
| | |  Lihat sumber di GitHub Lihat sumber di GitHub |
Tutorial ini adalah pengantar peramalan deret waktu menggunakan TensorFlow. Itu membangun beberapa gaya model yang berbeda termasuk Convolutional and Recurrent Neural Networks (CNNs dan RNNs).
Ini tercakup dalam dua bagian utama, dengan subbagian:
- Perkiraan untuk satu langkah waktu:
- Sebuah fitur tunggal.
- Semua fitur.
- Perkiraan beberapa langkah:
- Single-shot: Buat prediksi sekaligus.
- Autoregressive: Buat satu prediksi pada satu waktu dan berikan output kembali ke model.
Mempersiapkan
import os
import datetime
import IPython
import IPython.display
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import tensorflow as tf
mpl.rcParams['figure.figsize'] = (8, 6)
mpl.rcParams['axes.grid'] = False
Dataset cuaca
Tutorial ini menggunakan dataset deret waktu cuaca yang direkam oleh Max Planck Institute for Biogeochemistry .
Dataset ini berisi 14 fitur yang berbeda seperti suhu udara, tekanan atmosfer, dan kelembaban. Ini dikumpulkan setiap 10 menit, mulai tahun 2003. Untuk efisiensi, Anda hanya akan menggunakan data yang dikumpulkan antara 2009 dan 2016. Bagian kumpulan data ini disiapkan oleh François Chollet untuk bukunya Deep Learning with Python .
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip',
fname='jena_climate_2009_2016.csv.zip',
extract=True)
csv_path, _ = os.path.splitext(zip_path)
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip 13574144/13568290 [==============================] - 1s 0us/step 13582336/13568290 [==============================] - 1s 0us/step
Tutorial ini hanya akan membahas prediksi per jam , jadi mulailah dengan mensub-sampling data dari interval 10 menit hingga interval satu jam:
df = pd.read_csv(csv_path)
# Slice [start:stop:step], starting from index 5 take every 6th record.
df = df[5::6]
date_time = pd.to_datetime(df.pop('Date Time'), format='%d.%m.%Y %H:%M:%S')
Mari kita lihat datanya. Berikut adalah beberapa baris pertama:
df.head()
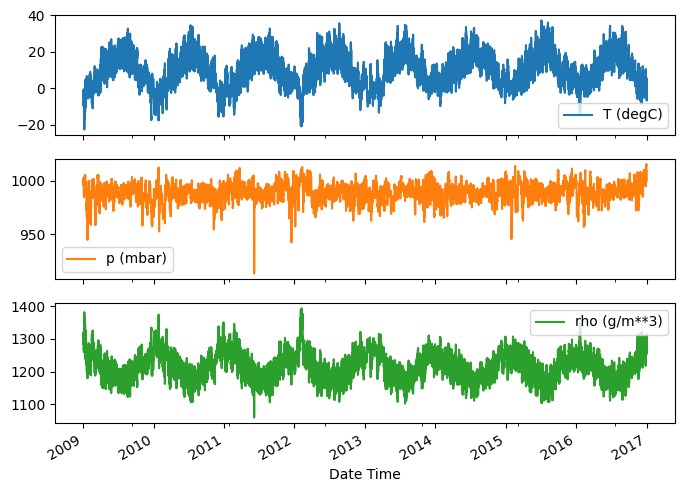
Berikut adalah evolusi dari beberapa fitur dari waktu ke waktu:
plot_cols = ['T (degC)', 'p (mbar)', 'rho (g/m**3)']
plot_features = df[plot_cols]
plot_features.index = date_time
_ = plot_features.plot(subplots=True)
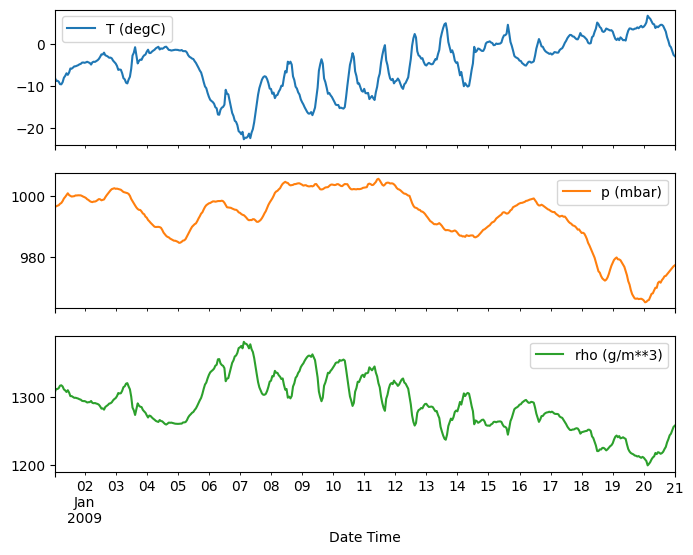
plot_features = df[plot_cols][:480]
plot_features.index = date_time[:480]
_ = plot_features.plot(subplots=True)
Periksa dan bersihkan
Selanjutnya, lihat statistik dataset:
df.describe().transpose()
Kecepatan angin
Satu hal yang harus diperhatikan adalah nilai min kecepatan angin ( wv (m/s) ) dan nilai maksimum ( max. wv (m/s) ) kolom. -9999 ini kemungkinan salah.
Ada kolom arah angin yang terpisah, jadi kecepatannya harus lebih besar dari nol ( >=0 ). Ganti dengan nol:
wv = df['wv (m/s)']
bad_wv = wv == -9999.0
wv[bad_wv] = 0.0
max_wv = df['max. wv (m/s)']
bad_max_wv = max_wv == -9999.0
max_wv[bad_max_wv] = 0.0
# The above inplace edits are reflected in the DataFrame.
df['wv (m/s)'].min()
0.0
Rekayasa fitur
Sebelum mendalami untuk membangun model, penting untuk memahami data Anda dan pastikan bahwa Anda meneruskan model dengan format data yang tepat.
Angin
Kolom terakhir dari data, wd (deg) —memberikan arah angin dalam satuan derajat. Sudut tidak membuat input model yang baik: 360° dan 0° harus saling berdekatan dan melingkar dengan mulus. Arah seharusnya tidak masalah jika angin tidak bertiup.
Saat ini distribusi data angin terlihat seperti ini:
plt.hist2d(df['wd (deg)'], df['wv (m/s)'], bins=(50, 50), vmax=400)
plt.colorbar()
plt.xlabel('Wind Direction [deg]')
plt.ylabel('Wind Velocity [m/s]')
Text(0, 0.5, 'Wind Velocity [m/s]')
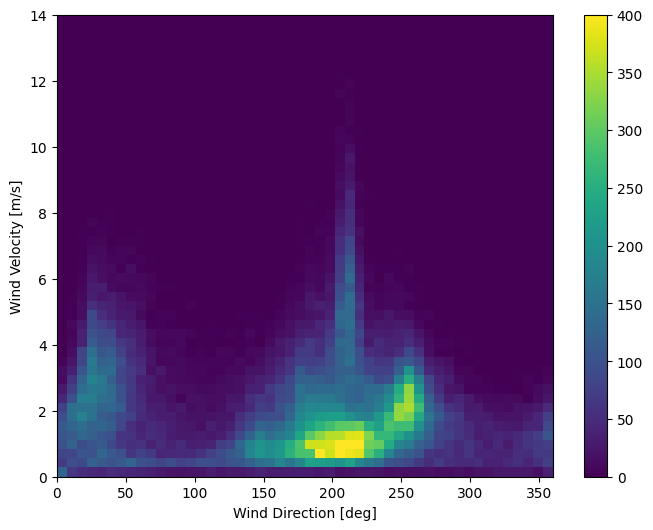
Tetapi ini akan lebih mudah diinterpretasikan oleh model jika Anda mengubah kolom arah dan kecepatan angin menjadi vektor angin :
wv = df.pop('wv (m/s)')
max_wv = df.pop('max. wv (m/s)')
# Convert to radians.
wd_rad = df.pop('wd (deg)')*np.pi / 180
# Calculate the wind x and y components.
df['Wx'] = wv*np.cos(wd_rad)
df['Wy'] = wv*np.sin(wd_rad)
# Calculate the max wind x and y components.
df['max Wx'] = max_wv*np.cos(wd_rad)
df['max Wy'] = max_wv*np.sin(wd_rad)
Distribusi vektor angin jauh lebih sederhana untuk model untuk menafsirkan dengan benar:
plt.hist2d(df['Wx'], df['Wy'], bins=(50, 50), vmax=400)
plt.colorbar()
plt.xlabel('Wind X [m/s]')
plt.ylabel('Wind Y [m/s]')
ax = plt.gca()
ax.axis('tight')
(-11.305513973134667, 8.24469928549079, -8.27438540335515, 7.7338312955467785)
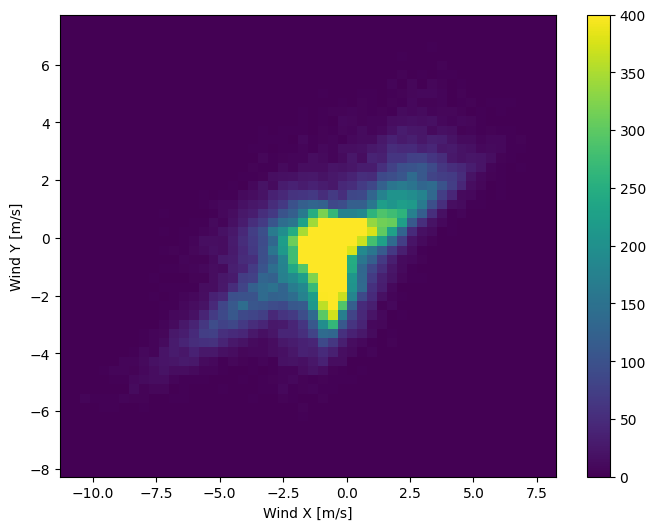
Waktu
Demikian pula, kolom Date Time sangat berguna, tetapi tidak dalam bentuk string ini. Mulailah dengan mengubahnya menjadi detik:
timestamp_s = date_time.map(pd.Timestamp.timestamp)
Mirip dengan arah angin, waktu dalam detik bukanlah input model yang berguna. Menjadi data cuaca, memiliki periodisitas harian dan tahunan yang jelas. Ada banyak cara untuk menangani periodisitas.
Anda bisa mendapatkan sinyal yang dapat digunakan dengan menggunakan transformasi sinus dan kosinus untuk menghapus sinyal "Waktu" dan "Waktu dalam setahun":
day = 24*60*60
year = (365.2425)*day
df['Day sin'] = np.sin(timestamp_s * (2 * np.pi / day))
df['Day cos'] = np.cos(timestamp_s * (2 * np.pi / day))
df['Year sin'] = np.sin(timestamp_s * (2 * np.pi / year))
df['Year cos'] = np.cos(timestamp_s * (2 * np.pi / year))
plt.plot(np.array(df['Day sin'])[:25])
plt.plot(np.array(df['Day cos'])[:25])
plt.xlabel('Time [h]')
plt.title('Time of day signal')
Text(0.5, 1.0, 'Time of day signal')
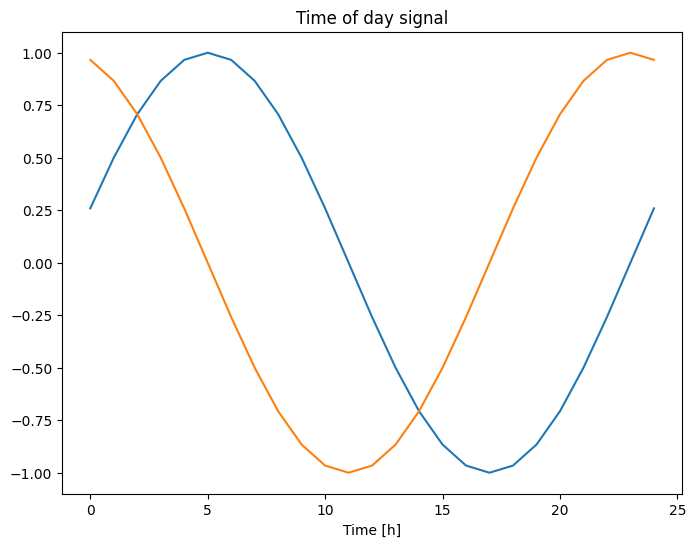
Ini memberikan akses model ke fitur frekuensi yang paling penting. Dalam hal ini Anda tahu sebelumnya frekuensi mana yang penting.
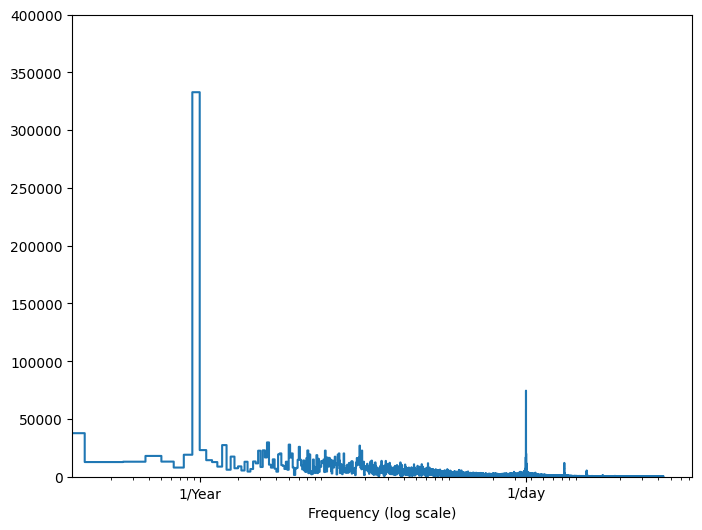
Jika Anda tidak memiliki informasi tersebut, Anda dapat menentukan frekuensi mana yang penting dengan mengekstrak fitur dengan Fast Fourier Transform . Untuk memeriksa asumsi, berikut adalah tf.signal.rfft dari suhu dari waktu ke waktu. Perhatikan puncak yang jelas pada frekuensi dekat 1/year dan 1/day :
fft = tf.signal.rfft(df['T (degC)'])
f_per_dataset = np.arange(0, len(fft))
n_samples_h = len(df['T (degC)'])
hours_per_year = 24*365.2524
years_per_dataset = n_samples_h/(hours_per_year)
f_per_year = f_per_dataset/years_per_dataset
plt.step(f_per_year, np.abs(fft))
plt.xscale('log')
plt.ylim(0, 400000)
plt.xlim([0.1, max(plt.xlim())])
plt.xticks([1, 365.2524], labels=['1/Year', '1/day'])
_ = plt.xlabel('Frequency (log scale)')
Pisahkan datanya
Anda akan menggunakan pembagian (70%, 20%, 10%) untuk set pelatihan, validasi, dan pengujian. Perhatikan bahwa data tidak dikocok secara acak sebelum dipecah. Ini karena dua alasan:
- Ini memastikan bahwa memotong data ke dalam jendela sampel berurutan masih dimungkinkan.
