
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
বরাবরের মতো, এই উদাহরণের tf.keras API ব্যবহার করবে, যেটি সম্পর্কে আপনি TensorFlow Keras গাইডে আরও জানতে পারবেন।
পূর্ববর্তী উভয় উদাহরণে- পাঠ্য শ্রেণীবদ্ধ করা এবং জ্বালানী দক্ষতার পূর্বাভাস দেওয়া - আমরা দেখেছি যে বৈধকরণ ডেটাতে আমাদের মডেলের নির্ভুলতা অনেকগুলি যুগের প্রশিক্ষণের পরে শীর্ষে উঠবে এবং তারপর স্থবির বা হ্রাস পেতে শুরু করবে।
অন্য কথায়, আমাদের মডেল প্রশিক্ষণ ডেটার সাথে ওভারফিট হবে। ওভারফিটিং কীভাবে মোকাবেলা করতে হয় তা শেখা গুরুত্বপূর্ণ। যদিও প্রশিক্ষণ সেটে উচ্চ নির্ভুলতা অর্জন করা প্রায়শই সম্ভব, আমরা আসলেই এমন মডেলগুলি তৈরি করতে চাই যা একটি পরীক্ষার সেটে ভালভাবে সাধারণীকরণ করে (বা তারা আগে দেখেনি এমন ডেটা)।
ওভারফিটিং এর বিপরীত হল আন্ডারফিটিং। ট্রেনের ডেটাতে উন্নতির জন্য এখনও অবকাশ থাকলে আন্ডারফিটিং ঘটে। এটি বেশ কয়েকটি কারণে ঘটতে পারে: যদি মডেলটি যথেষ্ট শক্তিশালী না হয়, অতিরিক্ত-নিয়ন্ত্রিত হয়, বা সহজভাবে যথেষ্ট দীর্ঘ প্রশিক্ষিত না হয়। এর মানে নেটওয়ার্ক প্রশিক্ষণের ডেটাতে প্রাসঙ্গিক নিদর্শন শিখেনি।
যদিও আপনি যদি খুব বেশি সময় ধরে প্রশিক্ষণ দেন, তবে মডেলটি ওভারফিট হতে শুরু করবে এবং প্রশিক্ষণের ডেটা থেকে প্যাটার্ন শিখবে যা পরীক্ষার ডেটাতে সাধারণীকরণ করে না। আমরা একটি ভারসাম্য আঘাত করা প্রয়োজন. আমরা নীচে অন্বেষণ করব হিসাবে উপযুক্ত সংখ্যক যুগের জন্য কীভাবে প্রশিক্ষণ দেওয়া যায় তা বোঝা একটি দরকারী দক্ষতা।
ওভারফিটিং প্রতিরোধ করার জন্য, সর্বোত্তম সমাধান হল আরও সম্পূর্ণ প্রশিক্ষণ ডেটা ব্যবহার করা। ডেটাসেটটি ইনপুটগুলির সম্পূর্ণ পরিসীমা কভার করবে যা মডেলটি পরিচালনা করবে বলে আশা করা হচ্ছে৷ অতিরিক্ত ডেটা শুধুমাত্র তখনই উপযোগী হতে পারে যদি এটি নতুন এবং আকর্ষণীয় ক্ষেত্রে কভার করে।
আরও সম্পূর্ণ ডেটাতে প্রশিক্ষিত একটি মডেল স্বাভাবিকভাবেই আরও ভাল সাধারণীকরণ করবে। যখন এটি আর সম্ভব হয় না, পরবর্তী সেরা সমাধান হল নিয়মিতকরণের মতো কৌশলগুলি ব্যবহার করা। এটি আপনার মডেল সংরক্ষণ করতে পারে এমন তথ্যের পরিমাণ এবং প্রকারের উপর সীমাবদ্ধতা রাখে। যদি একটি নেটওয়ার্ক শুধুমাত্র অল্প সংখ্যক নিদর্শন মনে রাখার সামর্থ্য রাখে, তবে অপ্টিমাইজেশন প্রক্রিয়া এটিকে সবচেয়ে বিশিষ্ট প্যাটার্নগুলিতে ফোকাস করতে বাধ্য করবে, যেগুলির ভালভাবে সাধারণীকরণের একটি ভাল সুযোগ রয়েছে।
এই নোটবুকে, আমরা বেশ কিছু সাধারণ নিয়মিতকরণ কৌশল অন্বেষণ করব, এবং একটি শ্রেণিবিন্যাস মডেলে উন্নতি করতে সেগুলি ব্যবহার করব।
সেটআপ
