
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה מדגים סיווג טקסט החל מקובצי טקסט רגיל המאוחסנים בדיסק. אתה תאמן מסווג בינארי לבצע ניתוח סנטימנטים על מערך נתונים IMDB. בסוף המחברת, יש תרגיל שתוכל לנסות, בו תאמן מסווג רב-מעמדי לחזות את התג עבור שאלת תכנות ב-Stack Overflow.
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
ניתוח הסנטימנט
מחברת זו מאמנת מודל ניתוח סנטימנטים כדי לסווג ביקורות סרטים כחיוביות או שליליות , בהתבסס על טקסט הביקורת. זוהי דוגמה לסיווג בינארי - או דו-כיתתי -, סוג חשוב וישים נרחב של בעיית למידת מכונה.
אתה תשתמש בערכת סקירת הסרטים הגדולה שמכילה את הטקסט של 50,000 ביקורות סרטים ממסד הנתונים של הסרטים באינטרנט . אלה מחולקים ל-25,000 ביקורות לאימון ו-25,000 ביקורות לבדיקה. ערכות ההדרכה והבדיקות מאוזנות , כלומר מכילות מספר שווה של ביקורות חיוביות ושליליות.
הורד וחקור את מערך הנתונים של IMDB
בואו להוריד ולחלץ את מערך הנתונים, ואז לחקור את מבנה הספריות.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
aclImdb/train/pos ו- aclImdb/train/neg מכילות קבצי טקסט רבים, שכל אחד מהם הוא סקירת סרט בודדת. בואו נסתכל על אחד מהם.
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
טען את מערך הנתונים
לאחר מכן, תטען את הנתונים מהדיסק ותכין אותם לפורמט המתאים לאימון. לשם כך, תשתמש בכלי השירות המועיל text_dataset_from_directory , אשר מצפה למבנה ספריות כדלקמן.
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
כדי להכין מערך נתונים לסיווג בינארי, תזדקק לשתי תיקיות בדיסק, המתאימות ל- class_a ו- class_b . אלו יהיו ביקורות הסרטים החיוביות והשליליות, שניתן למצוא ב- aclImdb/train/pos ו- aclImdb/train/neg . מכיוון שמערך הנתונים של IMDB מכיל תיקיות נוספות, תסיר אותן לפני השימוש בכלי השירות הזה.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
לאחר מכן, תשתמש בכלי השירות text_dataset_from_directory כדי ליצור קובץ שכותרתו tf.data.Dataset . tf.data הוא אוסף רב עוצמה של כלים לעבודה עם נתונים.
בעת הפעלת ניסוי למידת מכונה, השיטה המומלצת היא לחלק את מערך הנתונים לשלושה פיצולים: הדרכה , אימות ובדיקה .
מערך הנתונים של IMDB כבר חולק לרכבת ולבדיקה, אך חסר לו ערכת אימות. בואו ניצור ערכת אימות באמצעות פיצול של 80:20 של נתוני האימון באמצעות הארגומנט validation_split למטה.
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
כפי שניתן לראות למעלה, בתיקיית ההדרכה יש 25,000 דוגמאות, מהן תשתמשו ב-80% (או 20,000) להדרכה. כפי שתראה בעוד רגע, אתה יכול לאמן מודל על ידי העברת מערך נתונים ישירות אל model.fit . אם אתה חדש ב- tf.data , אתה יכול גם לעבור על מערך הנתונים ולהדפיס כמה דוגמאות כדלקמן.
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1
שימו לב שהביקורות מכילות טקסט גולמי (עם סימני פיסוק ותגי HTML מדי פעם כמו <br/> ). תראה כיצד להתמודד עם אלה בסעיף הבא.
התוויות הן 0 או 1. כדי לראות אילו מהן מתאימות לביקורות סרטים חיוביות ושליליות, תוכל לבדוק את המאפיין class_names במערך הנתונים.
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
לאחר מכן, תיצור מערך אימות ובדיקה. אתה תשתמש ב-5,000 הביקורות הנותרות ממערך ההדרכה לצורך אימות.
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
הכן את מערך הנתונים להדרכה
לאחר מכן, תתקן, תעשה אסימון ותעשה וקטור את הנתונים באמצעות שכבת tf.keras.layers.TextVectorization .
