
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
ملخص
توفر tf.distribute.Strategy API فكرة مجردة لتوزيع تدريبك عبر وحدات معالجة متعددة. يسمح لك بإجراء تدريب موزع باستخدام النماذج الحالية ورمز التدريب مع الحد الأدنى من التغييرات.
يوضح هذا البرنامج التعليمي كيفية استخدام tf.distribute.MirroredStrategy لأداء النسخ المتماثل في الرسم البياني مع التدريب المتزامن على العديد من وحدات معالجة الرسومات على جهاز واحد . تنسخ الإستراتيجية بشكل أساسي جميع متغيرات النموذج لكل معالج. بعد ذلك ، يستخدم all-Red لدمج التدرجات من جميع المعالجات ، ويطبق القيمة المجمعة على جميع نسخ النموذج.
ستستخدم واجهات برمجة تطبيقات tf.keras لبناء النموذج و Model.fit . (للتعرف على التدريب الموزع باستخدام حلقة تدريب مخصصة و MirroredStrategy ، راجع هذا البرنامج التعليمي .)
MirroredStrategy بتدريب نموذجك على وحدات معالجة رسومات متعددة على جهاز واحد. للتدريب المتزامن على العديد من وحدات معالجة الرسومات على عدة عمال ، استخدم tf.distribute.MultiWorkerMirroredStrategy مع Keras Model.fit أو حلقة تدريب مخصصة . للحصول على خيارات أخرى ، راجع دليل التدريب الموزع .
للتعرف على مختلف الاستراتيجيات الأخرى ، يوجد تدريب موزع باستخدام دليل TensorFlow .
يثبت
import tensorflow_datasets as tfds
import tensorflow as tf
import os
# Load the TensorBoard notebook extension.
%load_ext tensorboard
print(tf.__version__)
2.8.0-rc1
قم بتنزيل مجموعة البيانات
قم بتحميل مجموعة بيانات MNIST من مجموعات بيانات TensorFlow . يؤدي هذا إلى إرجاع مجموعة بيانات بتنسيق tf.data .
يتضمن تعيين الوسيطة with_info إلى True البيانات الوصفية لمجموعة البيانات بأكملها ، والتي يتم حفظها هنا في info . يتضمن كائن البيانات الوصفية هذا ، من بين أشياء أخرى ، عدد أمثلة القطار والاختبار.
datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train, mnist_test = datasets['train'], datasets['test']
تحديد استراتيجية التوزيع
إنشاء كائن MirroredStrategy . سيعالج هذا التوزيع ويوفر مدير سياق ( MirroredStrategy.scope ) لبناء نموذجك بالداخل.
strategy = tf.distribute.MirroredStrategy()
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
Number of devices: 1
قم بإعداد خط أنابيب الإدخال
عند تدريب نموذج باستخدام وحدات معالجة رسومات متعددة ، يمكنك استخدام قوة الحوسبة الإضافية بفعالية من خلال زيادة حجم الدُفعة. بشكل عام ، استخدم أكبر حجم للدفعة يناسب ذاكرة GPU وقم بضبط معدل التعلم وفقًا لذلك.
# You can also do info.splits.total_num_examples to get the total
# number of examples in the dataset.
num_train_examples = info.splits['train'].num_examples
num_test_examples = info.splits['test'].num_examples
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
حدد وظيفة تعمل على تسوية قيم بكسل الصورة من النطاق [0, 255] إلى النطاق [0, 1] ( تحجيم الميزة ):
def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label
قم بتطبيق وظيفة scale هذه على بيانات التدريب والاختبار ، ثم استخدم واجهات برمجة تطبيقات tf.data.Dataset لخلط بيانات التدريب ( Dataset.shuffle ) ، ودُفعاتها ( Dataset.batch ). لاحظ أنك تحتفظ أيضًا بذاكرة تخزين مؤقت لبيانات التدريب في الذاكرة لتحسين الأداء ( Dataset.cache ).
train_dataset = mnist_train.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
eval_dataset = mnist_test.map(scale).batch(BATCH_SIZE)
قم بإنشاء النموذج
قم بإنشاء وتجميع نموذج Keras في سياق Strategy.scope :
with strategy.scope():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
تحديد عمليات الاسترجاعات
حدد tf.keras.callbacks التالية:
-
tf.keras.callbacks.TensorBoard: يكتب سجلاً لـ TensorBoard ، والذي يسمح لك بتصور الرسوم البيانية. -
tf.keras.callbacks.ModelCheckpoint: يحفظ النموذج بتردد معين ، بعد كل حقبة مثلاً. -
tf.keras.callbacks.LearningRateScheduler: يقوم بجدولة معدل التعلم للتغيير بعد ، على سبيل المثال ، كل فترة / دفعة.
