
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
บทช่วยสอนนี้เน้นที่งานการแบ่งส่วนรูปภาพโดยใช้ U-Net ที่แก้ไข
การแบ่งส่วนภาพคืออะไร?
ในงานจำแนกรูปภาพ เครือข่ายกำหนดป้ายกำกับ (หรือคลาส) ให้กับรูปภาพอินพุตแต่ละรูป อย่างไรก็ตาม สมมติว่าคุณต้องการทราบรูปร่างของวัตถุนั้น พิกเซลใดเป็นของวัตถุใด ฯลฯ ในกรณีนี้ คุณจะต้องกำหนดคลาสให้กับแต่ละพิกเซลของรูปภาพ งานนี้เรียกว่าการแบ่งส่วน โมเดลการแบ่งกลุ่มจะส่งกลับข้อมูลที่มีรายละเอียดมากขึ้นเกี่ยวกับรูปภาพ การแบ่งส่วนรูปภาพมีการใช้งานมากมายในการถ่ายภาพทางการแพทย์ รถยนต์ที่ขับด้วยตนเอง และภาพถ่ายดาวเทียม เป็นต้น
บทช่วยสอนนี้ใช้ ชุดข้อมูลสัตว์เลี้ยงของ Oxford-IIIT ( Parkhi et al, 2012 ) ชุดข้อมูลประกอบด้วยภาพสัตว์เลี้ยง 37 สายพันธุ์ โดยมี 200 ภาพต่อสายพันธุ์ (ประมาณ 100 ภาพในการฝึกและแยกการทดสอบ) แต่ละภาพมีป้ายกำกับที่เกี่ยวข้องและมาสก์ที่ชาญฉลาด มาสก์เป็นป้ายกำกับระดับสำหรับแต่ละพิกเซล แต่ละพิกเซลจะได้รับหนึ่งในสามหมวดหมู่:
- คลาส 1: Pixel ที่เป็นของสัตว์เลี้ยง
- ระดับ 2: พิกเซลที่มีพรมแดนติดกับสัตว์เลี้ยง
- ชั้น 3: ไม่มีด้านบน/พิกเซลโดยรอบ
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
ดาวน์โหลดชุดข้อมูล Oxford-IIIT Pets
ชุดข้อมูล พร้อมใช้งานจาก TensorFlow Datasets มาสก์การแบ่งส่วนจะรวมอยู่ในเวอร์ชัน 3+
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
นอกจากนี้ ค่าสีของภาพจะถูกปรับให้เป็นมาตรฐานในช่วง [0,1] สุดท้าย ตามที่กล่าวไว้ข้างต้น พิกเซลในมาสก์การแบ่งส่วนจะมีป้ายกำกับว่า {1, 2, 3} เพื่อความสะดวก ให้ลบ 1 ออกจากมาสก์การแบ่งส่วน ส่งผลให้ป้ายกำกับคือ: {0, 1, 2}
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
ชุดข้อมูลมีการแยกการฝึกและการทดสอบที่จำเป็นอยู่แล้ว ดังนั้นให้ใช้การแยกเดียวกันต่อไป
