
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Her zaman olduğu gibi, bu örnekteki kod, TensorFlow Keras kılavuzunda daha fazla bilgi edinebileceğiniz tf.keras API'sini kullanacaktır.
Önceki örneklerin her ikisinde de - metni sınıflandırma ve yakıt verimliliğini tahmin etme - modelimizin doğrulama verileri üzerindeki doğruluğunun, birkaç dönem boyunca eğitimden sonra zirveye çıkacağını ve ardından durgunlaşacağını veya azalmaya başlayacağını gördük.
Başka bir deyişle, modelimiz eğitim verilerine fazla sığar. Aşırı uyum ile nasıl başa çıkılacağını öğrenmek önemlidir. Eğitim setinde yüksek doğruluk elde etmek çoğu zaman mümkün olsa da, gerçekten istediğimiz şey, bir test setine (veya daha önce görmedikleri verilere) iyi genelleme yapan modeller geliştirmektir.
Fazla takmanın tersi eksik takmadır . Yetersiz donatım, tren verilerinde hala iyileştirme için yer olduğunda meydana gelir. Bunun birkaç nedeni olabilir: Model yeterince güçlü değilse, aşırı düzenliyse veya yeterince uzun süre eğitilmediyse. Bu, ağın eğitim verilerindeki ilgili kalıpları öğrenmediği anlamına gelir.
Yine de çok uzun süre antrenman yaparsanız, model fazla uymaya başlayacak ve eğitim verilerinden test verilerine genellemeyen kalıpları öğrenecektir. Bir denge kurmamız gerekiyor. Aşağıda inceleyeceğimiz gibi, uygun sayıda çağ için nasıl eğitileceğini anlamak faydalı bir beceridir.
Fazla takmayı önlemek için en iyi çözüm, daha eksiksiz eğitim verileri kullanmaktır. Veri kümesi, modelin işlemesi beklenen tüm girdi aralığını kapsamalıdır. Ek veriler yalnızca yeni ve ilginç durumları kapsıyorsa faydalı olabilir.
Daha eksiksiz veriler üzerinde eğitilmiş bir model, doğal olarak daha iyi genelleşecektir. Bu artık mümkün olmadığında, bir sonraki en iyi çözüm, düzenleme gibi teknikleri kullanmaktır. Bunlar, modelinizin saklayabileceği bilgilerin miktarı ve türü üzerinde kısıtlamalar getirir. Bir ağ yalnızca az sayıda kalıbı ezberleyebiliyorsa, optimizasyon süreci onu daha iyi genelleme şansı olan en belirgin kalıplara odaklanmaya zorlayacaktır.
Bu not defterinde, birkaç yaygın düzenleme tekniğini keşfedeceğiz ve bunları bir sınıflandırma modelini geliştirmek için kullanacağız.
Kurmak
Başlamadan önce gerekli paketleri içe aktarın:
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import regularizers
print(tf.__version__)
2.8.0-rc1
!pip install git+https://github.com/tensorflow/docs
import tensorflow_docs as tfdocs
import tensorflow_docs.modeling
import tensorflow_docs.plots
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import pathlib
import shutil
import tempfile
logdir = pathlib.Path(tempfile.mkdtemp())/"tensorboard_logs"
shutil.rmtree(logdir, ignore_errors=True)
Higgs Veri Kümesi
Bu öğreticinin amacı parçacık fiziği yapmak değildir, bu nedenle veri kümesinin ayrıntıları üzerinde durmayın. Her biri 28 özelliğe sahip 11.000 000 örnek ve bir ikili sınıf etiketi içerir.
gz = tf.keras.utils.get_file('HIGGS.csv.gz', 'http://mlphysics.ics.uci.edu/data/higgs/HIGGS.csv.gz')
Downloading data from http://mlphysics.ics.uci.edu/data/higgs/HIGGS.csv.gz 2816409600/2816407858 [==============================] - 123s 0us/step 2816417792/2816407858 [==============================] - 123s 0us/step-yer tutucu7 l10n-yer
FEATURES = 28
tf.data.experimental.CsvDataset sınıfı, ara açma adımı olmadan doğrudan bir gzip dosyasından csv kayıtlarını okumak için kullanılabilir.
ds = tf.data.experimental.CsvDataset(gz,[float(),]*(FEATURES+1), compression_type="GZIP")
Bu csv okuyucu sınıfı, her kayıt için bir skaler listesi döndürür. Aşağıdaki işlev, bu skaler listesini bir (özellik_vektörü, etiket) çifti halinde yeniden paketler.
def pack_row(*row):
label = row[0]
features = tf.stack(row[1:],1)
return features, label
TensorFlow, büyük veri yığınları üzerinde çalışırken en verimlidir.
Bu nedenle, her satırı ayrı ayrı yeniden paketlemek yerine, 10000 örneklik toplu iş alan, her toplu iş için pack_row işlevini uygulayan ve ardından grupları ayrı ayrı kayıtlara bölen yeni bir Dataset oluşturun:
packed_ds = ds.batch(10000).map(pack_row).unbatch()
Bu yeni packed_ds bazı kayıtlara bir göz atın.
