
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này trình bày phân loại văn bản bắt đầu từ các tệp văn bản thuần túy được lưu trữ trên đĩa. Bạn sẽ đào tạo một bộ phân loại nhị phân để thực hiện phân tích tình cảm trên tập dữ liệu IMDB. Ở cuối sổ ghi chép, có một bài tập để bạn thử, trong đó bạn sẽ đào tạo một bộ phân loại nhiều lớp để dự đoán thẻ cho một câu hỏi lập trình trên Stack Overflow.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
Phân tích tình cảm
Sổ tay này đào tạo mô hình phân tích tình cảm để phân loại các bài đánh giá phim là tích cực hay tiêu cực , dựa trên nội dung của bài đánh giá. Đây là một ví dụ về phân loại nhị phân — hay hai lớp —, một dạng vấn đề học máy quan trọng và có thể áp dụng rộng rãi.
Bạn sẽ sử dụng Tập dữ liệu đánh giá phim lớn chứa văn bản của 50.000 bài đánh giá phim từ Cơ sở dữ liệu phim trên Internet . Chúng được chia thành 25.000 đánh giá để đào tạo và 25.000 đánh giá để kiểm tra. Các bộ đào tạo và kiểm tra được cân bằng , có nghĩa là chúng chứa một số lượng bằng nhau về đánh giá tích cực và tiêu cực.
Tải xuống và khám phá tập dữ liệu IMDB
Hãy tải xuống và giải nén tập dữ liệu, sau đó khám phá cấu trúc thư mục.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
Các aclImdb/train/pos và aclImdb/train/neg chứa nhiều tệp văn bản, mỗi tệp là một bài đánh giá phim duy nhất. Chúng ta hãy nhìn vào một trong số họ.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
Tải tập dữ liệu
Tiếp theo, bạn sẽ tải dữ liệu ra đĩa và chuẩn bị nó thành một định dạng phù hợp để đào tạo. Để làm như vậy, bạn sẽ sử dụng tiện ích text_dataset_from_directory hữu ích, tiện ích mong đợi một cấu trúc thư mục như sau.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
Để chuẩn bị một tập dữ liệu cho phân loại nhị phân, bạn sẽ cần hai thư mục trên đĩa, tương ứng với class_a và class_b . Đây sẽ là những đánh giá tích cực và tiêu cực về phim, có thể được tìm thấy trong aclImdb/train/pos và aclImdb/train/neg . Vì tập dữ liệu IMDB chứa các thư mục bổ sung, bạn sẽ xóa chúng trước khi sử dụng tiện ích này.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Tiếp theo, bạn sẽ sử dụng tiện ích text_dataset_from_directory để tạo một tf.data.Dataset có nhãn. tf.data là một tập hợp các công cụ mạnh mẽ để làm việc với dữ liệu.
Khi chạy thử nghiệm học máy, cách tốt nhất là chia tập dữ liệu của bạn thành ba phần: đào tạo , xác thực và kiểm tra .
Tập dữ liệu IMDB đã được chia thành huấn luyện và thử nghiệm, nhưng nó thiếu tập hợp xác thực. Hãy tạo một bộ xác thực bằng cách sử dụng phần tách 80:20 của dữ liệu huấn luyện bằng cách sử dụng đối số validation_split bên dưới.
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
Như bạn có thể thấy ở trên, có 25.000 ví dụ trong thư mục đào tạo, trong đó bạn sẽ sử dụng 80% (hoặc 20.000) để đào tạo. Như bạn sẽ thấy trong giây lát, bạn có thể đào tạo một mô hình bằng cách chuyển trực tiếp tập dữ liệu đến model.fit . Nếu bạn chưa quen với tf.data , bạn cũng có thể lặp lại tập dữ liệu và in ra một vài ví dụ như sau.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
Lưu ý rằng các bài đánh giá có chứa văn bản thô (với dấu chấm câu và các thẻ HTML không thường xuyên như <br/> ). Bạn sẽ chỉ ra cách xử lý những điều này trong phần sau.