শুরু করার আগে, প্রয়োজনীয় প্যাকেজগুলি আমদানি করুন:
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import regularizers
print(tf.__version__)
2.8.0-rc1
!pip install git+https://github.com/tensorflow/docs
import tensorflow_docs as tfdocs
import tensorflow_docs.modeling
import tensorflow_docs.plots
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import pathlib
import shutil
import tempfile
logdir = pathlib.Path(tempfile.mkdtemp())/"tensorboard_logs"
shutil.rmtree(logdir, ignore_errors=True)
হিগস ডেটাসেট
এই টিউটোরিয়ালটির লক্ষ্য কণা পদার্থবিদ্যা করা নয়, তাই ডেটাসেটের বিশদ বিবরণে চিন্তা করবেন না। এটিতে 11,000,000টি উদাহরণ রয়েছে, প্রতিটিতে 28টি বৈশিষ্ট্য এবং একটি বাইনারি ক্লাস লেবেল রয়েছে।
gz = tf.keras.utils.get_file('HIGGS.csv.gz', 'http://mlphysics.ics.uci.edu/data/higgs/HIGGS.csv.gz')
Downloading data from http://mlphysics.ics.uci.edu/data/higgs/HIGGS.csv.gz 2816409600/2816407858 [==============================] - 123s 0us/step 2816417792/2816407858 [==============================] - 123s 0us/step
FEATURES = 28
tf.data.experimental.CsvDataset ক্লাসটি কোনো মধ্যবর্তী ডিকম্প্রেশন ধাপ ছাড়াই একটি gzip ফাইল থেকে সরাসরি csv রেকর্ড পড়তে ব্যবহার করা যেতে পারে।
ds = tf.data.experimental.CsvDataset(gz,[float(),]*(FEATURES+1), compression_type="GZIP")
সেই csv পাঠক শ্রেণী প্রতিটি রেকর্ডের জন্য স্কেলারের একটি তালিকা প্রদান করে। নিম্নলিখিত ফাংশনটি স্কেলারগুলির তালিকাটিকে একটি (feature_vector, লেবেল) জোড়ায় পুনরায় প্যাক করে।
def pack_row(*row):
label = row[0]
features = tf.stack(row[1:],1)
return features, label
ডেটার বড় ব্যাচগুলিতে কাজ করার সময় টেনসরফ্লো সবচেয়ে কার্যকর।
তাই প্রতিটি সারি পৃথকভাবে পুনরায় প্যাক করার পরিবর্তে একটি নতুন Dataset তৈরি করুন যা 10000-উদাহরণগুলির ব্যাচ নেয়, প্রতিটি ব্যাচে pack_row ফাংশন প্রয়োগ করে এবং তারপর ব্যাচগুলিকে পৃথক রেকর্ডে বিভক্ত করে:
packed_ds = ds.batch(10000).map(pack_row).unbatch()
এই নতুন packed_ds থেকে কিছু রেকর্ড দেখুন।
বৈশিষ্ট্যগুলি পুরোপুরি স্বাভাবিক করা হয়নি, তবে এই টিউটোরিয়ালের জন্য এটি যথেষ্ট।
for features,label in packed_ds.batch(1000).take(1):
print(features[0])
plt.hist(features.numpy().flatten(), bins = 101)
