
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este tutorial mostra como classificar imagens de flores. Ele cria um classificador de imagem usando um modelo tf.keras.Sequential e carrega dados usando tf.keras.utils.image_dataset_from_directory . Você ganhará experiência prática com os seguintes conceitos:
- Carregar com eficiência um conjunto de dados fora do disco.
- Identificar overfitting e aplicar técnicas para mitigá-lo, incluindo aumento e abandono de dados.
Este tutorial segue um fluxo de trabalho básico de aprendizado de máquina:
- Examinar e entender os dados
- Construir um pipeline de entrada
- Construir o modelo
- Treine o modelo
- Teste o modelo
- Melhore o modelo e repita o processo
Importar TensorFlow e outras bibliotecas
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
Baixe e explore o conjunto de dados
Este tutorial usa um conjunto de dados de cerca de 3.700 fotos de flores. O conjunto de dados contém cinco subdiretórios, um por classe:
flower_photo/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
Após o download, agora você deve ter uma cópia do conjunto de dados disponível. Há 3.670 imagens no total:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Aqui estão algumas rosas:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

PIL.Image.open(str(roses[1]))

E algumas tulipas:
tulips = list(data_dir.glob('tulips/*'))
PIL.Image.open(str(tulips[0]))

PIL.Image.open(str(tulips[1]))
Carregar dados usando um utilitário Keras
Vamos carregar essas imagens do disco usando o útil utilitário tf.keras.utils.image_dataset_from_directory . Isso levará você de um diretório de imagens no disco para um tf.data.Dataset em apenas algumas linhas de código. Se desejar, você também pode escrever seu próprio código de carregamento de dados do zero visitando o tutorial Carregar e pré-processar imagens .
Criar um conjunto de dados
Defina alguns parâmetros para o carregador:
batch_size = 32
img_height = 180
img_width = 180
É uma boa prática usar uma divisão de validação ao desenvolver seu modelo. Vamos usar 80% das imagens para treinamento e 20% para validação.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Você pode encontrar os nomes das classes no atributo class_names nesses conjuntos de dados. Estes correspondem aos nomes dos diretórios em ordem alfabética.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
Visualize os dados
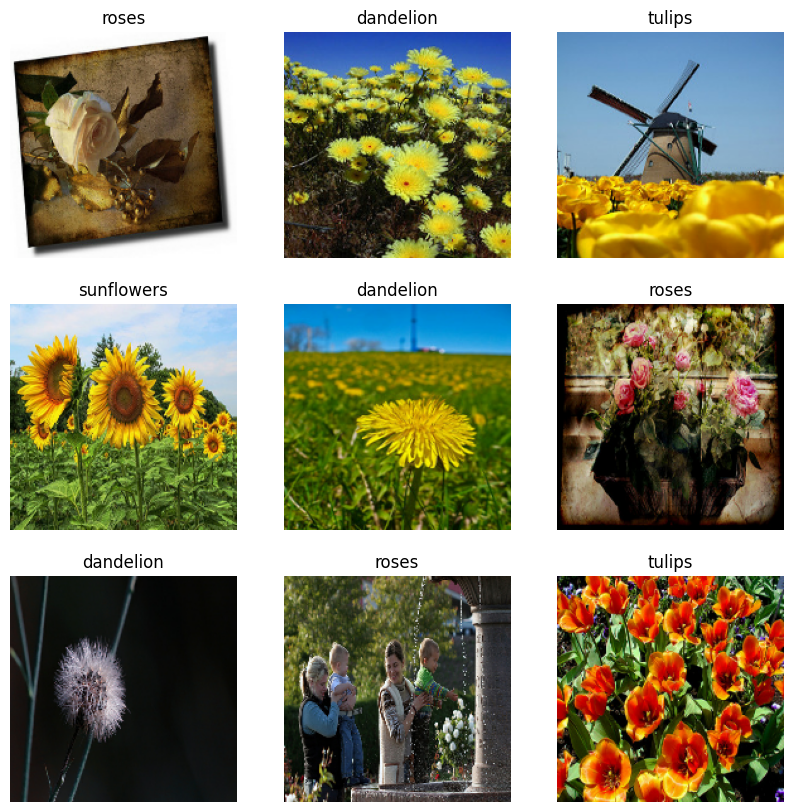
Aqui estão as primeiras nove imagens do conjunto de dados de treinamento:
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
Você treinará um modelo usando esses conjuntos de dados passando-os para Model.fit em um momento. Se desejar, você também pode iterar manualmente no conjunto de dados e recuperar lotes de imagens:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
O image_batch é um tensor da forma (32, 180, 180, 3) . Este é um lote de 32 imagens de formato 180x180x3 (a última dimensão refere-se aos canais de cores RGB). O label_batch é um tensor da forma (32,) , estes são os rótulos correspondentes às 32 imagens.
