
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này trình bày cách xây dựng và đào tạo mạng đối phương có điều kiện (cGAN) được gọi là pix2pix để học cách ánh xạ từ hình ảnh đầu vào đến hình ảnh đầu ra, như được mô tả trong phần Dịch hình ảnh sang hình ảnh với mạng đối phương có điều kiện của Isola et al. (2017). pix2pix không dành riêng cho ứng dụng — nó có thể được áp dụng cho nhiều tác vụ, bao gồm tổng hợp ảnh từ bản đồ nhãn, tạo ảnh màu từ ảnh đen trắng, biến ảnh trên Google Maps thành ảnh trên không và thậm chí chuyển bản phác thảo thành ảnh.
Trong ví dụ này, mạng của bạn sẽ tạo ra hình ảnh về các mặt tiền của tòa nhà bằng cách sử dụng Cơ sở dữ liệu về Mặt tiền CMP do Trung tâm Cảm nhận Máy tại Đại học Kỹ thuật Séc ở Praha cung cấp. Để ngắn gọn, bạn sẽ sử dụng bản sao được xử lý trước của tập dữ liệu này được tạo bởi các tác giả pix2pix.
Trong cGAN pix2pix, bạn điều kiện về hình ảnh đầu vào và tạo ra hình ảnh đầu ra tương ứng. cGAN lần đầu tiên được đề xuất trong Nets đối phương tạo ra có điều kiện (Mirza và Osindero, 2014)
Kiến trúc mạng của bạn sẽ bao gồm:
- Máy phát điện có kiến trúc dựa trên U-Net .
- Một bộ phân biệt được đại diện bởi bộ phân loại PatchGAN phức hợp (được đề xuất trong bài báo pix2pix ).
Lưu ý rằng mỗi kỷ nguyên có thể mất khoảng 15 giây trên một GPU V100.
Dưới đây là một số ví dụ về kết quả đầu ra do pix2pix cGAN tạo ra sau khi đào tạo trong 200 kỷ nguyên trên tập dữ liệu mặt tiền (80 nghìn bước).


Nhập TensorFlow và các thư viện khác
import tensorflow as tf
import os
import pathlib
import time
import datetime
from matplotlib import pyplot as plt
from IPython import display
Tải tập dữ liệu
Tải xuống dữ liệu Cơ sở dữ liệu mặt tiền CMP (30MB). Các bộ dữ liệu bổ sung có sẵn ở định dạng tương tự tại đây . Trong Colab, bạn có thể chọn các bộ dữ liệu khác từ menu thả xuống. Lưu ý rằng một số bộ dữ liệu khác lớn hơn đáng kể ( edges2handbags là 8GB).
dataset_name = "facades"
_URL = f'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{dataset_name}.tar.gz'
path_to_zip = tf.keras.utils.get_file(
fname=f"{dataset_name}.tar.gz",
origin=_URL,
extract=True)
path_to_zip = pathlib.Path(path_to_zip)
PATH = path_to_zip.parent/dataset_name
Downloading data from http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz 30171136/30168306 [==============================] - 19s 1us/step 30179328/30168306 [==============================] - 19s 1us/step
list(PATH.parent.iterdir())
[PosixPath('/home/kbuilder/.keras/datasets/facades.tar.gz'),
PosixPath('/home/kbuilder/.keras/datasets/YellowLabradorLooking_new.jpg'),
PosixPath('/home/kbuilder/.keras/datasets/facades'),
PosixPath('/home/kbuilder/.keras/datasets/mnist.npz')]
Mỗi hình ảnh gốc có kích thước 256 x 512 chứa hai hình ảnh 256 x 256 :
sample_image = tf.io.read_file(str(PATH / 'train/1.jpg'))
sample_image = tf.io.decode_jpeg(sample_image)
print(sample_image.shape)
(256, 512, 3)
plt.figure()
plt.imshow(sample_image)
<matplotlib.image.AxesImage at 0x7f35a3653c90>
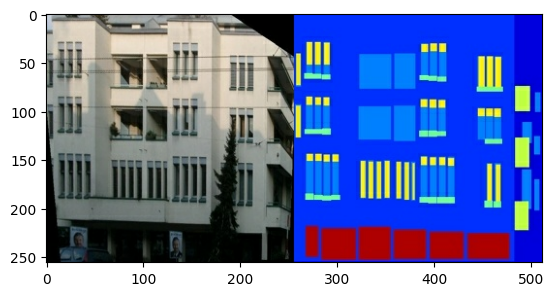
Bạn cần tách các hình ảnh mặt tiền của tòa nhà thực khỏi các hình ảnh nhãn kiến trúc — tất cả đều có kích thước 256 x 256 .