tf.Tensor( [ 0.8692932 -0.6350818 0.22569026 0.32747006 -0.6899932 0.75420225 -0.24857314 -1.0920639 0. 1.3749921 -0.6536742 0.9303491 1.1074361 1.1389043 -1.5781983 -1.0469854 0. 0.65792954 -0.01045457 -0.04576717 3.1019614 1.35376 0.9795631 0.97807616 0.92000484 0.72165745 0.98875093 0.87667835], shape=(28,), dtype=float32)
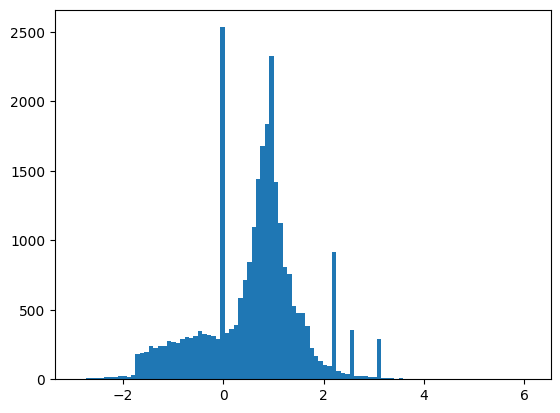
এই টিউটোরিয়ালটি তুলনামূলকভাবে সংক্ষিপ্ত রাখতে বৈধতার জন্য প্রথম 1000টি নমুনা এবং পরবর্তী 10000টি প্রশিক্ষণের জন্য ব্যবহার করুন:
N_VALIDATION = int(1e3)
N_TRAIN = int(1e4)
BUFFER_SIZE = int(1e4)
BATCH_SIZE = 500
STEPS_PER_EPOCH = N_TRAIN//BATCH_SIZE
Dataset.skip এবং Dataset.take পদ্ধতি এটিকে সহজ করে তোলে।
একই সময়ে, প্রতিটি যুগে লোডারকে ফাইল থেকে ডেটা পুনরায় পড়তে হবে না তা নিশ্চিত করতে Dataset.cache পদ্ধতি ব্যবহার করুন:
validate_ds = packed_ds.take(N_VALIDATION).cache()
train_ds = packed_ds.skip(N_VALIDATION).take(N_TRAIN).cache()
train_ds
<CacheDataset element_spec=(TensorSpec(shape=(28,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.float32, name=None))>
এই ডেটাসেটগুলি পৃথক উদাহরণ প্রদান করে। প্রশিক্ষণের জন্য উপযুক্ত আকারের ব্যাচ তৈরি করতে .batch পদ্ধতি ব্যবহার করুন। ব্যাচ করার আগে মনে রাখবেন .shuffle এবং .repeat ট্রেনিং সেটটি।
validate_ds = validate_ds.batch(BATCH_SIZE)
train_ds = train_ds.shuffle(BUFFER_SIZE).repeat().batch(BATCH_SIZE)
ওভারফিটিং প্রদর্শন করুন
ওভারফিটিং প্রতিরোধ করার সবচেয়ে সহজ উপায় হল একটি ছোট মডেল দিয়ে শুরু করা: একটি ছোট সংখ্যক শেখার যোগ্য প্যারামিটার সহ একটি মডেল (যা স্তরের সংখ্যা এবং প্রতি স্তরের ইউনিটের সংখ্যা দ্বারা নির্ধারিত হয়)। গভীর শিক্ষায়, একটি মডেলে শেখার যোগ্য প্যারামিটারের সংখ্যাকে প্রায়শই মডেলের "ক্ষমতা" হিসাবে উল্লেখ করা হয়।
স্বজ্ঞাতভাবে, আরও পরামিতি সহ একটি মডেলের আরও "স্মরণ ক্ষমতা" থাকবে এবং তাই প্রশিক্ষণের নমুনা এবং তাদের লক্ষ্যগুলির মধ্যে একটি নিখুঁত অভিধানের মতো ম্যাপিং সহজেই শিখতে সক্ষম হবে, কোনো সাধারণীকরণ ক্ষমতা ছাড়াই একটি ম্যাপিং, কিন্তু ভবিষ্যদ্বাণী করার সময় এটি অকেজো হবে। পূর্বে অদেখা তথ্যের উপর।
সর্বদা এটি মনে রাখবেন: গভীর শিক্ষার মডেলগুলি প্রশিক্ষণের ডেটার সাথে মানানসই হতে পারে, তবে আসল চ্যালেঞ্জ হল সাধারণীকরণ, মানানসই নয়।
