
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
در مسئله رگرسیون ، هدف پیشبینی خروجی یک مقدار پیوسته، مانند قیمت یا احتمال است. این را با مشکل طبقهبندی مقایسه کنید، جایی که هدف انتخاب یک کلاس از لیست کلاسها است (به عنوان مثال، جایی که یک تصویر حاوی یک سیب یا یک پرتقال است، تشخیص اینکه کدام میوه در تصویر است).
این آموزش از مجموعه داده کلاسیک Auto MPG استفاده میکند و نحوه ساخت مدلهایی را برای پیشبینی بازده سوخت خودروهای اواخر دهه 1970 و اوایل دهه 1980 نشان میدهد. برای انجام این کار، مدل ها را با توضیحات بسیاری از خودروهای آن دوره زمانی ارائه می دهید. این توضیحات شامل ویژگی هایی مانند سیلندر، جابجایی، اسب بخار و وزن است.
این مثال از Keras API استفاده می کند. (برای کسب اطلاعات بیشتر به آموزش ها و راهنماهای Keras مراجعه کنید.)
# Use seaborn for pairplot.pip install -q seaborn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# Make NumPy printouts easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
2.8.0-rc1
مجموعه داده MPG خودکار
مجموعه داده از مخزن یادگیری ماشین UCI در دسترس است.
داده ها را دریافت کنید
ابتدا مجموعه داده را با استفاده از پانداها دانلود و وارد کنید:
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()
داده ها را پاک کنید
مجموعه داده شامل چند مقدار ناشناخته است:
dataset.isna().sum()
MPG 0 Cylinders 0 Displacement 0 Horsepower 6 Weight 0 Acceleration 0 Model Year 0 Origin 0 dtype: int64
برای ساده نگه داشتن این آموزش اولیه، آن ردیف ها را رها کنید:
dataset = dataset.dropna()
ستون "Origin" مقوله ای است نه عددی. بنابراین گام بعدی این است که مقادیر موجود در ستون را با pd.get_dummies رمزگذاری کنید.
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, columns=['Origin'], prefix='', prefix_sep='')
dataset.tail()
داده ها را به مجموعه های آموزشی و آزمایشی تقسیم کنید
اکنون مجموعه داده را به یک مجموعه آموزشی و یک مجموعه آزمایشی تقسیم کنید. شما از مجموعه تست در ارزیابی نهایی مدل های خود استفاده خواهید کرد.
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
داده ها را بررسی کنید
توزیع مشترک چند جفت ستون از مجموعه آموزشی را مرور کنید.
ردیف بالا نشان می دهد که بازده سوخت (MPG) تابعی از تمام پارامترهای دیگر است. سطرهای دیگر نشان می دهد که آنها توابع یکدیگر هستند.
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
<seaborn.axisgrid.PairGrid at 0x7f6bfdae9850>
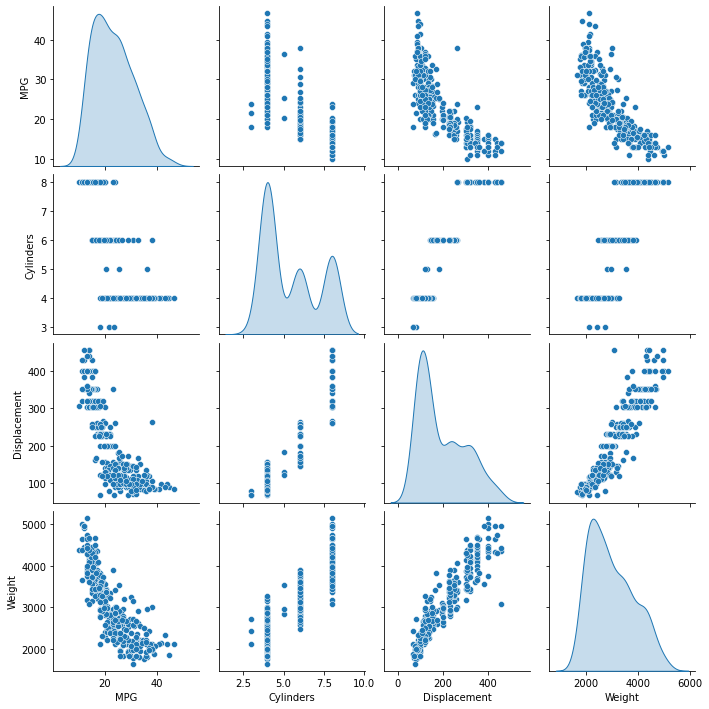
بیایید آمار کلی را نیز بررسی کنیم. توجه داشته باشید که چگونه هر ویژگی محدوده بسیار متفاوتی را پوشش می دهد:
train_dataset.describe().transpose()
ویژگیها را از برچسبها جدا کنید
مقدار هدف - "برچسب" - را از ویژگی ها جدا کنید. این برچسب مقداری است که شما به مدل آموزش می دهید تا پیش بینی کند.