סטנדרטיזציה מתייחסת לעיבוד מוקדם של הטקסט, בדרך כלל להסרת סימני פיסוק או רכיבי HTML כדי לפשט את מערך הנתונים. טוקניזציה מתייחסת לפיצול מחרוזות לאסימונים (לדוגמה, פיצול משפט למילים בודדות, על ידי פיצול על רווח לבן). וקטוריזציה מתייחסת להמרת אסימונים למספרים כך שניתן יהיה להזין אותם לרשת עצבית. ניתן לבצע את כל המשימות הללו בשכבה זו.
כפי שראית למעלה, הביקורות מכילות תגי HTML שונים כמו <br /> . תגים אלו לא יוסרו על ידי תקן ברירת המחדל בשכבת TextVectorization (הממיר טקסט לאותיות קטנות ומסיר סימני פיסוק כברירת מחדל, אך אינו מסיר HTML). תכתוב פונקציית סטנדרטיזציה מותאמת אישית כדי להסיר את ה-HTML.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
לאחר מכן, תיצור שכבת TextVectorization . אתה תשתמש בשכבה זו לסטנדרטיזציה, אסימון וקטוריזציה של הנתונים שלנו. אתה מגדיר את output_mode ל- int כדי ליצור מדדי מספר שלם ייחודיים עבור כל אסימון.
שים לב שאתה משתמש בפונקציית הפיצול המוגדרת כברירת מחדל, ובפונקציית הסטנדרטיזציה המותאמת אישית שהגדרת למעלה. אתה גם תגדיר כמה קבועים עבור המודל, כמו sequence_length מפורש, שיגרום לשכבה לרפד או לקצץ רצפים בדיוק לערכי sequence_length .
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
לאחר מכן, תקרא adapt כדי להתאים את מצב שכבת העיבוד המקדים למערך הנתונים. זה יגרום למודל לבנות אינדקס של מחרוזות למספרים שלמים.
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
בואו ניצור פונקציה כדי לראות את התוצאה של שימוש בשכבה זו לעיבוד מקדים של נתונים מסוימים.
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
כפי שניתן לראות למעלה, כל אסימון הוחלף במספר שלם. אתה יכול לחפש את האסימון (מחרוזת) שכל מספר שלם מתאים לו על ידי קריאה ל-. .get_vocabulary() בשכבה.
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
אתה כמעט מוכן לאמן את הדגם שלך. כשלב אחרון בעיבוד מקדים, תחיל את שכבת TextVectorization שיצרת קודם לכן על מערך הרכבת, האימות והבדיקה.
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
הגדר את מערך הנתונים לביצועים
אלו הן שתי שיטות חשובות שבהן אתה צריך להשתמש בעת טעינת נתונים כדי לוודא שהקלט/פלט לא ייחסם.
.cache() שומר נתונים בזיכרון לאחר טעינתם מהדיסק. זה יבטיח שמערך הנתונים לא יהפוך לצוואר בקבוק בזמן אימון המודל שלך. אם מערך הנתונים שלך גדול מכדי להתאים לזיכרון, אתה יכול גם להשתמש בשיטה זו כדי ליצור מטמון בעל ביצועים בדיסק, שיותר יעיל לקריאה מקבצים קטנים רבים.
.prefetch() חופף לעיבוד מקדים של נתונים וביצוע מודלים בזמן האימון.
תוכל ללמוד עוד על שתי השיטות, כמו גם כיצד לשמר נתונים בדיסק במדריך ביצועי הנתונים .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
צור את הדגם
הגיע הזמן ליצור את הרשת העצבית שלך:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
השכבות מוערמות ברצף כדי לבנות את המסווג:
- השכבה הראשונה היא שכבת
Embedding. שכבה זו לוקחת את הסקירות המקודדות במספרים שלמים ומחפשת וקטור הטמעה עבור כל אינדקס מילים. וקטורים אלה נלמדים כאשר המודל מתאמן. הוקטורים מוסיפים מימד למערך הפלט. הממדים המתקבלים הם:(batch, sequence, embedding). למידע נוסף על הטמעות, עיין במדריך המילה הטמעה . - לאחר מכן, שכבת
GlobalAveragePooling1Dמחזירה וקטור פלט באורך קבוע עבור כל דוגמה על ידי ממוצע על ממד הרצף. זה מאפשר למודל לטפל בקלט באורך משתנה, בצורה הפשוטה ביותר. - וקטור פלט זה באורך קבוע מועבר דרך שכבה מחוברת מלאה (
Dense) עם 16 יחידות נסתרות. - השכבה האחרונה מחוברת בצפיפות עם צומת פלט יחיד.