Các nhãn là 0 hoặc 1. Để xem nhãn nào trong số này tương ứng với các đánh giá tích cực và tiêu cực về phim, bạn có thể kiểm tra thuộc tính class_names trên tập dữ liệu.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
Tiếp theo, bạn sẽ tạo một tập dữ liệu kiểm tra và xác nhận. Bạn sẽ sử dụng 5.000 đánh giá còn lại từ bộ đào tạo để xác nhận.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
Chuẩn bị tập dữ liệu để đào tạo
Tiếp theo, bạn sẽ chuẩn hóa, mã hóa và vectơ hóa dữ liệu bằng cách sử dụng lớp tf.keras.layers.TextVectorization hữu ích.
Tiêu chuẩn hóa đề cập đến việc xử lý trước văn bản, thường là để loại bỏ dấu chấm câu hoặc các phần tử HTML để đơn giản hóa tập dữ liệu. Tokenization đề cập đến việc tách các chuỗi thành các mã thông báo (ví dụ: tách một câu thành các từ riêng lẻ, bằng cách tách trên khoảng trắng). Vectơ hóa đề cập đến việc chuyển đổi mã thông báo thành số để chúng có thể được đưa vào mạng nơ-ron. Tất cả các nhiệm vụ này có thể được thực hiện với lớp này.
Như bạn đã thấy ở trên, các bài đánh giá chứa nhiều thẻ HTML khác nhau như <br /> . Các thẻ này sẽ không bị xóa bởi trình chuẩn hóa mặc định trong lớp TextVectorization (chuyển đổi văn bản thành chữ thường và loại bỏ dấu chấm câu theo mặc định, nhưng không loại bỏ HTML). Bạn sẽ viết một hàm tiêu chuẩn hóa tùy chỉnh để loại bỏ HTML.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
Tiếp theo, bạn sẽ tạo một lớp TextVectorization . Bạn sẽ sử dụng lớp này để chuẩn hóa, mã hóa và vectơ hóa dữ liệu của chúng tôi. Bạn đặt output_mode thành int để tạo các chỉ số nguyên duy nhất cho mỗi mã thông báo.
Lưu ý rằng bạn đang sử dụng chức năng phân tách mặc định và chức năng tiêu chuẩn hóa tùy chỉnh mà bạn đã xác định ở trên. Bạn cũng sẽ xác định một số hằng số cho mô hình, chẳng hạn như độ dài sequence_length tối đa rõ ràng, điều này sẽ khiến lớp đệm hoặc cắt bớt các chuỗi thành các giá trị độ dài sequence_length chính xác.
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
Tiếp theo, bạn sẽ gọi adapt để phù hợp với trạng thái của lớp tiền xử lý với tập dữ liệu. Điều này sẽ làm cho mô hình xây dựng một chỉ mục của chuỗi thành số nguyên.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
Hãy tạo một hàm để xem kết quả của việc sử dụng lớp này để xử lý trước một số dữ liệu.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
Như bạn có thể thấy ở trên, mỗi mã thông báo đã được thay thế bằng một số nguyên. Bạn có thể tra cứu mã thông báo (chuỗi) mà mỗi số nguyên tương ứng bằng cách gọi .get_vocabulary() trên lớp.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
Bạn gần như đã sẵn sàng để đào tạo người mẫu của mình. Là bước tiền xử lý cuối cùng, bạn sẽ áp dụng lớp TextVectorization mà bạn đã tạo trước đó cho tập dữ liệu huấn luyện, xác thực và thử nghiệm.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
Định cấu hình tập dữ liệu cho hiệu suất
Đây là hai phương pháp quan trọng bạn nên sử dụng khi tải dữ liệu để đảm bảo rằng I / O không bị chặn.