Özellikler tam olarak normalleştirilmemiştir, ancak bu eğitim için bu yeterlidir.
for features,label in packed_ds.batch(1000).take(1):
print(features[0])
plt.hist(features.numpy().flatten(), bins = 101)
tf.Tensor( [ 0.8692932 -0.6350818 0.22569026 0.32747006 -0.6899932 0.75420225 -0.24857314 -1.0920639 0. 1.3749921 -0.6536742 0.9303491 1.1074361 1.1389043 -1.5781983 -1.0469854 0. 0.65792954 -0.01045457 -0.04576717 3.1019614 1.35376 0.9795631 0.97807616 0.92000484 0.72165745 0.98875093 0.87667835], shape=(28,), dtype=float32)
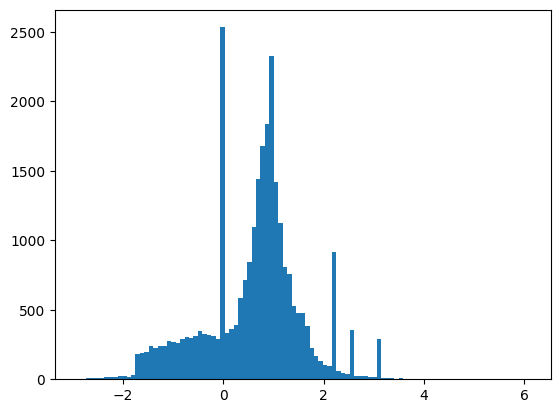
Bu öğreticiyi nispeten kısa tutmak için doğrulama için yalnızca ilk 1000 örneği ve eğitim için sonraki 10.000 örneği kullanın:
N_VALIDATION = int(1e3)
N_TRAIN = int(1e4)
BUFFER_SIZE = int(1e4)
BATCH_SIZE = 500
STEPS_PER_EPOCH = N_TRAIN//BATCH_SIZE
Dataset.skip ve Dataset.take yöntemleri bunu kolaylaştırır.
Aynı zamanda, yükleyicinin her çağda dosyadaki verileri yeniden okumasına gerek kalmamasını sağlamak için Dataset.cache yöntemini kullanın:
validate_ds = packed_ds.take(N_VALIDATION).cache()
train_ds = packed_ds.skip(N_VALIDATION).take(N_TRAIN).cache()
train_ds
<CacheDataset element_spec=(TensorSpec(shape=(28,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.float32, name=None))>
Bu veri kümeleri tek tek örnekler döndürür. Eğitim için uygun boyutta gruplar oluşturmak için .batch yöntemini kullanın. Gruplamadan önce, eğitim setini .shuffle ve .repeat etmeyi de unutmayın.
validate_ds = validate_ds.batch(BATCH_SIZE)
train_ds = train_ds.shuffle(BUFFER_SIZE).repeat().batch(BATCH_SIZE)
Fazla takmayı göster
Fazla takmayı önlemenin en basit yolu, küçük bir modelle başlamaktır: Az sayıda öğrenilebilir parametreye sahip bir model (katman sayısı ve katman başına birim sayısı ile belirlenir). Derin öğrenmede, bir modeldeki öğrenilebilir parametrelerin sayısı genellikle modelin "kapasitesi" olarak adlandırılır.
Sezgisel olarak, daha fazla parametreye sahip bir model daha fazla "ezberleme kapasitesine" sahip olacak ve bu nedenle eğitim örnekleri ve hedefleri arasında mükemmel bir sözlük benzeri eşleştirmeyi, herhangi bir genelleme gücü olmayan bir eşleştirmeyi kolayca öğrenebilecek, ancak bu, tahmin yaparken işe yaramaz olacaktır. Daha önce görülmemiş verilerde.
Bunu her zaman aklınızda bulundurun: derin öğrenme modelleri eğitim verilerine uyma konusunda iyi olma eğilimindedir, ancak asıl zorluk genellemedir, uydurma değil.
Öte yandan, ağın ezberleme kaynakları sınırlıysa, haritalamayı o kadar kolay öğrenemeyecektir. Kaybını en aza indirmek için, daha fazla tahmin gücüne sahip sıkıştırılmış temsilleri öğrenmesi gerekecektir. Aynı zamanda modelinizi çok küçük yaparsanız eğitim verilerine uyum sağlamakta zorlanacaktır. "Çok fazla kapasite" ile "yetersiz kapasite" arasında bir denge vardır.
Ne yazık ki, modelinizin doğru boyutunu veya mimarisini (katman sayısı veya her katman için doğru boyut açısından) belirlemek için sihirli bir formül yoktur. Bir dizi farklı mimariyi kullanarak deneme yapmanız gerekecek.
Uygun bir model boyutu bulmak için, nispeten az sayıda katman ve parametreyle başlamak, ardından doğrulama kaybında azalan getiriler görene kadar katmanların boyutunu artırmaya veya yeni katmanlar eklemeye başlamak en iyisidir.
Temel olarak yalnızca layers.Dense kullanan basit bir modelle başlayın, ardından daha büyük sürümler oluşturun ve bunları karşılaştırın.
Eğitim prosedürü
Eğitim sırasında öğrenme oranını kademeli olarak azaltırsanız birçok model daha iyi çalışır. Zamanla öğrenme oranını azaltmak için optimizers.schedules kullanın:
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
0.001,
decay_steps=STEPS_PER_EPOCH*1000,
decay_rate=1,
staircase=False)
def get_optimizer():
return tf.keras.optimizers.Adam(lr_schedule)
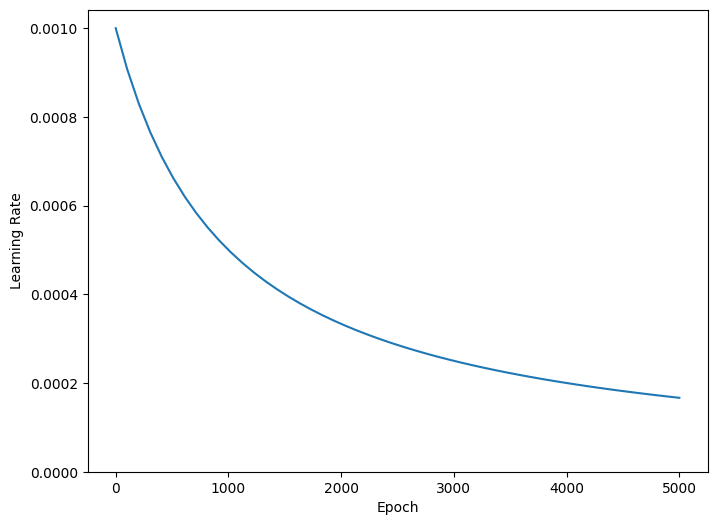
Yukarıdaki kod, öğrenme oranını 1000 çağda temel hızın 1/2'sine, 2000 çağda 1/3'üne vb. hiperbolik olarak düşürmek için bir schedules.InverseTimeDecay belirler.
