
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu öğretici, çiçek görüntülerinin nasıl sınıflandırılacağını gösterir. Bir tf.keras.Sequential modeli kullanarak bir görüntü sınıflandırıcı oluşturur ve tf.keras.utils.image_dataset_from_directory kullanarak verileri yükler. Aşağıdaki kavramlarla pratik deneyim kazanacaksınız:
- Bir veri kümesini diskten verimli bir şekilde yükleme.
- Veri artırma ve bırakma da dahil olmak üzere, fazla takmayı belirleme ve bunu hafifletmek için teknikleri uygulama.
Bu eğitici, temel bir makine öğrenimi iş akışını takip eder:
- Verileri inceleyin ve anlayın
- Bir giriş ardışık düzeni oluşturun
- Modeli oluşturun
- Modeli eğit
- Modeli test edin
- Modeli geliştirin ve işlemi tekrarlayın
TensorFlow ve diğer kitaplıkları içe aktarın
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
Veri kümesini indirin ve keşfedin
Bu öğretici, yaklaşık 3.700 çiçek fotoğrafından oluşan bir veri kümesi kullanır. Veri kümesi, sınıf başına bir tane olmak üzere beş alt dizin içerir:
flower_photo/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
İndirdikten sonra, artık mevcut veri kümesinin bir kopyasına sahip olmalısınız. Toplam 3.670 resim var:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
İşte bazı güller:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

PIL.Image.open(str(roses[1]))

Ve bazı laleler:
tulips = list(data_dir.glob('tulips/*'))
PIL.Image.open(str(tulips[0]))

PIL.Image.open(str(tulips[1]))
Keras yardımcı programını kullanarak verileri yükleyin
Yardımcı tf.keras.utils.image_dataset_from_directory yardımcı programını kullanarak bu görüntüleri diskten yükleyelim. Bu sizi diskteki bir görüntü dizininden sadece birkaç satır kodla bir tf.data.Dataset . İsterseniz, Görüntüleri yükleme ve önişleme eğitimini ziyaret ederek kendi veri yükleme kodunuzu sıfırdan da yazabilirsiniz.
Veri kümesi oluşturun
Yükleyici için bazı parametreleri tanımlayın:
batch_size = 32
img_height = 180
img_width = 180
Modelinizi geliştirirken bir doğrulama bölmesi kullanmak iyi bir uygulamadır. Görsellerin %80'ini eğitim için ve %20'sini doğrulama için kullanalım.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.yer tutucu12 l10n-yer
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Sınıf adlarını bu veri kümelerinde class_names özniteliğinde bulabilirsiniz. Bunlar alfabetik sırayla dizin adlarına karşılık gelir.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
Verileri görselleştirin
İşte eğitim veri setinden ilk dokuz görüntü:
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
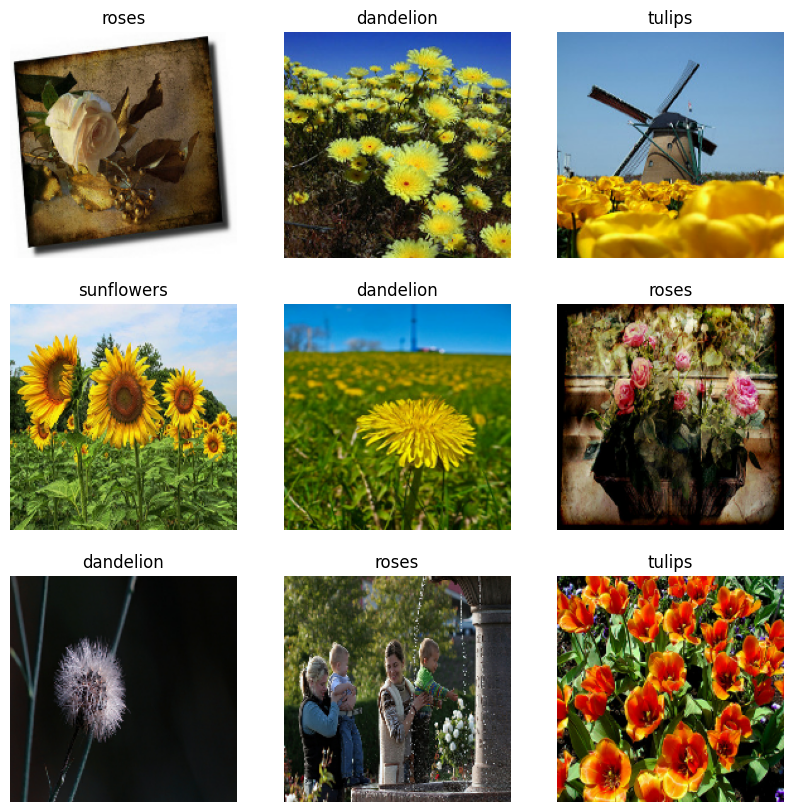
Bu veri setlerini kullanarak bir modeli Model.fit geçirerek eğiteceksiniz. İsterseniz, veri kümesini manuel olarak yineleyebilir ve toplu görüntü alabilirsiniz:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch , (32, 180, 180, 3) şeklinin bir tensörüdür. Bu, 180x180x3 şeklinde 32 görüntüden oluşan bir toplu işlemdir (son boyut, RGB renk kanallarını ifade eder). label_batch , şeklin (32,) bir tensörüdür, bunlar 32 görüntüye karşılık gelen etiketlerdir.