Você pode chamar .numpy() nos tensores image_batch e labels_batch para convertê-los em um numpy.ndarray .
Configurar o conjunto de dados para desempenho
Vamos nos certificar de usar a pré-busca em buffer para que você possa produzir dados do disco sem que a E/S se torne um bloqueio. Estes são dois métodos importantes que você deve usar ao carregar dados:
-
Dataset.cachemantém as imagens na memória depois de serem carregadas fora do disco durante a primeira época. Isso garantirá que o conjunto de dados não se torne um gargalo ao treinar seu modelo. Se seu conjunto de dados for muito grande para caber na memória, você também poderá usar esse método para criar um cache em disco de alto desempenho. -
Dataset.prefetchsobrepõe o pré-processamento de dados e a execução do modelo durante o treinamento.
Os leitores interessados podem aprender mais sobre os dois métodos, bem como sobre como armazenar dados em cache no disco na seção Pré -busca do guia Melhor desempenho com a API tf.data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Padronize os dados
Os valores do canal RGB estão na faixa [0, 255] . Isso não é ideal para uma rede neural; em geral, você deve procurar tornar seus valores de entrada pequenos.
Aqui, você padronizará os valores para estarem no intervalo [0, 1] usando tf.keras.layers.Rescaling :
normalization_layer = layers.Rescaling(1./255)
Existem duas maneiras de usar essa camada. Você pode aplicá-lo ao conjunto de dados chamando Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 1.0
Ou você pode incluir a camada dentro de sua definição de modelo, o que pode simplificar a implantação. Vamos usar a segunda abordagem aqui.
Crie o modelo
O modelo Sequencial consiste em três blocos de convolução ( tf.keras.layers.Conv2D ) com uma camada de agrupamento máximo ( tf.keras.layers.MaxPooling2D ) em cada um deles. Há uma camada totalmente conectada ( tf.keras.layers.Dense ) com 128 unidades em cima dela que é ativada por uma função de ativação ReLU ( 'relu' ). Este modelo não foi ajustado para alta precisão - o objetivo deste tutorial é mostrar uma abordagem padrão.
num_classes = len(class_names)
model = Sequential([
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Compilar o modelo
Para este tutorial, escolha o otimizador tf.keras.optimizers.Adam e a função de perda tf.keras.losses.SparseCategoricalCrossentropy . Para visualizar a precisão do treinamento e da validação para cada época de treinamento, passe o argumento de metrics para Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Resumo do modelo
Visualize todas as camadas da rede usando o método Model.summary do modelo:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_1 (Rescaling) (None, 180, 180, 3) 0
conv2d (Conv2D) (None, 180, 180, 16) 448
max_pooling2d (MaxPooling2D (None, 90, 90, 16) 0
)
conv2d_1 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_1 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_2 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_2 (MaxPooling (None, 22, 22, 64) 0
2D)
flatten (Flatten) (None, 30976) 0
dense (Dense) (None, 128) 3965056
dense_1 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
Treine o modelo
