
| | |  GitHub এ দেখুন GitHub এ দেখুন | | |
এই টিউটোরিয়ালটি একটি চিত্রকে অন্য চিত্রের শৈলীতে রচনা করার জন্য গভীর শিক্ষা ব্যবহার করে (কখনও যদি আপনি পিকাসো বা ভ্যান গগের মতো আঁকতে পারেন?) এটি নিউরাল স্টাইল ট্রান্সফার নামে পরিচিত এবং কৌশলটি শৈল্পিক শৈলীর একটি নিউরাল অ্যালগরিদমে (গ্যাটিস এট আল।) রূপরেখা দেওয়া হয়েছে।
স্টাইল ট্রান্সফারের একটি সহজ প্রয়োগের জন্য টেনসরফ্লো হাব থেকে কীভাবে পূর্বপ্রশিক্ষিত আরবিট্রারি ইমেজ স্টাইলাইজেশন মডেল বা টেনসরফ্লো লাইটের সাথে স্টাইল ট্রান্সফার মডেল কীভাবে ব্যবহার করবেন সে সম্পর্কে আরও জানতে এই টিউটোরিয়ালটি দেখুন।
নিউরাল স্টাইল ট্রান্সফার হল একটি অপ্টিমাইজেশান কৌশল যা দুটি ছবি তোলার জন্য ব্যবহৃত হয়—একটি বিষয়বস্তুর ছবি এবং একটি শৈলীর রেফারেন্স ইমেজ (যেমন একজন বিখ্যাত চিত্রশিল্পীর আর্টওয়ার্ক)-এবং সেগুলিকে একত্রে মিশ্রিত করা হয় যাতে আউটপুট ইমেজটি বিষয়বস্তুর ছবির মতো দেখায়, কিন্তু "আঁকা" শৈলী রেফারেন্স ইমেজ শৈলী মধ্যে.
বিষয়বস্তু চিত্রের বিষয়বস্তু পরিসংখ্যান এবং শৈলী রেফারেন্স চিত্রের শৈলী পরিসংখ্যানের সাথে মেলে আউটপুট চিত্রটিকে অপ্টিমাইজ করে এটি বাস্তবায়িত হয়। এই পরিসংখ্যান একটি convolutional নেটওয়ার্ক ব্যবহার করে ছবি থেকে বের করা হয়.
উদাহরণস্বরূপ, আসুন এই কুকুরটির একটি চিত্র এবং ওয়াসিলি ক্যান্ডিনস্কির রচনা 7 নেওয়া যাক:

ইয়েলো ল্যাব্রাডর লুকিং , উইকিমিডিয়া কমন্স থেকে এলফের লেখা । লাইসেন্স CC BY-SA 3.0
{kind=link}

এখন কেমন লাগবে যদি ক্যান্ডিনস্কি এই স্টাইল দিয়ে একচেটিয়াভাবে এই কুকুরের ছবি আঁকার সিদ্ধান্ত নেন? এটার মতো কিছু?

