| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
بررسی اجمالی
این راهنما یک مدل رگرسیون لجستیک را با استفاده از tf.estimator API آموزش می دهد. این مدل اغلب به عنوان پایه ای برای سایر الگوریتم های پیچیده تر استفاده می شود.
برپایی
pip install sklearn
import os
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import clear_output
from six.moves import urllib
مجموعه داده تایتانیک را بارگیری کنید
شما از مجموعه داده تایتانیک با هدف (بسیار بیمارگونه) پیش بینی بقای مسافران، با توجه به ویژگی هایی مانند جنسیت، سن، طبقه و غیره استفاده خواهید کرد.
import tensorflow.compat.v2.feature_column as fc
import tensorflow as tf
# Load dataset.
dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')
dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
داده ها را کاوش کنید
مجموعه داده شامل ویژگی های زیر است
dftrain.head()
dftrain.describe()
در مجموعه آموزشی و ارزشیابی به ترتیب 627 و 264 نمونه وجود دارد.
dftrain.shape[0], dfeval.shape[0]
(627, 264)
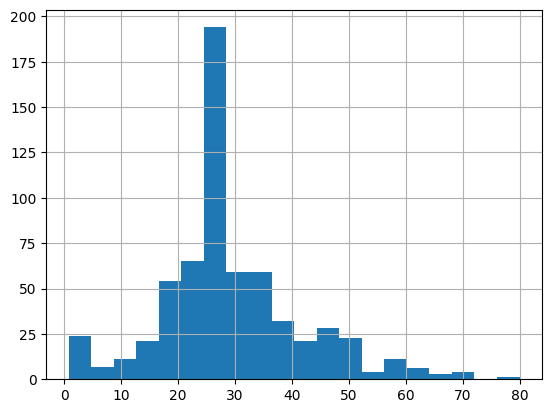
اکثر مسافران 20 و 30 ساله هستند.
dftrain.age.hist(bins=20)
<AxesSubplot:>
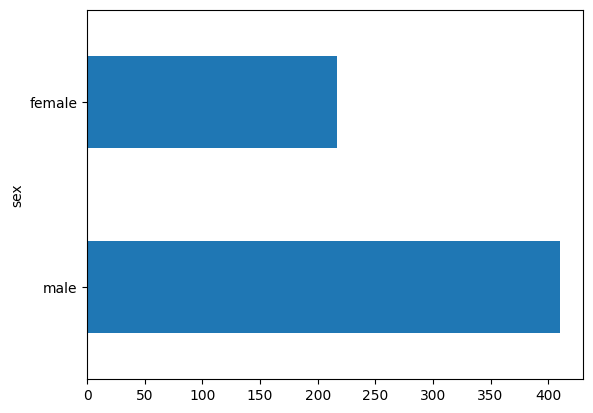
تعداد مسافران مرد تقریبا دو برابر بیشتر از مسافران زن است.
dftrain.sex.value_counts().plot(kind='barh')
<AxesSubplot:>
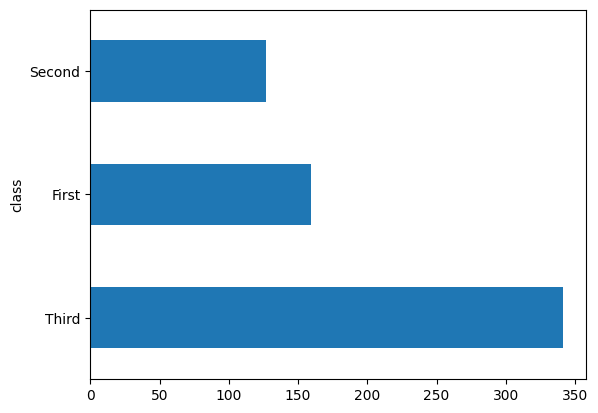
اکثر مسافران در کلاس "سوم" بودند.
dftrain['class'].value_counts().plot(kind='barh')
<AxesSubplot:>
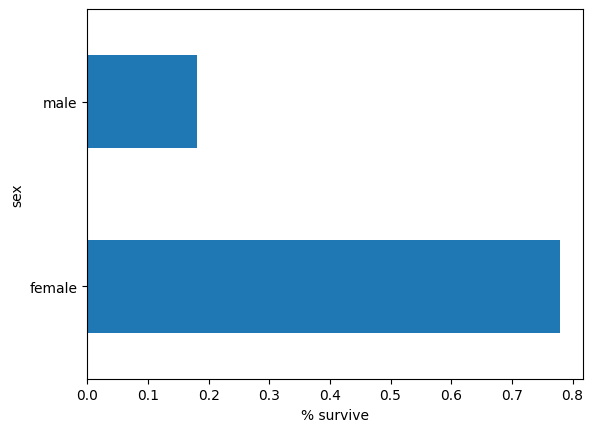
زنان در مقایسه با مردان شانس بسیار بیشتری برای زنده ماندن دارند. این به وضوح یک ویژگی پیش بینی کننده برای مدل است.
pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')
Text(0.5, 0, '% survive')
مهندسی ویژگی برای مدل
برآوردگرها از سیستمی به نام ستون های ویژگی استفاده می کنند تا توضیح دهند که مدل چگونه باید هر یک از ویژگی های ورودی خام را تفسیر کند. یک برآوردگر انتظار دارد که بردار ورودی های عددی باشد و ستون های ویژگی توضیح می دهند که مدل باید چگونه هر ویژگی را تبدیل کند.
انتخاب و ایجاد مجموعه مناسب از ستون های ویژگی، کلید یادگیری یک مدل موثر است. یک ستون ویژگی میتواند یکی از ورودیهای خام در dict ویژگیهای اصلی (یک ستون ویژگی پایه )، یا هر ستون جدیدی باشد که با استفاده از تبدیلهای تعریفشده روی یک یا چند ستون پایه (یک ستونهای ویژگی مشتق شده ) ایجاد شده است.
برآوردگر خطی از هر دو ویژگی عددی و مقوله ای استفاده می کند. ستونهای ویژگی با همه تخمینگرهای TensorFlow کار میکنند و هدف آنها تعریف ویژگیهای مورد استفاده برای مدلسازی است. علاوه بر این، آنها برخی از قابلیت های مهندسی ویژگی مانند یک رمزگذاری، نرمال سازی و سطل سازی را ارائه می دهند.
ستون های ویژگی پایه
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
vocabulary = dftrain[feature_name].unique()
feature_columns.append(tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
feature_columns.append(tf.feature_column.numeric_column(feature_name, dtype=tf.float32))
input_function مشخص می کند که چگونه داده ها به tf.data.Dataset تبدیل می شوند که خط لوله ورودی را به صورت جریانی تغذیه می کند. tf.data.Dataset می تواند چندین منبع مانند یک دیتافریم، یک فایل با فرمت csv و غیره را دریافت کند.
def make_input_fn(data_df, label_df, num_epochs=10, shuffle=True, batch_size=32):
def input_function():
ds = tf.data.Dataset.from_tensor_slices((dict(data_df), label_df))
if shuffle:
ds = ds.shuffle(1000)
ds = ds.batch(batch_size).repeat(num_epochs)
return ds
return input_function
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, num_epochs=1, shuffle=False)
می توانید مجموعه داده را بررسی کنید:
ds = make_input_fn(dftrain, y_train, batch_size=10)()
for feature_batch, label_batch in ds.take(1):
print('Some feature keys:', list(feature_batch.keys()))
print()
print('A batch of class:', feature_batch['class'].numpy())
print()
print('A batch of Labels:', label_batch.numpy())
Some feature keys: ['sex', 'age', 'n_siblings_spouses', 'parch', 'fare', 'class', 'deck', 'embark_town', 'alone'] A batch of class: [b'Third' b'Third' b'Third' b'Third' b'Third' b'First' b'Second' b'First' b'First' b'Third'] A batch of Labels: [0 1 1 0 0 1 0 1 1 0]
همچنین می توانید نتیجه یک ستون ویژگی خاص را با استفاده از لایه tf.keras.layers.DenseFeatures بررسی کنید:
age_column = feature_columns[7]
tf.keras.layers.DenseFeatures([age_column])(feature_batch).numpy()
array([[35.],
[14.],
[28.],
[19.],
[28.],
[35.],
[60.],
[63.],
[45.],
[21.]], dtype=float32)
DenseFeatures فقط تانسورهای متراکم را می پذیرد، برای بررسی یک ستون طبقه بندی شده باید ابتدا آن را به یک ستون نشانگر تبدیل کنید:
gender_column = feature_columns[0]
tf.keras.layers.DenseFeatures([tf.feature_column.indicator_column(gender_column)])(feature_batch).numpy()
array([[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.]], dtype=float32)
پس از افزودن تمام ویژگی های پایه به مدل، بیایید مدل را آموزش دهیم. آموزش یک مدل فقط یک دستور با استفاده از tf.estimator API است:
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7537879, 'accuracy_baseline': 0.625, 'auc': 0.8060607, 'auc_precision_recall': 0.7480768, 'average_loss': 0.5639972, 'label/mean': 0.375, 'loss': 0.5542658, 'precision': 0.7741935, 'prediction/mean': 0.25232768, 'recall': 0.4848485, 'global_step': 200}
ستون های ویژگی مشتق شده
اکنون به دقت 75 درصد رسیده اید. استفاده از هر ستون ویژگی پایه به طور جداگانه ممکن است برای توضیح داده ها کافی نباشد. به عنوان مثال، همبستگی بین سن و برچسب ممکن است برای جنسیت های مختلف متفاوت باشد. بنابراین، اگر فقط یک وزن مدل واحد را برای gender="Male" و " gender="Female" بگیرید، هر ترکیب سنی و جنسیتی را نمیبینید (مثلاً تمایز بین gender="Male" و age="30" و gender="Male" و age="40" ).