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('MPG')
test_labels = test_features.pop('MPG')
عادی سازی
در جدول آمار به راحتی می توان دید که محدوده هر ویژگی چقدر متفاوت است:
train_dataset.describe().transpose()[['mean', 'std']]
عادی سازی ویژگی هایی که از مقیاس ها و محدوده های مختلف استفاده می کنند، تمرین خوبی است.
یکی از دلایل اهمیت این موضوع این است که ویژگی ها در وزن مدل ضرب می شوند. بنابراین، مقیاس خروجی ها و مقیاس گرادیان ها تحت تأثیر مقیاس ورودی ها هستند.
اگرچه ممکن است یک مدل بدون نرمالسازی ویژگیها همگرا شود، اما نرمالسازی باعث میشود آموزش بسیار پایدارتر شود.
لایه عادی سازی
tf.keras.layers.Normalization یک راه ساده و تمیز برای افزودن نرمال سازی ویژگی به مدل شما است.
اولین مرحله ایجاد لایه است:
normalizer = tf.keras.layers.Normalization(axis=-1)
سپس، با فراخوانی Normalization.adapt ، وضعیت لایه پیش پردازش را با داده ها مطابقت دهید:
normalizer.adapt(np.array(train_features))
میانگین و واریانس را محاسبه کرده و در لایه ذخیره کنید:
print(normalizer.mean.numpy())
[[ 5.478 195.318 104.869 2990.252 15.559 75.898 0.178 0.197
0.624]]
هنگامی که لایه فراخوانی می شود، داده های ورودی را با هر ویژگی به طور مستقل عادی سازی شده برمی گرداند:
first = np.array(train_features[:1])
with np.printoptions(precision=2, suppress=True):
print('First example:', first)
print()
print('Normalized:', normalizer(first).numpy())
First example: [[ 4. 90. 75. 2125. 14.5 74. 0. 0. 1. ]] Normalized: [[-0.87 -1.01 -0.79 -1.03 -0.38 -0.52 -0.47 -0.5 0.78]]
رگرسیون خطی
قبل از ساخت یک مدل شبکه عصبی عمیق، با استفاده از یک و چند متغیر با رگرسیون خطی شروع کنید.
رگرسیون خطی با یک متغیر
با یک رگرسیون خطی تک متغیری شروع کنید تا 'MPG' از 'Horsepower' را پیشبینی کنید.
آموزش یک مدل با tf.keras معمولاً با تعریف معماری مدل شروع می شود. از یک مدل tf.keras.Sequential استفاده کنید که دنباله ای از مراحل را نشان می دهد.
در مدل رگرسیون خطی تک متغیری شما دو مرحله وجود دارد:
- ویژگی های ورودی
'Horsepower'را با استفاده از لایه پیش پردازشtf.keras.layers.Normalizationکنید. - یک تبدیل خطی (\(y = mx+b\)) برای تولید 1 خروجی با استفاده از یک لایه خطی اعمال کنید (
tf.keras.layers.Dense).
