| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
סקירה כללית
הדרכה מקצה לקצה זו מכשירה מודל רגרסיה לוגיסטי באמצעות ה-API של tf.estimator . המודל משמש לעתים קרובות כבסיס עבור אלגוריתמים אחרים, מורכבים יותר.
להכין
pip install sklearn
import os
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import clear_output
from six.moves import urllib
טען את מערך הנתונים של טיטאניק
אתה תשתמש במערך הנתונים של Titanic במטרה (די חולנית) לחזות את הישרדות הנוסעים, נתון מאפיינים כגון מין, גיל, מעמד וכו'.
import tensorflow.compat.v2.feature_column as fc
import tensorflow as tf
# Load dataset.
dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')
dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
חקור את הנתונים
מערך הנתונים מכיל את התכונות הבאות
dftrain.head()
dftrain.describe()
ישנן 627 ו-264 דוגמאות בערכות ההדרכה וההערכה, בהתאמה.
dftrain.shape[0], dfeval.shape[0]
(627, 264)
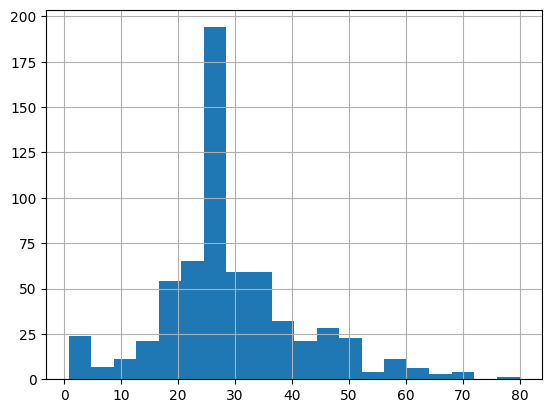
רוב הנוסעים הם בשנות ה-20 וה-30 לחייהם.
dftrain.age.hist(bins=20)
<AxesSubplot:>
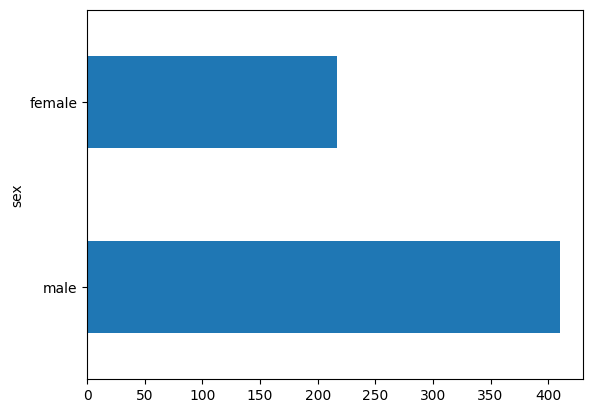
יש בערך פי שניים יותר נוסעים גברים מאשר נוסעות על הסיפון.
dftrain.sex.value_counts().plot(kind='barh')
<AxesSubplot:>
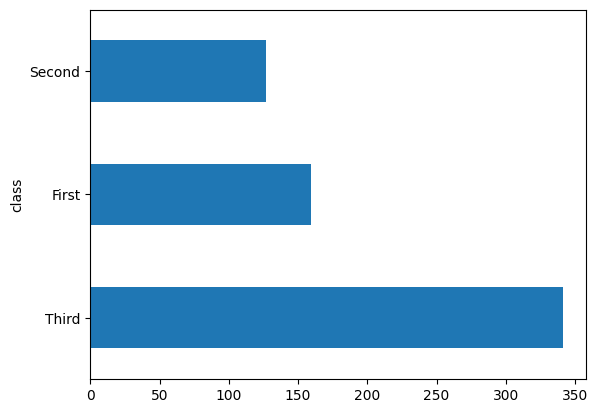
רוב הנוסעים היו במחלקה "שלישית".
dftrain['class'].value_counts().plot(kind='barh')
<AxesSubplot:>
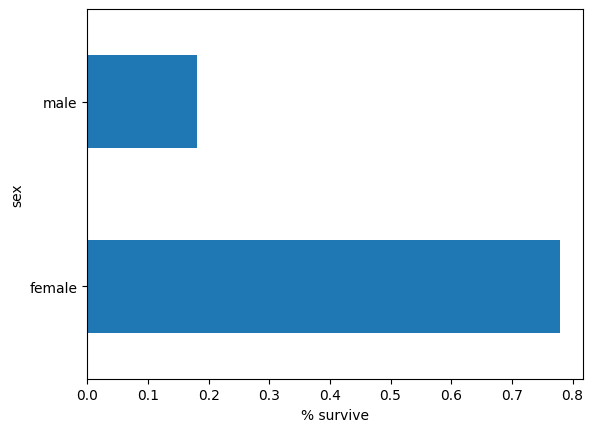
לנקבות יש סיכוי גבוה בהרבה לשרוד לעומת זכרים. ברור שזו תכונה חיזוי עבור המודל.
pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')
Text(0.5, 0, '% survive')
הנדסת תכונות עבור הדגם
האומדנים משתמשים במערכת הנקראת עמודות תכונה כדי לתאר כיצד המודל צריך לפרש כל אחת מתכונות הקלט הגולמיות. מעריך מצפה לוקטור של קלט מספרי, ועמודות תכונה מתארות כיצד המודל צריך להמיר כל תכונה.
בחירה ויצירת קבוצה נכונה של עמודות תכונה היא המפתח ללימוד מודל יעיל. עמודת תכונה יכולה להיות אחת מהקלטות הגולמיות ב- dict features המקורי ( עמודת תכונה בסיס ), או כל עמודה חדשה שנוצרה באמצעות טרנספורמציות המוגדרות על פני עמודת בסיס אחת או מרובות (עמודת תכונה נגזרת ).
האומד הליניארי משתמש הן בתכונות מספריות והן בתכונות קטגוריות. עמודות תכונות עובדות עם כל מערכי TensorFlow ומטרתן להגדיר את התכונות המשמשות למידול. בנוסף, הם מספקים כמה יכולות הנדסיות כמו קידוד חם אחד, נורמליזציה ו-bucketization.
עמודות תכונה בסיסיות
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
vocabulary = dftrain[feature_name].unique()
feature_columns.append(tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
feature_columns.append(tf.feature_column.numeric_column(feature_name, dtype=tf.float32))
input_function מציינת כיצד נתונים מומרים ל- tf.data.Dataset שמזין את צינור הקלט בצורה זורמת. tf.data.Dataset יכול לקלוט מספר מקורות כגון Dataframe, קובץ בפורמט CSV ועוד.
def make_input_fn(data_df, label_df, num_epochs=10, shuffle=True, batch_size=32):
def input_function():
ds = tf.data.Dataset.from_tensor_slices((dict(data_df), label_df))
if shuffle:
ds = ds.shuffle(1000)
ds = ds.batch(batch_size).repeat(num_epochs)
return ds
return input_function
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, num_epochs=1, shuffle=False)
אתה יכול לבדוק את מערך הנתונים:
ds = make_input_fn(dftrain, y_train, batch_size=10)()
for feature_batch, label_batch in ds.take(1):
print('Some feature keys:', list(feature_batch.keys()))
print()
print('A batch of class:', feature_batch['class'].numpy())
print()
print('A batch of Labels:', label_batch.numpy())
Some feature keys: ['sex', 'age', 'n_siblings_spouses', 'parch', 'fare', 'class', 'deck', 'embark_town', 'alone'] A batch of class: [b'Third' b'Third' b'Third' b'Third' b'Third' b'First' b'Second' b'First' b'First' b'Third'] A batch of Labels: [0 1 1 0 0 1 0 1 1 0]
אתה יכול גם לבדוק את התוצאה של עמודת תכונה ספציפית באמצעות שכבת tf.keras.layers.DenseFeatures :
age_column = feature_columns[7]
tf.keras.layers.DenseFeatures([age_column])(feature_batch).numpy()
array([[35.],
[14.],
[28.],
[19.],
[28.],
[35.],
[60.],
[63.],
[45.],
[21.]], dtype=float32)
DenseFeatures מקבל רק טנסורים צפופים, כדי לבדוק עמודה קטגורית, תחילה עליך להפוך אותה לעמודת אינדיקטור:
gender_column = feature_columns[0]
tf.keras.layers.DenseFeatures([tf.feature_column.indicator_column(gender_column)])(feature_batch).numpy()
array([[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.]], dtype=float32)
לאחר הוספת כל תכונות הבסיס לדגם, בואו נאמן את הדגם. אימון מודל הוא רק פקודה בודדת באמצעות ה-API של tf.estimator :
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7537879, 'accuracy_baseline': 0.625, 'auc': 0.8060607, 'auc_precision_recall': 0.7480768, 'average_loss': 0.5639972, 'label/mean': 0.375, 'loss': 0.5542658, 'precision': 0.7741935, 'prediction/mean': 0.25232768, 'recall': 0.4848485, 'global_step': 200}
עמודות תכונות נגזרות
כעת הגעת לדיוק של 75%. ייתכן ששימוש בכל עמודת תכונה בסיס בנפרד לא יספיק כדי להסביר את הנתונים. לדוגמה, המתאם בין הגיל והתווית עשוי להיות שונה עבור מגדר שונה. לכן, אם תלמדו רק משקל מודל בודד עבור gender="Male" gender="Female" , לא תלכוד כל שילוב גיל-מגדר (למשל הבחנה בין gender="Male" AND age="30" ו- gender="Male" AND age="40" ).