- Ini memastikan bahwa hasil validasi/pengujian lebih realistis, dievaluasi pada data yang dikumpulkan setelah model dilatih.
column_indices = {name: i for i, name in enumerate(df.columns)}
n = len(df)
train_df = df[0:int(n*0.7)]
val_df = df[int(n*0.7):int(n*0.9)]
test_df = df[int(n*0.9):]
num_features = df.shape[1]
Normalisasikan data
Penting untuk menskalakan fitur sebelum melatih jaringan saraf. Normalisasi adalah cara umum untuk melakukan penskalaan ini: kurangi rata-rata dan bagi dengan simpangan baku setiap fitur.
Rata-rata dan simpangan baku hanya boleh dihitung dengan menggunakan data pelatihan sehingga model tidak memiliki akses ke nilai dalam set validasi dan pengujian.
Juga dapat diperdebatkan bahwa model tidak boleh memiliki akses ke nilai masa depan dalam set pelatihan saat pelatihan, dan normalisasi ini harus dilakukan menggunakan rata-rata bergerak. Itu bukan fokus dari tutorial ini, dan set validasi dan pengujian memastikan bahwa Anda mendapatkan (agak) metrik yang jujur. Jadi, demi kesederhanaan tutorial ini menggunakan rata-rata sederhana.
train_mean = train_df.mean()
train_std = train_df.std()
train_df = (train_df - train_mean) / train_std
val_df = (val_df - train_mean) / train_std
test_df = (test_df - train_mean) / train_std
Sekarang, intip sebaran fiturnya. Beberapa fitur memang memiliki ekor yang panjang, tetapi tidak ada kesalahan yang jelas seperti nilai kecepatan angin -9999 .
df_std = (df - train_mean) / train_std
df_std = df_std.melt(var_name='Column', value_name='Normalized')
plt.figure(figsize=(12, 6))
ax = sns.violinplot(x='Column', y='Normalized', data=df_std)
_ = ax.set_xticklabels(df.keys(), rotation=90)

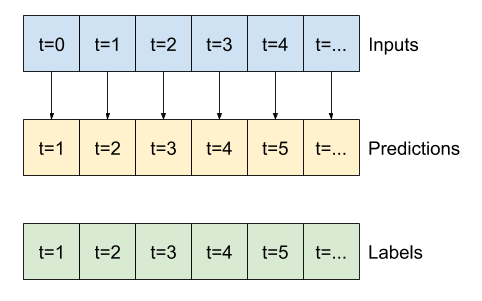
Jendela data
Model dalam tutorial ini akan membuat satu set prediksi berdasarkan jendela sampel berurutan dari data.
Fitur utama dari jendela input adalah:
- Lebar (jumlah langkah waktu) dari jendela input dan label.
- Jarak waktu di antara mereka.
- Fitur mana yang digunakan sebagai input, label, atau keduanya.
Tutorial ini membangun berbagai model (termasuk model Linear, DNN, CNN dan RNN), dan menggunakannya untuk keduanya:
- Prediksi keluaran tunggal , dan multi keluaran .
- Prediksi satu-waktu-langkah dan multi-waktu-langkah .
Bagian ini berfokus pada penerapan windowing data sehingga dapat digunakan kembali untuk semua model tersebut.
Tergantung pada tugas dan jenis model, Anda mungkin ingin menghasilkan berbagai jendela data. Berikut beberapa contohnya:
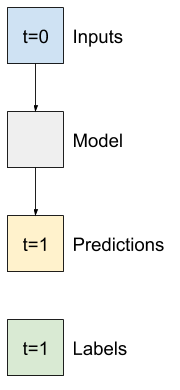
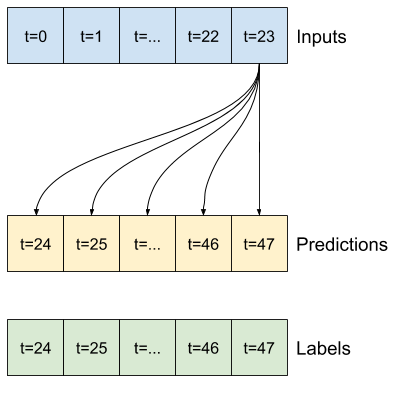
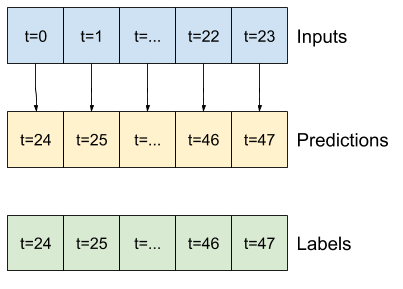
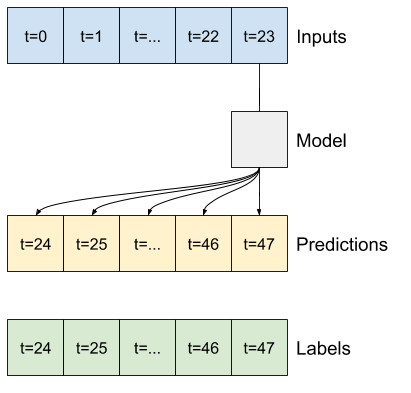
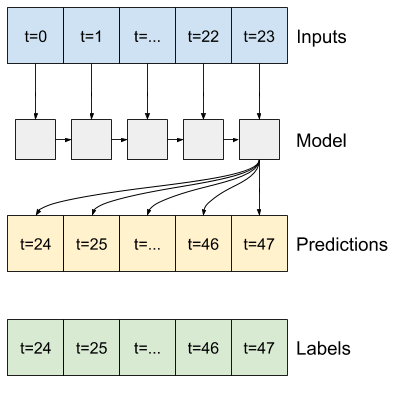
Misalnya, untuk membuat prediksi tunggal 24 jam ke depan, dengan riwayat 24 jam, Anda dapat menentukan jendela seperti ini:
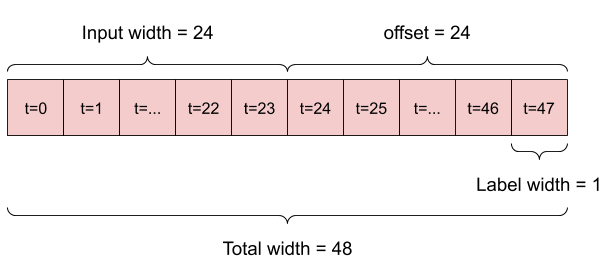
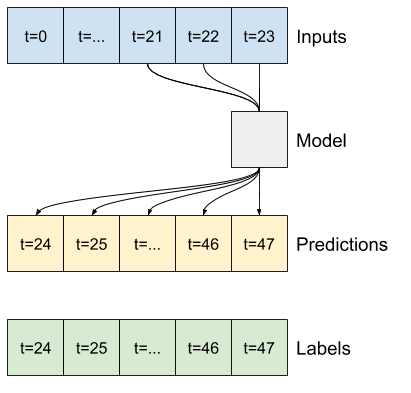
Sebuah model yang membuat prediksi satu jam ke depan, dengan sejarah enam jam, akan membutuhkan jendela seperti ini:

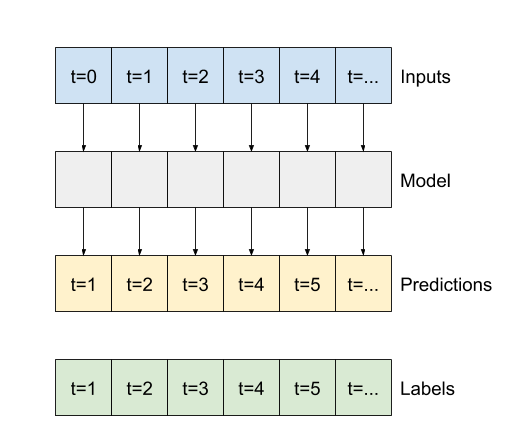
Sisa bagian ini mendefinisikan kelas WindowGenerator . Kelas ini dapat:
- Tangani indeks dan offset seperti yang ditunjukkan pada diagram di atas.
- Pisahkan jendela fitur menjadi pasangan
(features, labels). - Plot konten dari jendela yang dihasilkan.
- Buat kumpulan jendela ini secara efisien dari data pelatihan, evaluasi, dan pengujian, menggunakan
tf.data.Datasets.
1. Indeks dan offset
Mulailah dengan membuat kelas WindowGenerator . Metode __init__ mencakup semua logika yang diperlukan untuk indeks input dan label.
Ini juga membutuhkan pelatihan, evaluasi, dan pengujian DataFrames sebagai input. Ini akan dikonversi ke tf.data.Dataset s dari windows nanti.
class WindowGenerator():
def __init__(self, input_width, label_width, shift,
train_df=train_df, val_df=val_df, test_df=test_df,
label_columns=None):
# Store the raw data.
self.train_df = train_df
self.val_df = val_df
self.test_df = test_df
# Work out the label column indices.
self.label_columns = label_columns
if label_columns is not None:
self.label_columns_indices = {name: i for i, name in
enumerate(label_columns)}
self.column_indices = {name: i for i, name in
enumerate(train_df.columns)}
# Work out the window parameters.
self.input_width = input_width
self.label_width = label_width
self.shift = shift
self.total_window_size = input_width + shift
self.input_slice = slice(0, input_width)
self.input_indices = np.arange(self.total_window_size)[self.input_slice]
self.label_start = self.total_window_size - self.label_width
self.labels_slice = slice(self.label_start, None)
self.label_indices = np.arange(self.total_window_size)[self.labels_slice]
def __repr__(self):
return '\n'.join([
f'Total window size: {self.total_window_size}',
f'Input indices: {self.input_indices}',
f'Label indices: {self.label_indices}',
f'Label column name(s): {self.label_columns}'])
Berikut adalah kode untuk membuat 2 jendela yang ditunjukkan pada diagram di awal bagian ini:
w1 = WindowGenerator(input_width=24, label_width=1, shift=24,
label_columns=['T (degC)'])
w1
Total window size: 48 Input indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23] Label indices: [47] Label column name(s): ['T (degC)']
w2 = WindowGenerator(input_width=6, label_width=1, shift=1,
label_columns=['T (degC)'])
w2
Total window size: 7 Input indices: [0 1 2 3 4 5] Label indices: [6] Label column name(s): ['T (degC)']
2. Pisahkan
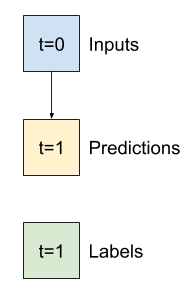
Diberikan daftar input berurutan, metode split_window akan mengonversinya menjadi jendela input dan jendela label.
Contoh w2 yang Anda tentukan sebelumnya akan dibagi seperti ini:
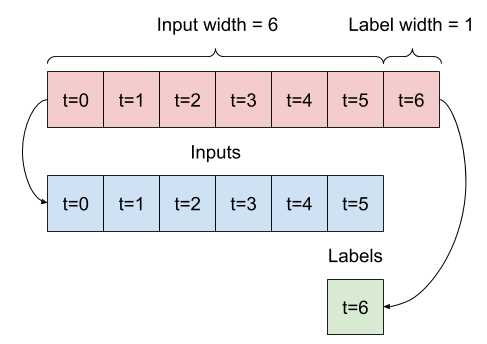
Diagram ini tidak menunjukkan sumbu features data, tetapi fungsi split_window ini juga menangani label_columns sehingga dapat digunakan untuk contoh output tunggal dan multi-output.
def split_window(self, features):
inputs = features[:, self.input_slice, :]
labels = features[:, self.labels_slice, :]
if self.label_columns is not None:
labels = tf.stack(
[labels[:, :, self.column_indices[name]] for name in self.label_columns],
axis=-1)
# Slicing doesn't preserve static shape information, so set the shapes
# manually. This way the `tf.data.Datasets` are easier to inspect.
inputs.set_shape([None, self.input_width, None])
labels.set_shape([None, self.label_width, None])
return inputs, labels
WindowGenerator.split_window = split_window
Cobalah:
# Stack three slices, the length of the total window.
example_window = tf.stack([np.array(train_df[:w2.total_window_size]),
np.array(train_df[100:100+w2.total_window_size]),
np.array(train_df[200:200+w2.total_window_size])])
example_inputs, example_labels = w2.split_window(example_window)
print('All shapes are: (batch, time, features)')
print(f'Window shape: {example_window.shape}')
print(f'Inputs shape: {example_inputs.shape}')
print(f'Labels shape: {example_labels.shape}')
All shapes are: (batch, time, features) Window shape: (3, 7, 19) Inputs shape: (3, 6, 19) Labels shape: (3, 1, 1)
Biasanya, data di TensorFlow dikemas ke dalam array dengan indeks terluar di seluruh contoh (dimensi "batch"). Indeks tengah adalah dimensi "waktu" atau "ruang" (lebar, tinggi). Indeks terdalam adalah fitur.
Kode di atas mengambil kumpulan tiga jendela langkah 7 kali dengan 19 fitur di setiap langkah waktu. Ini membaginya menjadi kumpulan input 19 fitur langkah 6 kali, dan label fitur 1 langkah langkah 1 kali. Label hanya memiliki satu fitur karena WindowGenerator diinisialisasi dengan label_columns=['T (degC)'] . Awalnya, tutorial ini akan membangun model yang memprediksi label keluaran tunggal.