Onları bir numpy.ndarray dönüştürmek için image_batch ve labels_batch tensörlerinde .numpy() öğesini çağırabilirsiniz.
Performans için veri kümesini yapılandırın
G/Ç'nin bloke olmasına gerek kalmadan diskten veri alabilmeniz için arabelleğe alınmış önceden getirmeyi kullandığınızdan emin olalım. Bunlar, verileri yüklerken kullanmanız gereken iki önemli yöntemdir:
-
Dataset.cache, görüntüleri ilk dönem boyunca diskten yüklendikten sonra bellekte tutar. Bu, modelinizi eğitirken veri setinin bir darboğaz haline gelmemesini sağlayacaktır. Veri kümeniz belleğe sığmayacak kadar büyükse, bu yöntemi, performanslı bir disk önbelleği oluşturmak için de kullanabilirsiniz. -
Dataset.prefetch, eğitim sırasında veri ön işleme ve model yürütme ile çakışır.
İlgilenen okuyucular , tf.data API kılavuzu ile daha iyi performans'ın Önceden Getirme bölümünde verilerin diske nasıl önbelleğe alınacağının yanı sıra her iki yöntem hakkında daha fazla bilgi edinebilir.
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Verileri standartlaştırın
RGB kanal değerleri [0, 255] aralığındadır. Bu bir sinir ağı için ideal değildir; genel olarak girdi değerlerinizi küçük yapmaya çalışmalısınız.
Burada, tf.keras.layers.Rescaling kullanarak değerleri [0, 1] aralığında olacak şekilde standartlaştıracaksınız:
normalization_layer = layers.Rescaling(1./255)
Bu katmanı kullanmanın iki yolu vardır. Dataset.map arayarak veri kümesine uygulayabilirsiniz:
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 1.0
Veya dağıtımı basitleştirebilecek katmanı model tanımınıza dahil edebilirsiniz. Burada ikinci yaklaşımı kullanalım.
modeli oluştur
Sıralı model, her birinde bir maksimum havuzlama katmanına ( tf.keras.layers.MaxPooling2D ) sahip üç evrişim bloğundan ( tf.keras.layers.Conv2D ) oluşur. Üstünde bir ReLU etkinleştirme işlevi ( 'relu' ) tarafından etkinleştirilen 128 birimlik tam bağlı bir katman ( tf.keras.layers.Dense ) vardır. Bu model yüksek doğruluk için ayarlanmamıştır—bu öğreticinin amacı standart bir yaklaşım göstermektir.
