
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này tập trung vào nhiệm vụ phân đoạn hình ảnh, sử dụng U-Net đã được sửa đổi.
Phân đoạn hình ảnh là gì?
Trong tác vụ phân loại ảnh, mạng sẽ gán nhãn (hoặc lớp) cho mỗi ảnh đầu vào. Tuy nhiên, giả sử bạn muốn biết hình dạng của đối tượng đó, pixel thuộc về đối tượng nào, v.v. Trong trường hợp này, bạn sẽ muốn gán một lớp cho mỗi pixel của hình ảnh. Nhiệm vụ này được gọi là phân đoạn. Mô hình phân đoạn trả về nhiều thông tin chi tiết hơn về hình ảnh. Phân đoạn hình ảnh có nhiều ứng dụng trong hình ảnh y tế, xe ô tô tự lái và hình ảnh vệ tinh.
Hướng dẫn này sử dụng Bộ dữ liệu thú cưng của Oxford-IIIT ( Parkhi và cộng sự, 2012 ). Bộ dữ liệu bao gồm hình ảnh của 37 giống vật nuôi, với 200 hình ảnh cho mỗi giống (~ 100 hình ảnh mỗi giống trong phần đào tạo và thử nghiệm). Mỗi hình ảnh bao gồm các nhãn tương ứng và mặt nạ theo pixel. Các mặt nạ là nhãn lớp cho mỗi pixel. Mỗi pixel được cung cấp một trong ba danh mục:
- Lớp 1: Pixel thuộc về vật nuôi.
- Lớp 2: Pixel bao quanh vật nuôi.
- Loại 3: Không có pixel nào ở trên / một pixel xung quanh.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
Tải xuống bộ dữ liệu Oxford-IIIT Pets
Tập dữ liệu có sẵn từ Bộ dữ liệu TensorFlow . Các mặt nạ phân đoạn được bao gồm trong phiên bản 3+.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
Ngoài ra, các giá trị màu ảnh được chuẩn hóa thành phạm vi [0,1] . Cuối cùng, như đã đề cập ở trên, các pixel trong mặt nạ phân đoạn được gắn nhãn {1, 2, 3}. Để thuận tiện, hãy trừ đi 1 từ mặt nạ phân đoạn, dẫn đến các nhãn là: {0, 1, 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
Tập dữ liệu đã chứa các phần tách đào tạo và kiểm tra bắt buộc, vì vậy hãy tiếp tục sử dụng các phần tách tương tự.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
Lớp sau thực hiện một phép tăng đơn giản bằng cách lật ngẫu nhiên một hình ảnh. Đi tới Hướng dẫn tăng hình ảnh để tìm hiểu thêm.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
Xây dựng đường dẫn đầu vào, áp dụng Tăng cường sau khi phân phối các đầu vào.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
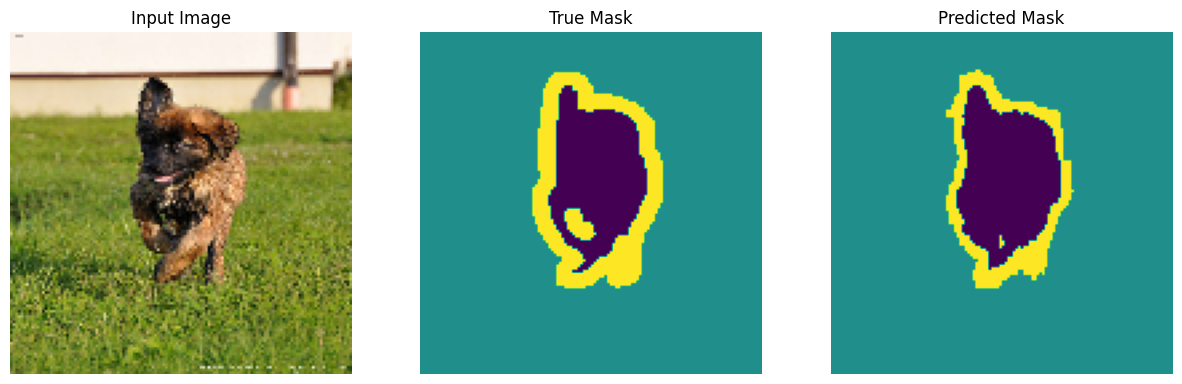
Hình dung một ví dụ hình ảnh và mặt nạ tương ứng của nó từ tập dữ liệu.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Xác định mô hình
Mô hình đang được sử dụng ở đây là một U-Net đã được sửa đổi. Một U-Net bao gồm bộ mã hóa (downampler) và bộ giải mã (upsampler). Để tìm hiểu các tính năng mạnh mẽ và giảm số lượng thông số có thể đào tạo, bạn sẽ sử dụng mô hình đào tạo trước - MobileNetV2 - làm bộ mã hóa. Đối với bộ giải mã, bạn sẽ sử dụng khối upsample, khối này đã được triển khai trong ví dụ pix2pix trong repo TensorFlow Examples. (Kiểm tra pix2pix: Bản dịch từ ảnh sang ảnh với hướng dẫn GAN có điều kiện trong sổ tay.)