برای یادگیری تفاوتهای بین ترکیبهای مختلف ویژگی، میتوانید ستونهای ویژگی متقاطع را به مدل اضافه کنید (همچنین میتوانید ستون سن را قبل از ستون متقاطع سطل کنید):
age_x_gender = tf.feature_column.crossed_column(['age', 'sex'], hash_bucket_size=100)
پس از افزودن ویژگی ترکیبی به مدل، بیایید دوباره مدل را آموزش دهیم:
derived_feature_columns = [age_x_gender]
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns+derived_feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7462121, 'accuracy_baseline': 0.625, 'auc': 0.845577, 'auc_precision_recall': 0.7873878, 'average_loss': 0.47313985, 'label/mean': 0.375, 'loss': 0.46722567, 'precision': 0.6509434, 'prediction/mean': 0.41550797, 'recall': 0.6969697, 'global_step': 200}
اکنون به دقت 77.6 درصدی دست یافته است که کمی بهتر از آموزش در ویژگی های پایه است. می توانید از ویژگی ها و تغییرات بیشتر استفاده کنید تا ببینید آیا می توانید بهتر انجام دهید یا خیر!
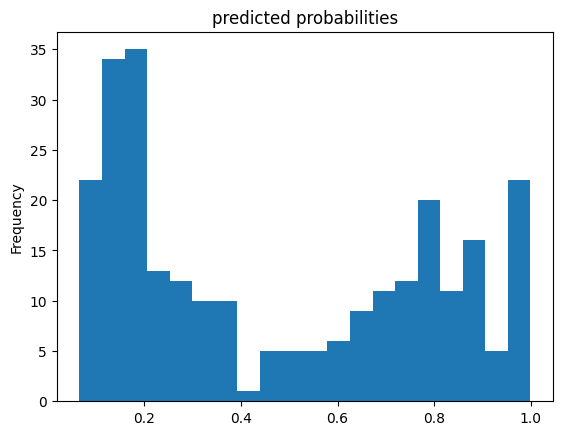
اکنون می توانید از مدل قطار برای پیش بینی مسافر از مجموعه ارزیابی استفاده کنید. مدلهای TensorFlow برای پیشبینی در یک دسته یا مجموعهای از نمونهها بهطور همزمان بهینهسازی شدهاند. پیش از این، eval_input_fn با استفاده از کل مجموعه ارزیابی تعریف شده بود.
pred_dicts = list(linear_est.predict(eval_input_fn))
probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])
probs.plot(kind='hist', bins=20, title='predicted probabilities')
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/tmpe5vngw46/model.ckpt-200
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
<AxesSubplot:title={'center':'predicted probabilities'}, ylabel='Frequency'>
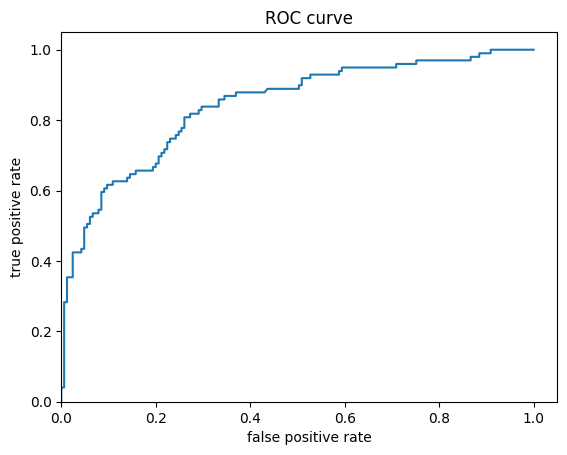
در نهایت، به مشخصه عملکرد گیرنده (ROC) نتایج نگاه کنید، که به ما ایده بهتری از مبادله بین نرخ مثبت واقعی و نرخ مثبت کاذب میدهد.
from sklearn.metrics import roc_curve
from matplotlib import pyplot as plt
fpr, tpr, _ = roc_curve(y_eval, probs)
plt.plot(fpr, tpr)
plt.title('ROC curve')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.xlim(0,)
plt.ylim(0,)
(0.0, 1.05)