
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini menunjukkan bagaimana mengklasifikasikan gambar bunga. Itu membuat pengklasifikasi gambar menggunakan model tf.keras.Sequential , dan memuat data menggunakan tf.keras.utils.image_dataset_from_directory . Anda akan mendapatkan pengalaman praktis dengan konsep-konsep berikut:
- Memuat kumpulan data dari disk secara efisien.
- Mengidentifikasi overfitting dan menerapkan teknik untuk menguranginya, termasuk augmentasi data dan putus sekolah.
Tutorial ini mengikuti alur kerja machine learning dasar:
- Memeriksa dan memahami data
- Bangun saluran input
- Bangun modelnya
- Latih modelnya
- Uji modelnya
- Tingkatkan model dan ulangi prosesnya
Impor TensorFlow dan perpustakaan lainnya
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
Unduh dan jelajahi kumpulan data
Tutorial ini menggunakan dataset sekitar 3.700 foto bunga. Dataset berisi lima sub-direktori, satu per kelas:
flower_photo/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
Setelah mengunduh, Anda sekarang harus memiliki salinan kumpulan data yang tersedia. Ada 3.670 total gambar:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Berikut beberapa bunga mawar:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

PIL.Image.open(str(roses[1]))

Dan beberapa tulip:
tulips = list(data_dir.glob('tulips/*'))
PIL.Image.open(str(tulips[0]))

PIL.Image.open(str(tulips[1]))
Muat data menggunakan utilitas Keras
Mari muat gambar-gambar ini dari disk menggunakan utilitas tf.keras.utils.image_dataset_from_directory yang bermanfaat. Ini akan membawa Anda dari direktori gambar pada disk ke tf.data.Dataset hanya dalam beberapa baris kode. Jika Anda suka, Anda juga dapat menulis kode pemuatan data Anda sendiri dari awal dengan mengunjungi tutorial Memuat dan memproses gambar .
Buat kumpulan data
Tentukan beberapa parameter untuk loader:
batch_size = 32
img_height = 180
img_width = 180
Ini adalah praktik yang baik untuk menggunakan pemisahan validasi saat mengembangkan model Anda. Mari kita gunakan 80% dari gambar untuk pelatihan, dan 20% untuk validasi.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Anda dapat menemukan nama kelas di atribut class_names pada kumpulan data ini. Ini sesuai dengan nama direktori dalam urutan abjad.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
Visualisasikan datanya
Berikut adalah sembilan gambar pertama dari dataset pelatihan:
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
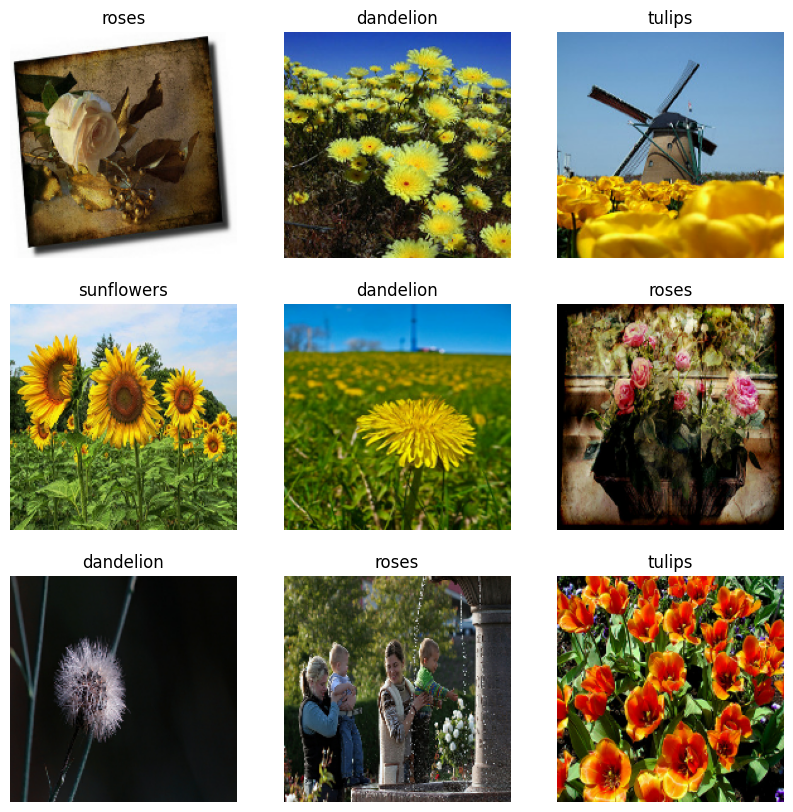
Anda akan melatih model menggunakan kumpulan data ini dengan meneruskannya ke Model.fit sebentar lagi. Jika Anda suka, Anda juga dapat secara manual mengulangi kumpulan data dan mengambil kumpulan gambar:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch adalah tensor dari bentuk (32, 180, 180, 3) . Ini adalah kumpulan 32 gambar dengan bentuk 180x180x3 (dimensi terakhir mengacu pada saluran warna RGB). label_batch adalah tensor dari bentuk (32,) , ini adalah label yang sesuai dengan 32 gambar.