.cache() giữ dữ liệu trong bộ nhớ sau khi nó được tải ra khỏi đĩa. Điều này sẽ đảm bảo tập dữ liệu không trở thành nút cổ chai trong khi đào tạo mô hình của bạn. Nếu tập dữ liệu của bạn quá lớn để vừa với bộ nhớ, bạn cũng có thể sử dụng phương pháp này để tạo bộ đệm ẩn trên đĩa hiệu quả, hiệu quả hơn để đọc so với nhiều tệp nhỏ.
.prefetch() chồng lên quá trình tiền xử lý dữ liệu và thực thi mô hình trong khi đào tạo.
Bạn có thể tìm hiểu thêm về cả hai phương pháp cũng như cách lưu trữ dữ liệu vào đĩa trong hướng dẫn về hiệu suất dữ liệu .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Tạo mô hình
Đã đến lúc tạo mạng nơ-ron của bạn:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
Các lớp được xếp chồng lên nhau tuần tự để xây dựng bộ phân loại:
- Lớp đầu tiên là một lớp
Embedding. Lớp này nhận các đánh giá được mã hóa số nguyên và tìm kiếm một vectơ nhúng cho mỗi từ-chỉ mục. Các vectơ này được học khi mô hình đào tạo. Các vectơ thêm một thứ nguyên vào mảng đầu ra. Các kích thước kết quả là:(batch, sequence, embedding). Để tìm hiểu thêm về cách nhúng, hãy xem hướng dẫn nhúng từ . - Tiếp theo, một lớp
GlobalAveragePooling1Dtrả về một vectơ đầu ra có độ dài cố định cho mỗi ví dụ bằng cách lấy trung bình trên thứ nguyên trình tự. Điều này cho phép mô hình xử lý đầu vào có độ dài thay đổi, theo cách đơn giản nhất có thể. - Vectơ đầu ra có độ dài cố định này được chuyển qua một lớp được kết nối đầy đủ (
Dense) với 16 đơn vị ẩn. - Lớp cuối cùng được kết nối dày đặc với một nút đầu ra duy nhất.
Chức năng mất mát và trình tối ưu hóa
Một mô hình cần một chức năng mất mát và một trình tối ưu hóa để đào tạo. Vì đây là một vấn đề phân loại nhị phân và mô hình xuất ra một xác suất (một lớp đơn vị với kích hoạt sigmoid), bạn sẽ sử dụng hàm mất losses.BinaryCrossentropy .
Bây giờ, hãy định cấu hình mô hình để sử dụng một trình tối ưu hóa và một hàm mất mát:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
Đào tạo mô hình
Bạn sẽ huấn luyện mô hình bằng cách chuyển đối tượng dataset sang phương thức fit.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
Đánh giá mô hình
Hãy xem mô hình hoạt động như thế nào. Hai giá trị sẽ được trả về. Mất mát (một con số đại diện cho lỗi của chúng tôi, giá trị càng thấp càng tốt) và độ chính xác.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
Cách tiếp cận khá ngây thơ này đạt độ chính xác khoảng 86%.