সেটআপ
মডিউল আমদানি এবং কনফিগার করুন
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
ইমেজ ডাউনলোড করুন এবং একটি শৈলী ইমেজ এবং একটি বিষয়বস্তু ইমেজ চয়ন করুন:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
ইনপুট কল্পনা করুন
একটি চিত্র লোড করার জন্য একটি ফাংশন সংজ্ঞায়িত করুন এবং এর সর্বাধিক মাত্রা 512 পিক্সেলের মধ্যে সীমাবদ্ধ করুন।
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
একটি চিত্র প্রদর্শন করার জন্য একটি সাধারণ ফাংশন তৈরি করুন:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

TF-হাব ব্যবহার করে দ্রুত শৈলী স্থানান্তর
এই টিউটোরিয়ালটি মূল স্টাইল-ট্রান্সফার অ্যালগরিদম প্রদর্শন করে, যা একটি নির্দিষ্ট শৈলীতে ছবির বিষয়বস্তুকে অপ্টিমাইজ করে। বিস্তারিত জানার আগে, আসুন টেনসরফ্লো হাব মডেলটি কীভাবে এটি করে তা দেখা যাক:
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
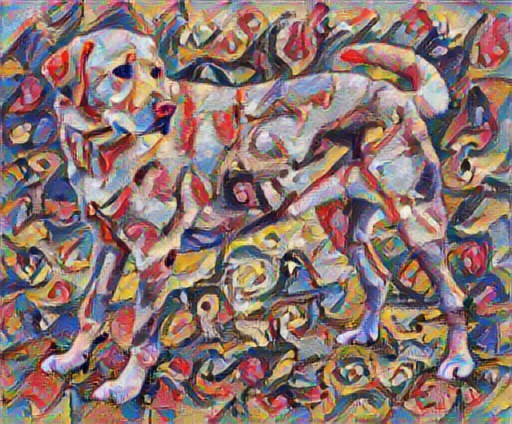
বিষয়বস্তু এবং শৈলী উপস্থাপনা সংজ্ঞায়িত করুন
ছবির বিষয়বস্তু এবং শৈলী উপস্থাপনা পেতে মডেলের মধ্যবর্তী স্তরগুলি ব্যবহার করুন৷ নেটওয়ার্কের ইনপুট স্তর থেকে শুরু করে, প্রথম কয়েকটি স্তর সক্রিয়করণ প্রান্ত এবং টেক্সচারের মতো নিম্ন-স্তরের বৈশিষ্ট্যগুলিকে উপস্থাপন করে। আপনি নেটওয়ার্কের মধ্য দিয়ে যাওয়ার সাথে সাথে, চূড়ান্ত কয়েকটি স্তর উচ্চ-স্তরের বৈশিষ্ট্যগুলিকে উপস্থাপন করে— চাকা বা চোখের মতো বস্তুর অংশগুলি। এই ক্ষেত্রে, আপনি VGG19 নেটওয়ার্ক আর্কিটেকচার ব্যবহার করছেন, একটি পূর্বপ্রশিক্ষিত চিত্র শ্রেণীবিভাগ নেটওয়ার্ক৷ এই মধ্যবর্তী স্তরগুলি চিত্রগুলি থেকে বিষয়বস্তু এবং শৈলীর উপস্থাপনা সংজ্ঞায়িত করার জন্য প্রয়োজনীয়। একটি ইনপুট চিত্রের জন্য, এই মধ্যবর্তী স্তরগুলিতে সংশ্লিষ্ট শৈলী এবং বিষয়বস্তু লক্ষ্য উপস্থাপনাগুলি মেলানোর চেষ্টা করুন৷
একটি VGG19 লোড করুন এবং এটি সঠিকভাবে ব্যবহার করা হয়েছে তা নিশ্চিত করতে এটিকে আমাদের ছবিতে চালান:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
এখন ক্লাসিফিকেশন হেড ছাড়াই একটি VGG19 লোড করুন এবং লেয়ারের নাম তালিকাভুক্ত করুন
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
ছবির শৈলী এবং বিষয়বস্তু উপস্থাপন করতে নেটওয়ার্ক থেকে মধ্যবর্তী স্তর নির্বাচন করুন:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
শৈলী এবং বিষয়বস্তুর জন্য মধ্যবর্তী স্তর
তাহলে কেন আমাদের পূর্বপ্রশিক্ষিত চিত্র শ্রেণীবিভাগ নেটওয়ার্কের মধ্যে এই মধ্যবর্তী আউটপুটগুলি আমাদের শৈলী এবং বিষয়বস্তু উপস্থাপনা সংজ্ঞায়িত করার অনুমতি দেয়?
