| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ওভারভিউ
এই এন্ড-টু-এন্ড tf.estimator API ব্যবহার করে একটি লজিস্টিক রিগ্রেশন মডেলকে প্রশিক্ষণ দেয়। মডেলটি প্রায়শই অন্যান্য, আরও জটিল, অ্যালগরিদমের জন্য একটি বেসলাইন হিসাবে ব্যবহৃত হয়।
সেটআপ
pip install sklearn
import os
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import clear_output
from six.moves import urllib
টাইটানিক ডেটাসেট লোড করুন
আপনি টাইটানিক ডেটাসেট ব্যবহার করবেন যাত্রীদের বেঁচে থাকার ভবিষ্যদ্বাণী করার লক্ষ্যে (বরং অসুস্থ) লক্ষ্য, প্রদত্ত বৈশিষ্ট্য যেমন লিঙ্গ, বয়স, শ্রেণী ইত্যাদি।
import tensorflow.compat.v2.feature_column as fc
import tensorflow as tf
# Load dataset.
dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')
dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
তথ্য অন্বেষণ
ডেটাসেটে নিম্নলিখিত বৈশিষ্ট্যগুলি রয়েছে
dftrain.head()
dftrain.describe()
প্রশিক্ষণ এবং মূল্যায়ন সেটে যথাক্রমে 627 এবং 264টি উদাহরণ রয়েছে।
dftrain.shape[0], dfeval.shape[0]
(627, 264)
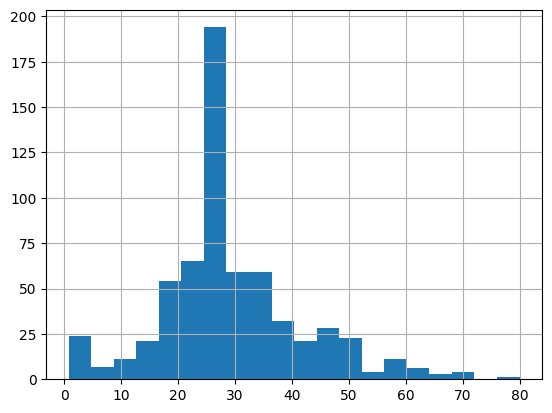
বেশিরভাগ যাত্রীর বয়স 20 এবং 30 এর মধ্যে।
dftrain.age.hist(bins=20)
<AxesSubplot:>
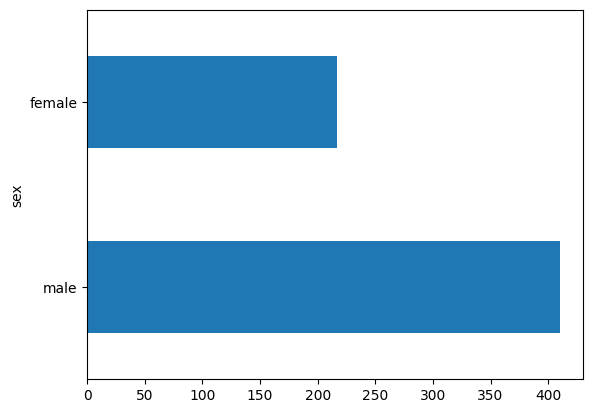
সেখানে মহিলা যাত্রীদের তুলনায় পুরুষ যাত্রীর সংখ্যা প্রায় দ্বিগুণ।
dftrain.sex.value_counts().plot(kind='barh')
<AxesSubplot:>
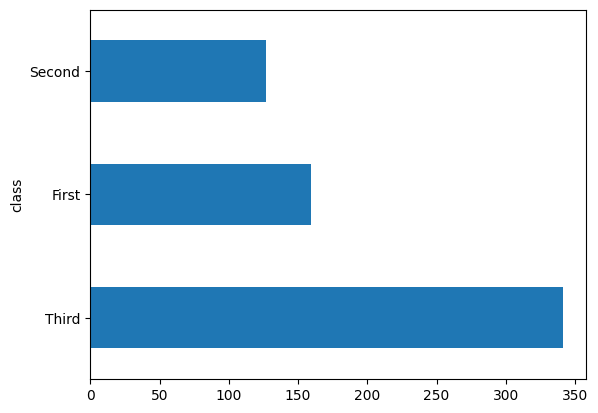
বেশির ভাগ যাত্রীই ছিল "তৃতীয়" শ্রেণীর।
dftrain['class'].value_counts().plot(kind='barh')
<AxesSubplot:>
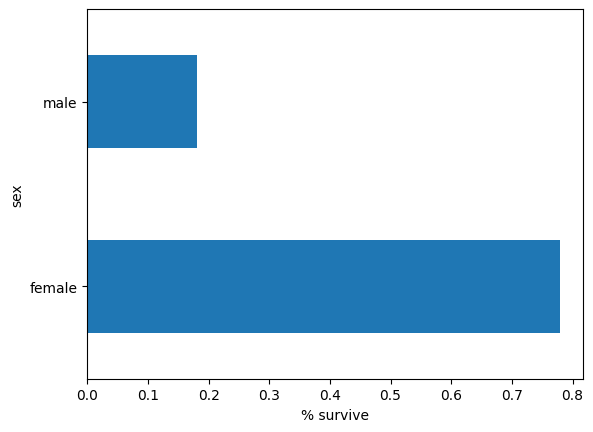
পুরুষদের তুলনায় মহিলাদের বেঁচে থাকার সম্ভাবনা অনেক বেশি। এটি স্পষ্টভাবে মডেলের জন্য একটি ভবিষ্যদ্বাণীমূলক বৈশিষ্ট্য।
pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')
Text(0.5, 0, '% survive')
মডেলের জন্য ফিচার ইঞ্জিনিয়ারিং
মডেলের প্রতিটি কাঁচা ইনপুট বৈশিষ্ট্যকে কীভাবে ব্যাখ্যা করা উচিত তা বর্ণনা করতে অনুমানকারীরা বৈশিষ্ট্য কলাম নামক একটি সিস্টেম ব্যবহার করে। একটি অনুমানকারী সাংখ্যিক ইনপুটগুলির একটি ভেক্টর আশা করে এবং বৈশিষ্ট্য কলামগুলি বর্ণনা করে যে মডেলটি প্রতিটি বৈশিষ্ট্যকে কীভাবে রূপান্তর করবে।
একটি কার্যকরী মডেল শেখার চাবিকাঠি হল ফিচার কলামের সঠিক সেট নির্বাচন করা এবং তৈরি করা। একটি ফিচার কলাম হতে পারে মূল ফিচার dict কাঁচা ইনপুটগুলির মধ্যে একটি (একটি বেস ফিচার কলাম ), অথবা একটি বা একাধিক বেস কলাম (একটি উদ্ভূত বৈশিষ্ট্য কলাম ) এর উপর সংজ্ঞায়িত রূপান্তর ব্যবহার করে তৈরি যেকোন নতুন কলাম।
