
| | |  Xem trên GitHub Xem trên GitHub | | |
Hướng dẫn này sử dụng học sâu để tạo một hình ảnh theo phong cách của một hình ảnh khác (bạn đã bao giờ ước mình có thể vẽ như Picasso hoặc Van Gogh?). Đây được gọi là chuyển kiểu thần kinh và kỹ thuật này được nêu trong Một thuật toán thần kinh của phong cách nghệ thuật (Gatys et al.).
Để có ứng dụng chuyển kiểu đơn giản, hãy xem hướng dẫn này để tìm hiểu thêm về cách sử dụng mô hình Cách điệu hình ảnh tùy ý được đào tạo trước từ TensorFlow Hub hoặc cách sử dụng mô hình chuyển kiểu với TensorFlow Lite .
Truyền kiểu thần kinh là một kỹ thuật tối ưu hóa được sử dụng để chụp hai hình ảnh — hình ảnh nội dung và hình ảnh tham chiếu kiểu (chẳng hạn như tác phẩm nghệ thuật của một họa sĩ nổi tiếng) —và kết hợp chúng với nhau để hình ảnh đầu ra trông giống như hình ảnh nội dung nhưng “được vẽ” theo kiểu của hình ảnh tham chiếu kiểu.
Điều này được thực hiện bằng cách tối ưu hóa hình ảnh đầu ra để khớp với thống kê nội dung của hình ảnh nội dung và thống kê kiểu của hình ảnh tham chiếu kiểu. Các số liệu thống kê này được trích xuất từ các hình ảnh bằng cách sử dụng một mạng phức hợp.
Ví dụ: hãy chụp ảnh con chó này và Sáng tác 7 của Wassily Kandinsky:

Yellow Labrador Looking , từ Wikimedia Commons của Elf . Giấy phép CC BY-SA 3.0
{kind=link}

Bây giờ sẽ như thế nào nếu Kandinsky quyết định vẽ bức tranh Con chó này độc quyền với phong cách này? Một cái gì đó như thế này?

Thành lập
Nhập và định cấu hình mô-đun
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
Tải xuống hình ảnh và chọn hình ảnh kiểu và hình ảnh nội dung:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
Hình dung đầu vào
Xác định một hàm để tải một hình ảnh và giới hạn kích thước tối đa của nó là 512 pixel.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
Tạo một chức năng đơn giản để hiển thị hình ảnh:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