3. Alur
Berikut adalah metode plot yang memungkinkan visualisasi sederhana dari jendela terpisah:
w2.example = example_inputs, example_labels
def plot(self, model=None, plot_col='T (degC)', max_subplots=3):
inputs, labels = self.example
plt.figure(figsize=(12, 8))
plot_col_index = self.column_indices[plot_col]
max_n = min(max_subplots, len(inputs))
for n in range(max_n):
plt.subplot(max_n, 1, n+1)
plt.ylabel(f'{plot_col} [normed]')
plt.plot(self.input_indices, inputs[n, :, plot_col_index],
label='Inputs', marker='.', zorder=-10)
if self.label_columns:
label_col_index = self.label_columns_indices.get(plot_col, None)
else:
label_col_index = plot_col_index
if label_col_index is None:
continue
plt.scatter(self.label_indices, labels[n, :, label_col_index],
edgecolors='k', label='Labels', c='#2ca02c', s=64)
if model is not None:
predictions = model(inputs)
plt.scatter(self.label_indices, predictions[n, :, label_col_index],
marker='X', edgecolors='k', label='Predictions',
c='#ff7f0e', s=64)
if n == 0:
plt.legend()
plt.xlabel('Time [h]')
WindowGenerator.plot = plot
Plot ini menyelaraskan input, label, dan prediksi (nanti) berdasarkan waktu yang dirujuk item:
w2.plot()
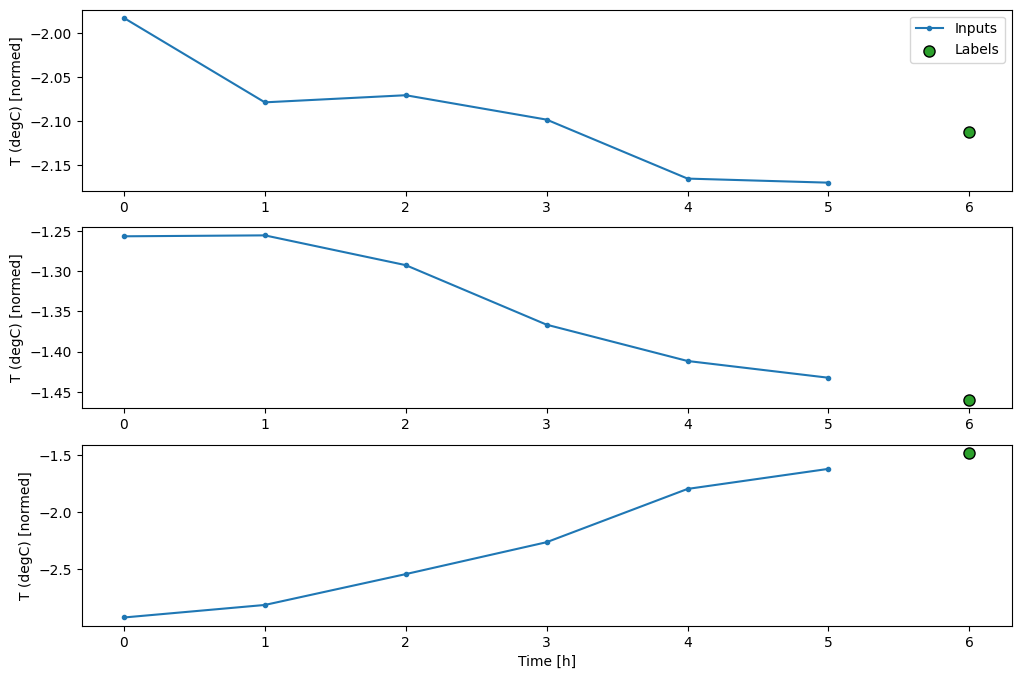
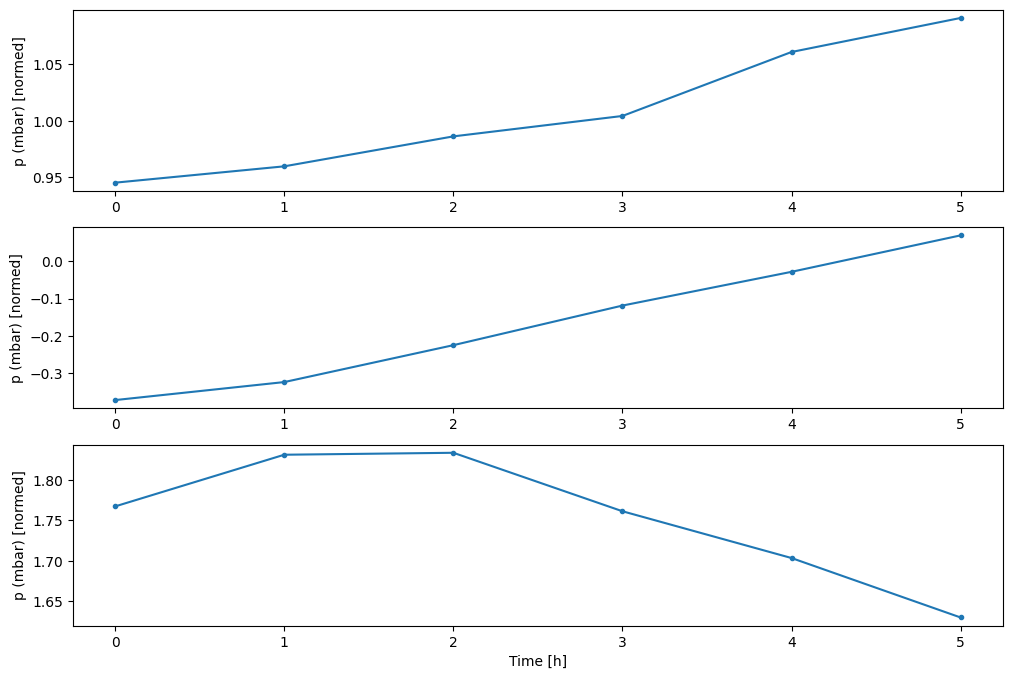
Anda dapat memplot kolom lain, tetapi konfigurasi jendela contoh w2 hanya memiliki label untuk kolom T (degC) .
w2.plot(plot_col='p (mbar)')
4. Buat tf.data.Dataset s
Terakhir, metode make_dataset ini akan menggunakan DataFrame deret waktu dan mengonversinya menjadi tf.data.Dataset dari (input_window, label_window) menggunakan fungsi tf.keras.utils.timeseries_dataset_from_array :
def make_dataset(self, data):
data = np.array(data, dtype=np.float32)
ds = tf.keras.utils.timeseries_dataset_from_array(
data=data,
targets=None,
sequence_length=self.total_window_size,
sequence_stride=1,
shuffle=True,
batch_size=32,)
ds = ds.map(self.split_window)
return ds
WindowGenerator.make_dataset = make_dataset
Objek WindowGenerator menyimpan data pelatihan, validasi, dan pengujian.
Tambahkan properti untuk mengaksesnya sebagai tf.data.Dataset s menggunakan metode make_dataset yang Anda tentukan sebelumnya. Juga, tambahkan kumpulan contoh standar untuk akses dan plot yang mudah:
@property
def train(self):
return self.make_dataset(self.train_df)
@property
def val(self):
return self.make_dataset(self.val_df)
@property
def test(self):
return self.make_dataset(self.test_df)
@property
def example(self):
"""Get and cache an example batch of `inputs, labels` for plotting."""
result = getattr(self, '_example', None)
if result is None:
# No example batch was found, so get one from the `.train` dataset
result = next(iter(self.train))
# And cache it for next time
self._example = result
return result
WindowGenerator.train = train
WindowGenerator.val = val
WindowGenerator.test = test
WindowGenerator.example = example
Sekarang, objek WindowGenerator memberi Anda akses ke objek tf.data.Dataset , sehingga Anda dapat dengan mudah mengulangi data.
Properti Dataset.element_spec memberi tahu Anda struktur, tipe data, dan bentuk elemen kumpulan data.
# Each element is an (inputs, label) pair.
w2.train.element_spec
(TensorSpec(shape=(None, 6, 19), dtype=tf.float32, name=None), TensorSpec(shape=(None, 1, 1), dtype=tf.float32, name=None))
Mengulangi Dataset menghasilkan kumpulan konkret:
for example_inputs, example_labels in w2.train.take(1):
print(f'Inputs shape (batch, time, features): {example_inputs.shape}')
print(f'Labels shape (batch, time, features): {example_labels.shape}')
Inputs shape (batch, time, features): (32, 6, 19) Labels shape (batch, time, features): (32, 1, 1)
Model langkah tunggal
Model paling sederhana yang dapat Anda buat berdasarkan data semacam ini adalah model yang memprediksi nilai fitur tunggal—1 langkah waktu (satu jam) ke depan hanya berdasarkan kondisi saat ini.
Jadi, mulailah dengan membangun model untuk memprediksi nilai T (degC) satu jam ke depan.
Konfigurasikan objek WindowGenerator untuk menghasilkan pasangan satu langkah (input, label) ini:
single_step_window = WindowGenerator(
input_width=1, label_width=1, shift=1,
label_columns=['T (degC)'])
single_step_window
Total window size: 2 Input indices: [0] Label indices: [1] Label column name(s): ['T (degC)']
Objek window membuat tf.data.Dataset s dari set pelatihan, validasi, dan pengujian, memungkinkan Anda untuk dengan mudah mengulangi kumpulan data.
for example_inputs, example_labels in single_step_window.train.take(1):
print(f'Inputs shape (batch, time, features): {example_inputs.shape}')
print(f'Labels shape (batch, time, features): {example_labels.shape}')
Inputs shape (batch, time, features): (32, 1, 19) Labels shape (batch, time, features): (32, 1, 1)
Dasar
Sebelum membangun model yang dapat dilatih, akan lebih baik untuk memiliki dasar kinerja sebagai titik perbandingan dengan model yang lebih rumit nantinya.
Tugas pertama ini adalah memprediksi suhu satu jam ke depan, berdasarkan nilai semua fitur saat ini. Nilai saat ini termasuk suhu saat ini.
Jadi, mulailah dengan model yang hanya mengembalikan suhu saat ini sebagai prediksi, memprediksi "Tidak ada perubahan". Ini adalah dasar yang masuk akal karena suhu berubah secara perlahan. Tentu saja, baseline ini akan bekerja kurang baik jika Anda membuat prediksi lebih lanjut di masa depan.
class Baseline(tf.keras.Model):
def __init__(self, label_index=None):
super().__init__()
self.label_index = label_index
def call(self, inputs):
if self.label_index is None:
return inputs
result = inputs[:, :, self.label_index]
return result[:, :, tf.newaxis]
Instansiasi dan evaluasi model ini:
baseline = Baseline(label_index=column_indices['T (degC)'])
baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
val_performance = {}
performance = {}
val_performance['Baseline'] = baseline.evaluate(single_step_window.val)
performance['Baseline'] = baseline.evaluate(single_step_window.test, verbose=0)
439/439 [==============================] - 1s 2ms/step - loss: 0.0128 - mean_absolute_error: 0.0785
Itu mencetak beberapa metrik kinerja, tetapi itu tidak memberi Anda perasaan tentang seberapa baik kinerja model.
WindowGenerator memiliki metode plot, tetapi plotnya tidak akan terlalu menarik dengan hanya satu sampel.