Xác định một chức năng tải các tệp hình ảnh và xuất ra hai bộ căng hình ảnh:
def load(image_file):
# Read and decode an image file to a uint8 tensor
image = tf.io.read_file(image_file)
image = tf.io.decode_jpeg(image)
# Split each image tensor into two tensors:
# - one with a real building facade image
# - one with an architecture label image
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, w:, :]
real_image = image[:, :w, :]
# Convert both images to float32 tensors
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
Vẽ một mẫu của hình ảnh đầu vào (hình ảnh nhãn kiến trúc) và hình ảnh thực (hình ảnh mặt tiền tòa nhà):
inp, re = load(str(PATH / 'train/100.jpg'))
# Casting to int for matplotlib to display the images
plt.figure()
plt.imshow(inp / 255.0)
plt.figure()
plt.imshow(re / 255.0)
<matplotlib.image.AxesImage at 0x7f35981a4910>
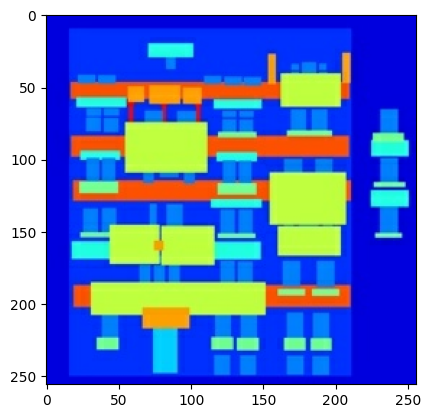
Như được mô tả trong bài báo pix2pix , bạn cần áp dụng tính năng phản chiếu và phản chiếu ngẫu nhiên để xử lý trước tập huấn luyện.
Xác định một số chức năng:
- Thay đổi kích thước từng hình ảnh
256 x 256thành chiều cao và chiều rộng lớn hơn—286 x 286. - Cắt ngẫu nhiên nó trở lại
256 x 256. - Lật ngẫu nhiên hình ảnh theo chiều ngang tức là từ trái sang phải (phản chiếu ngẫu nhiên).
- Chuẩn hóa hình ảnh thành phạm vi
[-1, 1].
# The facade training set consist of 400 images
BUFFER_SIZE = 400
# The batch size of 1 produced better results for the U-Net in the original pix2pix experiment
BATCH_SIZE = 1
# Each image is 256x256 in size
IMG_WIDTH = 256
IMG_HEIGHT = 256