একটি উচ্চ স্তরে, একটি নেটওয়ার্কের জন্য ইমেজ শ্রেণীবিভাগ (যা করার জন্য এই নেটওয়ার্ককে প্রশিক্ষিত করা হয়েছে) সঞ্চালনের জন্য, এটি অবশ্যই চিত্রটি বুঝতে হবে। এর জন্য কাঁচা ছবিকে ইনপুট পিক্সেল হিসাবে নেওয়া এবং একটি অভ্যন্তরীণ উপস্থাপনা তৈরি করতে হবে যা কাঁচা চিত্রের পিক্সেলগুলিকে চিত্রের মধ্যে উপস্থিত বৈশিষ্ট্যগুলির একটি জটিল বোঝার মধ্যে রূপান্তরিত করে।
এটিও একটি কারণ যে কনভোল্যুশনাল নিউরাল নেটওয়ার্কগুলি ভালভাবে সাধারণীকরণ করতে সক্ষম হয়: তারা ক্লাসের মধ্যে (যেমন বিড়াল বনাম কুকুর) অভ্যন্তরীণ বৈশিষ্ট্যগুলি ক্যাপচার করতে সক্ষম হয় যা পটভূমির শব্দ এবং অন্যান্য উপদ্রবগুলির জন্য অজ্ঞেয়বাদী। এইভাবে, মডেল এবং আউটপুট শ্রেণীবিভাগ লেবেলের মধ্যে যেখানে কাঁচা চিত্র দেওয়া হয়, মডেলটি একটি জটিল বৈশিষ্ট্য নিষ্কাশনকারী হিসাবে কাজ করে। মডেলের মধ্যবর্তী স্তরগুলি অ্যাক্সেস করে, আপনি ইনপুট চিত্রগুলির বিষয়বস্তু এবং শৈলী বর্ণনা করতে সক্ষম হন৷
মডেল তৈরি করুন
tf.keras.applications এর নেটওয়ার্কগুলি ডিজাইন করা হয়েছে যাতে আপনি Keras কার্যকরী API ব্যবহার করে সহজেই মধ্যবর্তী স্তরের মানগুলি বের করতে পারেন।
কার্যকরী API ব্যবহার করে একটি মডেল সংজ্ঞায়িত করতে, ইনপুট এবং আউটপুটগুলি নির্দিষ্ট করুন:
model = Model(inputs, outputs)
এই নিম্নলিখিত ফাংশনটি একটি VGG19 মডেল তৈরি করে যা মধ্যবর্তী স্তর আউটপুটগুলির একটি তালিকা প্রদান করে:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
এবং মডেল তৈরি করতে:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
শৈলী গণনা
একটি চিত্রের বিষয়বস্তু মধ্যবর্তী বৈশিষ্ট্য মানচিত্রের মান দ্বারা প্রতিনিধিত্ব করা হয়।
এটি সক্রিয় আউট, একটি চিত্রের শৈলী বিভিন্ন বৈশিষ্ট্য মানচিত্র জুড়ে উপায় এবং পারস্পরিক সম্পর্ক দ্বারা বর্ণনা করা যেতে পারে. একটি গ্রাম ম্যাট্রিক্স গণনা করুন যা প্রতিটি অবস্থানে বৈশিষ্ট্য ভেক্টরের বাইরের পণ্যটি নিজের সাথে নিয়ে এবং সমস্ত অবস্থানে সেই বাইরের পণ্যের গড় করে এই তথ্যটি অন্তর্ভুক্ত করে। এই গ্রাম ম্যাট্রিক্স একটি নির্দিষ্ট স্তরের জন্য গণনা করা যেতে পারে যেমন:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