epochs=10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/10 92/92 [==============================] - 3s 16ms/step - loss: 1.2769 - accuracy: 0.4489 - val_loss: 1.0457 - val_accuracy: 0.5804 Epoch 2/10 92/92 [==============================] - 1s 11ms/step - loss: 0.9386 - accuracy: 0.6328 - val_loss: 0.9665 - val_accuracy: 0.6158 Epoch 3/10 92/92 [==============================] - 1s 11ms/step - loss: 0.7390 - accuracy: 0.7200 - val_loss: 0.8768 - val_accuracy: 0.6540 Epoch 4/10 92/92 [==============================] - 1s 11ms/step - loss: 0.5649 - accuracy: 0.7963 - val_loss: 0.9258 - val_accuracy: 0.6540 Epoch 5/10 92/92 [==============================] - 1s 11ms/step - loss: 0.3662 - accuracy: 0.8733 - val_loss: 1.1734 - val_accuracy: 0.6267 Epoch 6/10 92/92 [==============================] - 1s 11ms/step - loss: 0.2169 - accuracy: 0.9343 - val_loss: 1.3728 - val_accuracy: 0.6499 Epoch 7/10 92/92 [==============================] - 1s 11ms/step - loss: 0.1191 - accuracy: 0.9629 - val_loss: 1.3791 - val_accuracy: 0.6471 Epoch 8/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0497 - accuracy: 0.9871 - val_loss: 1.8002 - val_accuracy: 0.6390 Epoch 9/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0372 - accuracy: 0.9922 - val_loss: 1.8545 - val_accuracy: 0.6390 Epoch 10/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0715 - accuracy: 0.9813 - val_loss: 2.0656 - val_accuracy: 0.6049
Visualize os resultados do treinamento
Crie gráficos de perda e precisão nos conjuntos de treinamento e validação:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
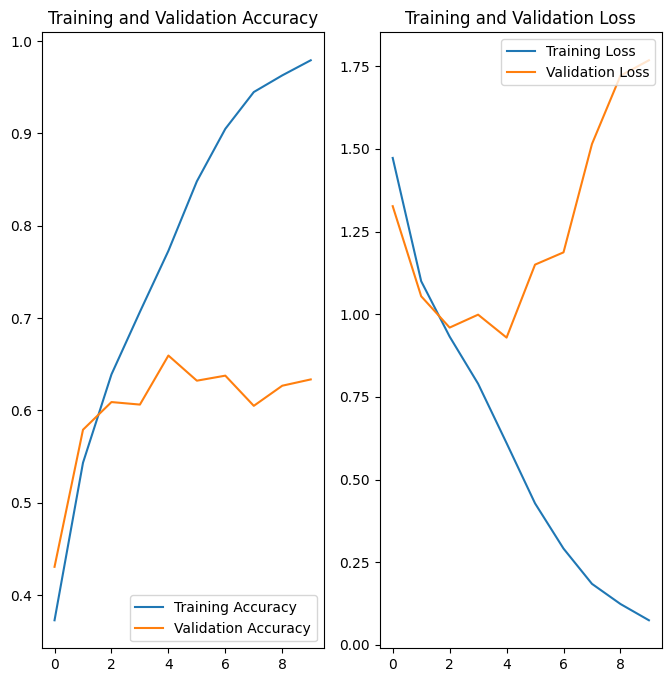
Os gráficos mostram que a precisão do treinamento e a precisão da validação estão com grandes margens, e o modelo alcançou apenas cerca de 60% de precisão no conjunto de validação.
Vamos inspecionar o que deu errado e tentar aumentar o desempenho geral do modelo.
Sobreajuste
Nos gráficos acima, a precisão do treinamento está aumentando linearmente ao longo do tempo, enquanto a precisão da validação fica em torno de 60% no processo de treinamento. Além disso, a diferença na precisão entre a precisão do treinamento e da validação é perceptível - um sinal de overfitting .
Quando há um pequeno número de exemplos de treinamento, o modelo às vezes aprende com ruídos ou detalhes indesejados de exemplos de treinamento - a ponto de impactar negativamente o desempenho do modelo em novos exemplos. Esse fenômeno é conhecido como overfitting. Isso significa que o modelo terá dificuldade em generalizar em um novo conjunto de dados.
Existem várias maneiras de combater o overfitting no processo de treinamento. Neste tutorial, você usará o aumento de dados e adicionará Dropout ao seu modelo.
Aumento de dados
O overfitting geralmente ocorre quando há um pequeno número de exemplos de treinamento. O aumento de dados adota a abordagem de gerar dados de treinamento adicionais de seus exemplos existentes, aumentando-os usando transformações aleatórias que produzem imagens de aparência crível. Isso ajuda a expor o modelo a mais aspectos dos dados e a generalizar melhor.
Você implementará o aumento de dados usando as seguintes camadas de pré-processamento Keras: tf.keras.layers.RandomFlip , tf.keras.layers.RandomRotation e tf.keras.layers.RandomZoom . Eles podem ser incluídos dentro do seu modelo como outras camadas e executados na GPU.
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.1),
]
)
Vamos visualizar alguns exemplos aumentados aplicando o aumento de dados à mesma imagem várias vezes:
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")

Você usará o aumento de dados para treinar um modelo em um momento.
Cair fora
Outra técnica para reduzir o overfitting é introduzir a regularização de dropout na rede.
Quando você aplica dropout a uma camada, ela descarta aleatoriamente (definindo a ativação como zero) um número de unidades de saída da camada durante o processo de treinamento. Dropout recebe um número fracionário como valor de entrada, na forma de 0,1, 0,2, 0,4, etc. Isso significa descartar 10%, 20% ou 40% das unidades de saída aleatoriamente da camada aplicada.