تعداد ورودیها را میتوان با آرگومان input_shape تنظیم کرد یا زمانی که مدل برای اولین بار اجرا میشود، بهطور خودکار.
ابتدا یک آرایه NumPy از ویژگی های 'Horsepower' ایجاد کنید. سپس، tf.keras.layers.Normalization را نمونه سازی کنید و وضعیت آن را با داده های horsepower مطابقت دهید:
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = layers.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)
مدل Keras Sequential را بسازید:
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])
horsepower_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense (Dense) (None, 1) 2
=================================================================
Total params: 5
Trainable params: 2
Non-trainable params: 3
_________________________________________________________________
این مدل 'MPG' از 'Horsepower' پیشبینی میکند.
مدل آموزش ندیده را روی 10 مقدار اول «اسب بخار» اجرا کنید. خروجی خوب نخواهد بود، اما توجه کنید که شکل مورد انتظار (10, 1) را دارد:
horsepower_model.predict(horsepower[:10])
array([[-1.186],
[-0.67 ],
[ 2.189],
[-1.662],
[-1.504],
[-0.59 ],
[-1.782],
[-1.504],
[-0.392],
[-0.67 ]], dtype=float32)
هنگامی که مدل ساخته شد، رویه آموزشی را با استفاده از روش Keras Model.compile کنید. مهمترین آرگومانهای کامپایل، loss و optimizer هستند، زیرا این آرگومانها تعریف میکنند که چه چیزی بهینه میشود ( mean_absolute_error ) و چگونه (با استفاده از tf.keras.optimizers.Adam ).
horsepower_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
از Keras Model.fit برای اجرای آموزش برای 100 دوره استفاده کنید:
%%time
history = horsepower_model.fit(
train_features['Horsepower'],
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.79 s, sys: 797 ms, total: 5.59 s Wall time: 3.8 s
با استفاده از آمارهای ذخیره شده در شی history ، پیشرفت آموزش مدل را تجسم کنید:
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, 10])
plt.xlabel('Epoch')
plt.ylabel('Error [MPG]')
plt.legend()
plt.grid(True)
plot_loss(history)

نتایج مجموعه تست را برای بعد جمع آوری کنید:
test_results = {}
test_results['horsepower_model'] = horsepower_model.evaluate(
test_features['Horsepower'],
test_labels, verbose=0)
از آنجایی که این یک رگرسیون تک متغیره است، مشاهده پیشبینیهای مدل به عنوان تابعی از ورودی آسان است:
x = tf.linspace(0.0, 250, 251)
y = horsepower_model.predict(x)
def plot_horsepower(x, y):
plt.scatter(train_features['Horsepower'], train_labels, label='Data')
plt.plot(x, y, color='k', label='Predictions')
plt.xlabel('Horsepower')
plt.ylabel('MPG')
plt.legend()
plot_horsepower(x, y)

رگرسیون خطی با ورودی های متعدد
میتوانید از تنظیمات تقریباً یکسانی برای پیشبینی بر اساس ورودیهای متعدد استفاده کنید. این مدل همچنان همان \(y = mx+b\) را انجام می دهد با این تفاوت که \(m\) یک ماتریس و \(b\) یک بردار است.
