
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה מדגים אימון של רשת עצבית קונבולוציונית פשוטה (CNN) לסיווג תמונות CIFAR . מכיוון שמדריך זה משתמש ב- Keras Sequential API , יצירה והדרכה של המודל שלך ידרשו רק כמה שורות קוד.
ייבוא TensorFlow
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
הורד והכן את מערך הנתונים של CIFAR10
מערך הנתונים של CIFAR10 מכיל 60,000 תמונות צבע ב-10 מחלקות, עם 6,000 תמונות בכל מחלקה. מערך הנתונים מחולק ל-50,000 תמונות אימון ו-10,000 תמונות בדיקה. השיעורים סותרים זה את זה ואין חפיפה ביניהם.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step 170508288/170498071 [==============================] - 11s 0us/step
אמת את הנתונים
כדי לוודא שמערך הנתונים נראה תקין, בואו נשרטט את 25 התמונות הראשונות ממערך ההדרכה ונציג את שם הכיתה מתחת לכל תמונה:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

צור את הבסיס הקונבולוציוני
6 שורות הקוד שלהלן מגדירות את הבסיס הקונבולוציוני באמצעות דפוס משותף: ערימה של שכבות Conv2D ו- MaxPooling2D .
כקלט, CNN מקבל טנסורים של צורה (גובה_תמונה, רוחב_תמונה, ערוצי_צבע), תוך התעלמות מגודל האצווה. אם אתה חדש בממדים האלה, color_channels מתייחס ל-(R,G,B). בדוגמה זו, תגדיר את ה-CNN שלך לעיבוד קלט של צורה (32, 32, 3), שהוא הפורמט של תמונות CIFAR. אתה יכול לעשות זאת על ידי העברת הארגומנט input_shape לשכבה הראשונה שלך.
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
בוא נציג את הארכיטקטורה של המודל שלך עד כה:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
למעלה, אתה יכול לראות שהפלט של כל שכבת Conv2D ו-MaxPooling2D הוא טנזור תלת מימדי של צורה (גובה, רוחב, ערוצים). מידות הרוחב והגובה נוטות להתכווץ ככל שמתעמקים ברשת. מספר ערוצי הפלט עבור כל שכבת Conv2D נשלט על ידי הארגומנט הראשון (למשל, 32 או 64). בדרך כלל, ככל שהרוחב והגובה מתכווצים, אתה יכול להרשות לעצמך (מבחינה חישובית) להוסיף עוד ערוצי פלט בכל שכבת Conv2D.
הוסף שכבות צפופות מעל
כדי להשלים את המודל, תזין את טנזור הפלט האחרון מבסיס הפיתול (של הצורה (4, 4, 64)) לשכבה אחת או יותר צפופה כדי לבצע סיווג. שכבות צפופות לוקחות וקטורים כקלט (שהם 1D), בעוד שהפלט הנוכחי הוא טנזור תלת מימדי. ראשית, תשטח (או תפתח) את פלט התלת-ממד ל-1D, ולאחר מכן תוסיף שכבה אחת או יותר צפופה למעלה. ל-CIFAR יש 10 מחלקות פלט, אז אתה משתמש בשכבת צפופה סופית עם 10 פלטים.
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
הנה הארכיטקטורה המלאה של הדגם שלך:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
סיכום הרשת מראה כי (4, 4, 64) פלטים הושטחו לוקטורים של צורה (1024) לפני שעברו שתי שכבות צפופות.
הרכיבו והכשירו את המודל
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
Epoch 1/10 1563/1563 [==============================] - 8s 4ms/step - loss: 1.4971 - accuracy: 0.4553 - val_loss: 1.2659 - val_accuracy: 0.5492 Epoch 2/10 1563/1563 [==============================] - 6s 4ms/step - loss: 1.1424 - accuracy: 0.5966 - val_loss: 1.1025 - val_accuracy: 0.6098 Epoch 3/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.9885 - accuracy: 0.6539 - val_loss: 0.9557 - val_accuracy: 0.6629 Epoch 4/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8932 - accuracy: 0.6878 - val_loss: 0.8924 - val_accuracy: 0.6935 Epoch 5/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8222 - accuracy: 0.7130 - val_loss: 0.8679 - val_accuracy: 0.7025 Epoch 6/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7663 - accuracy: 0.7323 - val_loss: 0.9336 - val_accuracy: 0.6819 Epoch 7/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7224 - accuracy: 0.7466 - val_loss: 0.8546 - val_accuracy: 0.7086 Epoch 8/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6726 - accuracy: 0.7611 - val_loss: 0.8777 - val_accuracy: 0.7068 Epoch 9/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6372 - accuracy: 0.7760 - val_loss: 0.8410 - val_accuracy: 0.7179 Epoch 10/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6024 - accuracy: 0.7875 - val_loss: 0.8475 - val_accuracy: 0.7192
העריכו את המודל
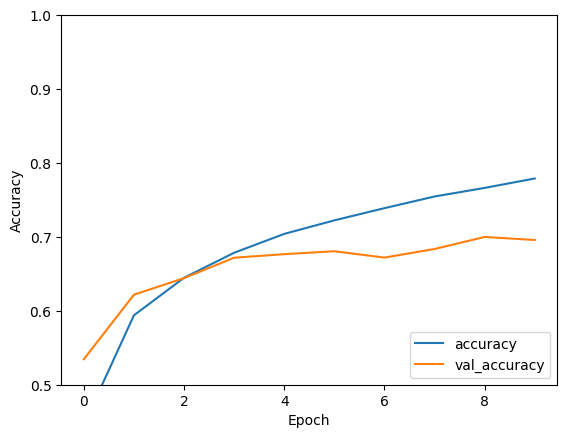
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 0.8475 - accuracy: 0.7192 - 634ms/epoch - 2ms/step
print(test_acc)
0.7192000150680542
CNN הפשוט שלך השיג דיוק בדיקה של למעלה מ-70%. לא רע עבור כמה שורות קוד! לסגנון אחר של CNN, בדוק את הדוגמה המהירה של TensorFlow 2 למומחים המשתמשת ב-Keras subclass API ו- tf.GradientTape .