لأغراض توضيحية ، قم بإضافة رد اتصال مخصص يسمى PrintLR لعرض معدل التعلم في الكمبيوتر الدفتري.
# Define the checkpoint directory to store the checkpoints.
checkpoint_dir = './training_checkpoints'
# Define the name of the checkpoint files.
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Define a function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
# Define a callback for printing the learning rate at the end of each epoch.
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format(epoch + 1,
model.optimizer.lr.numpy()))
# Put all the callbacks together.
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
تدريب وتقييم
الآن ، قم بتدريب النموذج بالطريقة المعتادة من خلال استدعاء Model.fit على النموذج وتمرير مجموعة البيانات التي تم إنشاؤها في بداية البرنامج التعليمي. هذه الخطوة هي نفسها سواء كنت تقوم بتوزيع التدريب أم لا.
EPOCHS = 12
model.fit(train_dataset, epochs=EPOCHS, callbacks=callbacks)
2022-01-26 05:38:28.865380: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed.
Epoch 1/12
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
933/938 [============================>.] - ETA: 0s - loss: 0.2029 - accuracy: 0.9399
Learning rate for epoch 1 is 0.0010000000474974513
938/938 [==============================] - 10s 4ms/step - loss: 0.2022 - accuracy: 0.9401 - lr: 0.0010
Epoch 2/12
930/938 [============================>.] - ETA: 0s - loss: 0.0654 - accuracy: 0.9813
Learning rate for epoch 2 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0652 - accuracy: 0.9813 - lr: 0.0010
Epoch 3/12
931/938 [============================>.] - ETA: 0s - loss: 0.0453 - accuracy: 0.9864
Learning rate for epoch 3 is 0.0010000000474974513
938/938 [==============================] - 3s 3ms/step - loss: 0.0453 - accuracy: 0.9864 - lr: 0.0010
Epoch 4/12
923/938 [============================>.] - ETA: 0s - loss: 0.0246 - accuracy: 0.9933
Learning rate for epoch 4 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0244 - accuracy: 0.9934 - lr: 1.0000e-04
Epoch 5/12
929/938 [============================>.] - ETA: 0s - loss: 0.0211 - accuracy: 0.9944
Learning rate for epoch 5 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0212 - accuracy: 0.9944 - lr: 1.0000e-04
Epoch 6/12
930/938 [============================>.] - ETA: 0s - loss: 0.0192 - accuracy: 0.9950
Learning rate for epoch 6 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0194 - accuracy: 0.9950 - lr: 1.0000e-04
Epoch 7/12
927/938 [============================>.] - ETA: 0s - loss: 0.0179 - accuracy: 0.9953