Truyền nhanh kiểu dáng bằng TF-Hub
Hướng dẫn này trình bày thuật toán chuyển kiểu ban đầu, thuật toán này tối ưu hóa nội dung hình ảnh theo một kiểu cụ thể. Trước khi đi vào chi tiết, hãy xem cách mô hình TensorFlow Hub thực hiện điều này:
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
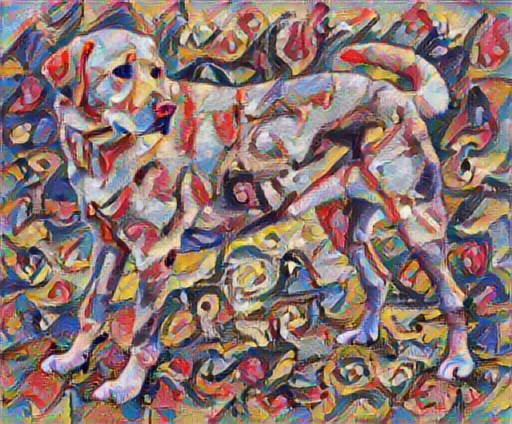
Xác định nội dung và trình bày phong cách
Sử dụng các lớp trung gian của mô hình để có được nội dung và kiểu thể hiện của hình ảnh. Bắt đầu từ lớp đầu vào của mạng, một số kích hoạt lớp đầu tiên đại diện cho các tính năng cấp thấp như các cạnh và kết cấu. Khi bạn lướt qua mạng, một vài lớp cuối cùng đại diện cho các tính năng cấp cao hơn — các bộ phận của đối tượng như bánh xe hoặc mắt . Trong trường hợp này, bạn đang sử dụng kiến trúc mạng VGG19, một mạng phân loại hình ảnh được đào tạo trước. Các lớp trung gian này là cần thiết để xác định sự thể hiện của nội dung và phong cách từ hình ảnh. Đối với hình ảnh đầu vào, hãy cố gắng khớp các biểu diễn mục tiêu nội dung và kiểu tương ứng tại các lớp trung gian này.
Tải VGG19 và chạy thử nghiệm nó trên hình ảnh của chúng tôi để đảm bảo nó được sử dụng đúng cách:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
Bây giờ tải một VGG19 mà không có đầu phân loại và liệt kê tên lớp
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
Chọn các lớp trung gian từ mạng để thể hiện phong cách và nội dung của hình ảnh:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
Các lớp trung gian cho phong cách và nội dung
Vậy tại sao các kết quả đầu ra trung gian này trong mạng phân loại hình ảnh được đào tạo trước của chúng tôi lại cho phép chúng tôi xác định các biểu diễn phong cách và nội dung?
Ở mức độ cao, để một mạng thực hiện phân loại ảnh (mà mạng này đã được đào tạo để làm) thì nó phải hiểu được ảnh. Điều này đòi hỏi phải lấy hình ảnh thô làm pixel đầu vào và xây dựng một biểu diễn bên trong để chuyển đổi pixel hình ảnh thô thành một sự hiểu biết phức tạp về các đặc điểm có trong hình ảnh.
Đây cũng là lý do tại sao mạng nơ-ron tích tụ có khả năng tổng quát hóa tốt: chúng có thể nắm bắt các bất biến và xác định các tính năng bên trong các lớp (ví dụ: mèo và chó) không có khả năng chống lại tiếng ồn xung quanh và các phiền toái khác. Do đó, ở đâu đó giữa nơi hình ảnh thô được đưa vào mô hình và nhãn phân loại đầu ra, mô hình đóng vai trò như một bộ trích xuất tính năng phức tạp. Bằng cách truy cập các lớp trung gian của mô hình, bạn có thể mô tả nội dung và kiểu dáng của hình ảnh đầu vào.
Xây dựng mô hình
Các mạng trong tf.keras.applications được thiết kế để bạn có thể dễ dàng trích xuất các giá trị lớp trung gian bằng cách sử dụng API chức năng Keras.
Để xác định một mô hình bằng cách sử dụng API chức năng, hãy chỉ định các đầu vào và đầu ra:
model = Model(inputs, outputs)
Hàm sau đây xây dựng mô hình VGG19 trả về danh sách các đầu ra của lớp trung gian:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
Và để tạo mô hình:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
Tính toán phong cách
Nội dung của hình ảnh được thể hiện bằng các giá trị của các bản đồ đối tượng trung gian.
Hóa ra, phong cách của một hình ảnh có thể được mô tả bằng các phương tiện và mối tương quan trên các bản đồ đối tượng địa lý khác nhau. Tính toán ma trận Gram bao gồm thông tin này bằng cách lấy tích ngoài của vectơ đặc trưng với chính nó tại mỗi vị trí và lấy trung bình sản phẩm bên ngoài đó trên tất cả các vị trí. Ma trận Gram này có thể được tính toán cho một lớp cụ thể như sau:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
Điều này có thể được thực hiện ngắn gọn bằng cách sử dụng hàm tf.linalg.einsum :
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
Trích xuất phong cách và nội dung
Xây dựng một mô hình trả về kiểu và nội dung.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
Khi được gọi trên một hình ảnh, mô hình này trả về ma trận gam (kiểu) của style_layers và nội dung của content_layers :
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
Chạy dốc xuống
Với trình trích xuất kiểu và nội dung này, bây giờ bạn có thể triển khai thuật toán chuyển kiểu. Thực hiện điều này bằng cách tính toán sai số bình phương trung bình cho đầu ra hình ảnh của bạn so với từng mục tiêu, sau đó lấy tổng có trọng số của những tổn thất này.
Đặt các giá trị mục tiêu nội dung và phong cách của bạn:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
Xác định một tf.Variable để chứa hình ảnh cần tối ưu hóa. Để thực hiện việc này nhanh chóng, hãy khởi tạo nó bằng hình ảnh nội dung ( tf.Variable phải có cùng hình dạng với hình ảnh nội dung):
image = tf.Variable(content_image)
Vì đây là hình ảnh nổi, hãy xác định một hàm để giữ các giá trị pixel trong khoảng từ 0 đến 1:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
Tạo một trình tối ưu hóa. Bài báo đề xuất LBFGS, nhưng Adam cũng hoạt động ổn:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
Để tối ưu hóa điều này, hãy sử dụng kết hợp có trọng số của hai tổn thất để có được tổng tổn thất:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
Sử dụng tf.GradientTape để cập nhật hình ảnh.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Bây giờ hãy chạy một vài bước để kiểm tra:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