פונקציית אובדן ואופטימיזציה
דגם צריך פונקציית אובדן ואופטימיזר לאימון. מכיוון שזו בעיית סיווג בינארי והמודל מוציא הסתברות (שכבה של יחידה אחת עם הפעלת סיגמואידית), תשתמש בפונקציית losses.BinaryCrossentropy loss.
כעת, הגדר את המודל לשימוש באופטימיזציה ובפונקציית אובדן:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
אימון הדגם
אתה תאמן את המודל על ידי העברת אובייקט dataset לשיטת ההתאמה.
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
העריכו את המודל
בואו נראה איך הדגם מתפקד. שני ערכים יוחזרו. הפסד (מספר המייצג את השגיאה שלנו, ערכים נמוכים יותר טובים יותר), ודיוק.
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
גישה נאיבית למדי זו משיגה דיוק של כ-86%.
צור עלילה של דיוק ואובדן לאורך זמן
model.fit() מחזיר אובייקט History המכיל מילון עם כל מה שקרה במהלך האימון:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
ישנן ארבע ערכים: אחד לכל מדד מנוטר במהלך ההדרכה והאימות. אתה יכול להשתמש באלה כדי לשרטט את אובדן האימון והאימות לצורך השוואה, כמו גם את דיוק ההדרכה והאימות:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
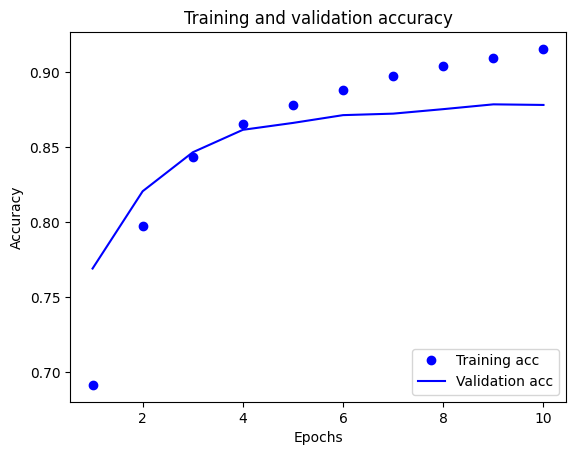
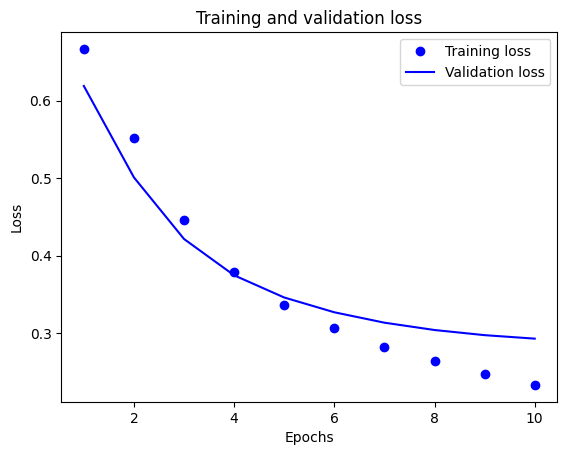
בעלילה זו, הנקודות מייצגות את אובדן האימון והדיוק, והקווים המוצקים הם אובדן האימות והדיוק.
שימו לב שהפסד האימון יורד עם כל תקופה ודיוק האימון עולה עם כל תקופה. זה צפוי בעת שימוש באופטימיזציה של ירידה בשיפוע - זה אמור למזער את הכמות הרצויה בכל איטרציה.
זה לא המקרה של אובדן האימות והדיוק - נראה שהם מגיעים לשיא לפני דיוק האימון. זוהי דוגמה להתאמת יתר: המודל מתפקד טוב יותר בנתוני האימון מאשר בנתונים שלא ראה מעולם. לאחר נקודה זו, המודל מבצע אופטימיזציה יתר ולומד ייצוגים ספציפיים לנתוני האימון שאינם מכלילים לנתוני בדיקה.
במקרה הספציפי הזה, תוכל למנוע התאמת יתר על ידי עצירת האימון כאשר דיוק האימות אינו עולה עוד. אחת הדרכים לעשות זאת היא להשתמש ב- tf.keras.callbacks.EarlyStopping callback.
