
| | |  Lihat di GitHub Lihat di GitHub | | |
Tutorial ini menggunakan pembelajaran mendalam untuk menyusun satu gambar dengan gaya gambar lain (pernah berharap Anda bisa melukis seperti Picasso atau Van Gogh?). Ini dikenal sebagai transfer gaya saraf dan tekniknya diuraikan dalam A Neural Algorithm of Artistic Style (Gatys et al.).
Untuk aplikasi sederhana transfer gaya, lihat tutorial ini untuk mempelajari lebih lanjut tentang cara menggunakan model Penyesuaian Gaya Gambar Sewenang -wenang yang telah dilatih sebelumnya dari TensorFlow Hub atau cara menggunakan model transfer gaya dengan TensorFlow Lite .
Transfer gaya saraf adalah teknik pengoptimalan yang digunakan untuk mengambil dua gambar—gambar konten dan gambar referensi gaya (seperti karya seni oleh pelukis terkenal)—dan memadukannya bersama sehingga gambar keluaran terlihat seperti gambar konten, tetapi "dilukis" dalam gaya gambar referensi gaya.
Ini diimplementasikan dengan mengoptimalkan gambar keluaran agar sesuai dengan statistik konten gambar konten dan statistik gaya gambar referensi gaya. Statistik ini diekstraksi dari gambar menggunakan jaringan konvolusi.
Sebagai contoh, mari kita ambil gambar anjing ini dan Komposisi 7: Wassily Kandinsky:

Mencari Labrador Kuning , dari Wikimedia Commons oleh Elf . Lisensi CC BY-SA 3.0
{kind=link}

Sekarang bagaimana jadinya jika Kandinsky memutuskan untuk melukis gambar Anjing ini secara eksklusif dengan gaya ini? Sesuatu seperti ini?

Mempersiapkan
Impor dan konfigurasikan modul
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
Unduh gambar dan pilih gambar gaya dan gambar konten:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
Visualisasikan masukannya
Tentukan fungsi untuk memuat gambar dan batasi dimensi maksimumnya hingga 512 piksel.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
Buat fungsi sederhana untuk menampilkan gambar:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