Vamos criar uma nova rede neural com tf.keras.layers.Dropout antes de treiná-la usando as imagens aumentadas:
model = Sequential([
data_augmentation,
layers.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Compilar e treinar o modelo
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential_1 (Sequential) (None, 180, 180, 3) 0
rescaling_2 (Rescaling) (None, 180, 180, 3) 0
conv2d_3 (Conv2D) (None, 180, 180, 16) 448
max_pooling2d_3 (MaxPooling (None, 90, 90, 16) 0
2D)
conv2d_4 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_4 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_5 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_5 (MaxPooling (None, 22, 22, 64) 0
2D)
dropout (Dropout) (None, 22, 22, 64) 0
flatten_1 (Flatten) (None, 30976) 0
dense_2 (Dense) (None, 128) 3965056
dense_3 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
epochs = 15
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/15 92/92 [==============================] - 2s 14ms/step - loss: 1.3840 - accuracy: 0.3999 - val_loss: 1.0967 - val_accuracy: 0.5518 Epoch 2/15 92/92 [==============================] - 1s 12ms/step - loss: 1.1152 - accuracy: 0.5395 - val_loss: 1.1123 - val_accuracy: 0.5545 Epoch 3/15 92/92 [==============================] - 1s 12ms/step - loss: 1.0049 - accuracy: 0.6052 - val_loss: 0.9544 - val_accuracy: 0.6253 Epoch 4/15 92/92 [==============================] - 1s 12ms/step - loss: 0.9452 - accuracy: 0.6257 - val_loss: 0.9681 - val_accuracy: 0.6213 Epoch 5/15 92/92 [==============================] - 1s 12ms/step - loss: 0.8804 - accuracy: 0.6591 - val_loss: 0.8450 - val_accuracy: 0.6798 Epoch 6/15 92/92 [==============================] - 1s 12ms/step - loss: 0.8001 - accuracy: 0.6945 - val_loss: 0.8715 - val_accuracy: 0.6594 Epoch 7/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7736 - accuracy: 0.6965 - val_loss: 0.8059 - val_accuracy: 0.6935 Epoch 8/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7477 - accuracy: 0.7078 - val_loss: 0.8292 - val_accuracy: 0.6812 Epoch 9/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7053 - accuracy: 0.7251 - val_loss: 0.7743 - val_accuracy: 0.6989 Epoch 10/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6884 - accuracy: 0.7340 - val_loss: 0.7867 - val_accuracy: 0.6907 Epoch 11/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6536 - accuracy: 0.7469 - val_loss: 0.7732 - val_accuracy: 0.6785 Epoch 12/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6456 - accuracy: 0.7500 - val_loss: 0.7801 - val_accuracy: 0.6907 Epoch 13/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5941 - accuracy: 0.7735 - val_loss: 0.7185 - val_accuracy: 0.7330 Epoch 14/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5824 - accuracy: 0.7735 - val_loss: 0.7282 - val_accuracy: 0.7357 Epoch 15/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5771 - accuracy: 0.7851 - val_loss: 0.7308 - val_accuracy: 0.7343
Visualize os resultados do treinamento
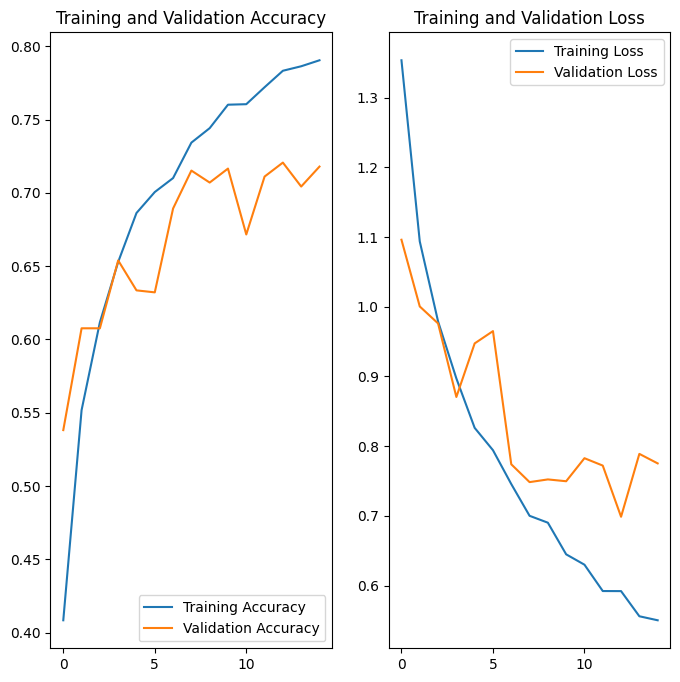
Depois de aplicar o aumento de dados e tf.keras.layers.Dropout , há menos overfitting do que antes, e a precisão do treinamento e da validação está mais alinhada:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
Prever novos dados
Por fim, vamos usar nosso modelo para classificar uma imagem que não foi incluída nos conjuntos de treinamento ou validação.
sunflower_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg"
sunflower_path = tf.keras.utils.get_file('Red_sunflower', origin=sunflower_url)
img = tf.keras.utils.load_img(
sunflower_path, target_size=(img_height, img_width)
)
img_array = tf.keras.utils.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batch
predictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])
print(
"This image most likely belongs to {} with a {:.2f} percent confidence."
.format(class_names[np.argmax(score)], 100 * np.max(score))
)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg 122880/117948 [===============================] - 0s 0us/step 131072/117948 [=================================] - 0s 0us/step This image most likely belongs to sunflowers with a 89.13 percent confidence.