Jadi, buat WindowGenerator yang lebih luas yang menghasilkan input dan label windows 24 jam berturut-turut sekaligus. Variabel wide_window baru tidak mengubah cara model beroperasi. Model masih membuat prediksi satu jam ke depan berdasarkan satu langkah waktu input. Di sini, sumbu time bertindak seperti sumbu batch : setiap prediksi dibuat secara independen tanpa interaksi antara langkah-langkah waktu:
wide_window = WindowGenerator(
input_width=24, label_width=24, shift=1,
label_columns=['T (degC)'])
wide_window
Total window size: 25 Input indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23] Label indices: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24] Label column name(s): ['T (degC)']
Jendela yang diperluas ini dapat diteruskan langsung ke model baseline yang sama tanpa perubahan kode apa pun. Ini dimungkinkan karena input dan label memiliki jumlah langkah waktu yang sama, dan baseline hanya meneruskan input ke output:
print('Input shape:', wide_window.example[0].shape)
print('Output shape:', baseline(wide_window.example[0]).shape)
Input shape: (32, 24, 19) Output shape: (32, 24, 1)
Dengan memplot prediksi model dasar, perhatikan bahwa itu hanya label yang digeser ke kanan satu jam:
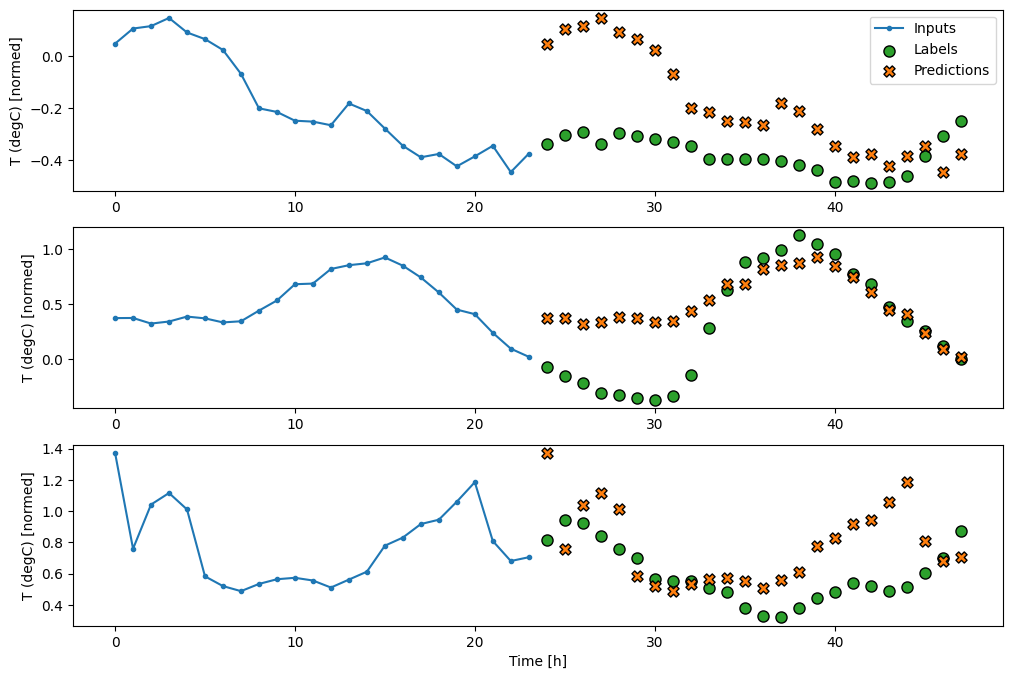
wide_window.plot(baseline)
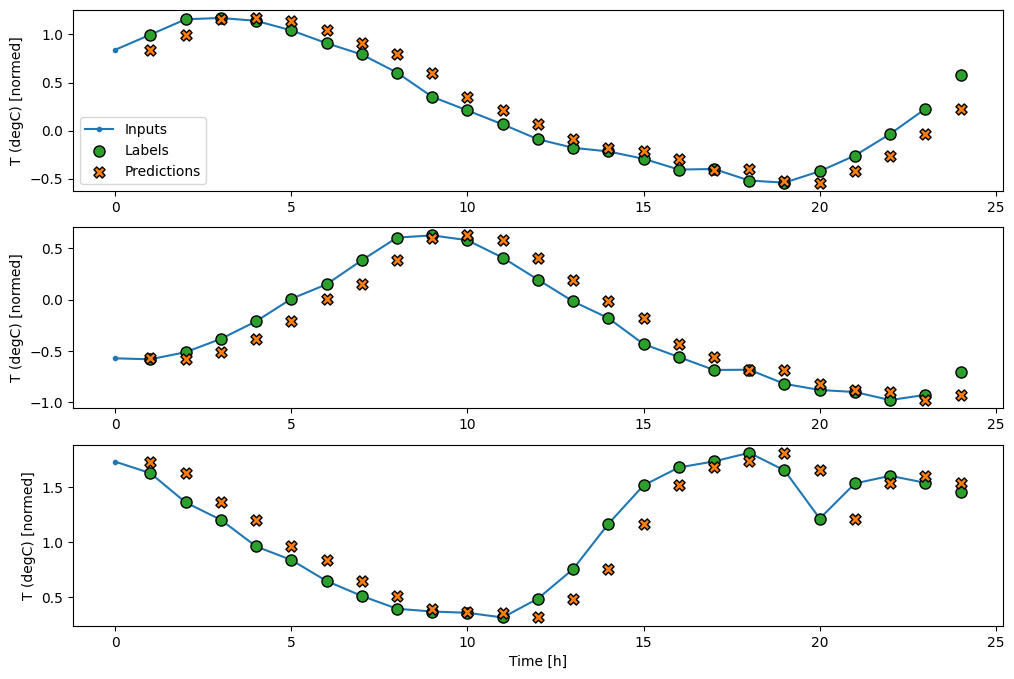
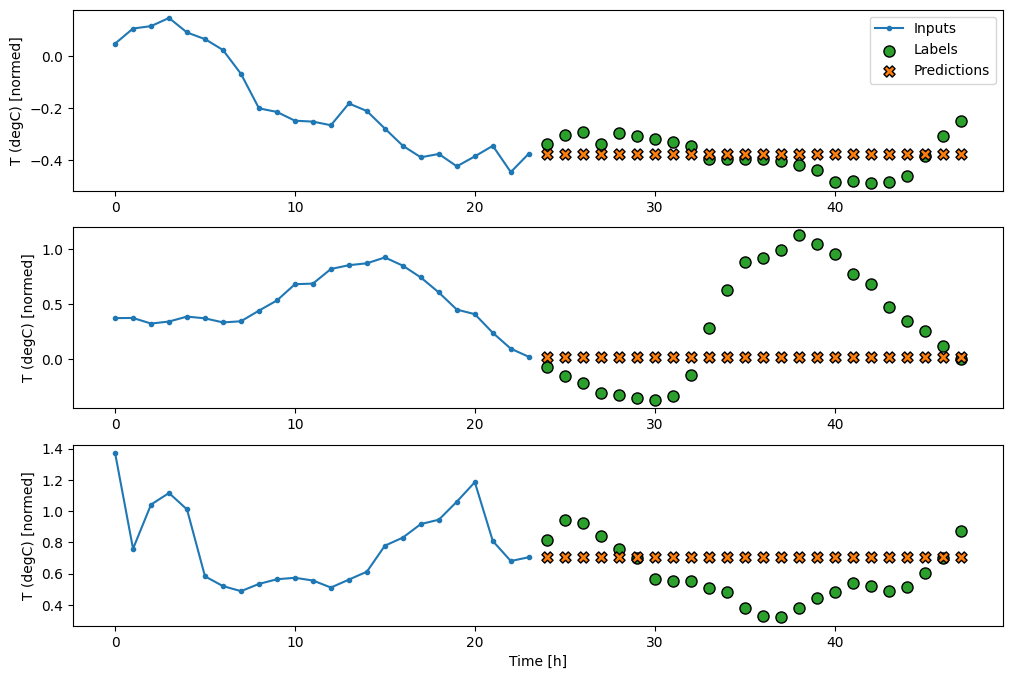
Dalam plot tiga contoh di atas, model langkah tunggal dijalankan selama 24 jam. Ini layak mendapat penjelasan:
- Garis
Inputsbiru menunjukkan suhu input pada setiap langkah waktu. Model menerima semua fitur, plot ini hanya menunjukkan suhu. - Titik
Labelshijau menunjukkan nilai prediksi target. Titik-titik ini ditampilkan pada waktu prediksi, bukan waktu input. Itulah sebabnya rentang label digeser 1 langkah relatif terhadap input. - Persilangan
Predictionsoranye adalah prediksi model untuk setiap langkah waktu keluaran. Jika model memprediksi dengan sempurna, prediksi akan langsung mendarat diLabels.
model linier
Model paling sederhana yang dapat dilatih yang dapat Anda terapkan pada tugas ini adalah dengan menyisipkan transformasi linier antara input dan output. Dalam hal ini output dari langkah waktu hanya bergantung pada langkah itu:
Lapisan tf.keras.layers.Dense tanpa set activation adalah model linier. Lapisan hanya mengubah sumbu terakhir data dari (batch, time, inputs) ke (batch, time, units) ; itu diterapkan secara independen untuk setiap item di seluruh batch dan sumbu time .
linear = tf.keras.Sequential([
tf.keras.layers.Dense(units=1)
])
print('Input shape:', single_step_window.example[0].shape)
print('Output shape:', linear(single_step_window.example[0]).shape)
Input shape: (32, 1, 19) Output shape: (32, 1, 1)
Tutorial ini melatih banyak model, jadi kemas prosedur pelatihan menjadi sebuah fungsi:
MAX_EPOCHS = 20
def compile_and_fit(model, window, patience=2):
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss',
patience=patience,
mode='min')
model.compile(loss=tf.losses.MeanSquaredError(),
optimizer=tf.optimizers.Adam(),
metrics=[tf.metrics.MeanAbsoluteError()])
history = model.fit(window.train, epochs=MAX_EPOCHS,
validation_data=window.val,
callbacks=[early_stopping])
return history
Latih model dan evaluasi kinerjanya:
history = compile_and_fit(linear, single_step_window)
val_performance['Linear'] = linear.evaluate(single_step_window.val)
performance['Linear'] = linear.evaluate(single_step_window.test, verbose=0)
Epoch 1/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0586 - mean_absolute_error: 0.1659 - val_loss: 0.0135 - val_mean_absolute_error: 0.0858 Epoch 2/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0109 - mean_absolute_error: 0.0772 - val_loss: 0.0093 - val_mean_absolute_error: 0.0711 Epoch 3/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0092 - mean_absolute_error: 0.0704 - val_loss: 0.0088 - val_mean_absolute_error: 0.0690 Epoch 4/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0091 - mean_absolute_error: 0.0697 - val_loss: 0.0089 - val_mean_absolute_error: 0.0692 Epoch 5/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0091 - mean_absolute_error: 0.0697 - val_loss: 0.0088 - val_mean_absolute_error: 0.0685 Epoch 6/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0091 - mean_absolute_error: 0.0697 - val_loss: 0.0087 - val_mean_absolute_error: 0.0687 Epoch 7/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0091 - mean_absolute_error: 0.0698 - val_loss: 0.0087 - val_mean_absolute_error: 0.0680 Epoch 8/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0090 - mean_absolute_error: 0.0695 - val_loss: 0.0087 - val_mean_absolute_error: 0.0683 Epoch 9/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0091 - mean_absolute_error: 0.0696 - val_loss: 0.0087 - val_mean_absolute_error: 0.0684 439/439 [==============================] - 1s 2ms/step - loss: 0.0087 - mean_absolute_error: 0.0684
Seperti model baseline , model linier dapat dipanggil pada kumpulan jendela lebar. Digunakan cara ini model membuat satu set prediksi independen pada langkah waktu berturut-turut. Sumbu time bertindak seperti sumbu batch lainnya. Tidak ada interaksi antara prediksi pada setiap langkah waktu.
print('Input shape:', wide_window.example[0].shape)
print('Output shape:', baseline(wide_window.example[0]).shape)
Input shape: (32, 24, 19) Output shape: (32, 24, 1)
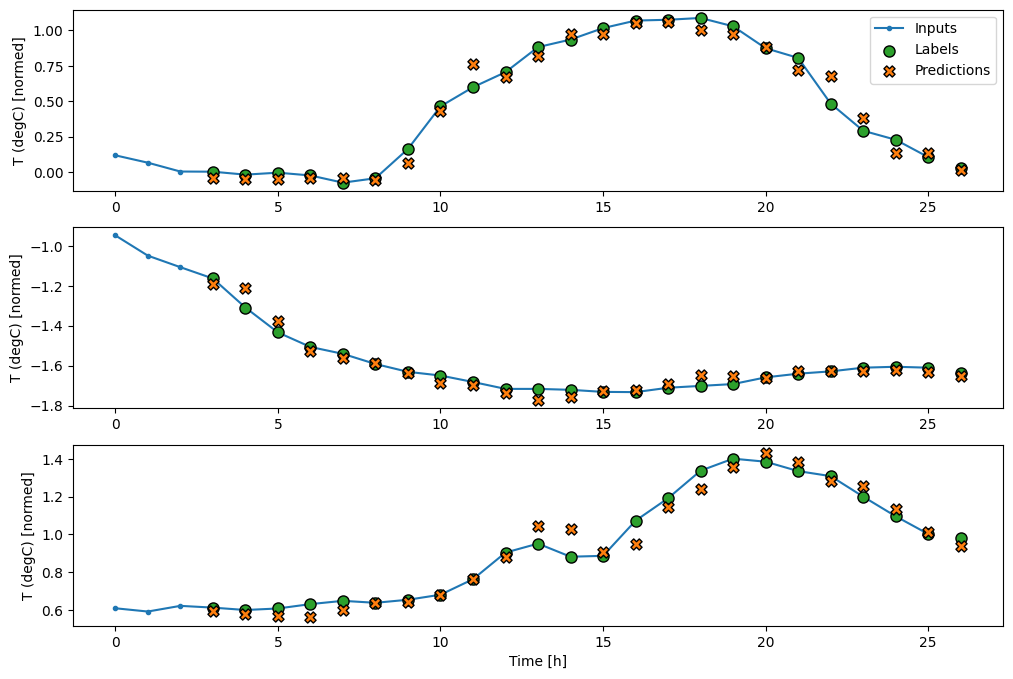
Berikut adalah plot contoh prediksinya di wide_window , perhatikan bagaimana dalam banyak kasus prediksi jelas lebih baik daripada hanya mengembalikan suhu input, tetapi dalam beberapa kasus lebih buruk:
wide_window.plot(linear)
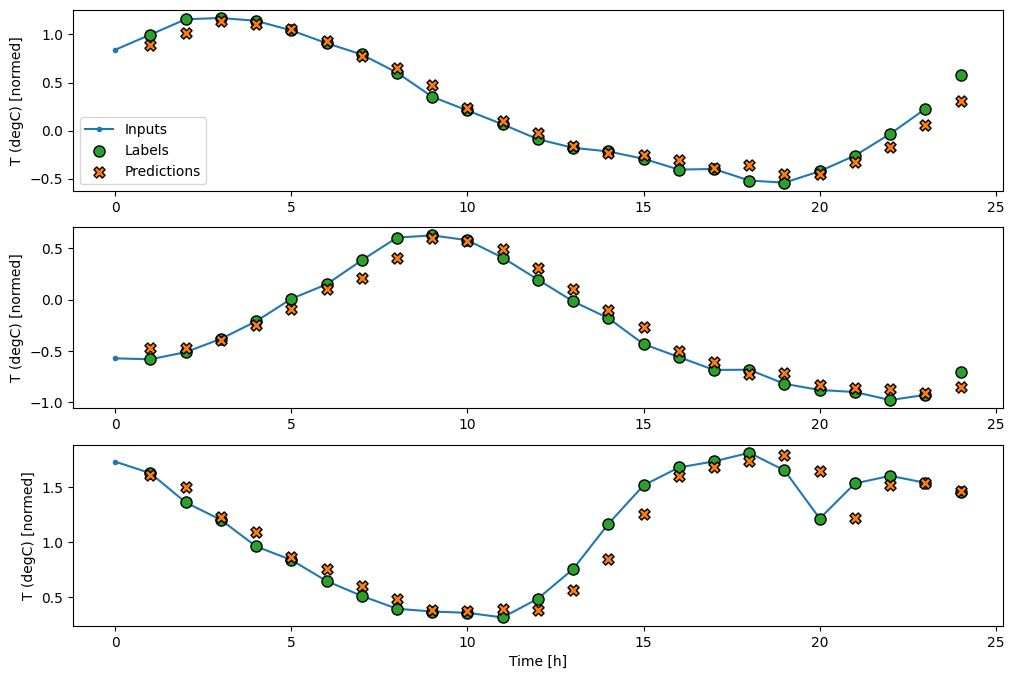
Satu keuntungan dari model linier adalah bahwa mereka relatif mudah untuk diinterpretasikan. Anda dapat mengeluarkan bobot layer dan memvisualisasikan bobot yang ditetapkan untuk setiap input:
plt.bar(x = range(len(train_df.columns)),
height=linear.layers[0].kernel[:,0].numpy())
axis = plt.gca()
axis.set_xticks(range(len(train_df.columns)))
_ = axis.set_xticklabels(train_df.columns, rotation=90)
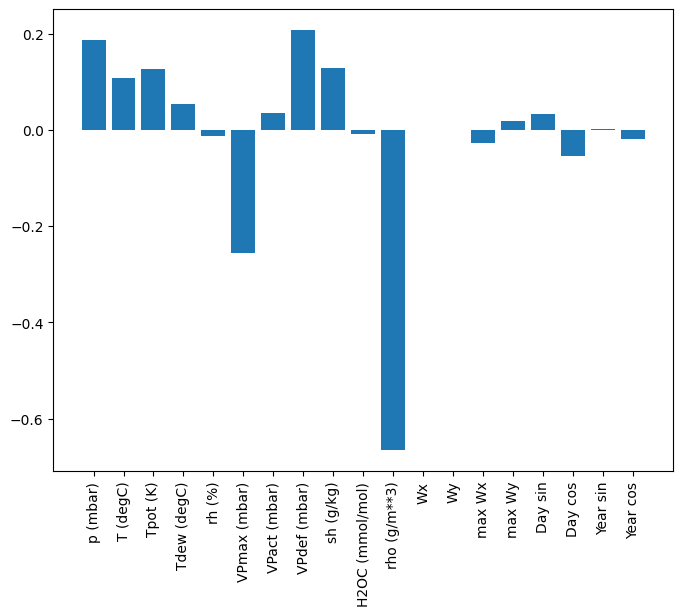
Terkadang model bahkan tidak menempatkan bobot paling besar pada input T (degC) . Ini adalah salah satu risiko inisialisasi acak.