Anda dapat memanggil .numpy() pada tensor image_batch dan labels_batch untuk mengonversinya menjadi numpy.ndarray .
Konfigurasikan kumpulan data untuk kinerja
Mari pastikan untuk menggunakan buffered prefetching sehingga Anda dapat menghasilkan data dari disk tanpa I/O menjadi pemblokiran. Ini adalah dua metode penting yang harus Anda gunakan saat memuat data:
-
Dataset.cachemenyimpan gambar dalam memori setelah mereka dimuat dari disk selama epoch pertama. Ini akan memastikan kumpulan data tidak menjadi hambatan saat melatih model Anda. Jika kumpulan data Anda terlalu besar untuk dimasukkan ke dalam memori, Anda juga dapat menggunakan metode ini untuk membuat cache di disk yang berkinerja baik. -
Dataset.prefetchtumpang tindih dengan prapemrosesan data dan eksekusi model saat pelatihan.
Pembaca yang tertarik dapat mempelajari lebih lanjut tentang kedua metode tersebut, serta cara menyimpan data ke disk di bagian Prefetching pada Performa yang lebih baik dengan panduan API tf.data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Standarisasi data
Nilai saluran RGB berada dalam kisaran [0, 255] . Ini tidak ideal untuk jaringan saraf; secara umum Anda harus berusaha membuat nilai input Anda kecil.
Di sini, Anda akan menstandardisasi nilai agar berada dalam kisaran [0, 1] dengan menggunakan tf.keras.layers.Rescaling :
normalization_layer = layers.Rescaling(1./255)
Ada dua cara untuk menggunakan lapisan ini. Anda dapat menerapkannya ke dataset dengan memanggil Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 1.0
Atau, Anda dapat menyertakan lapisan di dalam definisi model Anda, yang dapat menyederhanakan penerapan. Mari kita gunakan pendekatan kedua di sini.
Buat modelnya
Model Sequential terdiri dari tiga blok konvolusi ( tf.keras.layers.Conv2D ) dengan lapisan pooling maks ( tf.keras.layers.MaxPooling2D ) di masing-masing blok. Ada lapisan yang sepenuhnya terhubung ( tf.keras.layers.Dense ) dengan 128 unit di atasnya yang diaktifkan oleh fungsi aktivasi ReLU ( 'relu' ). Model ini belum disetel untuk akurasi tinggi—tujuan dari tutorial ini adalah untuk menunjukkan pendekatan standar.