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
คลาสต่อไปนี้ดำเนินการเสริมอย่างง่ายโดยสุ่มพลิกรูปภาพ ไปที่บทแนะนำ การเสริมรูปภาพ เพื่อเรียนรู้เพิ่มเติม
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
สร้างไพพ์ไลน์อินพุต ใช้ Augmentation หลังจากแบทช์อินพุต
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
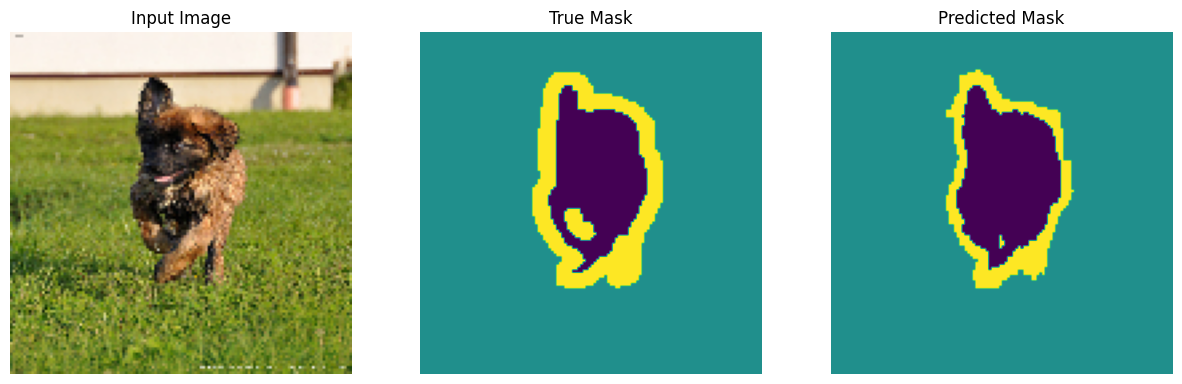
เห็นภาพตัวอย่างและมาสก์ที่เกี่ยวข้องจากชุดข้อมูล
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
กำหนดรูปแบบ
โมเดลที่ใช้ในที่นี้คือ U-Net ที่ดัดแปลง U-Net ประกอบด้วยตัวเข้ารหัส (ตัวสุ่มตัวอย่าง) และตัวถอดรหัส (ตัวขยายสัญญาณ) เพื่อที่จะเรียนรู้คุณลักษณะที่มีประสิทธิภาพและลดจำนวนพารามิเตอร์ที่ฝึกได้ คุณจะต้องใช้โมเดลที่ได้รับการฝึกอบรมล่วงหน้า - MobileNetV2 - เป็นตัวเข้ารหัส สำหรับตัวถอดรหัส คุณจะใช้บล็อกตัวอย่างซึ่งมีการใช้งานแล้วในตัวอย่าง pix2pix ใน repo ตัวอย่าง TensorFlow (ตรวจสอบ pix2pix: การแปลรูปภาพเป็นรูปภาพด้วยบทช่วยสอน GAN แบบมีเงื่อนไข ในสมุดบันทึก)
ดังที่กล่าวไว้ ตัวเข้ารหัสจะเป็นโมเดล MobileNetV2 ที่ผ่านการฝึกอบรมล่วงหน้า ซึ่งได้รับการจัดเตรียมและพร้อมใช้งานใน tf.keras.applications ตัวเข้ารหัสประกอบด้วยเอาต์พุตเฉพาะจากเลเยอร์ระดับกลางในโมเดล โปรดทราบว่าตัวเข้ารหัสจะไม่ได้รับการฝึกอบรมในระหว่างกระบวนการฝึกอบรม
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
ตัวถอดรหัส/ตัวขยายสัญญาณเป็นเพียงชุดของบล็อกตัวอย่างที่นำมาใช้ในตัวอย่าง TensorFlow
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
โปรดทราบว่าจำนวนตัวกรองในเลเยอร์สุดท้ายถูกกำหนดเป็นจำนวน output_channels นี่จะเป็นช่องสัญญาณออกหนึ่งช่องต่อคลาส
ฝึกโมเดล