Padat
Sebelum menerapkan model yang benar-benar beroperasi pada beberapa langkah waktu, ada baiknya memeriksa kinerja model langkah input tunggal yang lebih dalam, lebih bertenaga.
Berikut adalah model yang mirip dengan model linear , kecuali ia menumpuk beberapa lapisan Dense antara input dan output:
dense = tf.keras.Sequential([
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=1)
])
history = compile_and_fit(dense, single_step_window)
val_performance['Dense'] = dense.evaluate(single_step_window.val)
performance['Dense'] = dense.evaluate(single_step_window.test, verbose=0)
Epoch 1/20 1534/1534 [==============================] - 7s 4ms/step - loss: 0.0132 - mean_absolute_error: 0.0779 - val_loss: 0.0081 - val_mean_absolute_error: 0.0666 Epoch 2/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0081 - mean_absolute_error: 0.0652 - val_loss: 0.0073 - val_mean_absolute_error: 0.0610 Epoch 3/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0076 - mean_absolute_error: 0.0627 - val_loss: 0.0072 - val_mean_absolute_error: 0.0618 Epoch 4/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0072 - mean_absolute_error: 0.0609 - val_loss: 0.0068 - val_mean_absolute_error: 0.0582 Epoch 5/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0072 - mean_absolute_error: 0.0606 - val_loss: 0.0066 - val_mean_absolute_error: 0.0581 Epoch 6/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0070 - mean_absolute_error: 0.0594 - val_loss: 0.0067 - val_mean_absolute_error: 0.0579 Epoch 7/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0069 - mean_absolute_error: 0.0590 - val_loss: 0.0068 - val_mean_absolute_error: 0.0580 439/439 [==============================] - 1s 3ms/step - loss: 0.0068 - mean_absolute_error: 0.0580
Multi-langkah padat
Model single-time-step tidak memiliki konteks untuk nilai inputnya saat ini. Itu tidak dapat melihat bagaimana fitur input berubah dari waktu ke waktu. Untuk mengatasi masalah ini, model memerlukan akses ke beberapa langkah waktu saat membuat prediksi:
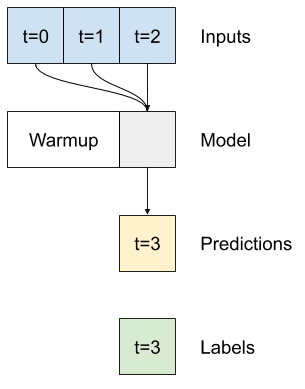
Model baseline , linear dan dense menangani setiap langkah waktu secara independen. Di sini model akan mengambil beberapa langkah waktu sebagai input untuk menghasilkan satu output.
Buat WindowGenerator yang akan menghasilkan kumpulan input tiga jam dan label satu jam:
Perhatikan bahwa parameter shift Window adalah relatif terhadap akhir dari dua jendela.
CONV_WIDTH = 3
conv_window = WindowGenerator(
input_width=CONV_WIDTH,
label_width=1,
shift=1,
label_columns=['T (degC)'])
conv_window
Total window size: 4 Input indices: [0 1 2] Label indices: [3] Label column name(s): ['T (degC)']
conv_window.plot()
plt.title("Given 3 hours of inputs, predict 1 hour into the future.")
Text(0.5, 1.0, 'Given 3 hours of inputs, predict 1 hour into the future.')
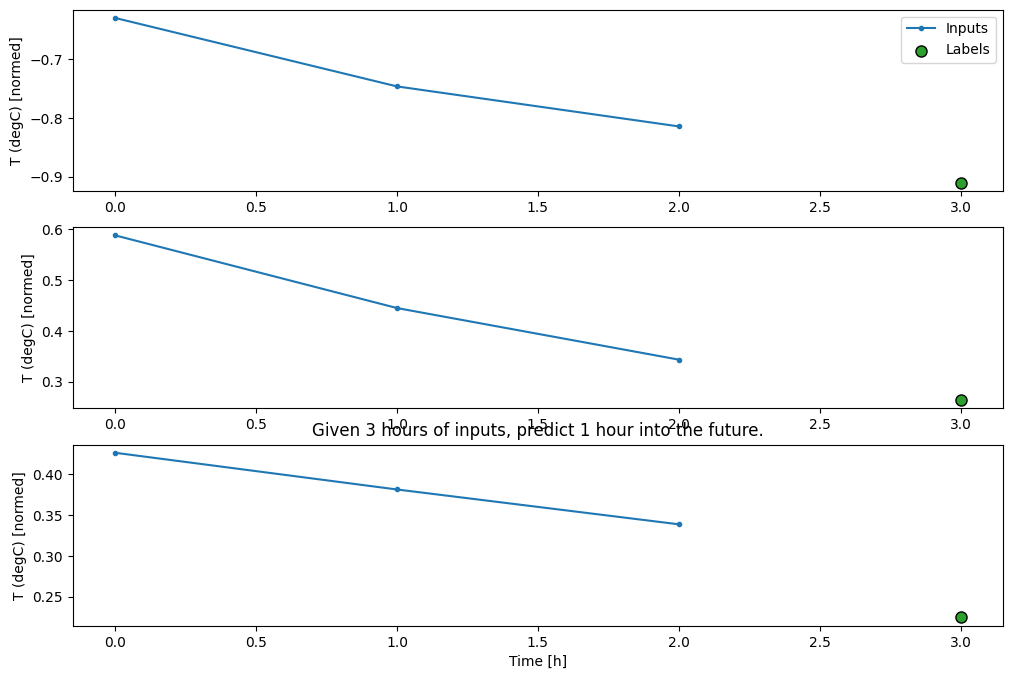
Anda dapat melatih model dense pada jendela beberapa langkah masukan dengan menambahkan tf.keras.layers.Flatten sebagai lapisan pertama model:
multi_step_dense = tf.keras.Sequential([
# Shape: (time, features) => (time*features)
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=1),
# Add back the time dimension.
# Shape: (outputs) => (1, outputs)
tf.keras.layers.Reshape([1, -1]),
])
print('Input shape:', conv_window.example[0].shape)
print('Output shape:', multi_step_dense(conv_window.example[0]).shape)
Input shape: (32, 3, 19) Output shape: (32, 1, 1)
history = compile_and_fit(multi_step_dense, conv_window)
IPython.display.clear_output()
val_performance['Multi step dense'] = multi_step_dense.evaluate(conv_window.val)
performance['Multi step dense'] = multi_step_dense.evaluate(conv_window.test, verbose=0)
438/438 [==============================] - 1s 2ms/step - loss: 0.0070 - mean_absolute_error: 0.0609
conv_window.plot(multi_step_dense)
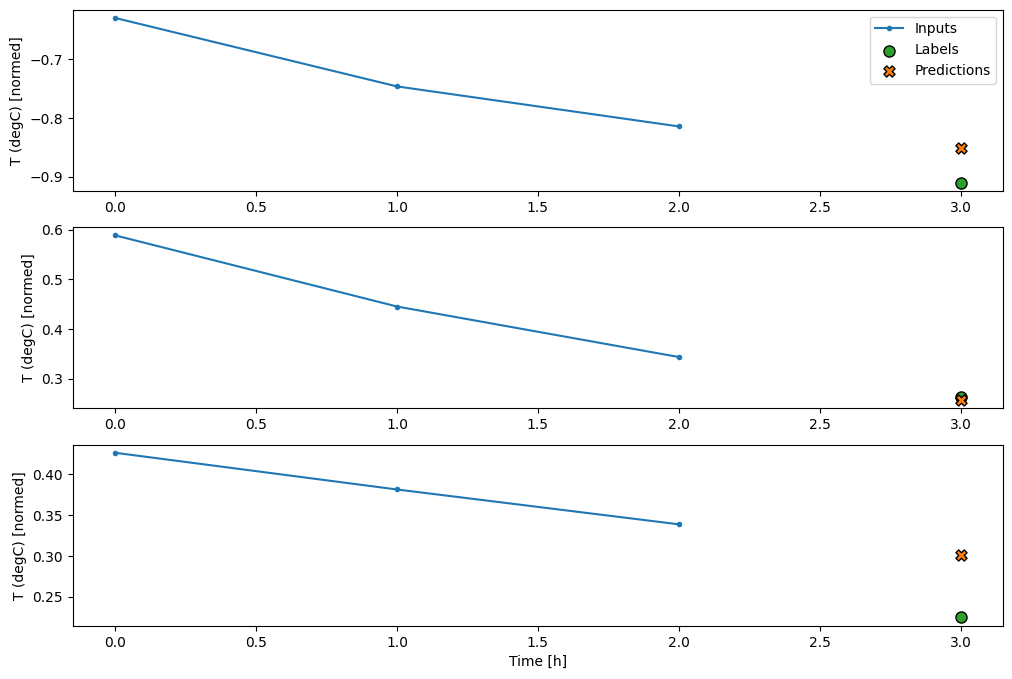
Kelemahan utama dari pendekatan ini adalah bahwa model yang dihasilkan hanya dapat dieksekusi pada jendela input dengan bentuk seperti ini.
print('Input shape:', wide_window.example[0].shape)
try:
print('Output shape:', multi_step_dense(wide_window.example[0]).shape)
except Exception as e:
print(f'\n{type(e).__name__}:{e}')
Input shape: (32, 24, 19) ValueError:Exception encountered when calling layer "sequential_2" (type Sequential). Input 0 of layer "dense_4" is incompatible with the layer: expected axis -1 of input shape to have value 57, but received input with shape (32, 456) Call arguments received: • inputs=tf.Tensor(shape=(32, 24, 19), dtype=float32) • training=None • mask=None
Model konvolusi di bagian berikutnya memperbaiki masalah ini.
Jaringan saraf konvolusi
Lapisan konvolusi ( tf.keras.layers.Conv1D ) juga membutuhkan beberapa langkah waktu sebagai masukan untuk setiap prediksi.
Di bawah ini adalah model yang sama dengan multi_step_dense , ditulis ulang dengan konvolusi.
Perhatikan perubahannya:
-
tf.keras.layers.Flattendantf.keras.layers.Densepertama digantikan olehtf.keras.layers.Conv1D. -
tf.keras.layers.Reshapetidak lagi diperlukan karena konvolusi mempertahankan sumbu waktu dalam outputnya.
conv_model = tf.keras.Sequential([
tf.keras.layers.Conv1D(filters=32,
kernel_size=(CONV_WIDTH,),
activation='relu'),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=1),
])
Jalankan pada kumpulan contoh untuk memeriksa apakah model menghasilkan keluaran dengan bentuk yang diharapkan:
print("Conv model on `conv_window`")
print('Input shape:', conv_window.example[0].shape)
print('Output shape:', conv_model(conv_window.example[0]).shape)
Conv model on `conv_window` Input shape: (32, 3, 19) Output shape: (32, 1, 1)
Latih dan evaluasi pada conv_window dan itu akan memberikan kinerja yang mirip dengan model multi_step_dense .
history = compile_and_fit(conv_model, conv_window)
IPython.display.clear_output()
val_performance['Conv'] = conv_model.evaluate(conv_window.val)
performance['Conv'] = conv_model.evaluate(conv_window.test, verbose=0)
438/438 [==============================] - 1s 3ms/step - loss: 0.0063 - mean_absolute_error: 0.0568
Perbedaan antara model conv_model dan multi_step_dense adalah bahwa conv_model dapat dijalankan pada input dengan panjang berapa pun. Lapisan convolutional diterapkan ke jendela geser input:
Jika Anda menjalankannya pada input yang lebih lebar, ini menghasilkan output yang lebih luas:
print("Wide window")
print('Input shape:', wide_window.example[0].shape)
print('Labels shape:', wide_window.example[1].shape)
print('Output shape:', conv_model(wide_window.example[0]).shape)
Wide window Input shape: (32, 24, 19) Labels shape: (32, 24, 1) Output shape: (32, 22, 1)
Perhatikan bahwa output lebih pendek dari input. Untuk membuat pelatihan atau plot bekerja, Anda memerlukan label, dan prediksi untuk memiliki panjang yang sama. Jadi buatlah WindowGenerator untuk menghasilkan jendela lebar dengan beberapa langkah waktu input tambahan sehingga label dan panjang prediksi cocok:
LABEL_WIDTH = 24
INPUT_WIDTH = LABEL_WIDTH + (CONV_WIDTH - 1)
wide_conv_window = WindowGenerator(
input_width=INPUT_WIDTH,
label_width=LABEL_WIDTH,
shift=1,
label_columns=['T (degC)'])
wide_conv_window
Total window size: 27 Input indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25] Label indices: [ 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26] Label column name(s): ['T (degC)']
print("Wide conv window")
print('Input shape:', wide_conv_window.example[0].shape)
print('Labels shape:', wide_conv_window.example[1].shape)
print('Output shape:', conv_model(wide_conv_window.example[0]).shape)
Wide conv window Input shape: (32, 26, 19) Labels shape: (32, 24, 1) Output shape: (32, 24, 1)
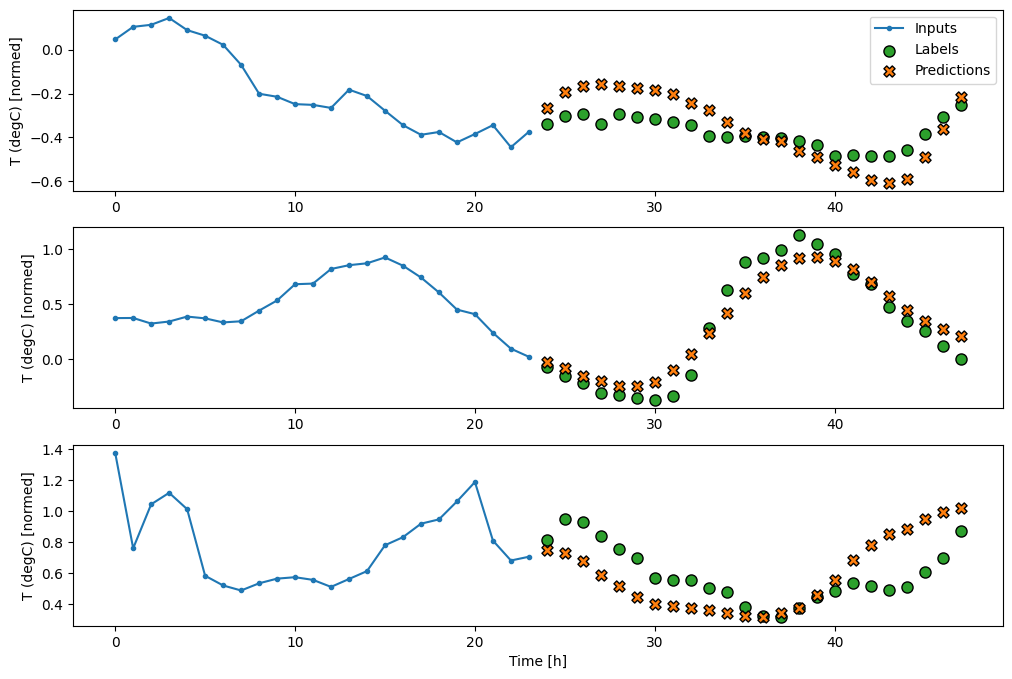
Sekarang, Anda dapat memplot prediksi model pada jendela yang lebih lebar. Perhatikan 3 langkah waktu input sebelum prediksi pertama. Setiap prediksi di sini didasarkan pada 3 langkah waktu sebelumnya:
wide_conv_window.plot(conv_model)
Jaringan saraf berulang
Recurrent Neural Network (RNN) adalah jenis neural network yang cocok untuk data deret waktu. RNN memproses deret waktu langkah demi langkah, mempertahankan keadaan internal dari langkah waktu ke langkah waktu.
