
| | |  Посмотреть на GitHub Посмотреть на GitHub | |
Это Colab является демонстрацией использования Tensorflow хаб для классификации текста в неанглийском / местных языках. Здесь мы выбираем Bangla как местный язык и использовать pretrained вложения слова для решения мультикласса классификации задач , где мы классифицируем Bangla новостных статьи в 5 категориях. В pretrained вложения для Bangla приходит из FastText который является библиотекой по Facebook с опубликованным pretrained векторов слов на 157 языках.
Мы будем использовать pretrained вложения экспортера TF-HUB для преобразования слова вложения в модуль текстового вложения первым , а затем использовать модуль для подготовки классификатора с tf.keras , высокого уровень удобного API Tensorflow, чтобы построить глубокие модели обучения. Даже если мы используем здесь встраивания fastText, можно экспортировать любые другие вложения, предварительно обученные из других задач, и быстро получить результаты с помощью концентратора Tensorflow.
Настраивать
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Набор данных
Мы будем использовать Бард (Bangla Статья Dataset) , который имеет около 376226 статей , собранных из различных новостных порталов Bangla и меченных 5 категорий: экономики, государство, международные, спорт и развлечения. Скачиваем файл из Google Drive это ( bit.ly/BARD_DATASET ссылка) указывает ссылка из этого репозитория GitHub.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
Экспорт предварительно обученных векторов слов в модуль TF-Hub
TF-концентратор обеспечивает некоторые полезные скрипты для преобразования вложения слов в TF-концентраторов модулей текст встраиванию здесь . Для того, чтобы модуль для Bangla или любых других языках, мы просто должны загрузить слово вложение .txt или .vec файл в том же каталоге, export_v2.py и запустить скрипт.
Экспортер читает вложения векторов и экспортирует его в Tensorflow SavedModel . SavedModel содержит полную программу TensorFlow, включая веса и график. TF-концентратор может загрузить SavedModel как модуль , который мы будем использовать для построения модели для классификации текста. Так как мы используем tf.keras для построения модели, мы будем использовать hub.KerasLayer , который обеспечивает оболочку для модуля TF-концентратор для использования в качестве Keras слоя.
Во- первых , мы получим наши слова вложения от FastText и внедренный экспортер из TF-концентратора репо .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
Затем мы запустим сценарий экспорта для нашего внедренного файла. Поскольку вложения fastText имеют строку заголовка и довольно большие (около 3,3 ГБ для Bangla после преобразования в модуль), мы игнорируем первую строку и экспортируем только первые 100 000 токенов в модуль встраивания текста.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
Модуль встраивания текста принимает на входе пакет предложений в одномерном тензоре строк и выводит векторы внедрения формы (batch_size, embedding_dim), соответствующие предложениям. Он предварительно обрабатывает ввод, разбивая его на пробелы. Вложения слов комбинируются приговорить вложения с sqrtn объединителем (см здесь ). Для демонстрации мы передаем список слов Bangla в качестве входных данных и получаем соответствующие векторы внедрения.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
Преобразовать в набор данных Tensorflow
Поскольку набор данных действительно большой , а не загружать весь набор данных в памяти , мы будем использовать генератор для получения образцов в время выполнения в пакетном режиме с использованием Tensorflow набора данных функций. Набор данных также очень несбалансирован, поэтому перед использованием генератора мы перетасуем набор данных.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
Мы можем проверить распределение меток в примерах обучения и проверки после перетасовки.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
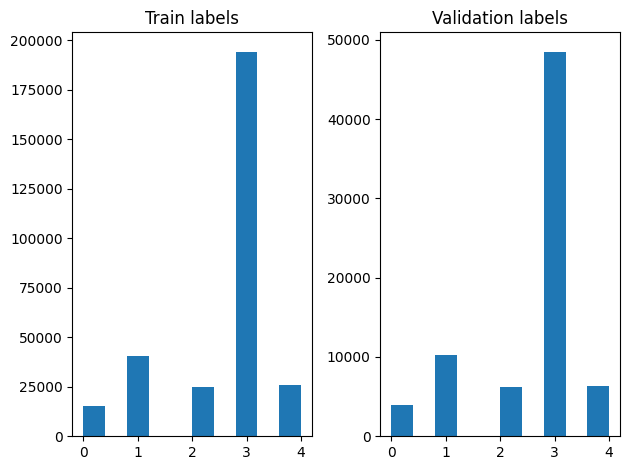
Для создания набора данных с помощью генератора, мы сначала напишем функцию генератора , который считывает каждый из статей file_paths и этикеток из массива этикеток, а также выходы один учебный пример на каждом шагу. Переходим эту функцию генератора в tf.data.Dataset.from_generator метод и указать типы выходных. Каждый учебный пример представляет собой кортеж , содержащий статью tf.string типа данных и один горячий кодированную метку. Мы разделили набор данных с раздельным железно-проверки в 80-20 с использованием tf.data.Dataset.skip и tf.data.Dataset.take методы.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
Модельное обучение и оценка
Так как мы уже добавили обертку вокруг нашего модуля , чтобы использовать его как любой другой слой в Keras, мы можем создать небольшую Последовательную модель , которая представляет собой линейный набор слоев. Мы можем добавить наш текст , внедренный модуль с model.add так же , как любой другой слой. Скомпилируем модель, указав потерю и оптимизатор, и обучаем ее 10 эпох. tf.keras API может обрабатывать Tensorflow наборов данных в качестве входных данных, поэтому мы можем передать экземпляр Dataset к пригонкам способу обучения модели. Так как мы используем функцию генератора, tf.data будет обрабатывать генерируя образцы, дозирование их и кормить их к модели.