step = np.linspace(0,100000)
lr = lr_schedule(step)
plt.figure(figsize = (8,6))
plt.plot(step/STEPS_PER_EPOCH, lr)
plt.ylim([0,max(plt.ylim())])
plt.xlabel('Epoch')
_ = plt.ylabel('Learning Rate')
Bu öğreticideki her model aynı eğitim yapılandırmasını kullanacaktır. Bu nedenle, geri aramalar listesinden başlayarak bunları yeniden kullanılabilir bir şekilde ayarlayın.
Bu öğreticinin eğitimi birçok kısa dönem için çalışır. tfdocs.EpochDots kaydetme gürültüsünü azaltmak için, yalnızca bir . her çağ için ve her 100 çağda bir tam bir metrik seti.
Sonraki, uzun ve gereksiz eğitim sürelerinden kaçınmak için callbacks.EarlyStopping içerir. Bu geri val_binary_crossentropy değil val_loss izleyecek şekilde ayarlandığını unutmayın. Bu fark daha sonra önemli olacaktır.
Eğitim için TensorBoard günlükleri oluşturmak için callbacks.TensorBoard kullanın.
def get_callbacks(name):
return [
tfdocs.modeling.EpochDots(),
tf.keras.callbacks.EarlyStopping(monitor='val_binary_crossentropy', patience=200),
tf.keras.callbacks.TensorBoard(logdir/name),
]
Benzer şekilde, her model aynı Model.compile ve Model.fit ayarlarını kullanır:
def compile_and_fit(model, name, optimizer=None, max_epochs=10000):
if optimizer is None:
optimizer = get_optimizer()
model.compile(optimizer=optimizer,
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[
tf.keras.losses.BinaryCrossentropy(
from_logits=True, name='binary_crossentropy'),
'accuracy'])
model.summary()
history = model.fit(
train_ds,
steps_per_epoch = STEPS_PER_EPOCH,
epochs=max_epochs,
validation_data=validate_ds,
callbacks=get_callbacks(name),
verbose=0)
return history
Minik model
Bir modeli eğiterek başlayın:
tiny_model = tf.keras.Sequential([
layers.Dense(16, activation='elu', input_shape=(FEATURES,)),
layers.Dense(1)
])
size_histories = {}
size_histories['Tiny'] = compile_and_fit(tiny_model, 'sizes/Tiny')
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 16) 464
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 481
Trainable params: 481
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.4961, binary_crossentropy:0.7294, loss:0.7294, val_accuracy:0.4840, val_binary_crossentropy:0.7200, val_loss:0.7200,
....................................................................................................
Epoch: 100, accuracy:0.5931, binary_crossentropy:0.6279, loss:0.6279, val_accuracy:0.5860, val_binary_crossentropy:0.6288, val_loss:0.6288,
....................................................................................................
Epoch: 200, accuracy:0.6157, binary_crossentropy:0.6178, loss:0.6178, val_accuracy:0.6200, val_binary_crossentropy:0.6134, val_loss:0.6134,
....................................................................................................
Epoch: 300, accuracy:0.6370, binary_crossentropy:0.6086, loss:0.6086, val_accuracy:0.6220, val_binary_crossentropy:0.6055, val_loss:0.6055,
....................................................................................................
Epoch: 400, accuracy:0.6522, binary_crossentropy:0.6008, loss:0.6008, val_accuracy:0.6260, val_binary_crossentropy:0.5997, val_loss:0.5997,
....................................................................................................
Epoch: 500, accuracy:0.6513, binary_crossentropy:0.5946, loss:0.5946, val_accuracy:0.6480, val_binary_crossentropy:0.5911, val_loss:0.5911,
....................................................................................................
Epoch: 600, accuracy:0.6636, binary_crossentropy:0.5894, loss:0.5894, val_accuracy:0.6390, val_binary_crossentropy:0.5898, val_loss:0.5898,
....................................................................................................
Epoch: 700, accuracy:0.6696, binary_crossentropy:0.5852, loss:0.5852, val_accuracy:0.6530, val_binary_crossentropy:0.5870, val_loss:0.5870,
....................................................................................................
Epoch: 800, accuracy:0.6706, binary_crossentropy:0.5824, loss:0.5824, val_accuracy:0.6590, val_binary_crossentropy:0.5850, val_loss:0.5850,
....................................................................................................
Epoch: 900, accuracy:0.6709, binary_crossentropy:0.5796, loss:0.5796, val_accuracy:0.6680, val_binary_crossentropy:0.5831, val_loss:0.5831,
....................................................................................................
Epoch: 1000, accuracy:0.6780, binary_crossentropy:0.5769, loss:0.5769, val_accuracy:0.6530, val_binary_crossentropy:0.5851, val_loss:0.5851,
....................................................................................................
Epoch: 1100, accuracy:0.6735, binary_crossentropy:0.5752, loss:0.5752, val_accuracy:0.6620, val_binary_crossentropy:0.5807, val_loss:0.5807,
....................................................................................................
Epoch: 1200, accuracy:0.6759, binary_crossentropy:0.5729, loss:0.5729, val_accuracy:0.6620, val_binary_crossentropy:0.5792, val_loss:0.5792,
....................................................................................................