Anda dapat mempelajari lebih lanjut di generasi Teks dengan tutorial RNN dan Jaringan Saraf Berulang (RNN) dengan panduan Keras .
Dalam tutorial ini, Anda akan menggunakan lapisan RNN yang disebut Long Short-Term Memory ( tf.keras.layers.LSTM ).
Argumen konstruktor penting untuk semua lapisan Keras RNN, seperti tf.keras.layers.LSTM , adalah argumen return_sequences . Pengaturan ini dapat mengonfigurasi lapisan dengan salah satu dari dua cara:
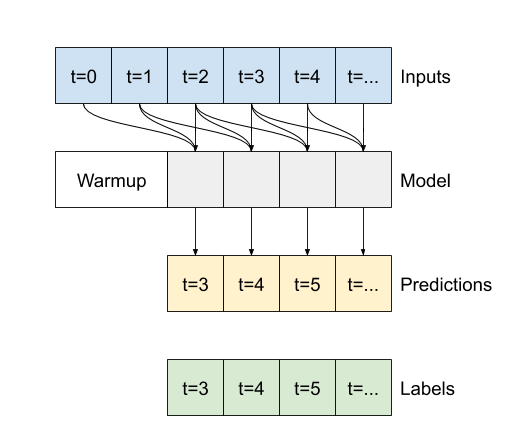
- Jika
False, defaultnya, layer hanya mengembalikan output dari langkah waktu terakhir, memberikan model waktu untuk menghangatkan keadaan internalnya sebelum membuat satu prediksi:
- Jika
True, layer mengembalikan output untuk setiap input. Ini berguna untuk:- Penumpukan lapisan RNN.
- Melatih model pada beberapa langkah waktu secara bersamaan.
lstm_model = tf.keras.models.Sequential([
# Shape [batch, time, features] => [batch, time, lstm_units]
tf.keras.layers.LSTM(32, return_sequences=True),
# Shape => [batch, time, features]
tf.keras.layers.Dense(units=1)
])
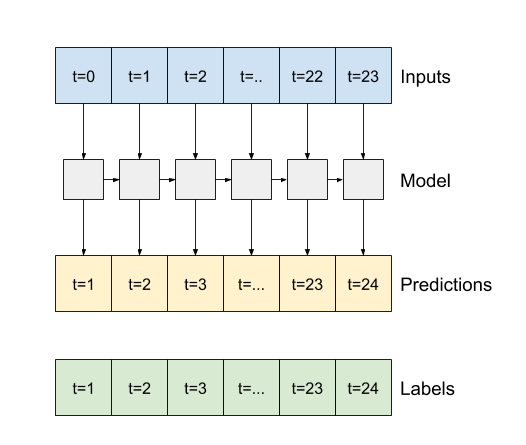
Dengan return_sequences=True , model dapat dilatih dengan data 24 jam sekaligus.
print('Input shape:', wide_window.example[0].shape)
print('Output shape:', lstm_model(wide_window.example[0]).shape)
Input shape: (32, 24, 19) Output shape: (32, 24, 1)
history = compile_and_fit(lstm_model, wide_window)
IPython.display.clear_output()
val_performance['LSTM'] = lstm_model.evaluate(wide_window.val)
performance['LSTM'] = lstm_model.evaluate(wide_window.test, verbose=0)
438/438 [==============================] - 1s 3ms/step - loss: 0.0055 - mean_absolute_error: 0.0509
wide_window.plot(lstm_model)
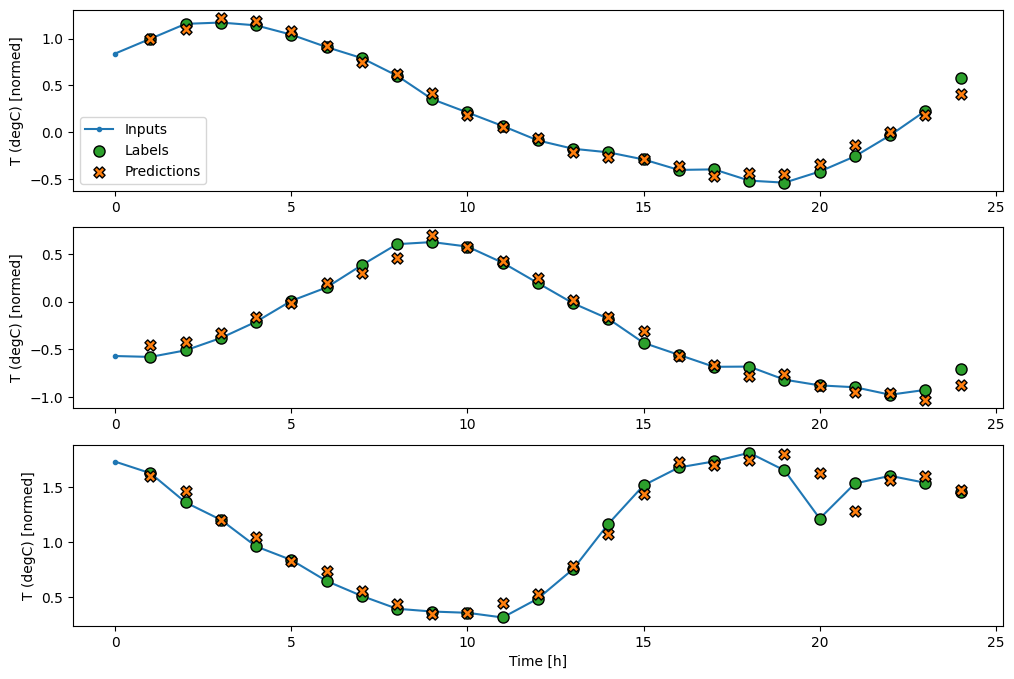
Pertunjukan
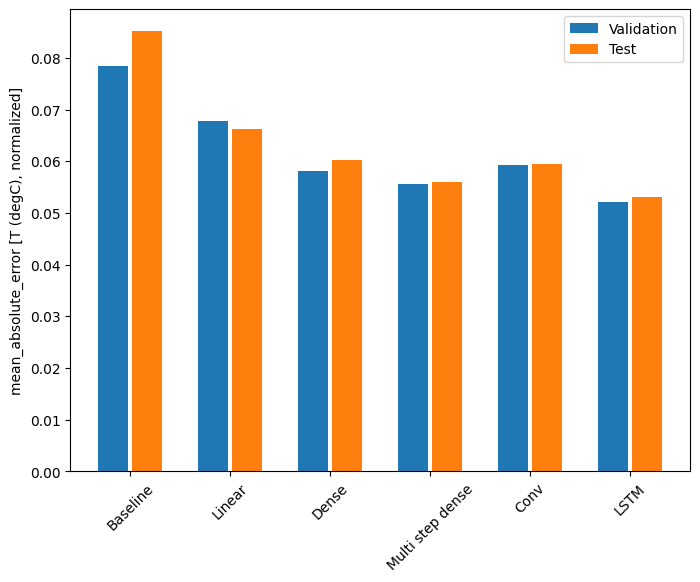
Dengan dataset ini biasanya masing-masing model melakukan sedikit lebih baik daripada yang sebelumnya:
x = np.arange(len(performance))
width = 0.3
metric_name = 'mean_absolute_error'
metric_index = lstm_model.metrics_names.index('mean_absolute_error')
val_mae = [v[metric_index] for v in val_performance.values()]
test_mae = [v[metric_index] for v in performance.values()]
plt.ylabel('mean_absolute_error [T (degC), normalized]')
plt.bar(x - 0.17, val_mae, width, label='Validation')
plt.bar(x + 0.17, test_mae, width, label='Test')
plt.xticks(ticks=x, labels=performance.keys(),
rotation=45)
_ = plt.legend()
for name, value in performance.items():
print(f'{name:12s}: {value[1]:0.4f}')
Baseline : 0.0852 Linear : 0.0666 Dense : 0.0573 Multi step dense: 0.0586 Conv : 0.0577 LSTM : 0.0518
Model multi-output
Semua model sejauh ini memprediksi fitur keluaran tunggal, T (degC) , untuk satu langkah waktu.
Semua model ini dapat dikonversi untuk memprediksi beberapa fitur hanya dengan mengubah jumlah unit di lapisan keluaran dan menyesuaikan jendela pelatihan untuk menyertakan semua fitur dalam labels ( example_labels ):
single_step_window = WindowGenerator(
# `WindowGenerator` returns all features as labels if you
# don't set the `label_columns` argument.
input_width=1, label_width=1, shift=1)
wide_window = WindowGenerator(
input_width=24, label_width=24, shift=1)
for example_inputs, example_labels in wide_window.train.take(1):
print(f'Inputs shape (batch, time, features): {example_inputs.shape}')
print(f'Labels shape (batch, time, features): {example_labels.shape}')
Inputs shape (batch, time, features): (32, 24, 19) Labels shape (batch, time, features): (32, 24, 19)
Perhatikan di atas bahwa sumbu features dari label sekarang memiliki kedalaman yang sama dengan input, bukan 1 .
Dasar
Model dasar yang sama ( Baseline ) dapat digunakan di sini, tetapi kali ini mengulangi semua fitur alih-alih memilih label_index :
baseline = Baseline()
baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
val_performance = {}
performance = {}
val_performance['Baseline'] = baseline.evaluate(wide_window.val)
performance['Baseline'] = baseline.evaluate(wide_window.test, verbose=0)
438/438 [==============================] - 1s 2ms/step - loss: 0.0886 - mean_absolute_error: 0.1589
Padat
dense = tf.keras.Sequential([
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=num_features)
])
history = compile_and_fit(dense, single_step_window)
IPython.display.clear_output()
val_performance['Dense'] = dense.evaluate(single_step_window.val)
performance['Dense'] = dense.evaluate(single_step_window.test, verbose=0)
439/439 [==============================] - 1s 3ms/step - loss: 0.0687 - mean_absolute_error: 0.1302
RNN
%%time
wide_window = WindowGenerator(
input_width=24, label_width=24, shift=1)
lstm_model = tf.keras.models.Sequential([
# Shape [batch, time, features] => [batch, time, lstm_units]
tf.keras.layers.LSTM(32, return_sequences=True),
# Shape => [batch, time, features]
tf.keras.layers.Dense(units=num_features)
])
history = compile_and_fit(lstm_model, wide_window)
IPython.display.clear_output()
val_performance['LSTM'] = lstm_model.evaluate( wide_window.val)
performance['LSTM'] = lstm_model.evaluate( wide_window.test, verbose=0)
print()
438/438 [==============================] - 1s 3ms/step - loss: 0.0617 - mean_absolute_error: 0.1205 CPU times: user 5min 14s, sys: 1min 17s, total: 6min 31s Wall time: 2min 8s
Lanjutan: Koneksi sisa
Model Baseline dari sebelumnya mengambil keuntungan dari fakta bahwa urutannya tidak berubah secara drastis dari waktu ke waktu. Setiap model yang dilatih dalam tutorial ini sejauh ini diinisialisasi secara acak, dan kemudian harus dipelajari bahwa outputnya adalah perubahan kecil dari langkah waktu sebelumnya.
Meskipun Anda dapat mengatasi masalah ini dengan inisialisasi yang cermat, lebih mudah untuk memasukkannya ke dalam struktur model.
Adalah umum dalam analisis deret waktu untuk membangun model yang alih-alih memprediksi nilai berikutnya, memprediksi bagaimana nilai akan berubah pada langkah waktu berikutnya. Demikian pula, jaringan residual —atau ResNets—dalam pembelajaran mendalam mengacu pada arsitektur di mana setiap lapisan menambah hasil akumulasi model.
Begitulah cara Anda memanfaatkan pengetahuan bahwa perubahan itu seharusnya kecil.
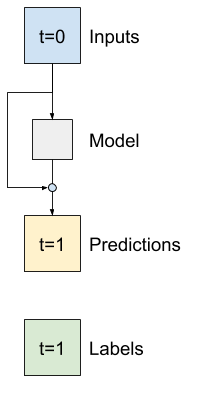
Pada dasarnya, ini menginisialisasi model agar sesuai dengan Baseline . Untuk tugas ini, ini membantu model menyatu lebih cepat, dengan kinerja yang sedikit lebih baik.
Pendekatan ini dapat digunakan bersama dengan model apa pun yang dibahas dalam tutorial ini.