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# Normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# Resizing to 286x286
input_image, real_image = resize(input_image, real_image, 286, 286)
# Random cropping back to 256x256
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# Random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
Bạn có thể kiểm tra một số đầu ra được xử lý trước:
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i + 1)
plt.imshow(rj_inp / 255.0)
plt.axis('off')
plt.show()
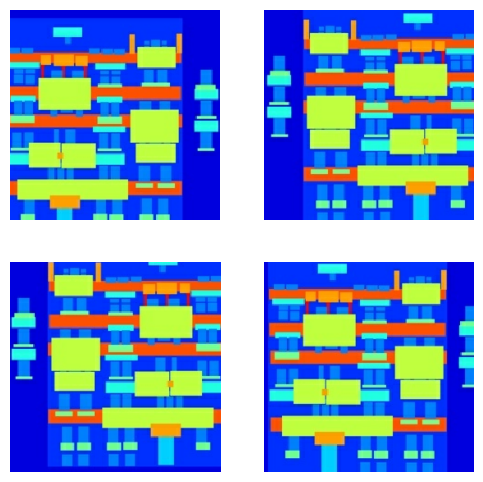
Sau khi kiểm tra xem quá trình tải và tiền xử lý có hoạt động hay không, hãy xác định một số hàm trợ giúp tải và xử lý trước các tập huấn luyện và kiểm tra:
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
Xây dựng đường dẫn đầu vào với tf.data
train_dataset = tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
try:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'test/*.jpg'))
except tf.errors.InvalidArgumentError:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'val/*.jpg'))
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
Xây dựng máy phát điện
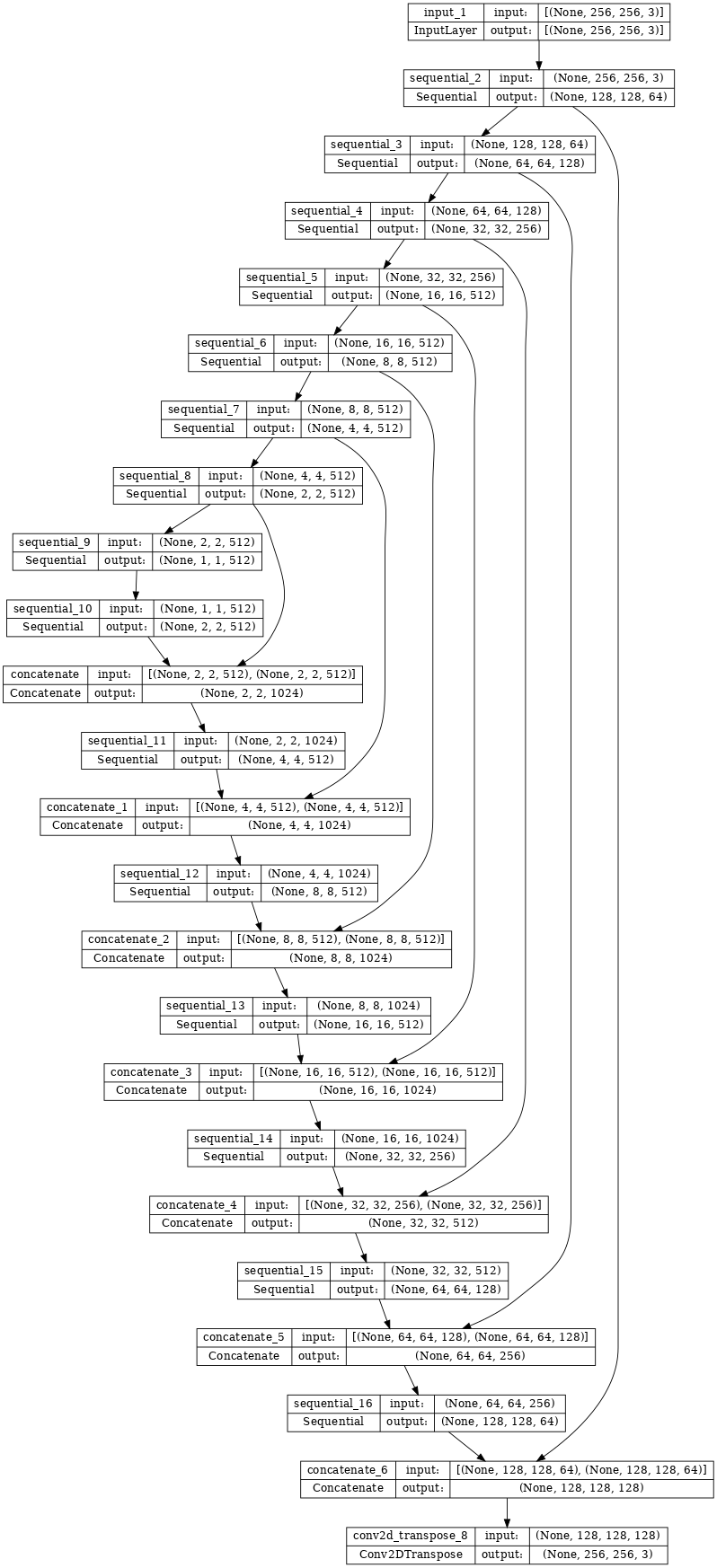
Trình tạo pix2pix cGAN của bạn là một U-Net đã được sửa đổi . Một U-Net bao gồm bộ mã hóa (downampler) và bộ giải mã (upsampler). (Bạn có thể tìm hiểu thêm về nó trong hướng dẫn Phân đoạn hình ảnh và trên trang web của dự án U-Net .)
- Mỗi khối trong bộ mã hóa là: Convolution -> Batch normalization -> Leaky ReLU
- Mỗi khối trong bộ giải mã là: Tích chập chuyển đổi -> Chuẩn hóa hàng loạt -> Bỏ qua (áp dụng cho 3 khối đầu tiên) -> ReLU
- Có các kết nối bỏ qua giữa bộ mã hóa và bộ giải mã (như trong U-Net).