রৈখিক অনুমানকারী সাংখ্যিক এবং শ্রেণীগত উভয় বৈশিষ্ট্য ব্যবহার করে। বৈশিষ্ট্য কলাম সমস্ত TensorFlow অনুমানকারীর সাথে কাজ করে এবং তাদের উদ্দেশ্য হল মডেলিংয়ের জন্য ব্যবহৃত বৈশিষ্ট্যগুলিকে সংজ্ঞায়িত করা। উপরন্তু, তারা এক-হট-এনকোডিং, স্বাভাবিকীকরণ এবং বালতিকরণের মতো কিছু বৈশিষ্ট্য ইঞ্জিনিয়ারিং ক্ষমতা প্রদান করে।
বেস ফিচার কলাম
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
vocabulary = dftrain[feature_name].unique()
feature_columns.append(tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
feature_columns.append(tf.feature_column.numeric_column(feature_name, dtype=tf.float32))
input_function নির্দিষ্ট করে কিভাবে ডাটা tf.data.Dataset এ রূপান্তরিত হয় যা স্ট্রিমিং ফ্যাশনে ইনপুট পাইপলাইন ফিড করে। tf.data.Dataset একাধিক উৎস যেমন একটি ডেটাফ্রেম, একটি csv-ফরম্যাট করা ফাইল এবং আরও অনেক কিছু নিতে পারে।
def make_input_fn(data_df, label_df, num_epochs=10, shuffle=True, batch_size=32):
def input_function():
ds = tf.data.Dataset.from_tensor_slices((dict(data_df), label_df))
if shuffle:
ds = ds.shuffle(1000)
ds = ds.batch(batch_size).repeat(num_epochs)
return ds
return input_function
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, num_epochs=1, shuffle=False)
আপনি ডেটাসেট পরিদর্শন করতে পারেন:
ds = make_input_fn(dftrain, y_train, batch_size=10)()
for feature_batch, label_batch in ds.take(1):
print('Some feature keys:', list(feature_batch.keys()))
print()
print('A batch of class:', feature_batch['class'].numpy())
print()
print('A batch of Labels:', label_batch.numpy())
Some feature keys: ['sex', 'age', 'n_siblings_spouses', 'parch', 'fare', 'class', 'deck', 'embark_town', 'alone'] A batch of class: [b'Third' b'Third' b'Third' b'Third' b'Third' b'First' b'Second' b'First' b'First' b'Third'] A batch of Labels: [0 1 1 0 0 1 0 1 1 0]
এছাড়াও আপনি tf.keras.layers.DenseFeatures স্তর ব্যবহার করে একটি নির্দিষ্ট বৈশিষ্ট্য কলামের ফলাফল পরিদর্শন করতে পারেন:
age_column = feature_columns[7]
tf.keras.layers.DenseFeatures([age_column])(feature_batch).numpy()
array([[35.],
[14.],
[28.],
[19.],
[28.],
[35.],
[60.],
[63.],
[45.],
[21.]], dtype=float32)