Epoch: 1300, accuracy:0.6849, binary_crossentropy:0.5716, loss:0.5716, val_accuracy:0.6450, val_binary_crossentropy:0.5859, val_loss:0.5859,
....................................................................................................
Epoch: 1400, accuracy:0.6790, binary_crossentropy:0.5695, loss:0.5695, val_accuracy:0.6700, val_binary_crossentropy:0.5776, val_loss:0.5776,
....................................................................................................
Epoch: 1500, accuracy:0.6824, binary_crossentropy:0.5681, loss:0.5681, val_accuracy:0.6730, val_binary_crossentropy:0.5761, val_loss:0.5761,
....................................................................................................
Epoch: 1600, accuracy:0.6828, binary_crossentropy:0.5669, loss:0.5669, val_accuracy:0.6690, val_binary_crossentropy:0.5766, val_loss:0.5766,
....................................................................................................
Epoch: 1700, accuracy:0.6874, binary_crossentropy:0.5657, loss:0.5657, val_accuracy:0.6600, val_binary_crossentropy:0.5774, val_loss:0.5774,
....................................................................................................
Epoch: 1800, accuracy:0.6845, binary_crossentropy:0.5655, loss:0.5655, val_accuracy:0.6780, val_binary_crossentropy:0.5752, val_loss:0.5752,
....................................................................................................
Epoch: 1900, accuracy:0.6837, binary_crossentropy:0.5644, loss:0.5644, val_accuracy:0.6790, val_binary_crossentropy:0.5753, val_loss:0.5753,
....................................................................................................
Epoch: 2000, accuracy:0.6853, binary_crossentropy:0.5632, loss:0.5632, val_accuracy:0.6780, val_binary_crossentropy:0.5753, val_loss:0.5753,
....................................................................................................
Epoch: 2100, accuracy:0.6871, binary_crossentropy:0.5625, loss:0.5625, val_accuracy:0.6670, val_binary_crossentropy:0.5769, val_loss:0.5769,
...................................
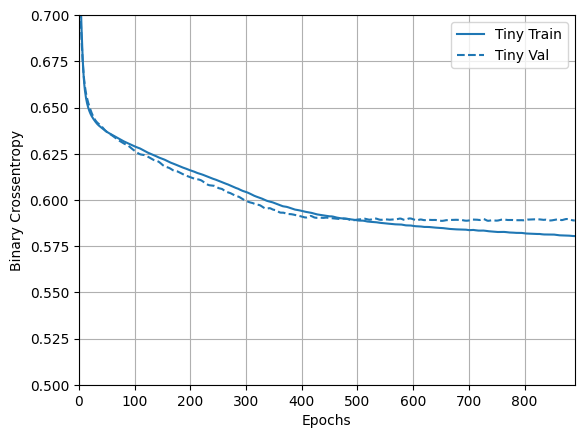
Şimdi modelin nasıl yaptığını kontrol edin:
plotter = tfdocs.plots.HistoryPlotter(metric = 'binary_crossentropy', smoothing_std=10)
plotter.plot(size_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
Küçük model
Küçük modelin performansını geçip geçemeyeceğinizi görmek için, daha büyük modelleri aşamalı olarak eğitin.
Her biri 16 birim olan iki gizli katman deneyin:
small_model = tf.keras.Sequential([
# `input_shape` is only required here so that `.summary` works.
layers.Dense(16, activation='elu', input_shape=(FEATURES,)),
layers.Dense(16, activation='elu'),
layers.Dense(1)
])
size_histories['Small'] = compile_and_fit(small_model, 'sizes/Small')
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 16) 464
dense_3 (Dense) (None, 16) 272
dense_4 (Dense) (None, 1) 17
=================================================================
Total params: 753
Trainable params: 753
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.4864, binary_crossentropy:0.7769, loss:0.7769, val_accuracy:0.4930, val_binary_crossentropy:0.7211, val_loss:0.7211,
....................................................................................................
Epoch: 100, accuracy:0.6386, binary_crossentropy:0.6052, loss:0.6052, val_accuracy:0.6020, val_binary_crossentropy:0.6177, val_loss:0.6177,
....................................................................................................
Epoch: 200, accuracy:0.6697, binary_crossentropy:0.5829, loss:0.5829, val_accuracy:0.6310, val_binary_crossentropy:0.6018, val_loss:0.6018,
....................................................................................................
Epoch: 300, accuracy:0.6838, binary_crossentropy:0.5721, loss:0.5721, val_accuracy:0.6490, val_binary_crossentropy:0.5940, val_loss:0.5940,
....................................................................................................
Epoch: 400, accuracy:0.6911, binary_crossentropy:0.5656, loss:0.5656, val_accuracy:0.6430, val_binary_crossentropy:0.5985, val_loss:0.5985,
....................................................................................................
Epoch: 500, accuracy:0.6930, binary_crossentropy:0.5607, loss:0.5607, val_accuracy:0.6430, val_binary_crossentropy:0.6028, val_loss:0.6028,
.........................
orta model
Şimdi her biri 64 birim olan 3 gizli katmanı deneyin:
medium_model = tf.keras.Sequential([
layers.Dense(64, activation='elu', input_shape=(FEATURES,)),
layers.Dense(64, activation='elu'),
layers.Dense(64, activation='elu'),
layers.Dense(1)
])
Ve aynı verileri kullanarak modeli eğitin:
size_histories['Medium'] = compile_and_fit(medium_model, "sizes/Medium")
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_5 (Dense) (None, 64) 1856
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 64) 4160
dense_8 (Dense) (None, 1) 65
=================================================================
Total params: 10,241
Trainable params: 10,241
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5017, binary_crossentropy:0.6840, loss:0.6840, val_accuracy:0.4790, val_binary_crossentropy:0.6723, val_loss:0.6723,
....................................................................................................