Xác định bộ lấy mẫu xuống (bộ mã hóa):
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
(1, 128, 128, 3)
Xác định bộ lấy mẫu khuếch đại (bộ giải mã):
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
(1, 256, 256, 3)
Xác định bộ tạo với bộ lấy mẫu xuống và bộ lấy mẫu lên:
def Generator():
inputs = tf.keras.layers.Input(shape=[256, 256, 3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (batch_size, 128, 128, 64)
downsample(128, 4), # (batch_size, 64, 64, 128)
downsample(256, 4), # (batch_size, 32, 32, 256)
downsample(512, 4), # (batch_size, 16, 16, 512)
downsample(512, 4), # (batch_size, 8, 8, 512)
downsample(512, 4), # (batch_size, 4, 4, 512)
downsample(512, 4), # (batch_size, 2, 2, 512)
downsample(512, 4), # (batch_size, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (batch_size, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 8, 8, 1024)
upsample(512, 4), # (batch_size, 16, 16, 1024)
upsample(256, 4), # (batch_size, 32, 32, 512)
upsample(128, 4), # (batch_size, 64, 64, 256)
upsample(64, 4), # (batch_size, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (batch_size, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Hình dung kiến trúc mô hình trình tạo:
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
Kiểm tra máy phát điện:
gen_output = generator(inp[tf.newaxis, ...], training=False)
plt.imshow(gen_output[0, ...])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). <matplotlib.image.AxesImage at 0x7f35cfd20610>
Xác định tổn thất máy phát điện
GAN học một lỗ thích ứng với dữ liệu, trong khi cGAN học một lỗ có cấu trúc phạt một cấu trúc có thể có khác với đầu ra mạng và hình ảnh đích, như được mô tả trong bài báo pix2pix .
- Suy hao bộ tạo là mất entropy chéo sigmoid của các hình ảnh được tạo ra và một mảng của các hình ảnh đó.
- Bài báo pix2pix cũng đề cập đến sự mất mát L1, là một MAE (sai số tuyệt đối trung bình) giữa hình ảnh được tạo ra và hình ảnh đích.
- Điều này cho phép hình ảnh được tạo ra trở nên tương tự về cấu trúc với hình ảnh đích.
- Công thức để tính tổng tổn thất của máy phát là
gan_loss + LAMBDA * l1_loss, trong đóLAMBDA = 100. Giá trị này được quyết định bởi các tác giả của bài báo.
LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# Mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
Quy trình đào tạo cho máy phát điện như sau:

Xây dựng bộ phân biệt
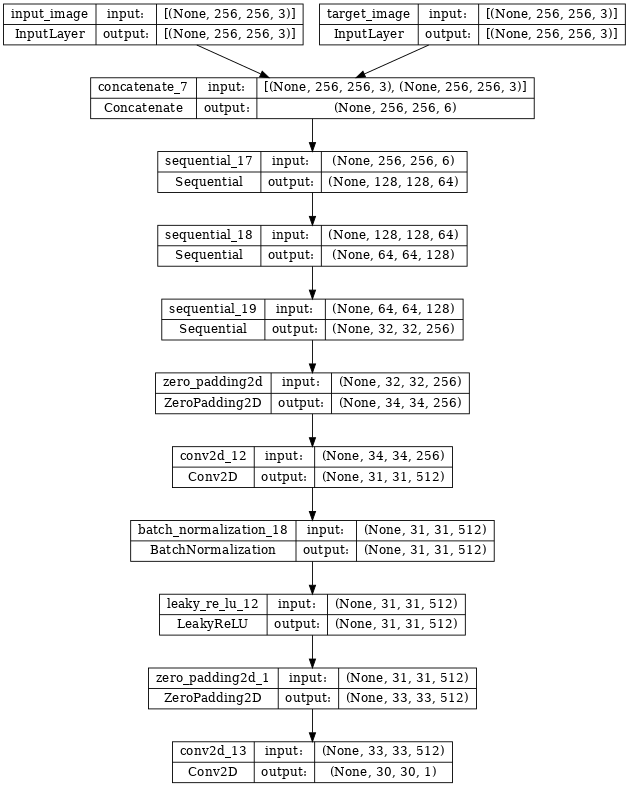
Bộ phân biệt trong pix2pix cGAN là bộ phân loại PatchGAN phức hợp — nó cố gắng phân loại xem mỗi bản vá hình ảnh là thật hay không thật, như được mô tả trong bài báo pix2pix .
- Mỗi khối trong bộ phân biệt là: Convolution -> Batch normalization -> Leaky ReLU.