Tạo một biểu đồ về độ chính xác và mất mát theo thời gian
model.fit() trả về đối tượng History có chứa từ điển với mọi thứ đã xảy ra trong quá trình đào tạo:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
Có bốn mục nhập: một mục cho mỗi chỉ số được giám sát trong quá trình đào tạo và xác nhận. Bạn có thể sử dụng chúng để lập biểu đồ về sự mất mát trong quá trình đào tạo và xác thực để so sánh, cũng như độ chính xác của quá trình đào tạo và xác nhận:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
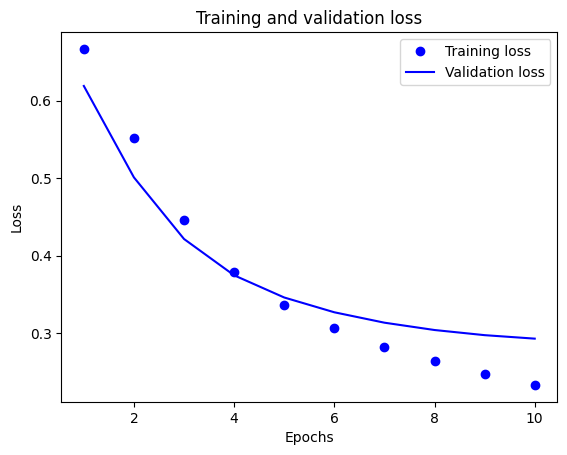
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
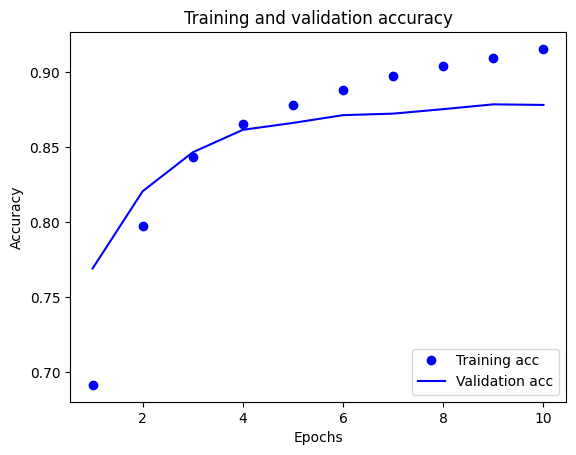
Trong biểu đồ này, các dấu chấm thể hiện sự mất mát trong quá trình huấn luyện và độ chính xác, còn các đường liền là sự mất xác thực và độ chính xác.
Lưu ý rằng tổn thất đào tạo giảm dần theo từng kỷ nguyên và độ chính xác đào tạo tăng lên theo từng kỷ nguyên. Điều này được mong đợi khi sử dụng tối ưu hóa giảm dần độ dốc — nó sẽ giảm thiểu số lượng mong muốn trên mỗi lần lặp.
Đây không phải là trường hợp của việc mất xác thực và độ chính xác — chúng dường như đạt đỉnh trước độ chính xác của quá trình huấn luyện. Đây là một ví dụ về overfitting: mô hình hoạt động tốt hơn trên dữ liệu đào tạo so với dữ liệu mà nó chưa từng thấy trước đây. Sau thời điểm này, mô hình tối ưu hóa quá mức và học các đại diện cụ thể cho dữ liệu đào tạo mà không tổng quát hóa để kiểm tra dữ liệu.
Đối với trường hợp cụ thể này, bạn có thể ngăn chặn việc trang bị quá mức bằng cách dừng đào tạo khi độ chính xác xác nhận không còn tăng nữa. Một cách để làm như vậy là sử dụng lệnh gọi lại tf.keras.callbacks.EarlyStopping .
Xuất mô hình
Trong đoạn mã trên, bạn đã áp dụng lớp TextVectorization cho tập dữ liệu trước khi cung cấp văn bản cho mô hình. Nếu bạn muốn làm cho mô hình của mình có khả năng xử lý các chuỗi thô (ví dụ: để đơn giản hóa việc triển khai nó), bạn có thể bao gồm lớp TextVectorization bên trong mô hình của mình. Để làm như vậy, bạn có thể tạo một mô hình mới bằng cách sử dụng khối lượng tạ vừa tập.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
Suy luận về dữ liệu mới
Để nhận dự đoán cho các ví dụ mới, bạn có thể chỉ cần gọi model.predict() .
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
Bao gồm logic tiền xử lý văn bản bên trong mô hình của bạn cho phép bạn xuất một mô hình để sản xuất giúp đơn giản hóa việc triển khai và giảm khả năng xảy ra sai lệch đào tạo / thử nghiệm .