num_classes = len(class_names)
model = Sequential([
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Kompilasi modelnya
Untuk tutorial ini, pilih tf.keras.optimizers.Adam optimizer dan tf.keras.losses.SparseCategoricalCrossentropy loss function. Untuk melihat akurasi pelatihan dan validasi untuk setiap periode pelatihan, teruskan argumen metrics ke Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Ringkasan model
Lihat semua lapisan jaringan menggunakan metode Model.summary model:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_1 (Rescaling) (None, 180, 180, 3) 0
conv2d (Conv2D) (None, 180, 180, 16) 448
max_pooling2d (MaxPooling2D (None, 90, 90, 16) 0
)
conv2d_1 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_1 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_2 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_2 (MaxPooling (None, 22, 22, 64) 0
2D)
flatten (Flatten) (None, 30976) 0
dense (Dense) (None, 128) 3965056
dense_1 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
Latih modelnya
epochs=10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/10 92/92 [==============================] - 3s 16ms/step - loss: 1.2769 - accuracy: 0.4489 - val_loss: 1.0457 - val_accuracy: 0.5804 Epoch 2/10 92/92 [==============================] - 1s 11ms/step - loss: 0.9386 - accuracy: 0.6328 - val_loss: 0.9665 - val_accuracy: 0.6158 Epoch 3/10 92/92 [==============================] - 1s 11ms/step - loss: 0.7390 - accuracy: 0.7200 - val_loss: 0.8768 - val_accuracy: 0.6540 Epoch 4/10 92/92 [==============================] - 1s 11ms/step - loss: 0.5649 - accuracy: 0.7963 - val_loss: 0.9258 - val_accuracy: 0.6540 Epoch 5/10 92/92 [==============================] - 1s 11ms/step - loss: 0.3662 - accuracy: 0.8733 - val_loss: 1.1734 - val_accuracy: 0.6267 Epoch 6/10 92/92 [==============================] - 1s 11ms/step - loss: 0.2169 - accuracy: 0.9343 - val_loss: 1.3728 - val_accuracy: 0.6499 Epoch 7/10 92/92 [==============================] - 1s 11ms/step - loss: 0.1191 - accuracy: 0.9629 - val_loss: 1.3791 - val_accuracy: 0.6471 Epoch 8/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0497 - accuracy: 0.9871 - val_loss: 1.8002 - val_accuracy: 0.6390 Epoch 9/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0372 - accuracy: 0.9922 - val_loss: 1.8545 - val_accuracy: 0.6390 Epoch 10/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0715 - accuracy: 0.9813 - val_loss: 2.0656 - val_accuracy: 0.6049
Visualisasikan hasil pelatihan
Buat plot kehilangan dan akurasi pada set pelatihan dan validasi:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
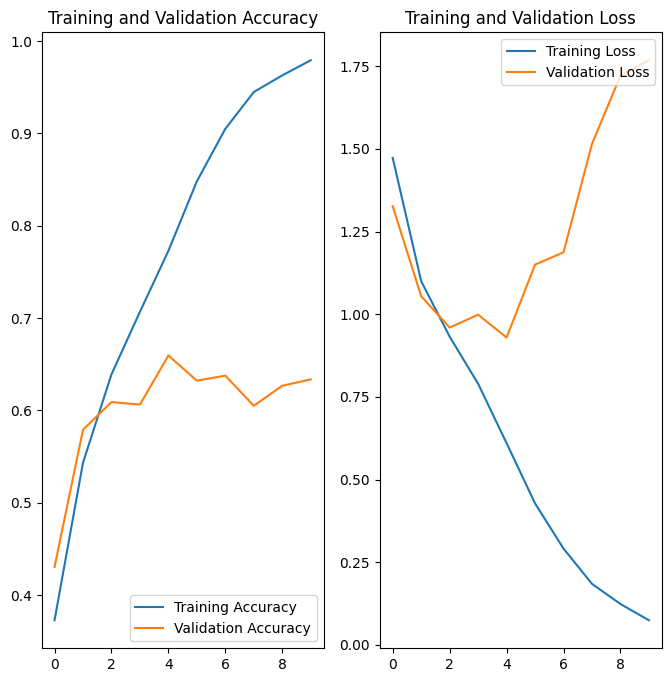
Plot menunjukkan bahwa akurasi pelatihan dan akurasi validasi berbeda jauh, dan model hanya mencapai akurasi sekitar 60% pada set validasi.
Mari kita periksa apa yang salah dan coba tingkatkan kinerja model secara keseluruhan.