- Hình dạng của đầu ra sau lớp cuối cùng là
(batch_size, 30, 30, 1). - Mỗi bản vá hình ảnh
30 x 30của đầu ra phân loại một phần70 x 70của hình ảnh đầu vào. - Bộ phân biệt nhận được 2 đầu vào:
- Hình ảnh đầu vào và hình ảnh mục tiêu, mà nó sẽ được phân loại là thực.
- Hình ảnh đầu vào và hình ảnh được tạo ra (đầu ra của máy phát điện), mà nó sẽ được phân loại là giả mạo.
- Sử dụng
tf.concat([inp, tar], axis=-1)để nối 2 đầu vào này với nhau.
Hãy xác định dấu phân biệt:
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (batch_size, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (batch_size, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (batch_size, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (batch_size, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (batch_size, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (batch_size, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (batch_size, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (batch_size, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
Hình dung kiến trúc mô hình phân biệt:
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
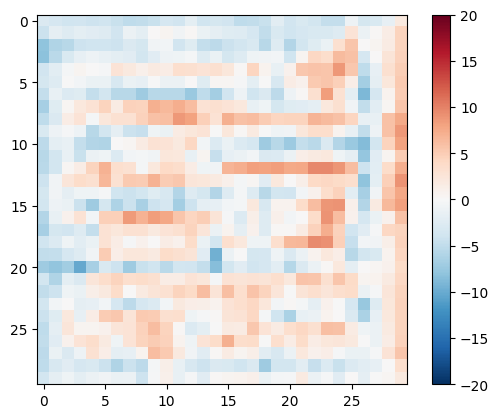
Kiểm tra bộ phân biệt:
disc_out = discriminator([inp[tf.newaxis, ...], gen_output], training=False)
plt.imshow(disc_out[0, ..., -1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x7f35cec82c50>
Xác định tổn thất phân biệt đối xử
- Hàm
discriminator_lossnhận 2 đầu vào: hình ảnh thực và hình ảnh được tạo . -
real_losslà sự mất đi entropy chéo sigmoid của các hình ảnh thực và một mảng của những hình ảnh đó (vì đây là những hình ảnh thực) . -
generated_losslà một mất mát entropy chéo sigmoid của các hình ảnh được tạo và một mảng các số không (vì đây là những hình ảnh giả mạo) . -
total_losslà tổng củareal_lossvàgenerated_loss.
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
Quy trình đào tạo cho người phân biệt đối xử được trình bày dưới đây.
Để tìm hiểu thêm về kiến trúc và các siêu thông số, bạn có thể tham khảo trang pix2pix .

Xác định trình tối ưu hóa và trình tiết kiệm điểm kiểm tra
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Tạo hình ảnh
Viết một hàm để vẽ một số hình ảnh trong quá trình đào tạo.
- Truyền hình ảnh từ bộ thử nghiệm sang bộ tạo.
- Sau đó bộ tạo sẽ dịch hình ảnh đầu vào thành đầu ra.
- Bước cuối cùng là lập kế hoạch cho các dự đoán và thì đấy !
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15, 15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# Getting the pixel values in the [0, 1] range to plot.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Kiểm tra chức năng:
for example_input, example_target in test_dataset.take(1):
generate_images(generator, example_input, example_target)

Tập huấn
- Đối với mỗi ví dụ đầu vào tạo ra một đầu ra.
- Bộ phân biệt nhận
input_imagevà hình ảnh được tạo làm đầu vào đầu tiên. Đầu vào thứ hai làinput_imagevàtarget_image. - Tiếp theo, tính toán máy phát điện và tổn hao bộ phân biệt.
- Sau đó, tính toán các mức độ mất mát liên quan đến cả biến trình tạo và biến phân biệt (đầu vào) và áp dụng chúng cho trình tối ưu hóa.
- Cuối cùng, ghi các khoản lỗ vào TensorBoard.
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
@tf.function
def train_step(input_image, target, step):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=step//1000)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=step//1000)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=step//1000)
tf.summary.scalar('disc_loss', disc_loss, step=step//1000)
Các vòng lặp đào tạo thực tế. Vì hướng dẫn này có thể chạy nhiều hơn một tập dữ liệu và các tập dữ liệu khác nhau rất nhiều về kích thước nên vòng lặp đào tạo được thiết lập để hoạt động theo từng bước thay vì kỷ nguyên.
- Lặp lại nhiều bước.