num_classes = len(class_names)
model = Sequential([
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Modeli derleyin
Bu öğretici için, tf.keras.optimizers.Adam optimizer ve tf.keras.losses.SparseCategoricalCrossentropy kaybı işlevini seçin. Her eğitim dönemi için eğitim ve doğrulama doğruluğunu görüntülemek için, metrics bağımsız değişkenini Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Model özeti
Modelin Model.summary yöntemini kullanarak ağın tüm katmanlarını görüntüleyin:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_1 (Rescaling) (None, 180, 180, 3) 0
conv2d (Conv2D) (None, 180, 180, 16) 448
max_pooling2d (MaxPooling2D (None, 90, 90, 16) 0
)
conv2d_1 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_1 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_2 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_2 (MaxPooling (None, 22, 22, 64) 0
2D)
flatten (Flatten) (None, 30976) 0
dense (Dense) (None, 128) 3965056
dense_1 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
Modeli eğit
epochs=10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/10 92/92 [==============================] - 3s 16ms/step - loss: 1.2769 - accuracy: 0.4489 - val_loss: 1.0457 - val_accuracy: 0.5804 Epoch 2/10 92/92 [==============================] - 1s 11ms/step - loss: 0.9386 - accuracy: 0.6328 - val_loss: 0.9665 - val_accuracy: 0.6158 Epoch 3/10 92/92 [==============================] - 1s 11ms/step - loss: 0.7390 - accuracy: 0.7200 - val_loss: 0.8768 - val_accuracy: 0.6540 Epoch 4/10 92/92 [==============================] - 1s 11ms/step - loss: 0.5649 - accuracy: 0.7963 - val_loss: 0.9258 - val_accuracy: 0.6540 Epoch 5/10 92/92 [==============================] - 1s 11ms/step - loss: 0.3662 - accuracy: 0.8733 - val_loss: 1.1734 - val_accuracy: 0.6267 Epoch 6/10 92/92 [==============================] - 1s 11ms/step - loss: 0.2169 - accuracy: 0.9343 - val_loss: 1.3728 - val_accuracy: 0.6499 Epoch 7/10 92/92 [==============================] - 1s 11ms/step - loss: 0.1191 - accuracy: 0.9629 - val_loss: 1.3791 - val_accuracy: 0.6471 Epoch 8/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0497 - accuracy: 0.9871 - val_loss: 1.8002 - val_accuracy: 0.6390 Epoch 9/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0372 - accuracy: 0.9922 - val_loss: 1.8545 - val_accuracy: 0.6390 Epoch 10/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0715 - accuracy: 0.9813 - val_loss: 2.0656 - val_accuracy: 0.6049
Eğitim sonuçlarını görselleştirin
Eğitim ve doğrulama setlerinde kayıp ve doğruluk grafikleri oluşturun:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
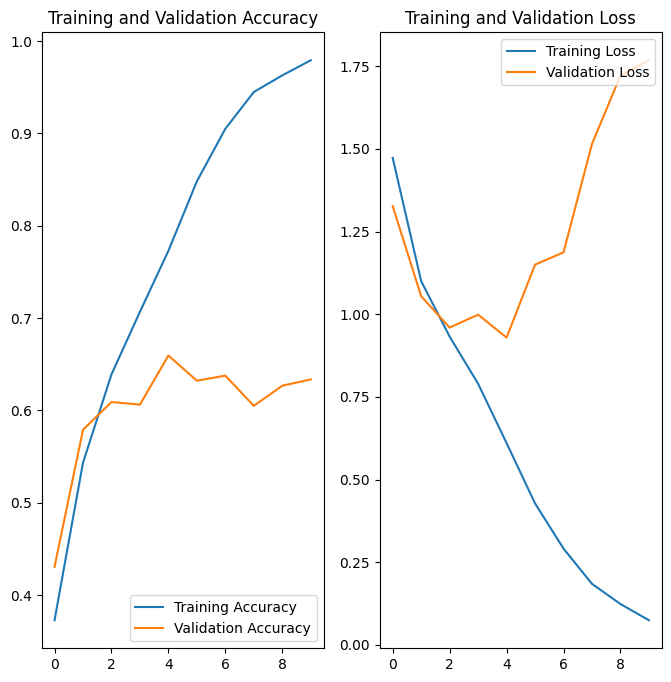
Grafikler, eğitim doğruluğunun ve doğrulama doğruluğunun büyük farklarla kapalı olduğunu ve modelin doğrulama setinde yalnızca yaklaşık %60 doğruluk elde ettiğini göstermektedir.
Neyin yanlış gittiğini inceleyelim ve modelin genel performansını artırmaya çalışalım.