Vì nó đang hoạt động, hãy thực hiện tối ưu hóa lâu hơn:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
Tổng số biến thể mất mát
Một nhược điểm của việc triển khai cơ bản này là nó tạo ra rất nhiều tạo tác tần số cao. Giảm những điều này bằng cách sử dụng thuật ngữ chính quy rõ ràng trên các thành phần tần số cao của hình ảnh. Trong chuyển kiểu, điều này thường được gọi là tổng tổn thất biến thể :
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
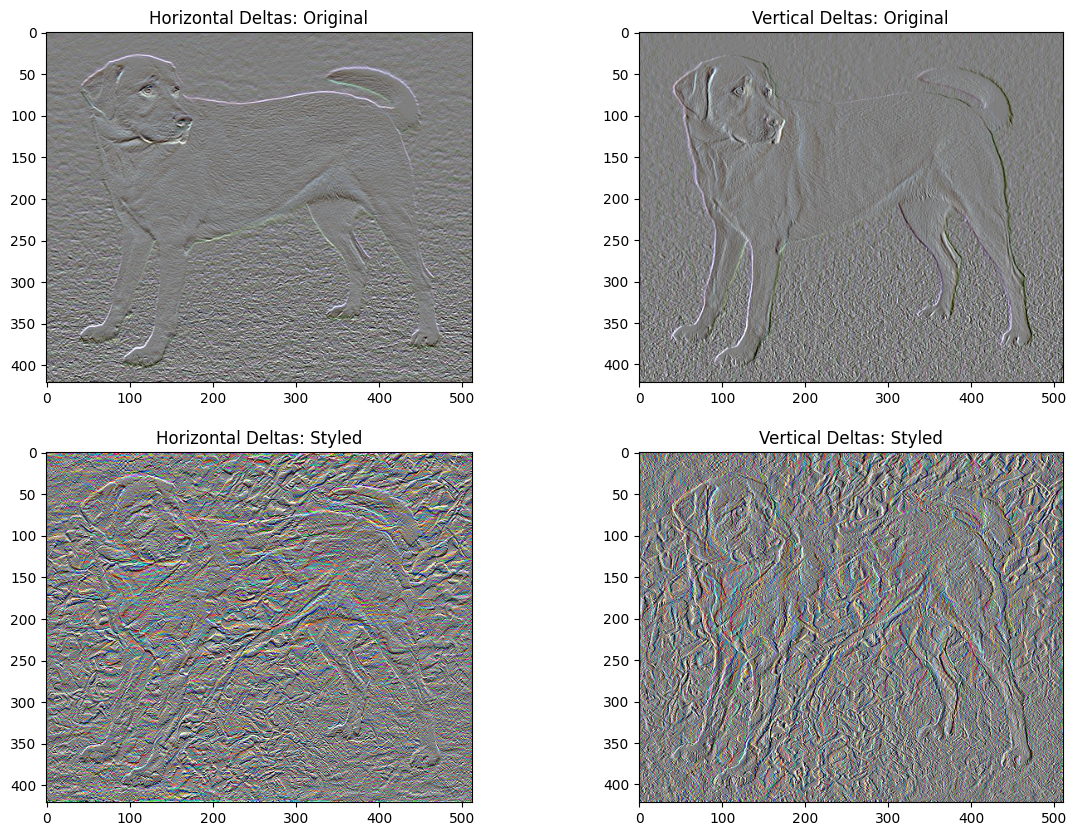
Điều này cho thấy các thành phần tần số cao đã tăng lên như thế nào.
Ngoài ra, thành phần tần số cao này về cơ bản là một bộ dò cạnh. Bạn có thể nhận được đầu ra tương tự từ bộ dò cạnh Sobel, ví dụ:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
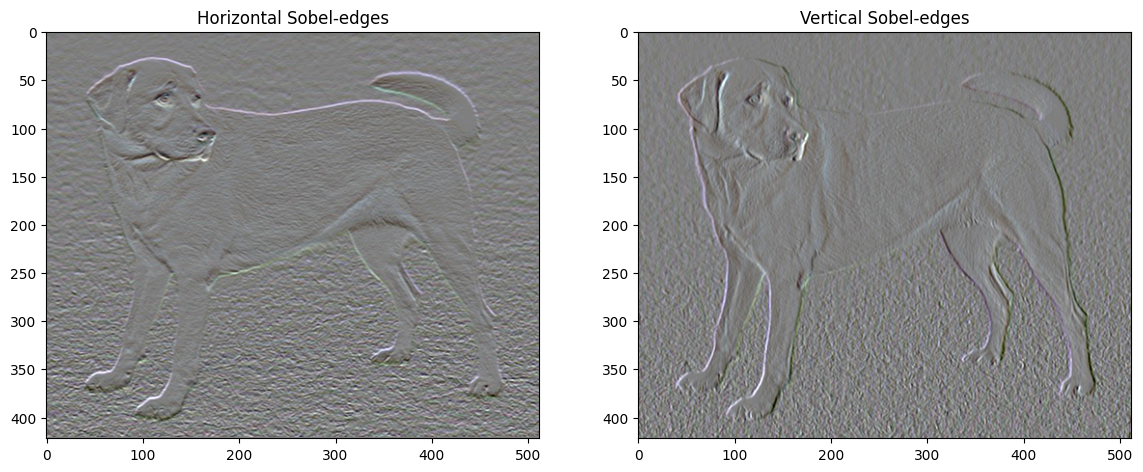
Sự mất mát chính quy liên quan đến điều này là tổng bình phương của các giá trị:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
Điều đó đã chứng minh những gì nó làm. Nhưng không cần phải tự mình triển khai, TensorFlow bao gồm một triển khai tiêu chuẩn:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
Chạy lại tối ưu hóa
Chọn trọng số cho total_variation_loss :
total_variation_weight=30
Bây giờ hãy đưa nó vào hàm train_step :
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Khởi động lại biến tối ưu hóa:
image = tf.Variable(content_image)
Và chạy tối ưu hóa:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
Cuối cùng, lưu kết quả:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
Tìm hiểu thêm
Hướng dẫn này trình bày thuật toán chuyển kiểu ban đầu. Để có ứng dụng chuyển kiểu đơn giản, hãy xem hướng dẫn này để tìm hiểu thêm về cách sử dụng mô hình chuyển kiểu hình ảnh tùy ý từ TensorFlow Hub .