Như đã đề cập, bộ mã hóa sẽ là một mô hình MobileNetV2 được đào tạo trước, được chuẩn bị và sẵn sàng sử dụng trong các ứng dụng tf.keras.applications . Bộ mã hóa bao gồm các đầu ra cụ thể từ các lớp trung gian trong mô hình. Lưu ý rằng bộ mã hóa sẽ không được đào tạo trong quá trình đào tạo.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
Bộ giải mã / bộ lấy mẫu chỉ đơn giản là một loạt các khối mẫu được triển khai trong các ví dụ của TensorFlow.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Lưu ý rằng số lượng bộ lọc trên lớp cuối cùng được đặt thành số output_channels đầu ra. Đây sẽ là một kênh đầu ra cho mỗi lớp.
Đào tạo mô hình
Bây giờ, tất cả những gì còn lại cần làm là biên dịch và đào tạo mô hình.
Vì đây là vấn đề phân loại đa lớp, hãy sử dụng hàm mất mát tf.keras.losses.CategoricalCrossentropy với đối số from_logits được đặt thành True , vì các nhãn là số nguyên vô hướng thay vì vectơ điểm cho mỗi pixel của mọi lớp.
Khi chạy suy luận, nhãn được gán cho pixel là kênh có giá trị cao nhất. Đây là những gì hàm create_mask đang làm.
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
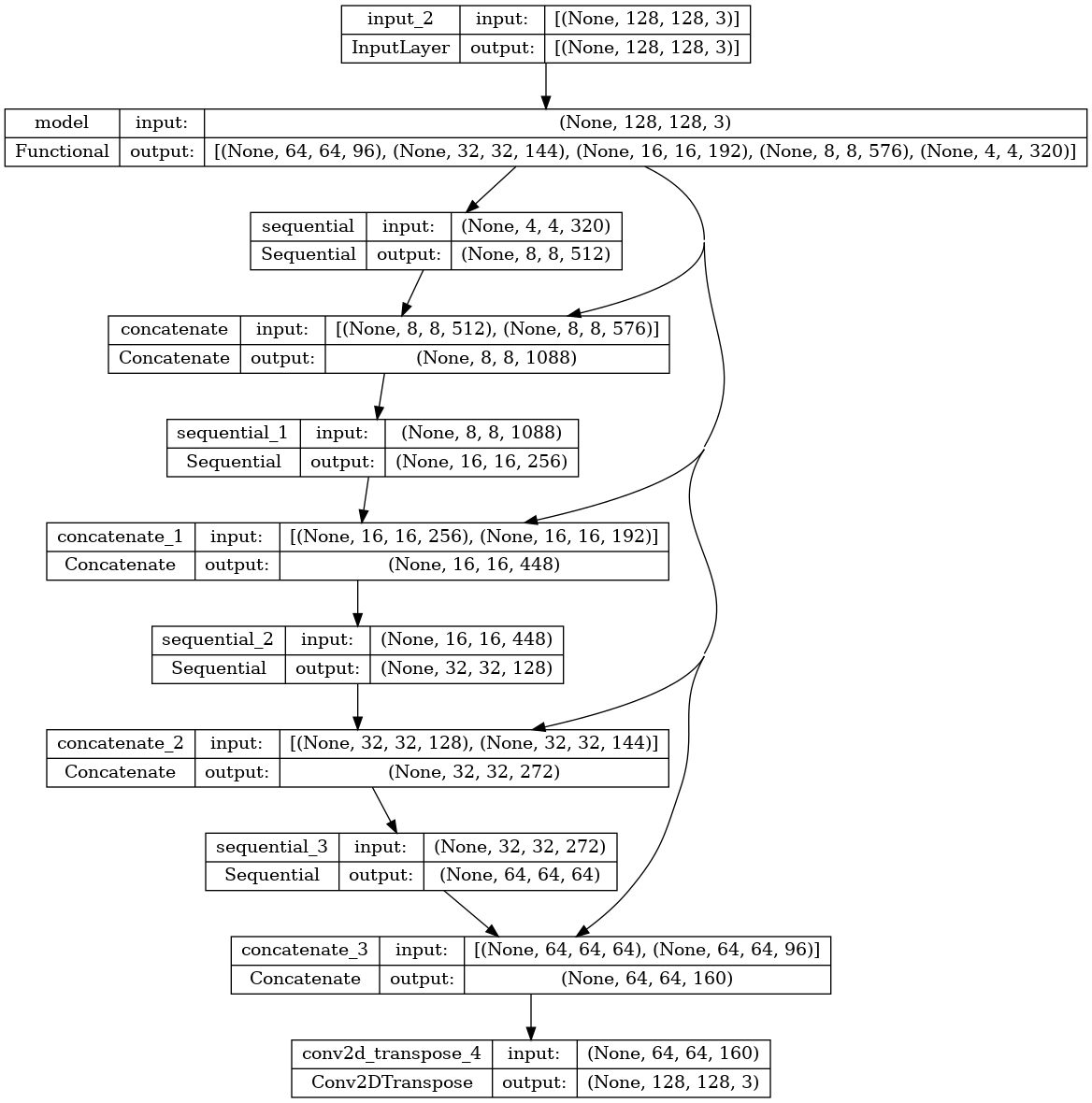
Hãy xem nhanh kiến trúc mô hình kết quả:
tf.keras.utils.plot_model(model, show_shapes=True)
Hãy thử mô hình để kiểm tra những gì nó dự đoán trước khi đào tạo.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

Lệnh gọi lại được xác định bên dưới được sử dụng để quan sát cách mô hình cải thiện trong khi nó đang được đào tạo.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
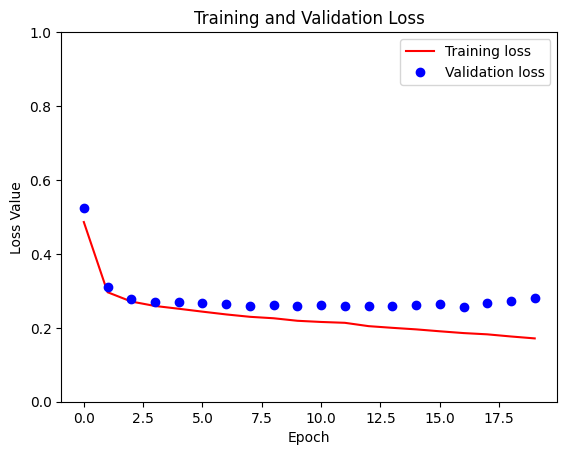
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
Dự đoán
Bây giờ, hãy đưa ra một số dự đoán. Vì lợi ích của việc tiết kiệm thời gian, số lượng kỷ nguyên được giữ ở mức nhỏ, nhưng bạn có thể đặt giá trị này cao hơn để đạt được kết quả chính xác hơn.
show_predictions(test_batches, 3)


Tùy chọn: Hạng không cân bằng và trọng lượng hạng