ייצא את הדגם
בקוד שלמעלה, החלת את שכבת TextVectorization על מערך הנתונים לפני הזנת טקסט למודל. אם אתה רוצה להפוך את המודל שלך למסוגל לעבד מחרוזות גולמיות (לדוגמה, כדי לפשט את הפריסה שלו), אתה יכול לכלול את שכבת TextVectorization בתוך המודל שלך. לשם כך, תוכל ליצור דגם חדש באמצעות המשקולות שזה עתה אימנת.
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
הסקה על נתונים חדשים
כדי לקבל תחזיות עבור דוגמאות חדשות, אתה יכול פשוט לקרוא model.predict() .
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
הכללת ההיגיון של עיבוד מוקדם של הטקסט בתוך המודל שלך מאפשרת לך לייצא מודל לייצור שמפשט את הפריסה, ומפחית את הפוטנציאל להטיית רכבת/בדיקה .
יש לזכור הבדל בביצועים בעת בחירת היכן ליישם את שכבת ה-TextVectorization. השימוש בו מחוץ לדגם שלך מאפשר לך לבצע עיבוד CPU אסינכרוני ואגירת הנתונים שלך בעת אימון על GPU. אז אם אתה מאמן את הדגם שלך על ה-GPU, אתה כנראה רוצה ללכת עם האפשרות הזו כדי לקבל את הביצועים הטובים ביותר בזמן פיתוח המודל שלך, ולאחר מכן עבור לכלול את שכבת TextVectorization בתוך המודל שלך כאשר אתה מוכן להתכונן לפריסה .
בקר במדריך זה כדי ללמוד עוד על שמירת דגמים.
תרגיל: סיווג רב כיתתי בשאלות Stack Overflow
מדריך זה הראה כיצד לאמן מסווג בינארי מאפס במערך הנתונים של IMDB. כתרגיל, אתה יכול לשנות מחברת זו כדי לאמן מסווג רב-מעמדי לחזות את התג של שאלת תכנות ב- Stack Overflow .
הוכן עבורך מערך נתונים לשימוש המכיל את הגוף של כמה אלפי שאלות תכנות (לדוגמה, "איך אני יכול למיין מילון לפי ערך ב-Python?") שפורסמו ב-Stack Overflow. כל אחד מאלה מסומן בתג אחד בדיוק (Python, CSharp, JavaScript או Java). המשימה שלך היא לקחת שאלה כקלט, ולחזות את התג המתאים, במקרה זה, Python.
מערך הנתונים שאיתו תעבוד מכיל כמה אלפי שאלות שחולצו ממערך הנתונים הציבורי הגדול בהרבה של Stack Overflow ב- BigQuery , שמכיל יותר מ-17 מיליון פוסטים.
לאחר הורדת מערך הנתונים, תגלה שיש לו מבנה ספריות דומה למערך הנתונים של IMDB איתו עבדת בעבר:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
כדי להשלים תרגיל זה, עליך לשנות מחברת זו כך שתעבוד עם מערך הנתונים של Stack Overflow על ידי ביצוע השינויים הבאים:
בחלק העליון של המחברת שלך, עדכן את הקוד שמוריד את מערך הנתונים של IMDB עם קוד כדי להוריד את מערך הנתונים של Stack Overflow שכבר הוכן. מכיוון שלמערך הנתונים של Stack Overflow יש מבנה ספריות דומה, לא תצטרך לבצע שינויים רבים.
שנה את השכבה האחרונה של המודל שלך ל-
Dense(4), מכיוון שיש כעת ארבע מחלקות פלט.בעת הידור המודל, שנה את ההפסד ל-
tf.keras.losses.SparseCategoricalCrossentropy. זוהי פונקציית ההפסד הנכונה לשימוש עבור בעיית סיווג מרובה מחלקות, כאשר התוויות עבור כל מחלקה הן מספרים שלמים (במקרה זה, הן יכולות להיות 0, 1 , 2 או 3 ). בנוסף, שנה את המדדים ל-metrics=['accuracy'], מאחר ומדובר בבעיית סיווג מרובת מחלקות (tf.metrics.BinaryAccuracyמשמש רק למסווגים בינאריים).כאשר מתווים דיוק לאורך זמן, שנה את הדיוק הבינארי ואת
binary_accuracyשלval_binary_accuracyaccuracyו-val_accuracy, בהתאמה.לאחר השלמת השינויים הללו, תוכל להכשיר מסווג רב-מעמדי.
ללמוד עוד
מדריך זה הציג סיווג טקסט מאפס. למידע נוסף על זרימת העבודה של סיווג טקסט באופן כללי, עיין במדריך סיווג הטקסט של Google Developers.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.