Модель
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
Обучение
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
Оценка
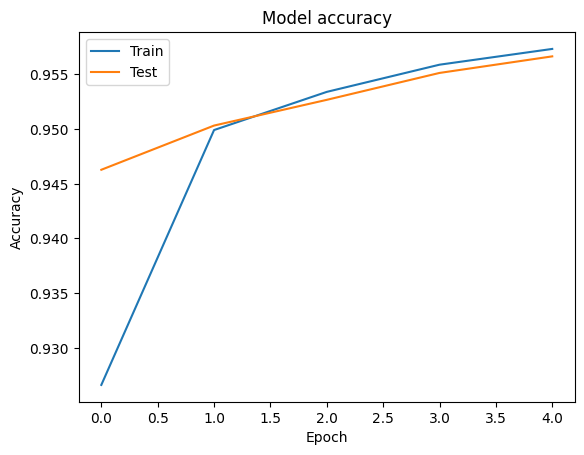
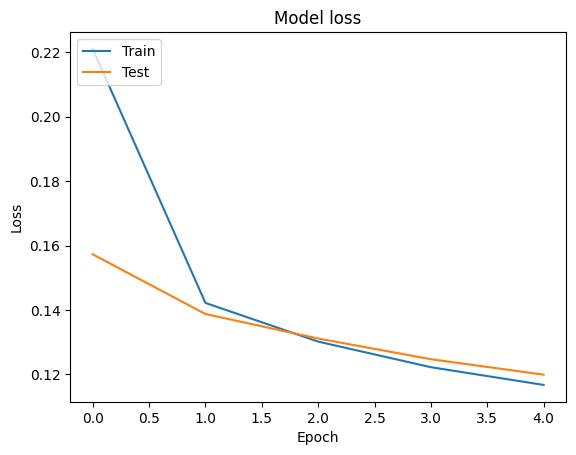
Мы можем визуализировать точность и потерь данных кривых для обучения и проверки с использованием tf.keras.callbacks.History объекта , возвращаемый tf.keras.Model.fit метода, который содержит значение потерь и точности для каждой эпохи.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
Прогноз
Мы можем получить прогнозы для данных проверки и проверить матрицу путаницы, чтобы увидеть производительность модели для каждого из 5 классов. Поскольку tf.keras.Model.predict метод возвращает массив я для вероятностей для каждого класса, они могут быть преобразованы в классе этикетки с использованием np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
Сравнить производительность
Теперь мы можем принимать правильные метки для проверки данных от labels и сравнить их с нашими прогнозами , чтобы получить classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
Мы также можем сравнить производительность нашей модели с опубликованными результатами , полученных в оригинальной статье , которая была 0,96 точности .The оригинальных авторы описали много шагов предварительной обработки выполняются на наборе данных, например, падение пунктуации и цифр, удаление верхних 25 самых frequest стоп - слов. Как мы можем видеть в classification_report , мы также смогли получить 0,96 точность и точность после тренировки только 5 эпох без какой - либо предварительной обработки!
В этом примере, когда мы создали слой Keras из нашего модуля вложения, мы устанавливаем параметр trainable=False , что означает , что вложения вес не будет обновляться во время тренировки. Попробуйте установить значение True , чтобы достичь примерно 97% точности с помощью этого набора данных только после 2 эпох.