Overfitting
Dalam plot di atas, akurasi pelatihan meningkat secara linier dari waktu ke waktu, sedangkan akurasi validasi terhenti sekitar 60% dalam proses pelatihan. Selain itu, perbedaan akurasi antara akurasi pelatihan dan validasi terlihat—tanda overfitting .
Ketika ada sejumlah kecil contoh pelatihan, model terkadang belajar dari noise atau detail yang tidak diinginkan dari contoh pelatihan—sejauh hal itu berdampak negatif pada kinerja model pada contoh baru. Fenomena ini dikenal sebagai overfitting. Ini berarti bahwa model akan mengalami kesulitan untuk melakukan generalisasi pada dataset baru.
Ada beberapa cara untuk melawan overfitting dalam proses pelatihan. Dalam tutorial ini, Anda akan menggunakan augmentasi data dan menambahkan Dropout ke model Anda.
augmentasi data
Overfitting umumnya terjadi ketika ada sejumlah kecil contoh pelatihan. Augmentasi data mengambil pendekatan untuk menghasilkan data pelatihan tambahan dari contoh yang ada dengan menambahkannya menggunakan transformasi acak yang menghasilkan gambar yang tampak dapat dipercaya. Ini membantu mengekspos model ke lebih banyak aspek data dan menggeneralisasi lebih baik.
Anda akan menerapkan augmentasi data menggunakan lapisan prapemrosesan Keras berikut: tf.keras.layers.RandomFlip , tf.keras.layers.RandomRotation , dan tf.keras.layers.RandomZoom . Ini dapat dimasukkan ke dalam model Anda seperti lapisan lain, dan berjalan di GPU.
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.1),
]
)
Mari kita visualisasikan seperti apa beberapa contoh augmented dengan menerapkan augmentasi data ke gambar yang sama beberapa kali:
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")

Anda akan menggunakan augmentasi data untuk melatih model dalam sekejap.
Keluar
Teknik lain untuk mengurangi overfitting adalah dengan memperkenalkan regularisasi putus sekolah ke jaringan.
Ketika Anda menerapkan dropout ke lapisan, secara acak menjatuhkan (dengan mengatur aktivasi ke nol) sejumlah unit output dari lapisan selama proses pelatihan. Dropout mengambil angka pecahan sebagai nilai inputnya, dalam bentuk seperti 0.1, 0.2, 0.4, dll. Ini berarti drop out 10%, 20% atau 40% dari unit output secara acak dari lapisan yang diterapkan.
Mari buat jaringan saraf baru dengan tf.keras.layers.Dropout sebelum melatihnya menggunakan gambar yang ditambah:
model = Sequential([
data_augmentation,
layers.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Kompilasi dan latih modelnya
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential_1 (Sequential) (None, 180, 180, 3) 0
rescaling_2 (Rescaling) (None, 180, 180, 3) 0
conv2d_3 (Conv2D) (None, 180, 180, 16) 448
max_pooling2d_3 (MaxPooling (None, 90, 90, 16) 0
2D)
conv2d_4 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_4 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_5 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_5 (MaxPooling (None, 22, 22, 64) 0
2D)
dropout (Dropout) (None, 22, 22, 64) 0
flatten_1 (Flatten) (None, 30976) 0
dense_2 (Dense) (None, 128) 3965056
dense_3 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
epochs = 15