এটি tf.linalg.einsum ফাংশন ব্যবহার করে সংক্ষিপ্তভাবে প্রয়োগ করা যেতে পারে:
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
শৈলী এবং বিষয়বস্তু নির্যাস
একটি মডেল তৈরি করুন যা শৈলী এবং বিষয়বস্তু টেনসর প্রদান করে।
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
যখন একটি ইমেজ কল করা হয়, তখন এই মডেলটি style_layers গ্রাম ম্যাট্রিক্স (স্টাইল) এবং content_layers এর বিষয়বস্তু প্রদান করে:
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
গ্রেডিয়েন্ট ডিসেন্ট চালান
এই স্টাইল এবং কন্টেন্ট এক্সট্র্যাক্টর দিয়ে, আপনি এখন স্টাইল ট্রান্সফার অ্যালগরিদম বাস্তবায়ন করতে পারেন। প্রতিটি টার্গেটের সাপেক্ষে আপনার ছবির আউটপুটের গড় বর্গাকার ত্রুটি গণনা করে এটি করুন, তারপর এই ক্ষতিগুলির ওজনযুক্ত যোগফল নিন।
আপনার শৈলী এবং বিষয়বস্তু লক্ষ্য মান সেট করুন:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
অপ্টিমাইজ করার জন্য ইমেজ ধারণ করার জন্য একটি tf.Variable সংজ্ঞায়িত করুন। এটি দ্রুত করতে, বিষয়বস্তু চিত্রের সাথে এটি শুরু করুন ( tf.Variable . পরিবর্তনশীল অবশ্যই সামগ্রী চিত্রের মতো একই আকারের হতে হবে):
image = tf.Variable(content_image)
যেহেতু এটি একটি ফ্লোট ইমেজ, পিক্সেল মান 0 এবং 1 এর মধ্যে রাখতে একটি ফাংশন সংজ্ঞায়িত করুন:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
একটি অপ্টিমাইজার তৈরি করুন। কাগজটি এলবিএফজিএস সুপারিশ করে, কিন্তু Adam ঠিক কাজ করে:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
এটি অপ্টিমাইজ করতে, মোট ক্ষতি পেতে দুটি ক্ষতির একটি ওজনযুক্ত সমন্বয় ব্যবহার করুন:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
ইমেজ আপডেট করতে tf.GradientTape ব্যবহার করুন।
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
এখন পরীক্ষা করার জন্য কয়েকটি ধাপ চালান:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