- Cứ sau 10 bước in một dấu chấm (
.). - Cứ sau 1k bước: xóa màn hình và chạy
generate_imagesđể hiển thị tiến trình. - Cứ sau 5k bước: lưu một điểm kiểm tra.
def fit(train_ds, test_ds, steps):
example_input, example_target = next(iter(test_ds.take(1)))
start = time.time()
for step, (input_image, target) in train_ds.repeat().take(steps).enumerate():
if (step) % 1000 == 0:
display.clear_output(wait=True)
if step != 0:
print(f'Time taken for 1000 steps: {time.time()-start:.2f} sec\n')
start = time.time()
generate_images(generator, example_input, example_target)
print(f"Step: {step//1000}k")
train_step(input_image, target, step)
# Training step
if (step+1) % 10 == 0:
print('.', end='', flush=True)
# Save (checkpoint) the model every 5k steps
if (step + 1) % 5000 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
Vòng đào tạo này lưu nhật ký mà bạn có thể xem trong TensorBoard để theo dõi tiến trình đào tạo.
Nếu bạn làm việc trên một máy cục bộ, bạn sẽ khởi chạy một quy trình TensorBoard riêng biệt. Khi làm việc trong sổ ghi chép, hãy khởi chạy trình xem trước khi bắt đầu đào tạo để theo dõi bằng TensorBoard.
Để khởi chạy trình xem, hãy dán nội dung sau vào một ô mã:
%load_ext tensorboard
%tensorboard --logdir {log_dir}
Cuối cùng, chạy vòng lặp đào tạo:
fit(train_dataset, test_dataset, steps=40000)
Time taken for 1000 steps: 36.53 sec

Step: 39k ....................................................................................................
Nếu bạn muốn chia sẻ công khai kết quả TensorBoard, bạn có thể tải nhật ký lên TensorBoard.dev bằng cách sao chép phần sau vào một ô mã.
tensorboard dev upload --logdir {log_dir}
Bạn có thể xem kết quả của lần chạy trước đó của sổ ghi chép này trên TensorBoard.dev .
TensorBoard.dev là một trải nghiệm được quản lý để lưu trữ, theo dõi và chia sẻ các thử nghiệm ML với mọi người.
Nó cũng có thể được đưa vào nội tuyến bằng cách sử dụng <iframe> :
display.IFrame(
src="https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw",
width="100%",
height="1000px")
Việc diễn giải các bản ghi sẽ tinh tế hơn khi huấn luyện một GAN (hoặc một cGAN như pix2pix) so với một mô hình phân loại hoặc hồi quy đơn giản. Những điều cần tìm:
- Kiểm tra để đảm bảo rằng cả bộ tạo và mô hình phân biệt đều không "thắng". Nếu
gen_gan_losshoặcdisc_lossrất thấp, thì đó là dấu hiệu cho thấy mô hình này đang thống trị mô hình kia và bạn không đào tạo thành công mô hình kết hợp. - Giá trị
log(2) = 0.69là một điểm tham chiếu tốt cho những tổn thất này, vì nó chỉ ra sự khó hiểu của 2 - trung bình, bộ phân biệt không chắc chắn như nhau về hai lựa chọn. - Đối với
disc_loss, giá trị dưới0.69có nghĩa là bộ phân biệt đang hoạt động tốt hơn so với ngẫu nhiên trên tập hợp các hình ảnh thực và được tạo kết hợp. - Đối với
gen_gan_loss, giá trị dưới0.69có nghĩa là trình tạo đang hoạt động tốt hơn ngẫu nhiên trong việc đánh lừa bộ phân biệt. - Khi quá trình đào tạo diễn ra,
gen_l1_losssẽ giảm xuống.
Khôi phục điểm kiểm tra mới nhất và kiểm tra mạng
ls {checkpoint_dir}
checkpoint ckpt-5.data-00000-of-00001 ckpt-1.data-00000-of-00001 ckpt-5.index ckpt-1.index ckpt-6.data-00000-of-00001 ckpt-2.data-00000-of-00001 ckpt-6.index ckpt-2.index ckpt-7.data-00000-of-00001 ckpt-3.data-00000-of-00001 ckpt-7.index ckpt-3.index ckpt-8.data-00000-of-00001 ckpt-4.data-00000-of-00001 ckpt-8.index ckpt-4.index
# Restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f35cfd6b8d0>
Tạo một số hình ảnh bằng cách sử dụng bộ thử nghiệm
# Run the trained model on a few examples from the test set
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)