ตอนนี้ ที่เหลือก็แค่คอมไพล์และฝึกโมเดล
เนื่องจากนี่เป็นปัญหาการจำแนกประเภทหลายคลาส ให้ใช้ฟังก์ชันการสูญเสีย tf.keras.losses.CategoricalCrossentropy โดยตั้งค่าอาร์กิวเมนต์ from_logits เป็น True เนื่องจากป้ายกำกับเป็นจำนวนเต็มสเกลาร์แทนที่จะเป็นเวกเตอร์ของคะแนนสำหรับแต่ละพิกเซลของทุกคลาส
เมื่อทำการอนุมาน ป้ายกำกับที่กำหนดให้กับพิกเซลคือแชนเนลที่มีค่าสูงสุด นี่คือสิ่งที่ฟังก์ชัน create_mask กำลังทำ
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
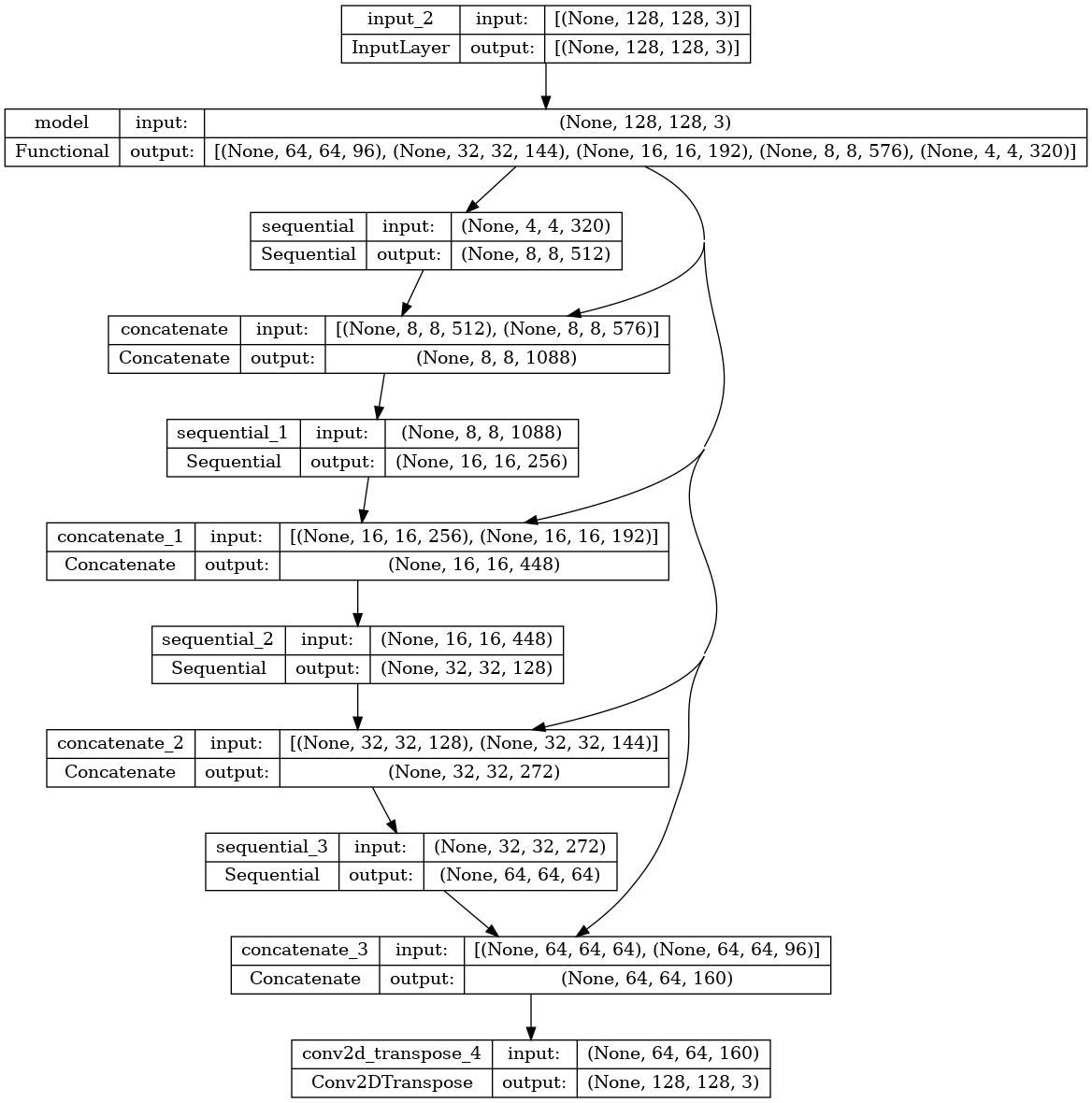
ดูสถาปัตยกรรมแบบจำลองที่เกิดขึ้นอย่างรวดเร็ว:
tf.keras.utils.plot_model(model, show_shapes=True)
ลองใช้แบบจำลองเพื่อตรวจสอบสิ่งที่คาดการณ์ก่อนการฝึก
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

การเรียกกลับที่กำหนดไว้ด้านล่างใช้เพื่อสังเกตว่าโมเดลมีการปรับปรุงอย่างไรในขณะที่กำลังฝึก
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
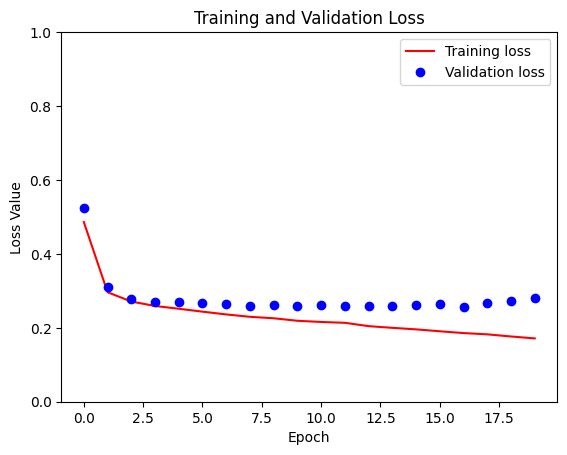
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
ทำนายฝัน
งั้นทำนายหน่อย เพื่อประโยชน์ในการประหยัดเวลา จำนวนยุคจึงมีขนาดเล็ก แต่คุณอาจตั้งค่าให้สูงขึ้นเพื่อให้ได้ผลลัพธ์ที่แม่นยำยิ่งขึ้น
show_predictions(test_batches, 3)


ทางเลือก: คลาสไม่สมดุลและตุ้มน้ำหนักคลาส
ชุดข้อมูลการแบ่งเซ็กเมนต์เชิงความหมายอาจมีความไม่สมดุลสูง หมายความว่าพิกเซลของคลาสเฉพาะสามารถแสดงภายในรูปภาพได้มากกว่าคลาสอื่นๆ เนื่องจากปัญหาการแบ่งส่วนสามารถถือเป็นปัญหาการจำแนกประเภทต่อพิกเซล คุณจึงสามารถจัดการกับปัญหาความไม่สมดุลได้โดยการชั่งน้ำหนักฟังก์ชันการสูญเสียเพื่อพิจารณาเรื่องนี้ เป็นวิธีที่ง่ายและสง่างามในการจัดการกับปัญหานี้ ดูบทแนะนำการ จัดหมวดหมู่ข้อมูลที่ไม่สมดุล เพื่อเรียนรู้เพิ่มเติม