যেহেতু এটি কাজ করছে, একটি দীর্ঘ অপ্টিমাইজেশান সঞ্চালন করুন:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
মোট প্রকরণ ক্ষতি
এই মৌলিক বাস্তবায়নের একটি নেতিবাচক দিক হল এটি প্রচুর উচ্চ ফ্রিকোয়েন্সি আর্টিফ্যাক্ট তৈরি করে। চিত্রের উচ্চ ফ্রিকোয়েন্সি উপাদানগুলিতে একটি সুস্পষ্ট নিয়মিতকরণ শব্দ ব্যবহার করে এগুলি হ্রাস করুন৷ শৈলী স্থানান্তরে, এটিকে প্রায়শই মোট প্রকরণ ক্ষতি বলা হয়:
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
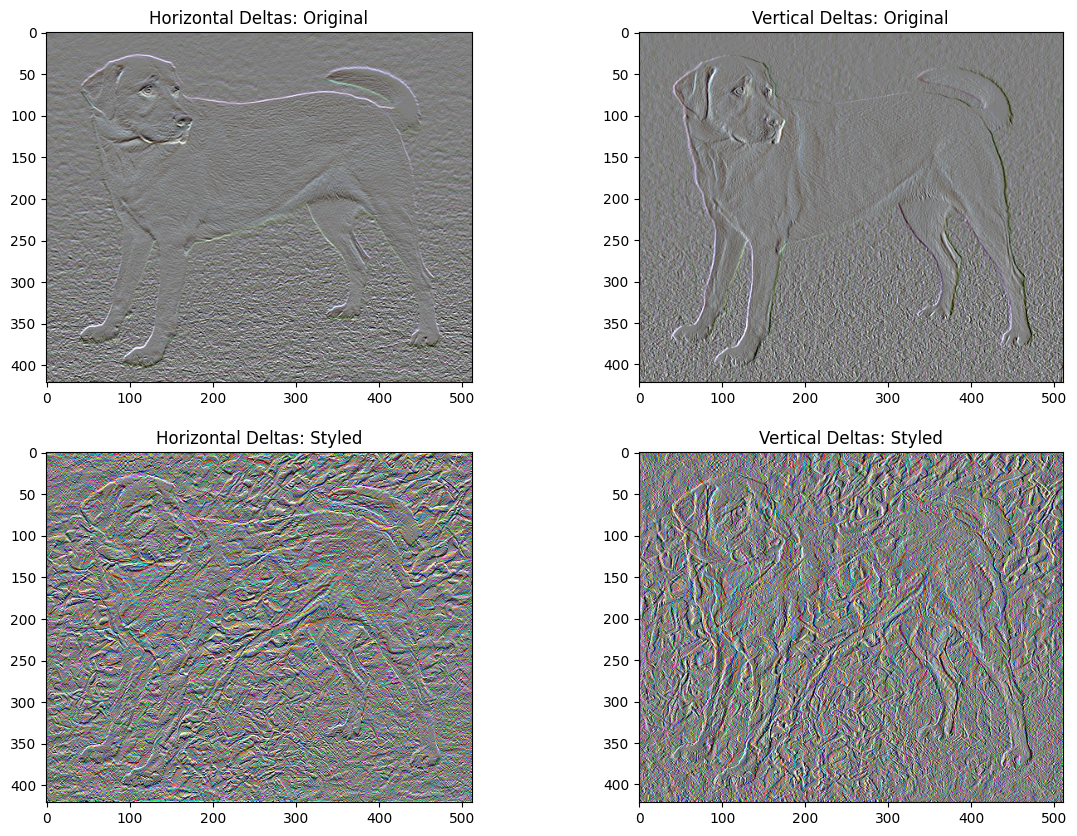
এটি দেখায় কিভাবে উচ্চ ফ্রিকোয়েন্সি উপাদান বৃদ্ধি পেয়েছে।
এছাড়াও, এই উচ্চ ফ্রিকোয়েন্সি উপাদানটি মূলত একটি প্রান্ত সনাক্তকারী। আপনি Sobel প্রান্ত আবিষ্কারক থেকে অনুরূপ আউটপুট পেতে পারেন, উদাহরণস্বরূপ:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
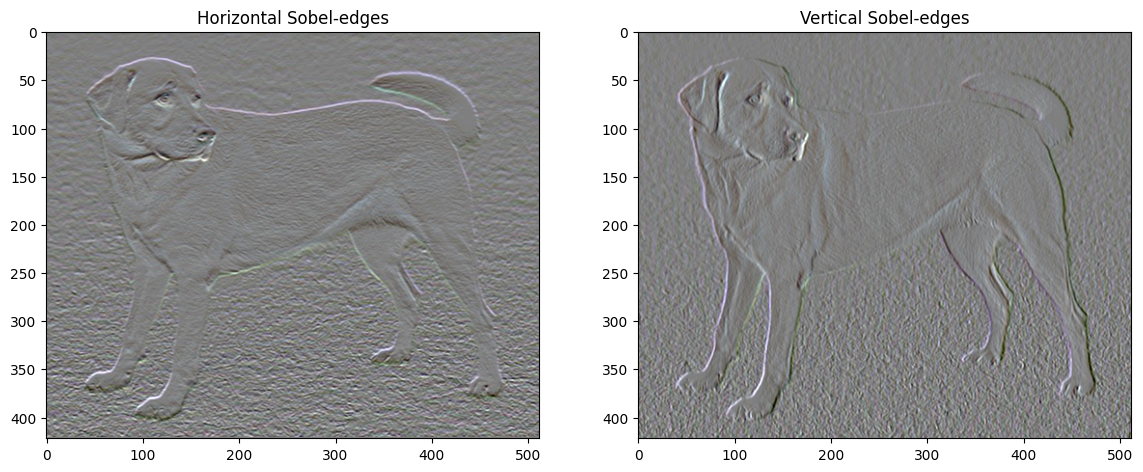
এর সাথে সম্পর্কিত নিয়মিতকরণ ক্ষতি হল মানের বর্গক্ষেত্রের সমষ্টি:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
যে এটা কি প্রমান. তবে এটি নিজে বাস্তবায়ন করার দরকার নেই, টেনসরফ্লোতে একটি আদর্শ বাস্তবায়ন অন্তর্ভুক্ত রয়েছে:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
অপ্টিমাইজেশান পুনরায় চালান
total_variation_loss জন্য একটি ওজন চয়ন করুন:
total_variation_weight=30
এখন train_step ফাংশনে এটি অন্তর্ভুক্ত করুন:
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
অপ্টিমাইজেশন ভেরিয়েবল পুনরায় চালু করুন:
image = tf.Variable(content_image)
এবং অপ্টিমাইজেশান চালান:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
অবশেষে, ফলাফল সংরক্ষণ করুন:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
আরও জানুন
এই টিউটোরিয়ালটি মূল স্টাইল-ট্রান্সফার অ্যালগরিদম প্রদর্শন করে। শৈলী স্থানান্তরের একটি সহজ প্রয়োগের জন্য TensorFlow Hub থেকে নির্বিচারে চিত্র শৈলী স্থানান্তর মডেলটি কীভাবে ব্যবহার করবেন সে সম্পর্কে আরও জানতে এই টিউটোরিয়ালটি দেখুন।