Aşırı uyum gösterme
Yukarıdaki grafiklerde, eğitim doğruluğu zamanla doğrusal olarak artarken, doğrulama doğruluğu eğitim sürecinde yaklaşık %60 oranında durur. Ayrıca, eğitim ve doğrulama doğruluğu arasındaki doğruluk farkı dikkat çekicidir - fazla uydurmanın bir işareti.
Az sayıda eğitim örneği olduğunda, model bazen eğitim örneklerinden gürültülerden veya istenmeyen ayrıntılardan öğrenir - bir dereceye kadar bu, modelin yeni örnekler üzerindeki performansını olumsuz etkiler. Bu fenomen aşırı takma olarak bilinir. Bu, modelin yeni bir veri kümesi üzerinde genelleme yapmakta zorlanacağı anlamına gelir.
Eğitim sürecinde aşırı uyumla mücadele etmenin birçok yolu vardır. Bu öğreticide, veri büyütmeyi kullanacak ve modelinize Dropout ekleyeceksiniz.
Veri büyütme
Fazla takma genellikle az sayıda eğitim örneği olduğunda meydana gelir. Veri büyütme , inandırıcı görünen görüntüler veren rastgele dönüşümler kullanarak mevcut örneklerinizden ek eğitim verileri üretme yaklaşımını benimser. Bu, modeli verilerin daha fazla yönüne maruz bırakmaya ve daha iyi genelleştirmeye yardımcı olur.
Aşağıdaki Keras ön işleme katmanlarını kullanarak veri büyütmeyi uygulayacaksınız: tf.keras.layers.RandomFlip , tf.keras.layers.RandomRotation ve tf.keras.layers.RandomZoom . Bunlar, diğer katmanlar gibi modelinizin içine dahil edilebilir ve GPU üzerinde çalıştırılabilir.
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.1),
]
)
Aynı görüntüye birkaç kez veri büyütme uygulayarak birkaç artırılmış örneğin nasıl göründüğünü görselleştirelim:
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")

Bir modeli bir anda eğitmek için veri büyütmeyi kullanacaksınız.
Bırakmak
Fazla takmayı azaltmak için başka bir teknik, ağa bırakma düzenlemesini getirmektir.
Bir katmana bırakma uyguladığınızda, eğitim süreci sırasında katmandan bir dizi çıktı birimini rastgele (etkinleştirmeyi sıfıra ayarlayarak) bırakır. Dropout, girdi değeri olarak 0,1, 0,2, 0,4 vb. şeklinde bir kesirli sayı alır. Bu, uygulanan katmandan çıktı birimlerinin %10, %20 veya %40'ının rastgele bırakılması anlamına gelir.
Artırılmış görüntüleri kullanarak tf.keras.layers.Dropout önce tf.keras.layers.Dropout ile yeni bir sinir ağı oluşturalım:
model = Sequential([
data_augmentation,
layers.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Modeli derleyin ve eğitin
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential_1 (Sequential) (None, 180, 180, 3) 0
rescaling_2 (Rescaling) (None, 180, 180, 3) 0
conv2d_3 (Conv2D) (None, 180, 180, 16) 448
max_pooling2d_3 (MaxPooling (None, 90, 90, 16) 0
2D)
conv2d_4 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_4 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_5 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_5 (MaxPooling (None, 22, 22, 64) 0
2D)
dropout (Dropout) (None, 22, 22, 64) 0
flatten_1 (Flatten) (None, 30976) 0
dense_2 (Dense) (None, 128) 3965056
dense_3 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
epochs = 15