دوباره یک مدل دو مرحله ای Keras Sequential ایجاد کنید که اولین لایه normalizer ساز است ( tf.keras.layers.Normalization(axis=-1) ) که قبلا تعریف کرده بودید و با کل مجموعه داده تطبیق داده بودید:
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
وقتی Model.predict را روی دستهای از ورودیها فراخوانی میکنید، برای هر مثال units=1 خروجی تولید میکند:
linear_model.predict(train_features[:10])
array([[ 0.441],
[ 1.522],
[ 0.188],
[ 1.169],
[ 0.058],
[ 0.965],
[ 0.034],
[-0.674],
[ 0.437],
[-0.37 ]], dtype=float32)
وقتی مدل را فراخوانی میکنید، ماتریسهای وزن آن ساخته میشوند - بررسی کنید که وزنهای kernel ( \(m\) در \(y=mx+b\)) شکل (9, 1) داشته باشند:
linear_model.layers[1].kernel
<tf.Variable 'dense_1/kernel:0' shape=(9, 1) dtype=float32, numpy=
array([[-0.702],
[ 0.307],
[ 0.114],
[ 0.233],
[ 0.244],
[ 0.322],
[-0.725],
[-0.151],
[ 0.407]], dtype=float32)>
مدل را با Keras Model.compile کنید و با Model.fit برای 100 دوره آموزش دهید:
linear_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
%%time
history = linear_model.fit(
train_features,
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.89 s, sys: 740 ms, total: 5.63 s Wall time: 3.75 s
با استفاده از تمام ورودیها در این مدل رگرسیون، خطای آموزشی و اعتبارسنجی بسیار کمتری نسبت به مدل horsepower_model که یک ورودی داشت، به دست میآید:
plot_loss(history)

نتایج مجموعه تست را برای بعد جمع آوری کنید:
test_results['linear_model'] = linear_model.evaluate(
test_features, test_labels, verbose=0)
رگرسیون با شبکه عصبی عمیق (DNN)
در قسمت قبل دو مدل خطی برای ورودی های تک و چندگانه پیاده سازی کردید.
در اینجا شما مدل های DNN تک ورودی و چند ورودی را پیاده سازی خواهید کرد.
کد اساساً یکسان است به جز اینکه مدل بسط داده شده است تا لایههای غیرخطی "پنهان" را در بر بگیرد. نام "مخفی" در اینجا فقط به معنای عدم اتصال مستقیم به ورودی یا خروجی است.
این مدل ها چند لایه بیشتر از مدل خطی دارند:
- لایه نرمال سازی، مانند قبل (با
horsepower_normalizerساز برای مدل تک ورودی وnormalizerساز برای مدل چند ورودی). - دو لایه پنهان، غیر خطی،
Denseبا غیرخطی بودن تابع فعال سازی ReLU (relu). - یک لایه خطی
Denseتک خروجی.
هر دو مدل از یک روش آموزشی استفاده میکنند، بنابراین متد compile در تابع build_and_compile_model زیر گنجانده شده است.
def build_and_compile_model(norm):
model = keras.Sequential([
norm,
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
model.compile(loss='mean_absolute_error',
optimizer=tf.keras.optimizers.Adam(0.001))
return model
رگرسیون با استفاده از یک DNN و یک ورودی واحد
یک مدل DNN با فقط 'Horsepower' به عنوان ورودی و horsepower_normalizer (که قبلاً تعریف شد) به عنوان لایه نرمالسازی ایجاد کنید:
dnn_horsepower_model = build_and_compile_model(horsepower_normalizer)
این مدل نسبت به مدل های خطی پارامترهای قابل آموزش بیشتری دارد:
dnn_horsepower_model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense_2 (Dense) (None, 64) 128
dense_3 (Dense) (None, 64) 4160
dense_4 (Dense) (None, 1) 65
=================================================================
Total params: 4,356
Trainable params: 4,353
Non-trainable params: 3
_________________________________________________________________
آموزش مدل با Keras Model.fit :
%%time
history = dnn_horsepower_model.fit(
train_features['Horsepower'],
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.07 s, sys: 691 ms, total: 5.76 s Wall time: 3.92 s
این مدل کمی بهتر از مدل تک ورودی خطی horsepower_model عمل می کند:
plot_loss(history)

اگر پیشبینیها را تابعی از 'Horsepower' ترسیم کنید، باید متوجه شوید که این مدل چگونه از غیرخطی بودن لایههای پنهان بهره میبرد:
x = tf.linspace(0.0, 250, 251)
y = dnn_horsepower_model.predict(x)
plot_horsepower(x, y)

نتایج مجموعه تست را برای بعد جمع آوری کنید:
test_results['dnn_horsepower_model'] = dnn_horsepower_model.evaluate(
test_features['Horsepower'], test_labels,
verbose=0)
رگرسیون با استفاده از یک DNN و ورودی های متعدد
فرآیند قبلی را با استفاده از تمام ورودی ها تکرار کنید. عملکرد مدل کمی در مجموعه داده های اعتبار سنجی بهبود می یابد.
