
|
|
|
 Veja a fonte em GitHub Veja a fonte em GitHub
|
|
Em um problema de regressão, o objetivo é prever as saídas (outputs) de um valor contínuo, como um preço ou probabilidade. Em contraste de problemas de classificação, onde temos o propósito de escolher uma classe em uma lista de classificações (por exemplo, se uma imagem contém uma maçã ou laranja, assim reconhecendo qual fruta é representada na imagem).
Este notebook usa a clássica base de dados Auto MPG e constrói um modelo para prever a economia de combustíveis de automóveis do final dos anos 1970, início dos anos 1980. Para isso, forneceremos um modelo com descrição de vários automóveis desse período. Essa descrição inclui atributos como: cilindros, deslocamento, potência do motor, e peso.
Este exemplo usa a API tf.keras. Veja este guia para mais detalhes.
# Use seaborn para pairplotpip install -q seaborn
import pathlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
2.4.1
Base de dados Auto MPG
A base de dados está disponível em UCI Machine Learning Repository.
Pegando os dados
Primeiro baixe a base de dados dos automóveis.
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
Downloading data from http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data 32768/30286 [================================] - 0s 4us/step '/home/kbuilder/.keras/datasets/auto-mpg.data'
Utilizando o pandas, importe os dados:
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()
Limpe os dados
Esta base contém alguns valores não conhecidos (unknown).
dataset.isna().sum()
MPG 0 Cylinders 0 Displacement 0 Horsepower 6 Weight 0 Acceleration 0 Model Year 0 Origin 0 dtype: int64
Para manter esse tutorial básico, remova as linhas com esses valores não conhecidos.
dataset = dataset.dropna()
A coluna "Origin" é uma coluna categórica e não numérica. Logo converta para one-hot :
origin = dataset.pop('Origin')
dataset['USA'] = (origin == 1)*1.0
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
dataset.tail()
Separando dados de treinamento e teste
Agora separe os dados em um conjunto de treinamento e outro teste.
Iremos utilizar o conjunto de teste no final da análise do modelo.
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
Inspecione o dado
Dê uma rápida olhada em como está a distribuição de algumas colunas do conjunto de treinamento.
sns.pairplot(train_dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde")
<seaborn.axisgrid.PairGrid at 0x7f088d352978>
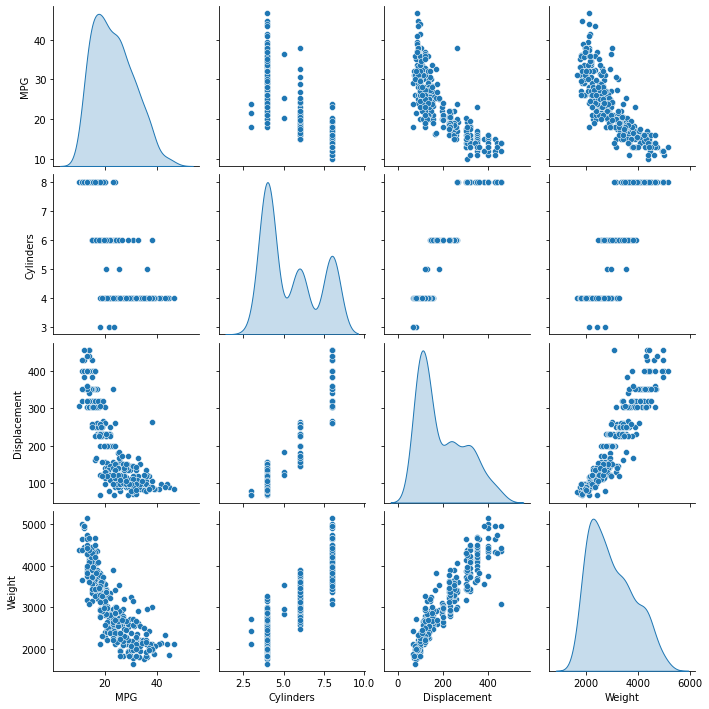
Repare na visão geral das estatísticas:
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_stats
Separe features de labels
Separe o valor alvo (labels), das features. Esta label é o valor no qual o model é treinado para prever.
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
Normalize os dados
Olhe novamente para o bloco train_stats acima e note quão diferente é a variação de feature.
Uma boa prática é normalizar as features que usam diferentes escalas e intervalos. Apesar do modelo poder convergir sem a normalização, isso torna o treinamento mais difícil, e torna o resultado do modelo dependente da escolha das unidades da entrada.
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
O dado normalizado é o que nós usaremos para treinar o modelo.
O Modelo
Construindo o modelo
Vamos construir o modelo. Aqui usaremos o modelo Sequential com duas camadas densely connected, e a camada de saída que retorna um único valor contínuo. Os passos de construção do modelo são agrupados em uma função, build_model, já que criaremos um segundo modelo mais tarde.
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
Examine o modelo
Use o método .summary para exibir uma descrição simples do modelo.
model.summary()
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 64) 640 _________________________________________________________________ dense_1 (Dense) (None, 64) 4160 _________________________________________________________________ dense_2 (Dense) (None, 1) 65 ================================================================= Total params: 4,865 Trainable params: 4,865 Non-trainable params: 0 _________________________________________________________________
Agora teste o modelo. Pegue um batch de 10 exemplos do conjunto de treinamento e chame model.predict nestes.
example_batch = normed_train_data[:10]
example_result = model.predict(example_batch)
example_result
array([[-0.32038543],
[-0.03224104],
[ 0.13639623],
[-0.18148893],
[-0.06226134],
[ 0.35602754],
[-0.0232144 ],
[-0.38673395],
[ 0.13995253],
[-0.20493355]], dtype=float32)
Parece que está funcionando e ele produz o resultado de forma e tipo esperados.