Epoch: 100, accuracy:0.7173, binary_crossentropy:0.5221, loss:0.5221, val_accuracy:0.6470, val_binary_crossentropy:0.6111, val_loss:0.6111,
....................................................................................................
Epoch: 200, accuracy:0.7884, binary_crossentropy:0.4270, loss:0.4270, val_accuracy:0.6390, val_binary_crossentropy:0.7045, val_loss:0.7045,
..............................................................
Büyük model
Bir alıştırma olarak, daha da büyük bir model oluşturabilir ve ne kadar çabuk fazla uydurmaya başladığını görebilirsiniz. Ardından, bu kıyaslamaya, sorunun garanti edeceğinden çok daha fazla kapasiteye sahip bir ağ ekleyelim:
large_model = tf.keras.Sequential([
layers.Dense(512, activation='elu', input_shape=(FEATURES,)),
layers.Dense(512, activation='elu'),
layers.Dense(512, activation='elu'),
layers.Dense(512, activation='elu'),
layers.Dense(1)
])
Ve yine aynı verileri kullanarak modeli eğitin:
size_histories['large'] = compile_and_fit(large_model, "sizes/large")
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_9 (Dense) (None, 512) 14848
dense_10 (Dense) (None, 512) 262656
dense_11 (Dense) (None, 512) 262656
dense_12 (Dense) (None, 512) 262656
dense_13 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5145, binary_crossentropy:0.7740, loss:0.7740, val_accuracy:0.4980, val_binary_crossentropy:0.6793, val_loss:0.6793,
....................................................................................................
Epoch: 100, accuracy:1.0000, binary_crossentropy:0.0020, loss:0.0020, val_accuracy:0.6600, val_binary_crossentropy:1.8540, val_loss:1.8540,
....................................................................................................
Epoch: 200, accuracy:1.0000, binary_crossentropy:0.0001, loss:0.0001, val_accuracy:0.6560, val_binary_crossentropy:2.5293, val_loss:2.5293,
..........................
Eğitim ve doğrulama kayıplarını çizin
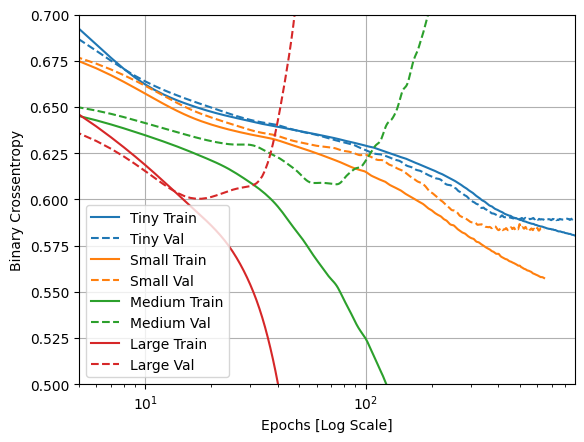
Düz çizgiler eğitim kaybını ve kesikli çizgiler doğrulama kaybını gösterir (unutmayın: daha düşük bir doğrulama kaybı daha iyi bir modeli gösterir).
Daha büyük bir model inşa etmek ona daha fazla güç verirken, bu güç bir şekilde kısıtlanmazsa, eğitim setine kolayca sığabilir.
Bu örnekte, tipik olarak, yalnızca "Tiny" modeli fazla sığdırmayı tamamen önlemeyi başarır ve daha büyük modellerin her biri verilere daha hızlı sığar. Bu, "large" model için o kadar şiddetli hale gelir ki, neler olduğunu gerçekten görmek için grafiği bir günlük ölçeğine çevirmeniz gerekir.
Doğrulama metriklerini eğitim metrikleriyle çizip karşılaştırırsanız, bu açıkça görülür.
- Küçük bir fark olması normaldir.
- Her iki metrik de aynı yönde hareket ediyorsa, her şey yolunda demektir.
- Antrenman metriği gelişmeye devam ederken doğrulama metriği durgunlaşmaya başlarsa, muhtemelen fazla uydurmaya yakınsınız demektir.
- Doğrulama metriği yanlış yöne gidiyorsa, model açıkça fazla uyuyor.
plotter.plot(size_histories)
a = plt.xscale('log')
plt.xlim([5, max(plt.xlim())])
plt.ylim([0.5, 0.7])
plt.xlabel("Epochs [Log Scale]")
Text(0.5, 0, 'Epochs [Log Scale]')
TensorBoard'da Görüntüle
Bu modellerin tümü eğitim sırasında TensorBoard günlüklerini yazdı.
Bir not defterinin içinde gömülü bir TensorBoard görüntüleyici açın:
#docs_infra: no_execute
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Open an embedded TensorBoard viewer
%tensorboard --logdir {logdir}/sizes
Bu not defterinin önceki bir çalışmasının sonuçlarını TensorBoard.dev'de görüntüleyebilirsiniz .
TensorBoard.dev, makine öğrenimi deneylerini herkesle barındırmak, izlemek ve paylaşmak için yönetilen bir deneyimdir.