Tập dữ liệu phân đoạn ngữ nghĩa có thể mất cân bằng cao, nghĩa là các pixel của lớp cụ thể có thể hiện diện bên trong hình ảnh nhiều hơn so với các pixel của các lớp khác. Vì các vấn đề phân đoạn có thể được coi là vấn đề phân loại theo pixel, bạn có thể giải quyết vấn đề mất cân bằng bằng cách cân nhắc hàm mất mát để giải thích cho vấn đề này. Đó là một cách đơn giản và thanh lịch để giải quyết vấn đề này. Tham khảo hướng dẫn Phân loại về dữ liệu mất cân bằng để tìm hiểu thêm.
Để tránh sự mơ hồ , Model.fit không hỗ trợ đối số class_weight cho các đầu vào có 3 thứ nguyên trở lên.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
Vì vậy, trong trường hợp này, bạn cần tự thực hiện việc tính trọng số. Bạn sẽ thực hiện việc này bằng cách sử dụng trọng lượng mẫu: Ngoài các cặp (data, label) , Model.fit cũng chấp nhận bộ ba (data, label, sample_weight) .
Model.fit truyền dẫn sample_weight cho các tổn thất và chỉ số, cũng chấp nhận đối số sample_weight . Khối lượng mẫu được nhân với giá trị của mẫu trước bước khử. Ví dụ:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
Vì vậy, để tạo các trọng số mẫu cho hướng dẫn này, bạn cần một hàm nhận một cặp (data, label) và trả về một (data, label, sample_weight) gấp ba. Trong đó sample_weight là hình ảnh 1 kênh chứa trọng lượng lớp cho mỗi pixel.
Cách triển khai đơn giản nhất có thể là sử dụng nhãn làm chỉ mục vào danh sách class_weight :
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
Các phần tử tập dữ liệu kết quả chứa 3 hình ảnh, mỗi phần tử:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
Bây giờ bạn có thể đào tạo một mô hình trên tập dữ liệu có trọng số này:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
Bước tiếp theo
Bây giờ bạn đã hiểu phân đoạn hình ảnh là gì và nó hoạt động như thế nào, bạn có thể thử hướng dẫn này với các đầu ra lớp trung gian khác nhau hoặc thậm chí các mô hình được đào tạo trước khác nhau. Bạn cũng có thể thử thách bản thân bằng cách thử thách thức tạo mặt nạ hình ảnh Carvana được tổ chức trên Kaggle.
Bạn cũng có thể muốn xem API phát hiện đối tượng Tensorflow cho một mô hình khác mà bạn có thể đào tạo lại trên dữ liệu của riêng mình. Các mô hình tiền chế có sẵn trên TensorFlow Hub