Transfer Gaya Cepat menggunakan TF-Hub
Tutorial ini menunjukkan algoritme transfer gaya asli, yang mengoptimalkan konten gambar ke gaya tertentu. Sebelum masuk ke detailnya, mari kita lihat bagaimana model TensorFlow Hub melakukan ini:
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
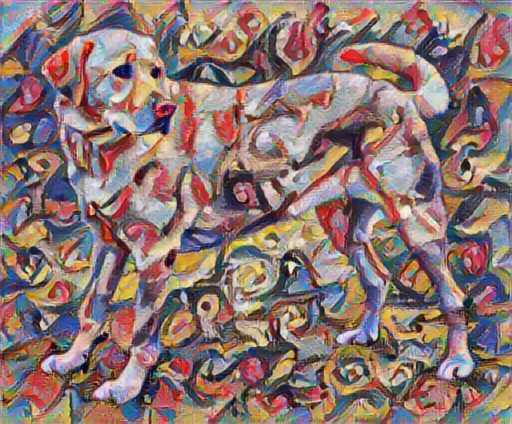
Tentukan konten dan gaya representasi
Gunakan lapisan menengah model untuk mendapatkan konten dan representasi gaya gambar. Mulai dari lapisan input jaringan, beberapa aktivasi lapisan pertama mewakili fitur tingkat rendah seperti tepi dan tekstur. Saat Anda melangkah melalui jaringan, beberapa lapisan terakhir mewakili fitur tingkat yang lebih tinggi—bagian objek seperti roda atau mata . Dalam hal ini, Anda menggunakan arsitektur jaringan VGG19, jaringan klasifikasi gambar yang telah dilatih sebelumnya. Lapisan perantara ini diperlukan untuk menentukan representasi konten dan gaya dari gambar. Untuk gambar masukan, cobalah untuk mencocokkan gaya yang sesuai dan representasi target konten pada lapisan perantara ini.
Muat VGG19 dan uji jalankan pada gambar kami untuk memastikan itu digunakan dengan benar:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
Sekarang muat VGG19 tanpa kepala klasifikasi, dan buat daftar nama layer
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
Pilih lapisan perantara dari jaringan untuk mewakili gaya dan konten gambar:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
Lapisan menengah untuk gaya dan konten
Jadi, mengapa keluaran perantara ini dalam jaringan klasifikasi gambar pra-latihan kami memungkinkan kami untuk menentukan gaya dan representasi konten?
Pada tingkat tinggi, agar jaringan dapat melakukan klasifikasi citra (yang telah dilatih untuk dilakukan oleh jaringan ini), ia harus memahami citra. Ini membutuhkan pengambilan gambar mentah sebagai piksel masukan dan membangun representasi internal yang mengubah piksel gambar mentah menjadi pemahaman kompleks tentang fitur yang ada di dalam gambar.
Ini juga merupakan alasan mengapa jaringan saraf convolutional mampu menggeneralisasi dengan baik: mereka mampu menangkap invarians dan mendefinisikan fitur dalam kelas (misalnya kucing vs anjing) yang agnostik terhadap kebisingan latar belakang dan gangguan lainnya. Jadi, di suatu tempat antara di mana gambar mentah dimasukkan ke dalam model dan label klasifikasi keluaran, model berfungsi sebagai ekstraktor fitur yang kompleks. Dengan mengakses lapisan menengah model, Anda dapat mendeskripsikan konten dan gaya gambar masukan.
Bangun modelnya
Jaringan di tf.keras.applications dirancang agar Anda dapat dengan mudah mengekstrak nilai lapisan perantara menggunakan API fungsional Keras.
Untuk mendefinisikan model menggunakan API fungsional, tentukan input dan output:
model = Model(inputs, outputs)
Fungsi berikut ini membangun model VGG19 yang mengembalikan daftar keluaran lapisan menengah:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
Dan untuk membuat modelnya:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
Hitung gaya
Isi gambar diwakili oleh nilai-nilai peta fitur menengah.
Ternyata, gaya gambar dapat dijelaskan dengan cara dan korelasi di berbagai peta fitur. Hitung matriks Gram yang mencakup informasi ini dengan mengambil produk luar dari vektor fitur dengan dirinya sendiri di setiap lokasi, dan rata-rata produk luar itu di semua lokasi. Matriks Gram ini dapat dihitung untuk lapisan tertentu sebagai:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
Ini dapat diimplementasikan secara ringkas menggunakan fungsi tf.linalg.einsum :
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
Ekstrak gaya dan konten
Buat model yang mengembalikan gaya dan tensor konten.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
Saat dipanggil pada sebuah gambar, model ini mengembalikan matriks gram (gaya) dari style_layers dan konten dari content_layers :
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
Jalankan penurunan gradien
Dengan ekstraktor gaya dan konten ini, Anda sekarang dapat menerapkan algoritme transfer gaya. Lakukan ini dengan menghitung kesalahan kuadrat rata-rata untuk output gambar Anda relatif terhadap setiap target, lalu ambil jumlah tertimbang dari kerugian ini.
Tetapkan nilai target gaya dan konten Anda:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
Tentukan tf.Variable untuk memuat gambar yang akan dioptimalkan. Untuk mempercepat ini, inisialisasi dengan gambar konten ( tf.Variable harus memiliki bentuk yang sama dengan gambar konten):
image = tf.Variable(content_image)
Karena ini adalah gambar float, tentukan fungsi untuk menjaga nilai piksel antara 0 dan 1:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
Buat pengoptimal. Makalah ini merekomendasikan LBFGS, tetapi Adam juga berfungsi dengan baik:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
Untuk mengoptimalkan ini, gunakan kombinasi tertimbang dari dua kerugian untuk mendapatkan total kerugian:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
Gunakan tf.GradientTape untuk memperbarui gambar.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Sekarang jalankan beberapa langkah untuk menguji:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