DenseFeatures শুধুমাত্র ঘন টেনসর গ্রহণ করে, একটি শ্রেণীবদ্ধ কলাম পরিদর্শন করার জন্য আপনাকে প্রথমে একটি নির্দেশক কলামে রূপান্তর করতে হবে:
gender_column = feature_columns[0]
tf.keras.layers.DenseFeatures([tf.feature_column.indicator_column(gender_column)])(feature_batch).numpy()
array([[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.]], dtype=float32)
মডেলটিতে সমস্ত বেস বৈশিষ্ট্য যুক্ত করার পরে, আসুন মডেলটিকে প্রশিক্ষণ দেওয়া যাক। tf.estimator API ব্যবহার করে একটি মডেলকে প্রশিক্ষণ দেওয়া একটি মাত্র কমান্ড:
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7537879, 'accuracy_baseline': 0.625, 'auc': 0.8060607, 'auc_precision_recall': 0.7480768, 'average_loss': 0.5639972, 'label/mean': 0.375, 'loss': 0.5542658, 'precision': 0.7741935, 'prediction/mean': 0.25232768, 'recall': 0.4848485, 'global_step': 200}
প্রাপ্ত বৈশিষ্ট্য কলাম
এখন আপনি 75% এর নির্ভুলতায় পৌঁছেছেন। প্রতিটি বেস বৈশিষ্ট্য কলাম আলাদাভাবে ব্যবহার করা ডেটা ব্যাখ্যা করার জন্য যথেষ্ট নাও হতে পারে। উদাহরণস্বরূপ, বয়স এবং লেবেলের মধ্যে পারস্পরিক সম্পর্ক বিভিন্ন লিঙ্গের জন্য ভিন্ন হতে পারে। অতএব, আপনি যদি gender="Male" এবং gender="Female" এর জন্য শুধুমাত্র একটি মডেলের ওজন শিখেন, তাহলে আপনি প্রতিটি বয়স-লিঙ্গ সমন্বয় ক্যাপচার করবেন না (যেমন gender="Male" এবং age="30" এবং gender="Male" মধ্যে পার্থক্য করা gender="Male" এবং age="40" )।
বিভিন্ন বৈশিষ্ট্য সংমিশ্রণের মধ্যে পার্থক্য জানতে, আপনি মডেলটিতে ক্রস করা বৈশিষ্ট্য কলাম যুক্ত করতে পারেন (আপনি ক্রস কলামের আগে বয়সের কলামটিও বকেটাইজ করতে পারেন):
age_x_gender = tf.feature_column.crossed_column(['age', 'sex'], hash_bucket_size=100)
মডেলটিতে সমন্বয় বৈশিষ্ট্য যোগ করার পরে, আসুন মডেলটিকে আবার প্রশিক্ষণ দিই:
derived_feature_columns = [age_x_gender]
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns+derived_feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7462121, 'accuracy_baseline': 0.625, 'auc': 0.845577, 'auc_precision_recall': 0.7873878, 'average_loss': 0.47313985, 'label/mean': 0.375, 'loss': 0.46722567, 'precision': 0.6509434, 'prediction/mean': 0.41550797, 'recall': 0.6969697, 'global_step': 200}
এটি এখন 77.6% এর নির্ভুলতা অর্জন করেছে, যা শুধুমাত্র বেস বৈশিষ্ট্যগুলিতে প্রশিক্ষিতের চেয়ে কিছুটা ভাল। আপনি আরও ভাল করতে পারেন কিনা তা দেখতে আপনি আরও বৈশিষ্ট্য এবং রূপান্তর ব্যবহার করে দেখতে পারেন!