Di sini, ini diterapkan pada model LSTM, perhatikan penggunaan tf.initializers.zeros untuk memastikan bahwa perubahan awal yang diprediksi kecil, dan tidak mengalahkan koneksi residual. Tidak ada masalah yang melanggar simetri untuk gradien di sini, karena zeros hanya digunakan pada lapisan terakhir.
class ResidualWrapper(tf.keras.Model):
def __init__(self, model):
super().__init__()
self.model = model
def call(self, inputs, *args, **kwargs):
delta = self.model(inputs, *args, **kwargs)
# The prediction for each time step is the input
# from the previous time step plus the delta
# calculated by the model.
return inputs + delta
%%time
residual_lstm = ResidualWrapper(
tf.keras.Sequential([
tf.keras.layers.LSTM(32, return_sequences=True),
tf.keras.layers.Dense(
num_features,
# The predicted deltas should start small.
# Therefore, initialize the output layer with zeros.
kernel_initializer=tf.initializers.zeros())
]))
history = compile_and_fit(residual_lstm, wide_window)
IPython.display.clear_output()
val_performance['Residual LSTM'] = residual_lstm.evaluate(wide_window.val)
performance['Residual LSTM'] = residual_lstm.evaluate(wide_window.test, verbose=0)
print()
438/438 [==============================] - 1s 3ms/step - loss: 0.0620 - mean_absolute_error: 0.1179 CPU times: user 1min 43s, sys: 26.1 s, total: 2min 9s Wall time: 43.1 s
Pertunjukan
Berikut adalah kinerja keseluruhan untuk model multi-output ini.
x = np.arange(len(performance))
width = 0.3
metric_name = 'mean_absolute_error'
metric_index = lstm_model.metrics_names.index('mean_absolute_error')
val_mae = [v[metric_index] for v in val_performance.values()]
test_mae = [v[metric_index] for v in performance.values()]
plt.bar(x - 0.17, val_mae, width, label='Validation')
plt.bar(x + 0.17, test_mae, width, label='Test')
plt.xticks(ticks=x, labels=performance.keys(),
rotation=45)
plt.ylabel('MAE (average over all outputs)')
_ = plt.legend()
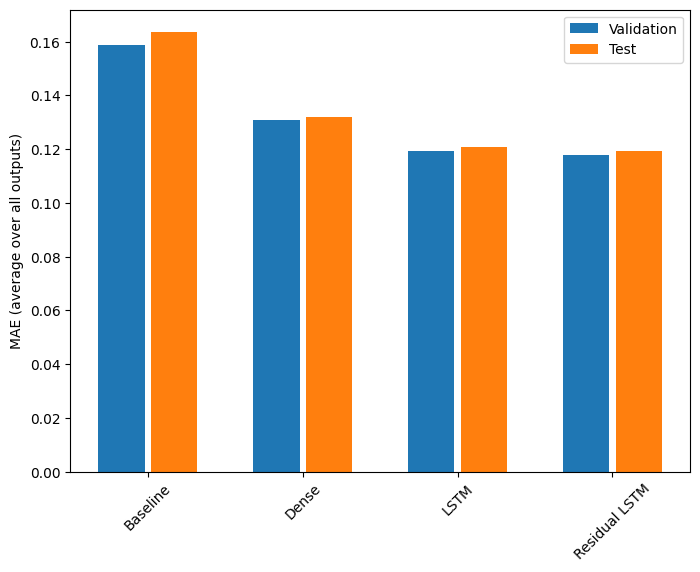
for name, value in performance.items():
print(f'{name:15s}: {value[1]:0.4f}')
Baseline : 0.1638 Dense : 0.1311 LSTM : 0.1214 Residual LSTM : 0.1194
Performa di atas dirata-ratakan di semua keluaran model.
Model multi-langkah
Baik model keluaran tunggal dan keluaran ganda di bagian sebelumnya membuat prediksi langkah waktu tunggal , satu jam ke depan.
Bagian ini membahas bagaimana mengembangkan model-model ini untuk membuat beberapa prediksi langkah waktu .
Dalam prediksi multi-langkah, model perlu belajar memprediksi rentang nilai masa depan. Jadi, tidak seperti model langkah tunggal, di mana hanya satu titik masa depan diprediksi, model multi-langkah memprediksi urutan nilai masa depan.
Ada dua pendekatan kasar untuk ini:
- Prediksi tembakan tunggal di mana seluruh rangkaian waktu diprediksi sekaligus.
- Prediksi autoregressive dimana model hanya membuat prediksi satu langkah dan outputnya diumpankan kembali sebagai inputnya.
Di bagian ini semua model akan memprediksi semua fitur di semua langkah waktu keluaran .
Untuk model multi-langkah, data pelatihan lagi-lagi terdiri dari sampel per jam. Namun, di sini, model akan belajar memprediksi 24 jam ke depan, mengingat 24 jam di masa lalu.
Berikut adalah objek Window yang menghasilkan irisan ini dari dataset:
OUT_STEPS = 24
multi_window = WindowGenerator(input_width=24,
label_width=OUT_STEPS,
shift=OUT_STEPS)
multi_window.plot()
multi_window
Total window size: 48 Input indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23] Label indices: [24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47] Label column name(s): None
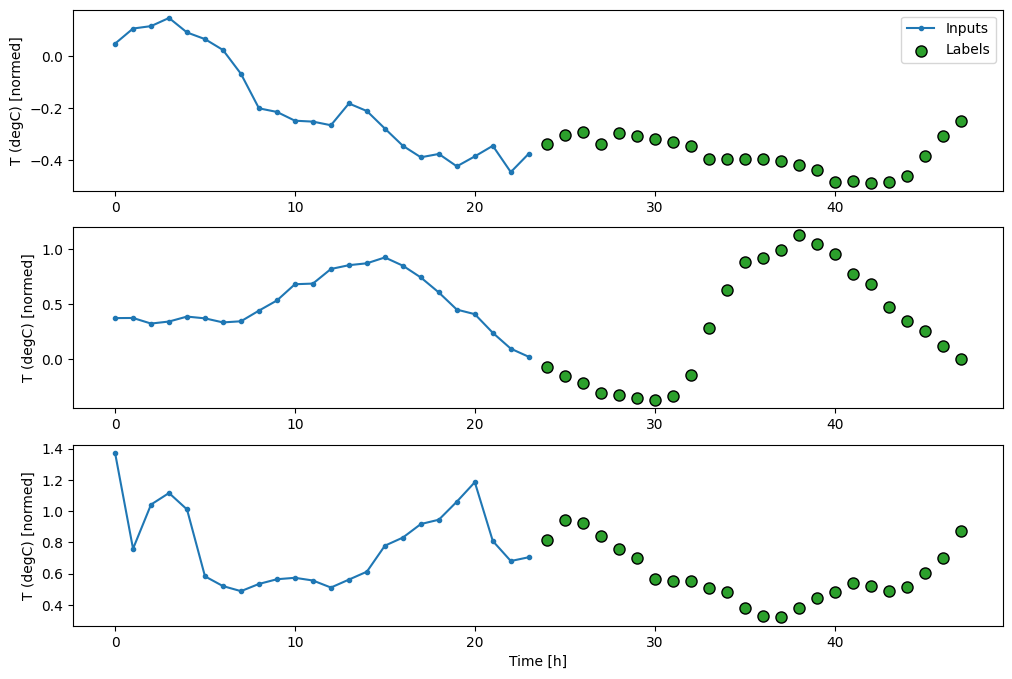
Dasar
Garis dasar sederhana untuk tugas ini adalah mengulangi langkah waktu input terakhir untuk jumlah langkah waktu output yang diperlukan:
class MultiStepLastBaseline(tf.keras.Model):
def call(self, inputs):
return tf.tile(inputs[:, -1:, :], [1, OUT_STEPS, 1])
last_baseline = MultiStepLastBaseline()
last_baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
multi_val_performance = {}
multi_performance = {}
multi_val_performance['Last'] = last_baseline.evaluate(multi_window.val)
multi_performance['Last'] = last_baseline.evaluate(multi_window.test, verbose=0)
multi_window.plot(last_baseline)
437/437 [==============================] - 1s 2ms/step - loss: 0.6285 - mean_absolute_error: 0.5007
Karena tugas ini adalah untuk memprediksi 24 jam ke depan, mengingat 24 jam yang lalu, pendekatan sederhana lainnya adalah mengulangi hari sebelumnya, dengan asumsi besok akan serupa:
class RepeatBaseline(tf.keras.Model):
def call(self, inputs):
return inputs
repeat_baseline = RepeatBaseline()
repeat_baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
multi_val_performance['Repeat'] = repeat_baseline.evaluate(multi_window.val)
multi_performance['Repeat'] = repeat_baseline.evaluate(multi_window.test, verbose=0)
multi_window.plot(repeat_baseline)
437/437 [==============================] - 1s 2ms/step - loss: 0.4270 - mean_absolute_error: 0.3959
Model bidikan tunggal
Salah satu pendekatan tingkat tinggi untuk masalah ini adalah dengan menggunakan model "single-shot", di mana model membuat prediksi seluruh urutan dalam satu langkah.
Ini dapat diimplementasikan secara efisien sebagai tf.keras.layers.Dense dengan OUT_STEPS*features unit keluaran. Model hanya perlu membentuk kembali output itu ke yang dibutuhkan (OUTPUT_STEPS, features) .
Linier
Model linier sederhana yang didasarkan pada langkah waktu input terakhir lebih baik daripada kedua garis dasar, tetapi kurang bertenaga. Model perlu memprediksi langkah waktu OUTPUT_STEPS , dari satu langkah waktu input dengan proyeksi linier. Itu hanya dapat menangkap sepotong perilaku berdimensi rendah, kemungkinan besar didasarkan terutama pada waktu hari dan waktu dalam setahun.
multi_linear_model = tf.keras.Sequential([
# Take the last time-step.
# Shape [batch, time, features] => [batch, 1, features]
tf.keras.layers.Lambda(lambda x: x[:, -1:, :]),
# Shape => [batch, 1, out_steps*features]
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros()),
# Shape => [batch, out_steps, features]
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_linear_model, multi_window)
IPython.display.clear_output()
multi_val_performance['Linear'] = multi_linear_model.evaluate(multi_window.val)
multi_performance['Linear'] = multi_linear_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_linear_model)
437/437 [==============================] - 1s 2ms/step - loss: 0.2559 - mean_absolute_error: 0.3053

Padat
Menambahkan tf.keras.layers.Dense antara input dan output memberikan model linier lebih banyak kekuatan, tetapi masih hanya didasarkan pada satu langkah waktu input.
multi_dense_model = tf.keras.Sequential([
# Take the last time step.
# Shape [batch, time, features] => [batch, 1, features]
tf.keras.layers.Lambda(lambda x: x[:, -1:, :]),
# Shape => [batch, 1, dense_units]
tf.keras.layers.Dense(512, activation='relu'),
# Shape => [batch, out_steps*features]
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros()),
# Shape => [batch, out_steps, features]
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_dense_model, multi_window)
IPython.display.clear_output()
multi_val_performance['Dense'] = multi_dense_model.evaluate(multi_window.val)
multi_performance['Dense'] = multi_dense_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_dense_model)
437/437 [==============================] - 1s 3ms/step - loss: 0.2205 - mean_absolute_error: 0.2837
CNN
Model konvolusi membuat prediksi berdasarkan histori lebar tetap, yang dapat menghasilkan kinerja yang lebih baik daripada model padat karena model ini dapat melihat perubahan dari waktu ke waktu:
CONV_WIDTH = 3
multi_conv_model = tf.keras.Sequential([
# Shape [batch, time, features] => [batch, CONV_WIDTH, features]
tf.keras.layers.Lambda(lambda x: x[:, -CONV_WIDTH:, :]),
# Shape => [batch, 1, conv_units]
tf.keras.layers.Conv1D(256, activation='relu', kernel_size=(CONV_WIDTH)),
# Shape => [batch, 1, out_steps*features]
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros()),
# Shape => [batch, out_steps, features]
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_conv_model, multi_window)
IPython.display.clear_output()
multi_val_performance['Conv'] = multi_conv_model.evaluate(multi_window.val)
multi_performance['Conv'] = multi_conv_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_conv_model)
437/437 [==============================] - 1s 2ms/step - loss: 0.2158 - mean_absolute_error: 0.2833
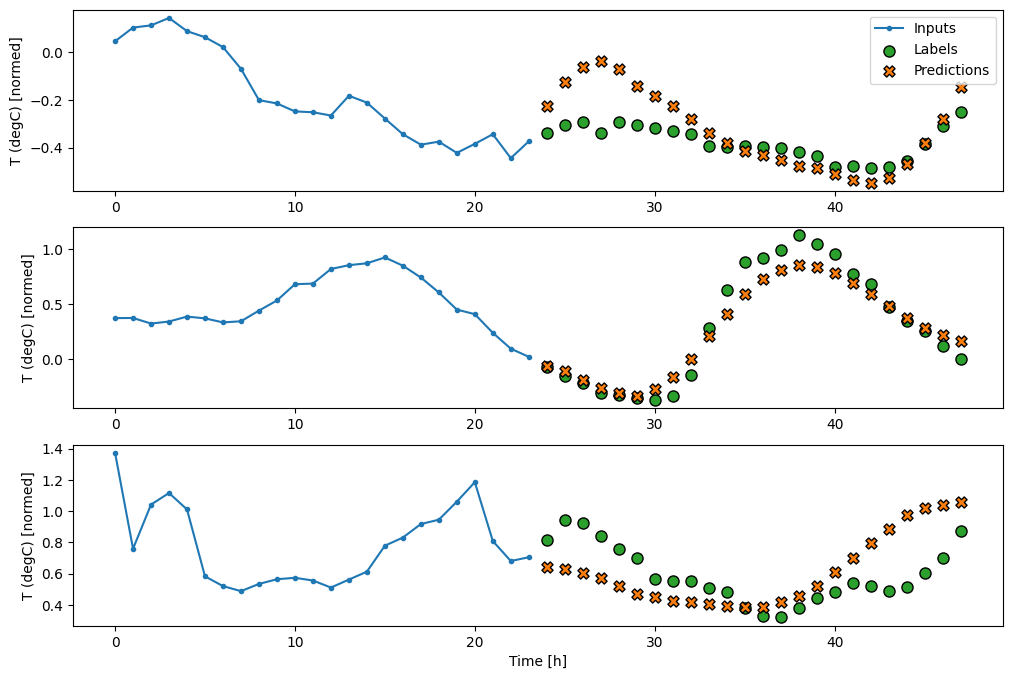
RNN
Model berulang dapat belajar menggunakan sejarah masukan yang panjang, jika relevan dengan prediksi yang dibuat model. Di sini model akan mengakumulasi keadaan internal selama 24 jam, sebelum membuat prediksi tunggal untuk 24 jam berikutnya.