Treinando o modelo
Treine o modelo com 1000 epochs, e grave a acurácia do treinamento e da validação em um objeto history.
# Mostra o progresso do treinamento imprimindo um único ponto para cada epoch completada
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2, verbose=0,
callbacks=[PrintDot()])
.................................................................................................... .................................................................................................... .................................................................................................... .................................................................................................... .................................................................................................... .................................................................................................... .................................................................................................... .................................................................................................... .................................................................................................... ....................................................................................................
Visualize o progresso do modelo de treinamento usando o estados armazenados no objeto history
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [MPG]')
plt.plot(hist['epoch'], hist['mae'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mae'],
label = 'Val Error')
plt.ylim([0,5])
plt.legend()
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Square Error [$MPG^2$]')
plt.plot(hist['epoch'], hist['mse'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mse'],
label = 'Val Error')
plt.ylim([0,20])
plt.legend()
plt.show()
plot_history(history)
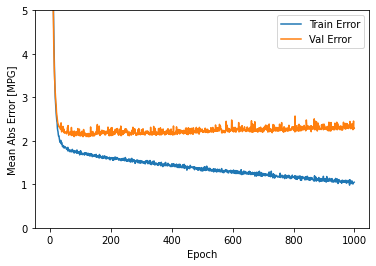
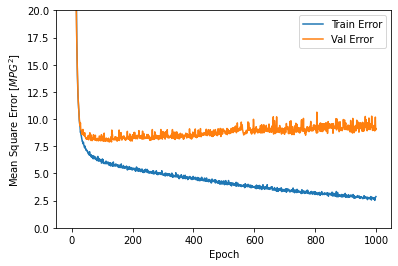
Este grafo mostra as pequenas melhoras, ou mesmo a diminuição do validation error após 100 epochs. Vamos atualizar o model.fit para que pare automaticamente o treinamento quando o validation score não aumentar mais. Usaremos o EarlyStopping callback que testa a condição do treinamento a cada epoch. Se um grupo de epochs decorre sem mostrar melhoras, o treinamento irá parar automaticamente.
Você pode aprender mais sobre este callback aqui.
model = build_model()
# O parâmetro patience é o quantidade de epochs para checar as melhoras
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(normed_train_data, train_labels, epochs=EPOCHS,
validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])
plot_history(history)
........................................................
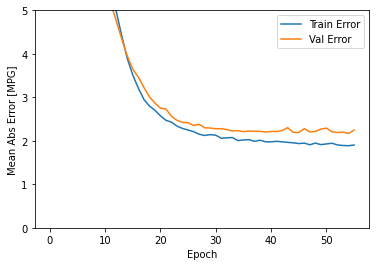
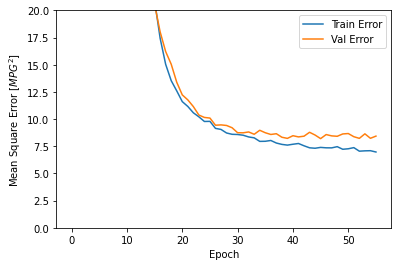
O gráfico mostra que no conjunto de validação, a média de erro é próximo de +/- 2MPG. Isso é bom? Deixaremos essa decisão a você.
Vamos ver quão bem o modelo generaliza usando o conjunto de teste, que não usamos para treinar o modelo. Isso diz quão bem podemos esperar que o modelo se saia quando usarmos na vida real.
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)
print("Testing set Mean Abs Error: {:5.2f} MPG".format(mae))
3/3 - 0s - loss: 5.9054 - mae: 1.8057 - mse: 5.9054 Testing set Mean Abs Error: 1.81 MPG
Faça predições
Finalmente, prevejam os valores MPG usando o conjunto de teste.
test_predictions = model.predict(normed_test_data).flatten()
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])
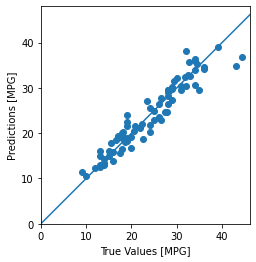
Parece que o nosso modelo prediz razoavelmente bem. Vamos dar uma olhada na distribuição dos erros.
error = test_predictions - test_labels
plt.hist(error, bins = 25)
plt.xlabel("Prediction Error [MPG]")
_ = plt.ylabel("Count")
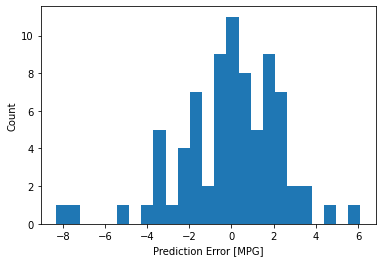
Não é tão gaussiana, porém podemos esperar que por conta do número de exemplo é bem pequeno.
Conclusão
Este notebook introduz algumas técnicas para trabalhar com problema de regressão.
- Mean Squared Error(MSE), é uma função comum de loss usada para problemas de regressão (diferentes funções de loss são usadas para problemas de classificação).
- Similarmente, as métricas de evolução usadas na regressão são diferentes da classificação. Uma métrica comum de regressão é Mean Absolute Error (MAE).
- Quando o dado de entrada de features tem diferentes intervalos, cada feature deve ser escalada para o mesmo intervalo.
- Se não possuir muitos dados de treinamento, uma técnica é preferir uma pequena rede com poucas camadas para evitar overfitting.
- Early stopping é uma boa técnica para evitar overfitting.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.