Learning rate for epoch 7 is 9.999999747378752e-05
938/938 [==============================] - 3s 3ms/step - loss: 0.0179 - accuracy: 0.9953 - lr: 1.0000e-04
Epoch 8/12
938/938 [==============================] - ETA: 0s - loss: 0.0153 - accuracy: 0.9966
Learning rate for epoch 8 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0153 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 9/12
927/938 [============================>.] - ETA: 0s - loss: 0.0151 - accuracy: 0.9966
Learning rate for epoch 9 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0150 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 10/12
935/938 [============================>.] - ETA: 0s - loss: 0.0148 - accuracy: 0.9966
Learning rate for epoch 10 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0148 - accuracy: 0.9966 - lr: 1.0000e-05
Epoch 11/12
937/938 [============================>.] - ETA: 0s - loss: 0.0146 - accuracy: 0.9967
Learning rate for epoch 11 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0146 - accuracy: 0.9967 - lr: 1.0000e-05
Epoch 12/12
926/938 [============================>.] - ETA: 0s - loss: 0.0145 - accuracy: 0.9967
Learning rate for epoch 12 is 9.999999747378752e-06
938/938 [==============================] - 3s 3ms/step - loss: 0.0144 - accuracy: 0.9967 - lr: 1.0000e-05
<keras.callbacks.History at 0x7fad70067c10>
تحقق من نقاط التفتيش المحفوظة:
# Check the checkpoint directory.ls {checkpoint_dir}
checkpoint ckpt_4.data-00000-of-00001 ckpt_1.data-00000-of-00001 ckpt_4.index ckpt_1.index ckpt_5.data-00000-of-00001 ckpt_10.data-00000-of-00001 ckpt_5.index ckpt_10.index ckpt_6.data-00000-of-00001 ckpt_11.data-00000-of-00001 ckpt_6.index ckpt_11.index ckpt_7.data-00000-of-00001 ckpt_12.data-00000-of-00001 ckpt_7.index ckpt_12.index ckpt_8.data-00000-of-00001 ckpt_2.data-00000-of-00001 ckpt_8.index ckpt_2.index ckpt_9.data-00000-of-00001 ckpt_3.data-00000-of-00001 ckpt_9.index ckpt_3.index
للتحقق من جودة أداء النموذج ، قم بتحميل أحدث نقطة فحص واستدعاء Model.evaluate على بيانات الاختبار:
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
eval_loss, eval_acc = model.evaluate(eval_dataset)
print('Eval loss: {}, Eval accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:15.260539: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 2s 4ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval accuracy: 0.9879000186920166
لتصور الإخراج ، قم بتشغيل TensorBoard واعرض السجلات:
%tensorboard --logdir=logs
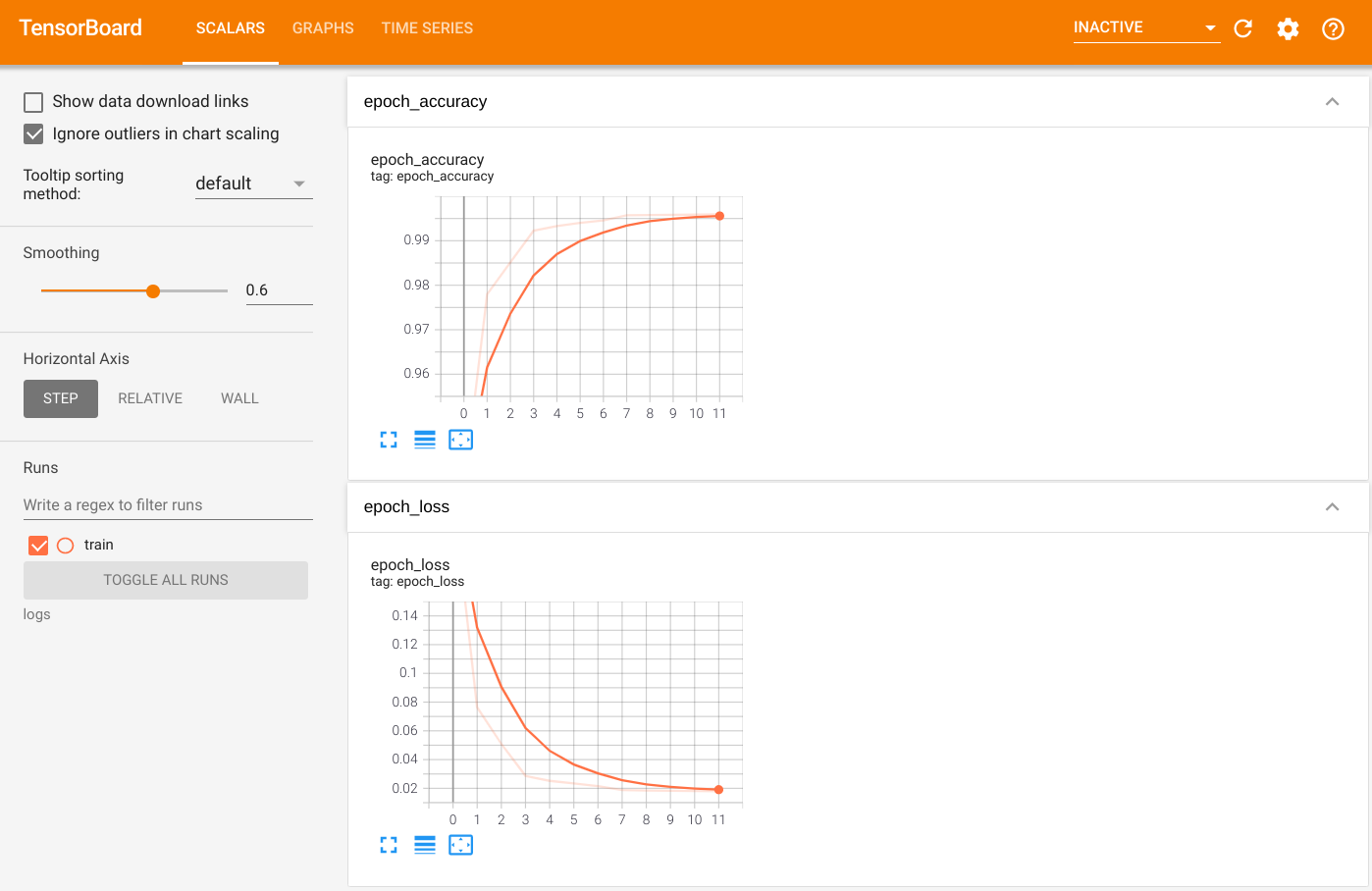
ls -sh ./logs
total 4.0K 4.0K train
تصدير إلى SavedModel