Karena berfungsi, lakukan pengoptimalan yang lebih lama:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
Kehilangan variasi total
Satu kelemahan dari implementasi dasar ini adalah ia menghasilkan banyak artefak frekuensi tinggi. Kurangi ini menggunakan istilah regularisasi eksplisit pada komponen frekuensi tinggi gambar. Dalam transfer gaya, ini sering disebut kerugian variasi total :
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
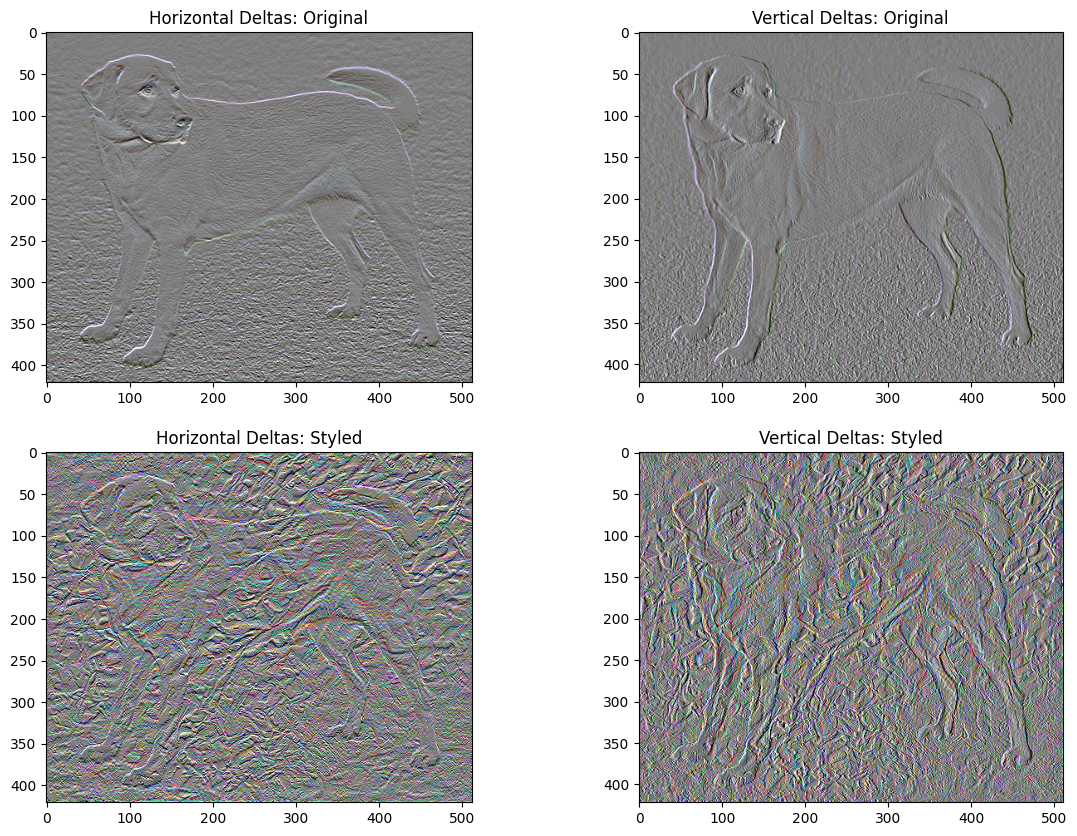
Ini menunjukkan bagaimana komponen frekuensi tinggi telah meningkat.
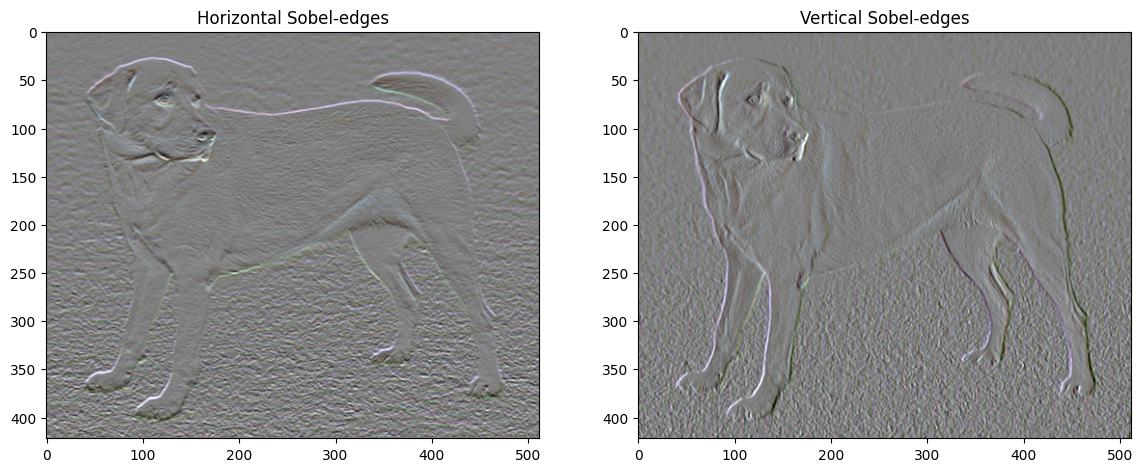
Juga, komponen frekuensi tinggi ini pada dasarnya adalah detektor tepi. Anda bisa mendapatkan output serupa dari detektor tepi Sobel, misalnya:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
Rugi regularisasi yang terkait dengan ini adalah jumlah kuadrat dari nilai-nilai:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
Itu menunjukkan apa yang dilakukannya. Tetapi tidak perlu mengimplementasikannya sendiri, TensorFlow menyertakan implementasi standar:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
Jalankan kembali pengoptimalan
Pilih bobot untuk total_variation_loss :
total_variation_weight=30
Sekarang sertakan dalam fungsi train_step :
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Inisialisasi ulang variabel pengoptimalan:
image = tf.Variable(content_image)
Dan jalankan optimasi:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
Terakhir, simpan hasilnya:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
Belajarlah lagi
Tutorial ini menunjukkan algoritma transfer gaya asli. Untuk aplikasi sederhana transfer gaya, lihat tutorial ini untuk mempelajari lebih lanjut tentang cara menggunakan model transfer gaya gambar arbitrer dari TensorFlow Hub .