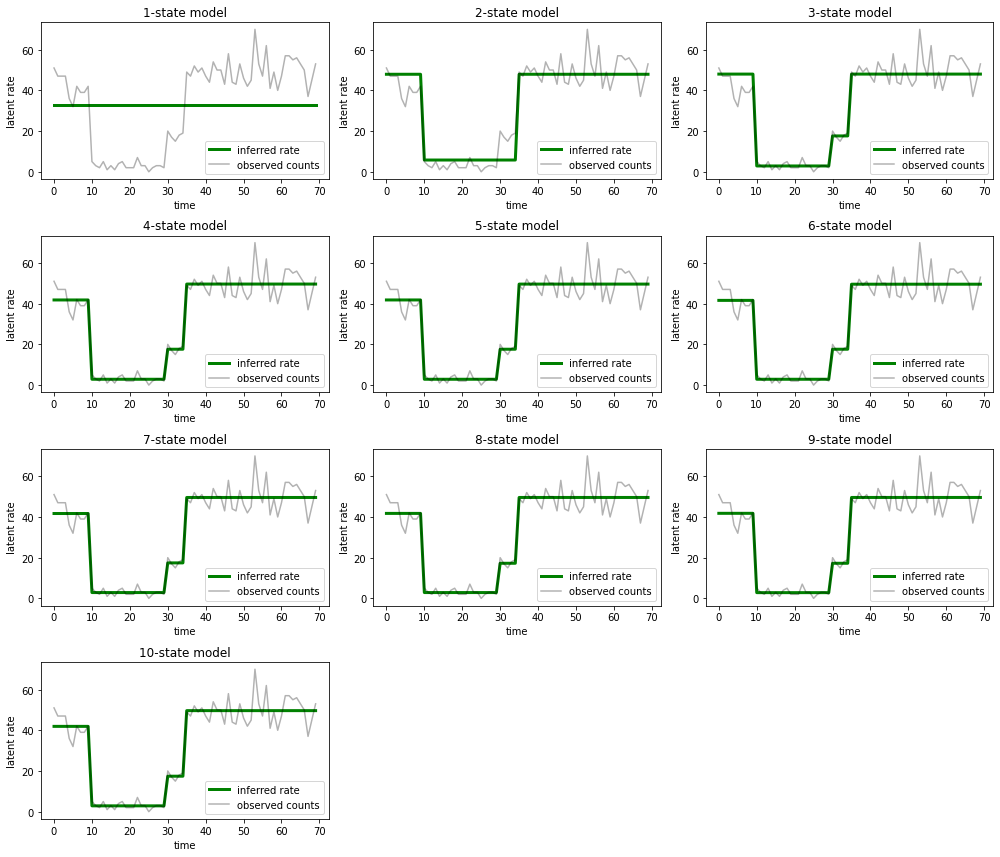
Es fácil ver cómo los modelos de uno, dos y (más sutilmente) tres estados proporcionan explicaciones inadecuadas. Curiosamente, ¡todos los modelos por encima de los cuatro estados proporcionan esencialmente la misma explicación! Es probable que esto se deba a que nuestros "datos" son relativamente limpios y dejan poco espacio para explicaciones alternativas; en datos más desordenados del mundo real, esperaríamos que los modelos de mayor capacidad proporcionen ajustes progresivamente mejores a los datos, con algún punto de compensación en el que el ajuste mejorado se ve compensado por la complejidad del modelo.
Extensiones
Los modelos de este portátil se pueden ampliar fácilmente de muchas formas. Por ejemplo:
- permitir que los estados latentes tengan diferentes probabilidades (algunos estados pueden ser comunes o raros)
- Permitir transiciones no uniformes entre estados latentes (por ejemplo, saber que una falla de la máquina generalmente es seguida por un reinicio del sistema y generalmente es seguido por un período de buen desempeño, etc.)
- otros modelos de emisión, por ejemplo
NegativeBinomialpara modelar diferentes dispersiones en datos de recuento, o distribuciones continuas tales comoNormalpara los datos de valor real.