قم بتصدير الرسم البياني والمتغيرات إلى تنسيق SavedModel المحايد للنظام الأساسي باستخدام Model.save . بعد حفظ نموذجك ، يمكنك تحميله باستخدام Strategy.scope أو بدونه.
path = 'saved_model/'
model.save(path, save_format='tf')
2022-01-26 05:39:18.012847: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: saved_model/assets INFO:tensorflow:Assets written to: saved_model/assets
الآن ، قم بتحميل النموذج بدون Strategy.scope :
unreplicated_model = tf.keras.models.load_model(path)
unreplicated_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = unreplicated_model.evaluate(eval_dataset)
print('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
157/157 [==============================] - 1s 2ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
قم بتحميل النموذج باستخدام Strategy.scope :
with strategy.scope():
replicated_model = tf.keras.models.load_model(path)
replicated_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
eval_loss, eval_acc = replicated_model.evaluate(eval_dataset)
print ('Eval loss: {}, Eval Accuracy: {}'.format(eval_loss, eval_acc))
2022-01-26 05:39:19.489971: W tensorflow/core/grappler/optimizers/data/auto_shard.cc:547] The `assert_cardinality` transformation is currently not handled by the auto-shard rewrite and will be removed. 157/157 [==============================] - 3s 3ms/step - loss: 0.0373 - accuracy: 0.9879 Eval loss: 0.03732967749238014, Eval Accuracy: 0.9879000186920166
مصادر إضافية
المزيد من الأمثلة التي تستخدم استراتيجيات توزيع مختلفة مع Keras Model.fit API:
- تستخدم مهام حل GLUE باستخدام BERT في البرنامج التعليمي
tf.distribute.MirroredStrategyللتدريب على وحدات معالجة الرسومات وtf.distribute.TPUStrategy- على TPU. - يوضح برنامج حفظ وتحميل نموذج باستخدام البرنامج التعليمي لإستراتيجية التوزيع كيفية استخدام SavedModel APIs مع
tf.distribute.Strategy. - يمكن تكوين نماذج TensorFlow الرسمية لتشغيل استراتيجيات توزيع متعددة.
لمعرفة المزيد حول استراتيجيات توزيع TensorFlow:
- يوضح التدريب المخصص مع tf.distribute.Strategy كيفية استخدام
tf.distribute.MirroredStrategyلتدريب العامل الفردي باستخدام حلقة تدريب مخصصة. - يوضح التدريب متعدد العاملين باستخدام Keras كيفية استخدام
MultiWorkerMirroredStrategyمعModel.fit. - تُظهر حلقة التدريب المخصصة مع Keras و MultiWorkerMirroredStrategy كيفية استخدام
MultiWorkerMirroredStrategyمع Keras وحلقة تدريب مخصصة. - يوفر التدريب الموزع في دليل TensorFlow نظرة عامة على استراتيجيات التوزيع المتاحة.
- يوفر دليل الأداء الأفضل مع وظيفة tf معلومات حول الاستراتيجيات والأدوات الأخرى ، مثل TensorFlow Profiler الذي يمكنك استخدامه لتحسين أداء نماذج TensorFlow.