এখন আপনি মূল্যায়ন সেট থেকে একজন যাত্রী সম্পর্কে ভবিষ্যদ্বাণী করতে ট্রেন মডেল ব্যবহার করতে পারেন। টেনসরফ্লো মডেলগুলি একবারে উদাহরণগুলির একটি ব্যাচ বা সংগ্রহে ভবিষ্যদ্বাণী করার জন্য অপ্টিমাইজ করা হয়েছে। আগে, eval_input_fn সম্পূর্ণ মূল্যায়ন সেট ব্যবহার করে সংজ্ঞায়িত করা হয়েছিল।
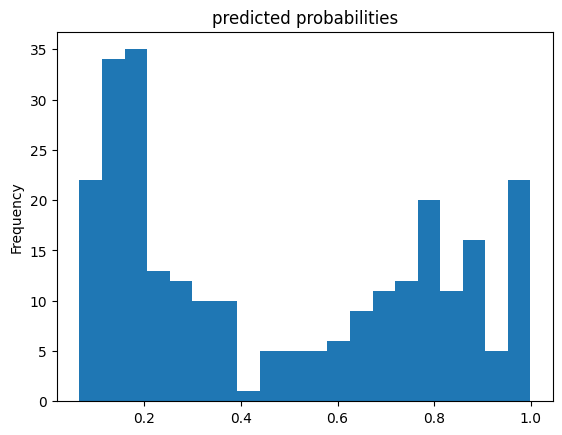
pred_dicts = list(linear_est.predict(eval_input_fn))
probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])
probs.plot(kind='hist', bins=20, title='predicted probabilities')
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/tmpe5vngw46/model.ckpt-200
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
<AxesSubplot:title={'center':'predicted probabilities'}, ylabel='Frequency'>
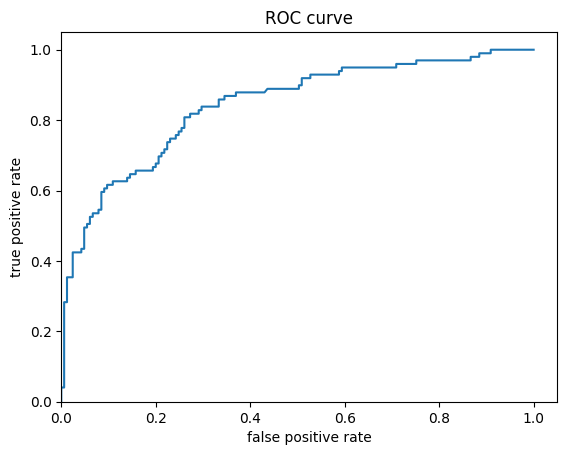
অবশেষে, ফলাফলের রিসিভার অপারেটিং বৈশিষ্ট্য (ROC) দেখুন, যা আমাদের সত্যিকারের ইতিবাচক হার এবং মিথ্যা ইতিবাচক হারের মধ্যে ট্রেডঅফ সম্পর্কে আরও ভাল ধারণা দেবে।
from sklearn.metrics import roc_curve
from matplotlib import pyplot as plt
fpr, tpr, _ = roc_curve(y_eval, probs)
plt.plot(fpr, tpr)
plt.title('ROC curve')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.xlim(0,)
plt.ylim(0,)
(0.0, 1.05)