כדי ללמוד את ההבדלים בין שילובי תכונות שונים, אתה יכול להוסיף עמודות תכונות מוצלבות למודל (תוכל גם לסמן את עמודת הגיל לפני העמודה הצולבת):
age_x_gender = tf.feature_column.crossed_column(['age', 'sex'], hash_bucket_size=100)
לאחר הוספת תכונת השילוב לדגם, בואו נאמן את הדגם שוב:
derived_feature_columns = [age_x_gender]
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns+derived_feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7462121, 'accuracy_baseline': 0.625, 'auc': 0.845577, 'auc_precision_recall': 0.7873878, 'average_loss': 0.47313985, 'label/mean': 0.375, 'loss': 0.46722567, 'precision': 0.6509434, 'prediction/mean': 0.41550797, 'recall': 0.6969697, 'global_step': 200}
כעת הוא משיג דיוק של 77.6%, שהוא מעט טוב יותר מאשר מיומן רק בתכונות בסיס. אתה יכול לנסות להשתמש בעוד תכונות וטרנספורמציות כדי לראות אם אתה יכול להשתפר!
כעת אתה יכול להשתמש במודל הרכבת כדי לבצע תחזיות על נוסע מתוך ערכת ההערכה. מודלים של TensorFlow מותאמים לביצוע תחזיות על אצווה, או אוסף, של דוגמאות בבת אחת. מוקדם יותר, ה- eval_input_fn הוגדר באמצעות כל מערך ההערכה.
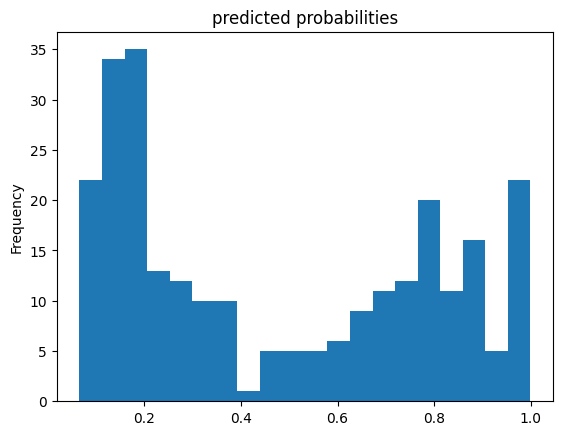
pred_dicts = list(linear_est.predict(eval_input_fn))
probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])
probs.plot(kind='hist', bins=20, title='predicted probabilities')
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/tmpe5vngw46/model.ckpt-200
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
<AxesSubplot:title={'center':'predicted probabilities'}, ylabel='Frequency'>
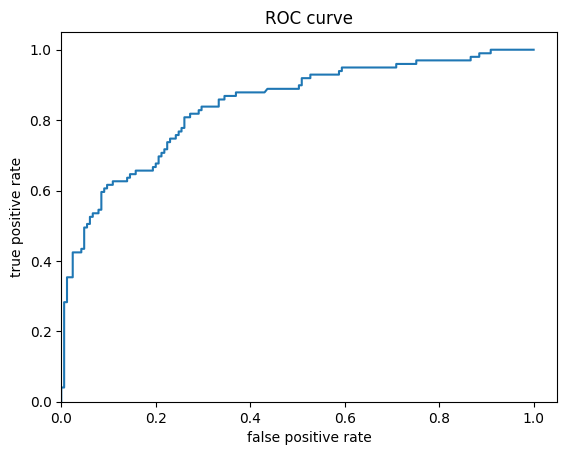
לבסוף, הסתכלו על מאפיין הפעולה של המקלט (ROC) של התוצאות, מה שייתן לנו מושג טוב יותר על הפער בין השיעור החיובי האמיתי לשיעור חיובי שגוי.
from sklearn.metrics import roc_curve
from matplotlib import pyplot as plt
fpr, tpr, _ = roc_curve(y_eval, probs)
plt.plot(fpr, tpr)
plt.title('ROC curve')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.xlim(0,)
plt.ylim(0,)
(0.0, 1.05)