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/15 92/92 [==============================] - 2s 14ms/step - loss: 1.3840 - accuracy: 0.3999 - val_loss: 1.0967 - val_accuracy: 0.5518 Epoch 2/15 92/92 [==============================] - 1s 12ms/step - loss: 1.1152 - accuracy: 0.5395 - val_loss: 1.1123 - val_accuracy: 0.5545 Epoch 3/15 92/92 [==============================] - 1s 12ms/step - loss: 1.0049 - accuracy: 0.6052 - val_loss: 0.9544 - val_accuracy: 0.6253 Epoch 4/15 92/92 [==============================] - 1s 12ms/step - loss: 0.9452 - accuracy: 0.6257 - val_loss: 0.9681 - val_accuracy: 0.6213 Epoch 5/15 92/92 [==============================] - 1s 12ms/step - loss: 0.8804 - accuracy: 0.6591 - val_loss: 0.8450 - val_accuracy: 0.6798 Epoch 6/15 92/92 [==============================] - 1s 12ms/step - loss: 0.8001 - accuracy: 0.6945 - val_loss: 0.8715 - val_accuracy: 0.6594 Epoch 7/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7736 - accuracy: 0.6965 - val_loss: 0.8059 - val_accuracy: 0.6935 Epoch 8/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7477 - accuracy: 0.7078 - val_loss: 0.8292 - val_accuracy: 0.6812 Epoch 9/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7053 - accuracy: 0.7251 - val_loss: 0.7743 - val_accuracy: 0.6989 Epoch 10/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6884 - accuracy: 0.7340 - val_loss: 0.7867 - val_accuracy: 0.6907 Epoch 11/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6536 - accuracy: 0.7469 - val_loss: 0.7732 - val_accuracy: 0.6785 Epoch 12/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6456 - accuracy: 0.7500 - val_loss: 0.7801 - val_accuracy: 0.6907 Epoch 13/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5941 - accuracy: 0.7735 - val_loss: 0.7185 - val_accuracy: 0.7330 Epoch 14/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5824 - accuracy: 0.7735 - val_loss: 0.7282 - val_accuracy: 0.7357 Epoch 15/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5771 - accuracy: 0.7851 - val_loss: 0.7308 - val_accuracy: 0.7343
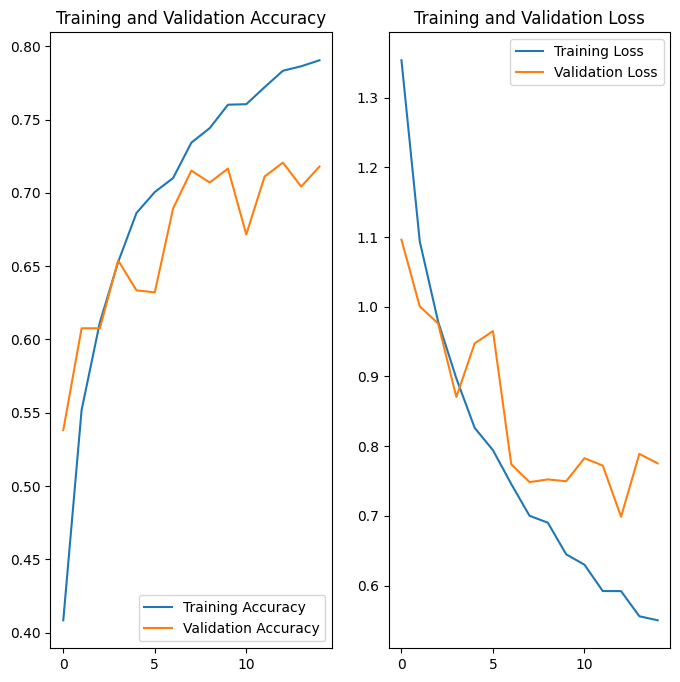
Eğitim sonuçlarını görselleştirin
Veri büyütme ve tf.keras.layers.Dropout uygulandıktan sonra, eskisinden daha az fazla uyum olur ve eğitim ile doğrulama doğruluğu daha yakın hizalanır:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
Yeni veriler hakkında tahminde bulunun
Son olarak, eğitim veya doğrulama kümelerine dahil olmayan bir görüntüyü sınıflandırmak için modelimizi kullanalım.
sunflower_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg"
sunflower_path = tf.keras.utils.get_file('Red_sunflower', origin=sunflower_url)
img = tf.keras.utils.load_img(
sunflower_path, target_size=(img_height, img_width)
)
img_array = tf.keras.utils.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batch
predictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])
print(
"This image most likely belongs to {} with a {:.2f} percent confidence."
.format(class_names[np.argmax(score)], 100 * np.max(score))
)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg 122880/117948 [===============================] - 0s 0us/step 131072/117948 [=================================] - 0s 0us/step This image most likely belongs to sunflowers with a 89.13 percent confidence.