Ayrıca kolaylık olması için bir <iframe> dahil edilmiştir:
display.IFrame(
src="https://tensorboard.dev/experiment/vW7jmmF9TmKmy3rbheMQpw/#scalars&_smoothingWeight=0.97",
width="100%", height="800px")
TensorBoard sonuçlarını paylaşmak istiyorsanız, aşağıdakileri bir kod hücresine kopyalayarak günlükleri TensorBoard.dev'e yükleyebilirsiniz.
tensorboard dev upload --logdir {logdir}/sizes
Aşırı takmayı önleme stratejileri
Bu bölümün içeriğine girmeden önce, karşılaştırma için temel olarak kullanmak üzere yukarıdaki "Tiny" modelinden eğitim günlüklerini kopyalayın.
shutil.rmtree(logdir/'regularizers/Tiny', ignore_errors=True)
shutil.copytree(logdir/'sizes/Tiny', logdir/'regularizers/Tiny')
PosixPath('/tmp/tmpn1rdh98q/tensorboard_logs/regularizers/Tiny')
-yer tutucu44 l10n-yerregularizer_histories = {}
regularizer_histories['Tiny'] = size_histories['Tiny']
Ağırlık düzenlemesi ekle
Occam'ın Ustura ilkesine aşina olabilirsiniz: Bir şey için iki açıklama verildiğinde, doğru olması en muhtemel açıklama "en basit" olandır, en az varsayımda bulunandır. Bu aynı zamanda sinir ağları tarafından öğrenilen modeller için de geçerlidir: bazı eğitim verileri ve bir ağ mimarisi verildiğinde, verileri açıklayabilecek birden fazla ağırlık değeri seti (birden çok model) vardır ve daha basit modellerin karmaşık olanlardan daha fazla uyma olasılığı daha düşüktür.
Bu bağlamda "basit bir model", parametre değerlerinin dağılımının daha az entropiye sahip olduğu bir modeldir (veya yukarıdaki bölümde gördüğümüz gibi, toplamda daha az parametreye sahip bir model). Bu nedenle, fazla uydurmayı azaltmanın yaygın bir yolu, ağırlıklarını yalnızca küçük değerler almaya zorlayarak bir ağın karmaşıklığına kısıtlamalar getirmektir, bu da ağırlık değerlerinin dağılımını daha "düzenli" hale getirir. Buna "ağırlık düzenleme" denir ve ağın kayıp fonksiyonuna büyük ağırlıklara sahip olmanın bir maliyeti eklenerek yapılır. Bu maliyet iki şekilde gelir:
L1 düzenlemesi , burada eklenen maliyet ağırlık katsayılarının mutlak değeriyle orantılıdır (yani ağırlıkların "L1 normu" olarak adlandırılan değerle).
L2 düzenlemesi , burada eklenen maliyet, ağırlık katsayılarının değerinin karesiyle orantılıdır (yani, ağırlıkların karesi "L2 normu" olarak adlandırılan şeyle). L2 düzenlemesi, sinir ağları bağlamında ağırlık azalması olarak da adlandırılır. Farklı adların sizi şaşırtmasına izin vermeyin: ağırlık düşüşü matematiksel olarak L2 düzenlemesiyle tamamen aynıdır.
L1 düzenlemesi, seyrek bir modeli teşvik ederek ağırlıkları tam olarak sıfıra doğru iter. L2'nin daha yaygın olmasının bir nedeni olarak, ceza küçük ağırlıklar için sıfıra gittiğinden, L2 düzenlemesi, ağırlık parametrelerini seyrek hale getirmeden cezalandıracaktır.
tf.keras , ağırlık düzenleyici örnekleri anahtar kelime argümanları olarak katmanlara geçirilerek ağırlık düzenlemesi eklenir. Şimdi L2 ağırlık düzenlemesini ekleyelim.
l2_model = tf.keras.Sequential([
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001),
input_shape=(FEATURES,)),
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(1)
])
regularizer_histories['l2'] = compile_and_fit(l2_model, "regularizers/l2")
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_14 (Dense) (None, 512) 14848
dense_15 (Dense) (None, 512) 262656
dense_16 (Dense) (None, 512) 262656
dense_17 (Dense) (None, 512) 262656
dense_18 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5126, binary_crossentropy:0.7481, loss:2.2415, val_accuracy:0.4950, val_binary_crossentropy:0.6707, val_loss:2.0653,
....................................................................................................
Epoch: 100, accuracy:0.6625, binary_crossentropy:0.5945, loss:0.6173, val_accuracy:0.6400, val_binary_crossentropy:0.5871, val_loss:0.6100,
....................................................................................................
Epoch: 200, accuracy:0.6690, binary_crossentropy:0.5864, loss:0.6079, val_accuracy:0.6650, val_binary_crossentropy:0.5856, val_loss:0.6076,
....................................................................................................
Epoch: 300, accuracy:0.6790, binary_crossentropy:0.5762, loss:0.5976, val_accuracy:0.6550, val_binary_crossentropy:0.5881, val_loss:0.6095,
....................................................................................................
Epoch: 400, accuracy:0.6843, binary_crossentropy:0.5697, loss:0.5920, val_accuracy:0.6650, val_binary_crossentropy:0.5878, val_loss:0.6101,
....................................................................................................
Epoch: 500, accuracy:0.6897, binary_crossentropy:0.5651, loss:0.5907, val_accuracy:0.6890, val_binary_crossentropy:0.5798, val_loss:0.6055,
....................................................................................................
Epoch: 600, accuracy:0.6945, binary_crossentropy:0.5610, loss:0.5864, val_accuracy:0.6820, val_binary_crossentropy:0.5772, val_loss:0.6026,
..........................................................
l2(0.001) , katmanın ağırlık matrisindeki her katsayının ağın toplam kaybına 0.001 * weight_coefficient_value**2 ekleyeceği anlamına gelir.
Bu yüzden binary_crossentropy doğrudan izliyoruz. Çünkü bu düzenlileştirme bileşenini karıştırmamış.