เพื่อ หลีกเลี่ยงความกำกวม Model.fit ไม่สนับสนุนอาร์กิวเมนต์ class_weight สำหรับอินพุตที่มีมิติ 3+
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
ดังนั้น ในกรณีนี้ คุณต้องทำการชั่งน้ำหนักด้วยตัวเอง คุณจะทำได้โดยใช้น้ำหนักตัวอย่าง: นอกเหนือจากคู่ (data, label) แล้ว Model.fit ยังยอมรับ (data, label, sample_weight) สามเท่าด้วย
Model.fit เผยแพร่ sample_weight ไปยังการสูญเสียและหน่วยเมตริก ซึ่งยอมรับอาร์กิวเมนต์ sample_weight ด้วย น้ำหนักตัวอย่างจะถูกคูณด้วยค่าของตัวอย่างก่อนขั้นตอนการลดขนาด ตัวอย่างเช่น:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)ตัวยึดตำแหน่ง32
ดังนั้น ในการสร้างน้ำหนักตัวอย่างสำหรับบทช่วยสอนนี้ คุณต้องมีฟังก์ชันที่ใช้คู่ (data, label) และส่งกลับค่า (data, label, sample_weight) สามเท่า โดยที่ sample_weight คือรูปภาพ 1 ช่องที่มีน้ำหนักคลาสสำหรับแต่ละพิกเซล
การใช้งานที่ง่ายที่สุดที่เป็นไปได้คือการใช้ป้ายกำกับเป็นดัชนีในรายการ class_weight :
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
องค์ประกอบชุดข้อมูลที่เป็นผลลัพธ์ประกอบด้วย 3 ภาพแต่ละภาพ:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
ตอนนี้คุณสามารถฝึกแบบจำลองบนชุดข้อมูลแบบถ่วงน้ำหนักนี้:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
ขั้นตอนถัดไป
เมื่อคุณเข้าใจแล้วว่าการแบ่งส่วนรูปภาพคืออะไรและทำงานอย่างไร คุณสามารถลองใช้บทช่วยสอนนี้กับเอาต์พุตเลเยอร์กลางต่างๆ หรือแม้แต่โมเดลที่ได้รับการฝึกล่วงหน้าที่แตกต่างกัน คุณอาจท้าทายตัวเองด้วยการลองความท้าทายในการปิดบังรูปภาพของ Carvana ที่โฮสต์บน Kaggle
คุณอาจต้องการดู Tensorflow Object Detection API สำหรับโมเดลอื่นที่คุณสามารถฝึกข้อมูลของคุณเองได้ โมเดลที่ได้รับการฝึกอบรมล่วงหน้ามีอยู่ใน TensorFlow Hub