dnn_model = build_and_compile_model(normalizer)
dnn_model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization (Normalizatio (None, 9) 19
n)
dense_5 (Dense) (None, 64) 640
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 1) 65
=================================================================
Total params: 4,884
Trainable params: 4,865
Non-trainable params: 19
_________________________________________________________________
%%time
history = dnn_model.fit(
train_features,
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.08 s, sys: 725 ms, total: 5.8 s Wall time: 3.94 s
plot_loss(history)

نتایج را در مجموعه تست جمع آوری کنید:
test_results['dnn_model'] = dnn_model.evaluate(test_features, test_labels, verbose=0)
کارایی
از آنجایی که همه مدل ها آموزش دیده اند، می توانید عملکرد مجموعه تست آنها را بررسی کنید:
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
این نتایج با خطای اعتبارسنجی مشاهده شده در طول تمرین مطابقت دارد.
پیش بینی کنید
اکنون می توانید با استفاده از Keras Model.predict با dnn_model در مجموعه آزمایشی پیش بینی کنید و ضرر را بررسی کنید:
test_predictions = dnn_model.predict(test_features).flatten()
a = plt.axes(aspect='equal')
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
lims = [0, 50]
plt.xlim(lims)
plt.ylim(lims)
_ = plt.plot(lims, lims)
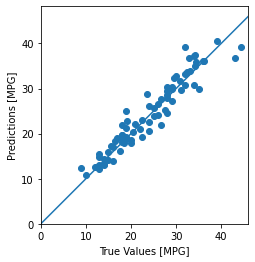
به نظر می رسد که مدل به خوبی پیش بینی می کند.
اکنون توزیع خطا را بررسی کنید:
error = test_predictions - test_labels
plt.hist(error, bins=25)
plt.xlabel('Prediction Error [MPG]')
_ = plt.ylabel('Count')
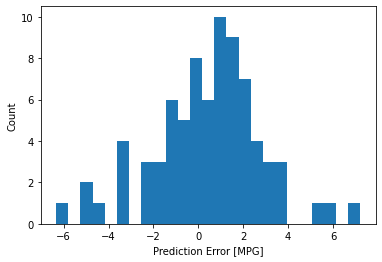
اگر از مدل راضی هستید، آن را برای استفاده بعدی با Model.save کنید:
dnn_model.save('dnn_model')
2022-01-26 07:26:13.372245: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: dnn_model/assets
اگر مدل را مجدداً بارگذاری کنید، خروجی یکسانی می دهد:
reloaded = tf.keras.models.load_model('dnn_model')
test_results['reloaded'] = reloaded.evaluate(
test_features, test_labels, verbose=0)
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
نتیجه
این نوت بوک چند تکنیک را برای حل مشکل رگرسیون معرفی می کند. در اینجا چند نکته دیگر وجود دارد که ممکن است کمک کند:
- میانگین مربعات خطا (MSE) (
tf.losses.MeanSquaredError) و میانگین خطای مطلق (MAE) (tf.losses.MeanAbsoluteError) توابع ضرر متداول هستند که برای مشکلات رگرسیون استفاده می شوند. MAE نسبت به موارد پرت حساسیت کمتری دارد. توابع زیان متفاوتی برای مسائل طبقه بندی استفاده می شود. - به طور مشابه، معیارهای ارزیابی مورد استفاده برای رگرسیون با طبقه بندی متفاوت است.
- وقتی ویژگیهای داده ورودی عددی مقادیری با محدودههای مختلف دارند، هر ویژگی باید به طور مستقل در همان محدوده مقیاس شود.
- نصب بیش از حد یک مشکل رایج برای مدلهای DNN است، اگرچه برای این آموزش مشکلی نبود. برای راهنمایی بیشتر در این زمینه به آموزش Overfit and underfit مراجعه کنید.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.