Có một sự khác biệt về hiệu suất cần lưu ý khi chọn vị trí áp dụng lớp TextVectorization của bạn. Sử dụng nó bên ngoài mô hình của bạn cho phép bạn xử lý CPU không đồng bộ và lưu vào bộ đệm dữ liệu của bạn khi đào tạo về GPU. Vì vậy, nếu bạn đang đào tạo mô hình của mình trên GPU, bạn có thể muốn sử dụng tùy chọn này để có được hiệu suất tốt nhất trong khi phát triển mô hình của mình, sau đó chuyển sang bao gồm lớp TextVectorization bên trong mô hình của bạn khi bạn sẵn sàng chuẩn bị triển khai .
Truy cập hướng dẫn này để tìm hiểu thêm về các mô hình tiết kiệm.
Bài tập: phân loại nhiều lớp trên câu hỏi Stack Overflow
Hướng dẫn này đã chỉ ra cách đào tạo một bộ phân loại nhị phân từ đầu trên tập dữ liệu IMDB. Như một bài tập, bạn có thể sửa đổi sổ ghi chép này để đào tạo một bộ phân loại nhiều lớp để dự đoán thẻ của một câu hỏi lập trình trên Stack Overflow .
Một tập dữ liệu đã được chuẩn bị để bạn sử dụng có chứa nội dung của hàng nghìn câu hỏi lập trình (ví dụ: "Làm cách nào để sắp xếp từ điển theo giá trị trong Python?") Được đăng lên Stack Overflow. Mỗi trong số này được gắn nhãn bằng chính xác một thẻ (Python, CSharp, JavaScript hoặc Java). Nhiệm vụ của bạn là lấy một câu hỏi làm đầu vào và dự đoán thẻ thích hợp, trong trường hợp này là Python.
Tập dữ liệu bạn sẽ làm việc chứa hàng nghìn câu hỏi được trích xuất từ tập dữ liệu Stack Overflow công khai lớn hơn nhiều trên BigQuery , chứa hơn 17 triệu bài đăng.
Sau khi tải xuống tập dữ liệu, bạn sẽ thấy nó có cấu trúc thư mục tương tự với tập dữ liệu IMDB mà bạn đã làm việc trước đó:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
Để hoàn thành bài tập này, bạn nên sửa đổi sổ ghi chép này để làm việc với tập dữ liệu Stack Overflow bằng cách thực hiện các sửa đổi sau:
Ở đầu sổ ghi chép của bạn, hãy cập nhật mã tải xuống tập dữ liệu IMDB với mã để tải xuống tập dữ liệu Stack Overflow đã được chuẩn bị. Vì tập dữ liệu Stack Overflow có cấu trúc thư mục tương tự, bạn sẽ không cần thực hiện nhiều sửa đổi.
Sửa đổi lớp cuối cùng của mô hình của bạn thành
Dense(4), vì bây giờ có bốn lớp đầu ra.Khi biên dịch mô hình, hãy thay đổi tổn thất thành
tf.keras.losses.SparseCategoricalCrossentropy. Đây là hàm mất đúng để sử dụng cho bài toán phân loại nhiều lớp, khi nhãn cho mỗi lớp là số nguyên (trong trường hợp này, chúng có thể là 0, 1 , 2 hoặc 3 ). Ngoài ra, hãy thay đổi số liệu thànhmetrics=['accuracy'], vì đây là bài toán phân loại nhiều lớp (tf.metrics.BinaryAccuracychỉ được sử dụng cho bộ phân loại nhị phân).Khi vẽ biểu đồ độ chính xác theo thời gian, hãy thay đổi độ chính xác
binary_accuracyvàval_binary_accuracythànhaccuracyvà độ chính xácval_accuracy, tương ứng.Khi những thay đổi này hoàn tất, bạn sẽ có thể đào tạo một bộ phân loại nhiều lớp.
Học nhiều hơn nữa
Hướng dẫn này đã giới thiệu phân loại văn bản từ đầu. Để tìm hiểu thêm về quy trình phân loại văn bản nói chung, hãy xem Hướng dẫn phân loại văn bản từ Google Developers.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.