Dolayısıyla, L2 düzenleme cezasına sahip aynı "Large" model çok daha iyi performans gösterir:
plotter.plot(regularizer_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
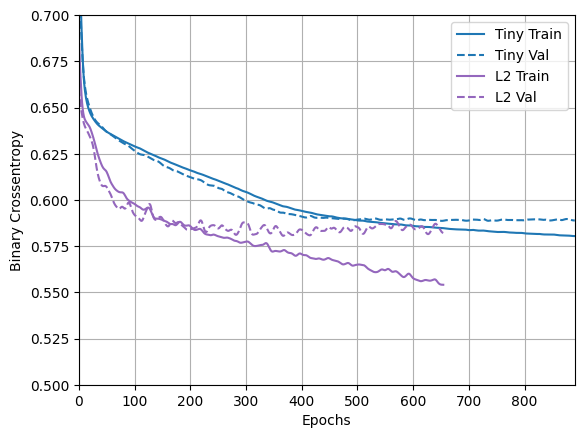
Gördüğünüz gibi, "L2" düzenli model artık "Tiny" modeliyle çok daha rekabetçi. Bu "L2" modeli, aynı sayıda parametreye sahip olmasına rağmen, dayandığı "Large" modele göre fazla takmaya karşı çok daha dirençlidir.
Daha fazla bilgi
Bu tür bir düzenleme hakkında dikkat edilmesi gereken iki önemli şey vardır.
Birincisi: Kendi eğitim döngünüzü yazıyorsanız, modele düzenlileştirme kayıplarını sorduğunuzdan emin olmanız gerekir.
result = l2_model(features)
regularization_loss=tf.add_n(l2_model.losses)
İkincisi: Bu uygulama, modelin kaybına ağırlık cezaları ekleyerek ve ardından standart bir optimizasyon prosedürü uygulayarak çalışır.
Bunun yerine yalnızca optimize ediciyi ham kayıp üzerinde çalıştıran ve ardından hesaplanan adımı uygularken optimize edici ayrıca bir miktar ağırlık düşüşü uygulayan ikinci bir yaklaşım vardır. Bu "Ayrıştırılmış Ağırlık Azalması", optimizers.FTRL ve optimizers.AdamW gibi optimizers.FTRL edicilerde görülür.
Bırakma ekle
Bırakma, Hinton ve Toronto Üniversitesi'ndeki öğrencileri tarafından geliştirilen, sinir ağları için en etkili ve en yaygın olarak kullanılan düzenlileştirme tekniklerinden biridir.
Bırakmanın sezgisel açıklaması, ağdaki bireysel düğümlerin diğerlerinin çıktısına güvenemeyeceğinden, her düğümün kendi başına yararlı özellikler çıkarması gerektiğidir.
Bir katmana uygulanan bırakma, eğitim sırasında katmanın bir dizi çıktı özelliğinin rastgele "bırakılmasından" (yani sıfıra ayarlanmasından) oluşur. Belirli bir katmanın normalde eğitim sırasında belirli bir girdi örneği için bir vektör [0.2, 0.5, 1.3, 0.8, 1.1] döndüreceğini varsayalım; bırakma uygulandıktan sonra, bu vektör rastgele dağıtılmış birkaç sıfır girişine sahip olacaktır, örneğin [0, 0.5, 1.3, 0, 1.1].
"Bırakma oranı", sıfırlanmakta olan özelliklerin oranıdır; genellikle 0,2 ile 0,5 arasında ayarlanır. Test zamanında, hiçbir birim atılmaz ve bunun yerine katmanın çıkış değerleri, eğitim zamanından daha fazla birimin aktif olduğu gerçeğini dengelemek için bırakma oranına eşit bir faktörle küçültülür.
tf.keras , hemen önce katmanın çıktısına uygulanan Dropout katmanı aracılığıyla bir ağda bırakma uygulayabilirsiniz.
Fazla takmayı azaltmada ne kadar başarılı olduklarını görmek için ağımıza iki Bırakma katmanı ekleyelim:
dropout_model = tf.keras.Sequential([
layers.Dense(512, activation='elu', input_shape=(FEATURES,)),
layers.Dropout(0.5),
layers.Dense(512, activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, activation='elu'),
layers.Dropout(0.5),
layers.Dense(1)
])
regularizer_histories['dropout'] = compile_and_fit(dropout_model, "regularizers/dropout")
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_19 (Dense) (None, 512) 14848
dropout (Dropout) (None, 512) 0
dense_20 (Dense) (None, 512) 262656
dropout_1 (Dropout) (None, 512) 0
dense_21 (Dense) (None, 512) 262656
dropout_2 (Dropout) (None, 512) 0
dense_22 (Dense) (None, 512) 262656
dropout_3 (Dropout) (None, 512) 0
dense_23 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.4961, binary_crossentropy:0.8110, loss:0.8110, val_accuracy:0.5330, val_binary_crossentropy:0.6900, val_loss:0.6900,
....................................................................................................
Epoch: 100, accuracy:0.6557, binary_crossentropy:0.5961, loss:0.5961, val_accuracy:0.6710, val_binary_crossentropy:0.5788, val_loss:0.5788,
....................................................................................................
Epoch: 200, accuracy:0.6871, binary_crossentropy:0.5622, loss:0.5622, val_accuracy:0.6860, val_binary_crossentropy:0.5856, val_loss:0.5856,
....................................................................................................
Epoch: 300, accuracy:0.7246, binary_crossentropy:0.5121, loss:0.5121, val_accuracy:0.6820, val_binary_crossentropy:0.5927, val_loss:0.5927,
............
yer tutucu52 l10n-yerplotter.plot(regularizer_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
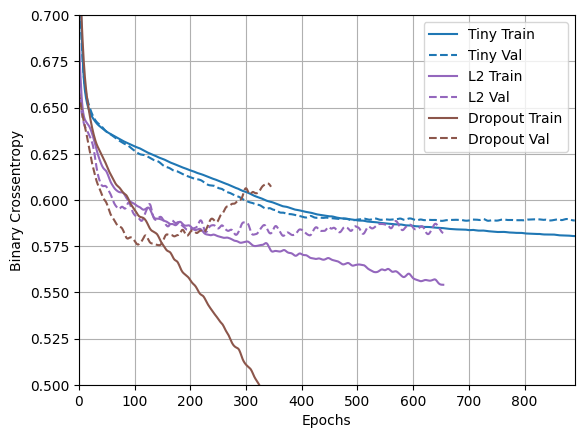
Bu plandan, bu düzenlileştirme yaklaşımlarının her ikisinin de "Large" modelin davranışını iyileştirdiği açıktır. Ama bu yine de "Tiny" temel çizgisini bile geçmiyor.