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/15 92/92 [==============================] - 2s 14ms/step - loss: 1.3840 - accuracy: 0.3999 - val_loss: 1.0967 - val_accuracy: 0.5518 Epoch 2/15 92/92 [==============================] - 1s 12ms/step - loss: 1.1152 - accuracy: 0.5395 - val_loss: 1.1123 - val_accuracy: 0.5545 Epoch 3/15 92/92 [==============================] - 1s 12ms/step - loss: 1.0049 - accuracy: 0.6052 - val_loss: 0.9544 - val_accuracy: 0.6253 Epoch 4/15 92/92 [==============================] - 1s 12ms/step - loss: 0.9452 - accuracy: 0.6257 - val_loss: 0.9681 - val_accuracy: 0.6213 Epoch 5/15 92/92 [==============================] - 1s 12ms/step - loss: 0.8804 - accuracy: 0.6591 - val_loss: 0.8450 - val_accuracy: 0.6798 Epoch 6/15 92/92 [==============================] - 1s 12ms/step - loss: 0.8001 - accuracy: 0.6945 - val_loss: 0.8715 - val_accuracy: 0.6594 Epoch 7/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7736 - accuracy: 0.6965 - val_loss: 0.8059 - val_accuracy: 0.6935 Epoch 8/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7477 - accuracy: 0.7078 - val_loss: 0.8292 - val_accuracy: 0.6812 Epoch 9/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7053 - accuracy: 0.7251 - val_loss: 0.7743 - val_accuracy: 0.6989 Epoch 10/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6884 - accuracy: 0.7340 - val_loss: 0.7867 - val_accuracy: 0.6907 Epoch 11/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6536 - accuracy: 0.7469 - val_loss: 0.7732 - val_accuracy: 0.6785 Epoch 12/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6456 - accuracy: 0.7500 - val_loss: 0.7801 - val_accuracy: 0.6907 Epoch 13/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5941 - accuracy: 0.7735 - val_loss: 0.7185 - val_accuracy: 0.7330 Epoch 14/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5824 - accuracy: 0.7735 - val_loss: 0.7282 - val_accuracy: 0.7357 Epoch 15/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5771 - accuracy: 0.7851 - val_loss: 0.7308 - val_accuracy: 0.7343
Visualisasikan hasil pelatihan
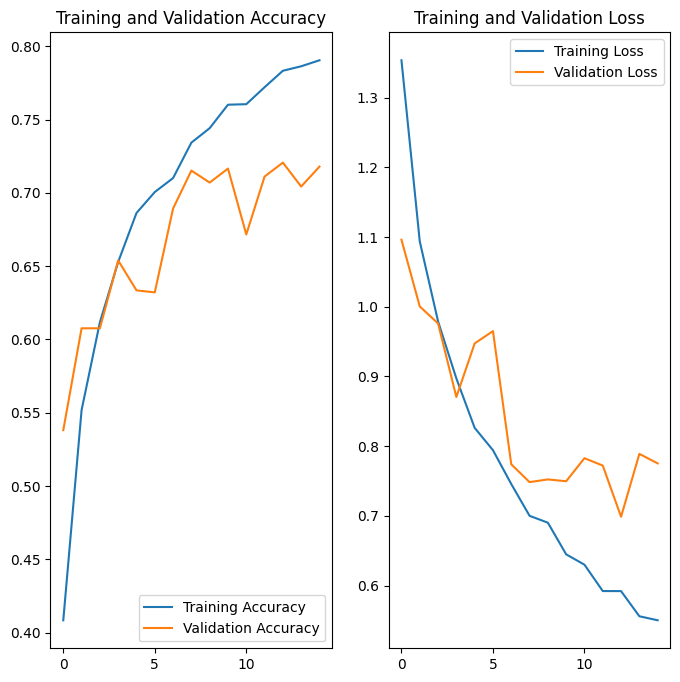
Setelah menerapkan augmentasi data dan tf.keras.layers.Dropout , overfitting lebih sedikit daripada sebelumnya, dan akurasi pelatihan dan validasi lebih selaras:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
Prediksi pada data baru
Terakhir, mari gunakan model kita untuk mengklasifikasikan gambar yang tidak disertakan dalam set pelatihan atau validasi.
sunflower_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg"
sunflower_path = tf.keras.utils.get_file('Red_sunflower', origin=sunflower_url)
img = tf.keras.utils.load_img(
sunflower_path, target_size=(img_height, img_width)
)
img_array = tf.keras.utils.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batch
predictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])
print(
"This image most likely belongs to {} with a {:.2f} percent confidence."
.format(class_names[np.argmax(score)], 100 * np.max(score))
)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg 122880/117948 [===============================] - 0s 0us/step 131072/117948 [=================================] - 0s 0us/step This image most likely belongs to sunflowers with a 89.13 percent confidence.