Dalam format single-shot ini, LSTM hanya perlu menghasilkan output pada langkah terakhir, jadi setel return_sequences=False di tf.keras.layers.LSTM .
multi_lstm_model = tf.keras.Sequential([
# Shape [batch, time, features] => [batch, lstm_units].
# Adding more `lstm_units` just overfits more quickly.
tf.keras.layers.LSTM(32, return_sequences=False),
# Shape => [batch, out_steps*features].
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros()),
# Shape => [batch, out_steps, features].
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_lstm_model, multi_window)
IPython.display.clear_output()
multi_val_performance['LSTM'] = multi_lstm_model.evaluate(multi_window.val)
multi_performance['LSTM'] = multi_lstm_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_lstm_model)
437/437 [==============================] - 1s 3ms/step - loss: 0.2159 - mean_absolute_error: 0.2863
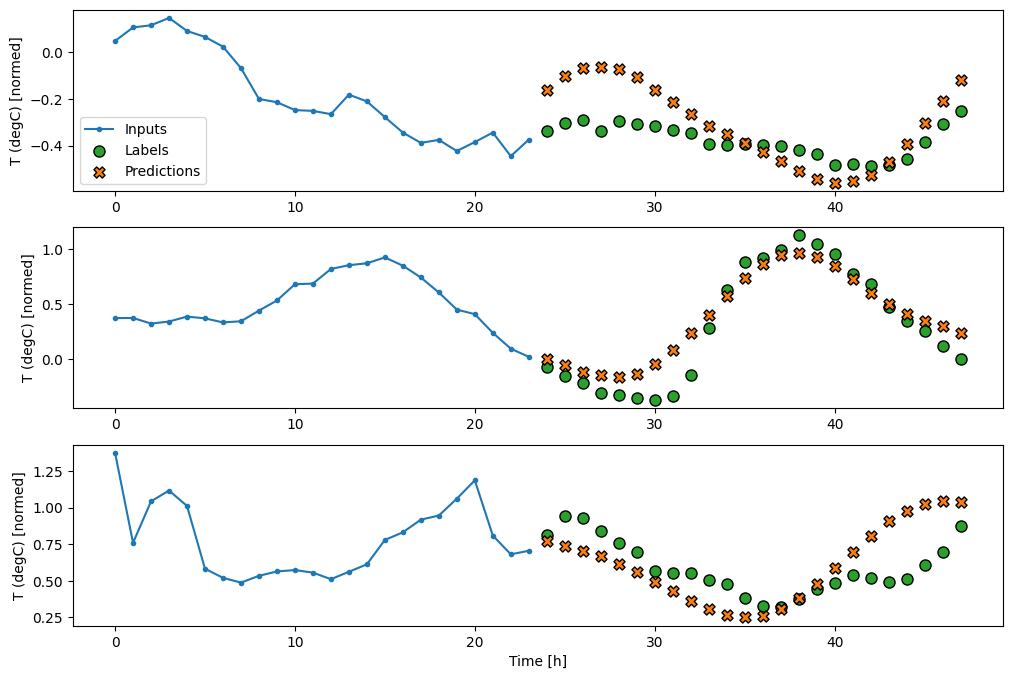
Lanjutan: Model autoregresif
Semua model di atas memprediksi seluruh urutan output dalam satu langkah.
Dalam beberapa kasus mungkin akan membantu model untuk menguraikan prediksi ini menjadi langkah-langkah waktu individu. Kemudian, setiap keluaran model dapat diumpankan kembali ke dalam dirinya sendiri pada setiap langkah dan prediksi dapat dibuat dikondisikan pada yang sebelumnya, seperti di Generating Sequences With Recurrent Neural Networks klasik.
Salah satu keuntungan yang jelas untuk gaya model ini adalah dapat diatur untuk menghasilkan output dengan panjang yang bervariasi.
Anda dapat mengambil salah satu model multi-output satu langkah yang dilatih di paruh pertama tutorial ini dan dijalankan dalam loop umpan balik autoregresif, tetapi di sini Anda akan fokus membangun model yang telah dilatih secara eksplisit untuk melakukan itu.
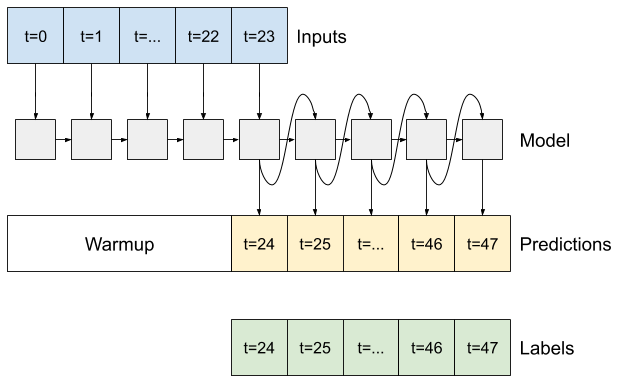
RNN
Tutorial ini hanya membuat model RNN autoregresif, tetapi pola ini dapat diterapkan ke model apa pun yang dirancang untuk menghasilkan satu langkah waktu.
Model akan memiliki bentuk dasar yang sama dengan model LSTM satu langkah dari sebelumnya: lapisan tf.keras.layers.LSTM diikuti oleh lapisan tf.keras.layers.Dense yang mengubah keluaran lapisan LSTM menjadi prediksi model.
tf.keras.layers.LSTM adalah tf.keras.layers.LSTMCell yang dibungkus dengan tf.keras.layers.RNN tingkat yang lebih tinggi yang mengelola hasil status dan urutan untuk Anda (Lihat Recurrent Neural Networks (RNN) dengan Keras panduan untuk rincian).
Dalam hal ini, model harus mengelola input secara manual untuk setiap langkah, sehingga model menggunakan tf.keras.layers.LSTMCell secara langsung untuk antarmuka langkah satu kali tingkat yang lebih rendah.
class FeedBack(tf.keras.Model):
def __init__(self, units, out_steps):
super().__init__()
self.out_steps = out_steps
self.units = units
self.lstm_cell = tf.keras.layers.LSTMCell(units)
# Also wrap the LSTMCell in an RNN to simplify the `warmup` method.
self.lstm_rnn = tf.keras.layers.RNN(self.lstm_cell, return_state=True)
self.dense = tf.keras.layers.Dense(num_features)
feedback_model = FeedBack(units=32, out_steps=OUT_STEPS)
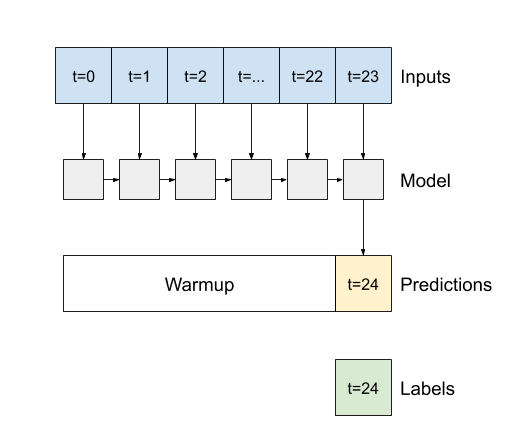
Metode pertama yang dibutuhkan model ini adalah metode warmup untuk menginisialisasi keadaan internalnya berdasarkan input. Setelah dilatih, status ini akan menangkap bagian yang relevan dari riwayat input. Ini setara dengan model LSTM satu langkah dari sebelumnya:
def warmup(self, inputs):
# inputs.shape => (batch, time, features)
# x.shape => (batch, lstm_units)
x, *state = self.lstm_rnn(inputs)
# predictions.shape => (batch, features)
prediction = self.dense(x)
return prediction, state
FeedBack.warmup = warmup
Metode ini mengembalikan prediksi langkah waktu tunggal dan status internal LSTM :
prediction, state = feedback_model.warmup(multi_window.example[0])
prediction.shape
TensorShape([32, 19])
Dengan status RNN , dan prediksi awal, Anda sekarang dapat melanjutkan iterasi model yang memberi makan prediksi di setiap langkah mundur sebagai input.
Pendekatan paling sederhana untuk mengumpulkan prediksi keluaran adalah dengan menggunakan daftar Python dan tf.stack setelah loop.
def call(self, inputs, training=None):
# Use a TensorArray to capture dynamically unrolled outputs.
predictions = []
# Initialize the LSTM state.
prediction, state = self.warmup(inputs)
# Insert the first prediction.
predictions.append(prediction)
# Run the rest of the prediction steps.
for n in range(1, self.out_steps):
# Use the last prediction as input.
x = prediction
# Execute one lstm step.
x, state = self.lstm_cell(x, states=state,
training=training)
# Convert the lstm output to a prediction.
prediction = self.dense(x)
# Add the prediction to the output.
predictions.append(prediction)
# predictions.shape => (time, batch, features)
predictions = tf.stack(predictions)
# predictions.shape => (batch, time, features)
predictions = tf.transpose(predictions, [1, 0, 2])
return predictions
FeedBack.call = call
Uji coba model ini pada input contoh:
print('Output shape (batch, time, features): ', feedback_model(multi_window.example[0]).shape)
Output shape (batch, time, features): (32, 24, 19)
Sekarang, latih modelnya:
history = compile_and_fit(feedback_model, multi_window)
IPython.display.clear_output()
multi_val_performance['AR LSTM'] = feedback_model.evaluate(multi_window.val)
multi_performance['AR LSTM'] = feedback_model.evaluate(multi_window.test, verbose=0)
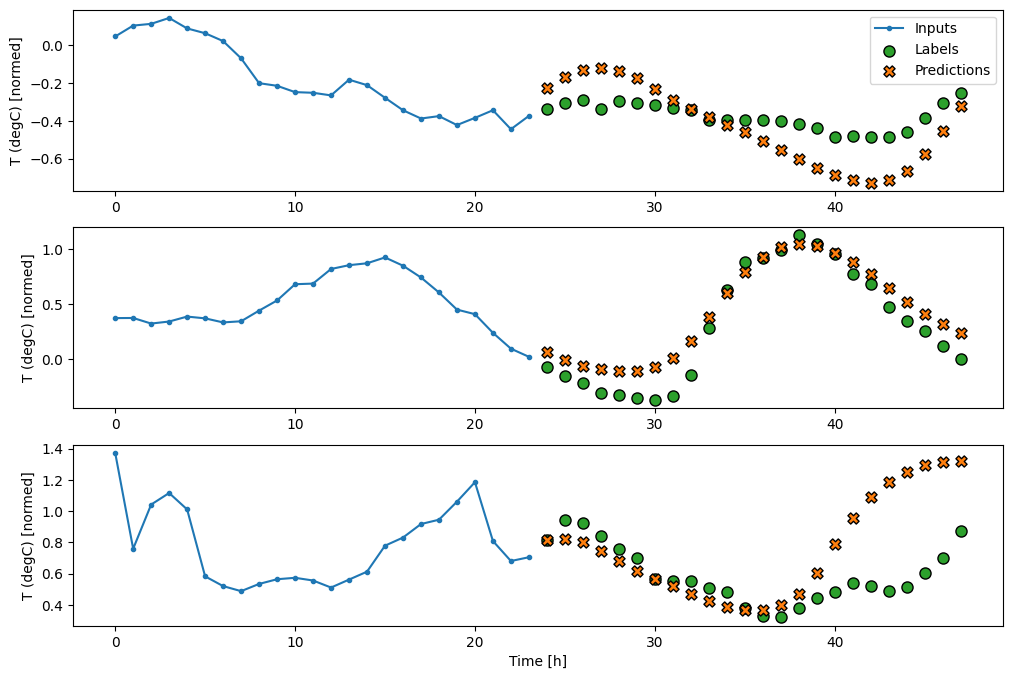
multi_window.plot(feedback_model)
437/437 [==============================] - 3s 8ms/step - loss: 0.2269 - mean_absolute_error: 0.3011
Pertunjukan
Jelas ada hasil yang semakin berkurang sebagai fungsi dari kompleksitas model pada masalah ini:
x = np.arange(len(multi_performance))
width = 0.3
metric_name = 'mean_absolute_error'
metric_index = lstm_model.metrics_names.index('mean_absolute_error')
val_mae = [v[metric_index] for v in multi_val_performance.values()]
test_mae = [v[metric_index] for v in multi_performance.values()]
plt.bar(x - 0.17, val_mae, width, label='Validation')
plt.bar(x + 0.17, test_mae, width, label='Test')
plt.xticks(ticks=x, labels=multi_performance.keys(),
rotation=45)
plt.ylabel(f'MAE (average over all times and outputs)')
_ = plt.legend()
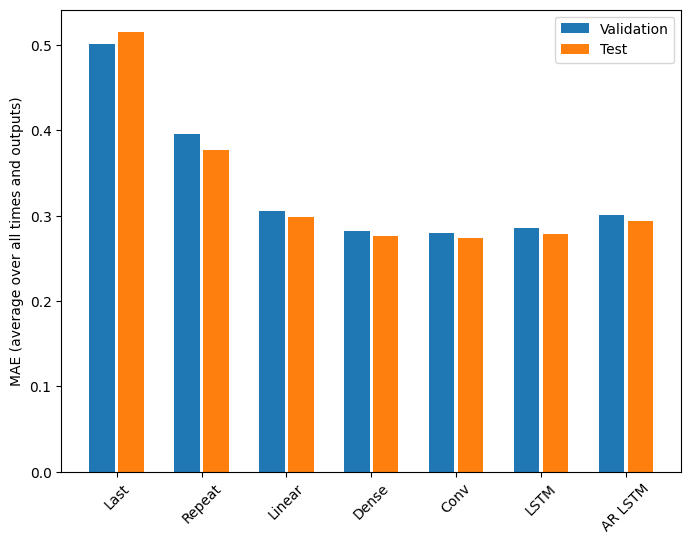
Metrik untuk model multi-output di paruh pertama tutorial ini menunjukkan kinerja rata-rata di semua fitur output. Performa ini serupa tetapi juga dirata-ratakan di seluruh langkah waktu keluaran.
for name, value in multi_performance.items():
print(f'{name:8s}: {value[1]:0.4f}')
Last : 0.5157 Repeat : 0.3774 Linear : 0.2977 Dense : 0.2781 Conv : 0.2796 LSTM : 0.2767 AR LSTM : 0.2901
Keuntungan yang dicapai dari model padat ke model konvolusi dan berulang hanya beberapa persen (jika ada), dan model autoregresif jelas berkinerja lebih buruk. Jadi pendekatan yang lebih kompleks ini mungkin tidak berguna untuk masalah ini , tetapi tidak ada cara untuk mengetahuinya tanpa mencoba, dan model ini dapat membantu untuk masalah Anda .
Langkah selanjutnya
Tutorial ini adalah pengantar singkat untuk perkiraan deret waktu menggunakan TensorFlow.
Untuk mempelajari lebih lanjut, lihat:
- Bab 15 Pembelajaran Mesin Langsung dengan Scikit-Learn, Keras, dan TensorFlow , Edisi ke-2.
- Bab 6 Pembelajaran Mendalam dengan Python .
- Pelajaran 8 dari pengantar Udacity ke TensorFlow untuk pembelajaran mendalam , termasuk buku catatan latihan .
Juga, ingat bahwa Anda dapat menerapkan model deret waktu klasik apa pun di TensorFlow—tutorial ini hanya berfokus pada fungsionalitas bawaan TensorFlow.