Sonra ikisini birlikte deneyin ve daha iyi olup olmadığına bakın.
Birleşik L2 + bırakma
combined_model = tf.keras.Sequential([
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu', input_shape=(FEATURES,)),
layers.Dropout(0.5),
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu'),
layers.Dropout(0.5),
layers.Dense(1)
])
regularizer_histories['combined'] = compile_and_fit(combined_model, "regularizers/combined")
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_24 (Dense) (None, 512) 14848
dropout_4 (Dropout) (None, 512) 0
dense_25 (Dense) (None, 512) 262656
dropout_5 (Dropout) (None, 512) 0
dense_26 (Dense) (None, 512) 262656
dropout_6 (Dropout) (None, 512) 0
dense_27 (Dense) (None, 512) 262656
dropout_7 (Dropout) (None, 512) 0
dense_28 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5090, binary_crossentropy:0.8064, loss:0.9648, val_accuracy:0.4660, val_binary_crossentropy:0.6877, val_loss:0.8454,
....................................................................................................
Epoch: 100, accuracy:0.6445, binary_crossentropy:0.6050, loss:0.6350, val_accuracy:0.6630, val_binary_crossentropy:0.5871, val_loss:0.6169,
....................................................................................................
Epoch: 200, accuracy:0.6660, binary_crossentropy:0.5932, loss:0.6186, val_accuracy:0.6880, val_binary_crossentropy:0.5722, val_loss:0.5975,
....................................................................................................
Epoch: 300, accuracy:0.6697, binary_crossentropy:0.5818, loss:0.6100, val_accuracy:0.6900, val_binary_crossentropy:0.5614, val_loss:0.5895,
....................................................................................................
Epoch: 400, accuracy:0.6749, binary_crossentropy:0.5742, loss:0.6046, val_accuracy:0.6870, val_binary_crossentropy:0.5576, val_loss:0.5881,
....................................................................................................
Epoch: 500, accuracy:0.6854, binary_crossentropy:0.5703, loss:0.6029, val_accuracy:0.6970, val_binary_crossentropy:0.5458, val_loss:0.5784,
....................................................................................................
Epoch: 600, accuracy:0.6806, binary_crossentropy:0.5673, loss:0.6015, val_accuracy:0.6980, val_binary_crossentropy:0.5453, val_loss:0.5795,
....................................................................................................
Epoch: 700, accuracy:0.6937, binary_crossentropy:0.5583, loss:0.5938, val_accuracy:0.6870, val_binary_crossentropy:0.5477, val_loss:0.5832,
....................................................................................................
Epoch: 800, accuracy:0.6911, binary_crossentropy:0.5576, loss:0.5947, val_accuracy:0.7000, val_binary_crossentropy:0.5446, val_loss:0.5817,
.......................
yer tutucu56 l10n-yerplotter.plot(regularizer_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
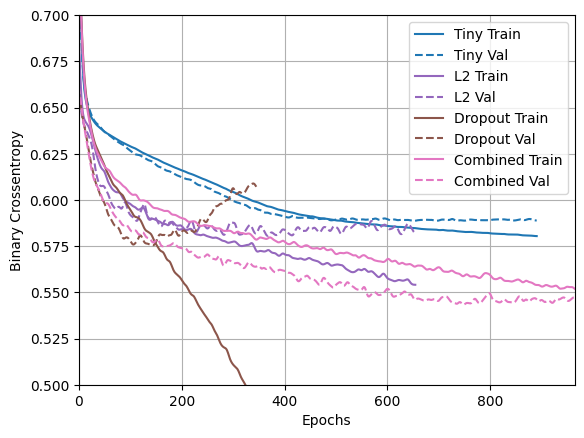
"Combined" düzenlemeye sahip bu model, açıkçası şimdiye kadarki en iyisidir.
TensorBoard'da Görüntüle
Bu modeller ayrıca TensorBoard günlüklerini de kaydetti.
Bir not defterinde yerleşik bir tensör panosu görüntüleyici açmak için aşağıdakileri bir kod hücresine kopyalayın:
%tensorboard --logdir {logdir}/regularizers
Bu not defterinin önceki bir çalışmasının sonuçlarını TensorDoard.dev'de görüntüleyebilirsiniz .
Ayrıca kolaylık olması için bir <iframe> dahil edilmiştir:
display.IFrame(
src="https://tensorboard.dev/experiment/fGInKDo8TXes1z7HQku9mw/#scalars&_smoothingWeight=0.97",
width = "100%",
height="800px")
Bu, şununla yüklendi:
tensorboard dev upload --logdir {logdir}/regularizers
Sonuçlar
Özetlemek gerekirse: sinir ağlarında fazla takmayı önlemenin en yaygın yolları şunlardır:
- Daha fazla eğitim verisi alın.
- Ağın kapasitesini azaltın.
- Ağırlık düzenlemesi ekleyin.
- Bırakma ekleyin.
Bu kılavuzda ele alınmayan iki önemli yaklaşım şunlardır:
- veri büyütme
- toplu normalleştirme
Her yöntemin kendi başına yardımcı olabileceğini unutmayın, ancak çoğu zaman bunları birleştirmek daha da etkili olabilir.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.