অন্যদিকে, যদি নেটওয়ার্কে সীমিত মুখস্থ সংস্থান থাকে, তবে এটি সহজে ম্যাপিং শিখতে সক্ষম হবে না। এর ক্ষতি কমানোর জন্য, এটিকে আরও ভবিষ্যদ্বাণী করার ক্ষমতা সহ সংকুচিত উপস্থাপনা শিখতে হবে। একই সময়ে, আপনি যদি আপনার মডেলটিকে খুব ছোট করেন তবে এটি প্রশিক্ষণের ডেটাতে ফিট করতে অসুবিধা হবে। "অত্যধিক ক্ষমতা" এবং "পর্যাপ্ত ক্ষমতা নয়" এর মধ্যে একটি ভারসাম্য রয়েছে।
দুর্ভাগ্যবশত, আপনার মডেলের সঠিক আকার বা স্থাপত্য নির্ধারণ করার জন্য কোন জাদুকরী সূত্র নেই (স্তরের সংখ্যার পরিপ্রেক্ষিতে বা প্রতিটি স্তরের জন্য সঠিক আকার)। আপনাকে বিভিন্ন স্থাপত্যের একটি সিরিজ ব্যবহার করে পরীক্ষা করতে হবে।
একটি উপযুক্ত মডেলের আকার খুঁজে পেতে, তুলনামূলকভাবে কয়েকটি স্তর এবং পরামিতি দিয়ে শুরু করা ভাল, তারপরে স্তরগুলির আকার বাড়ানো শুরু করা বা নতুন স্তর যুক্ত করা যতক্ষণ না আপনি বৈধতা ক্ষতির উপর কম আয় না দেখতে পান।
শুধুমাত্র layers.Dense ব্যবহার করে একটি সাধারণ মডেল দিয়ে শুরু করুন৷ একটি বেসলাইন হিসাবে ঘন, তারপরে আরও বড় সংস্করণ তৈরি করুন এবং তাদের তুলনা করুন৷
প্রশিক্ষণ পদ্ধতি
আপনি যদি প্রশিক্ষণের সময় ধীরে ধীরে শেখার হার হ্রাস করেন তবে অনেক মডেল আরও ভাল প্রশিক্ষণ দেয়। সময়ের সাথে সাথে শেখার হার কমাতে optimizers.schedules ব্যবহার করুন:
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
0.001,
decay_steps=STEPS_PER_EPOCH*1000,
decay_rate=1,
staircase=False)
def get_optimizer():
return tf.keras.optimizers.Adam(lr_schedule)
উপরের কোডটি একটি schedules.InverseTimeDecay সেট করে। InverseTimeDecay হাইপারবোলিকভাবে শেখার হারকে 1000 যুগে ভিত্তি হারের 1/2, 2000 যুগে 1/3 এবং আরও অনেক কিছুতে হ্রাস করতে পারে।
step = np.linspace(0,100000)
lr = lr_schedule(step)
plt.figure(figsize = (8,6))
plt.plot(step/STEPS_PER_EPOCH, lr)
plt.ylim([0,max(plt.ylim())])
plt.xlabel('Epoch')
_ = plt.ylabel('Learning Rate')
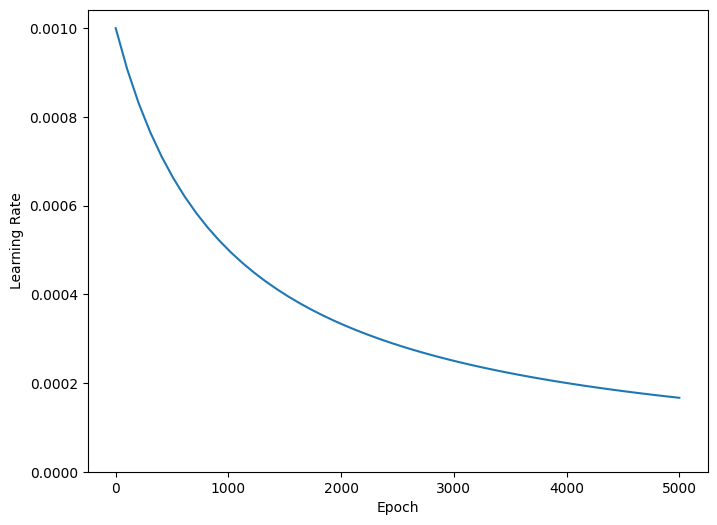
এই টিউটোরিয়ালের প্রতিটি মডেল একই প্রশিক্ষণ কনফিগারেশন ব্যবহার করবে। তাই কলব্যাকের তালিকা থেকে শুরু করে এইগুলিকে পুনরায় ব্যবহারযোগ্য উপায়ে সেট আপ করুন৷
এই টিউটোরিয়ালের প্রশিক্ষণ অনেক ছোট যুগের জন্য চলে। লগিং নয়েজ কমাতে tfdocs.EpochDots ব্যবহার করুন যা সহজভাবে একটি প্রিন্ট করে . প্রতিটি যুগের জন্য, এবং প্রতি 100 যুগে মেট্রিক্সের একটি সম্পূর্ণ সেট।
এর callbacks.EarlyStopping অন্তর্ভুক্ত করুন। দীর্ঘ এবং অপ্রয়োজনীয় প্রশিক্ষণের সময় এড়াতে তাড়াতাড়ি থামানো। মনে রাখবেন যে এই val_loss val_binary_crossentropy । এই পার্থক্যটি পরে গুরুত্বপূর্ণ হবে।
প্রশিক্ষণের জন্য TensorBoard লগ তৈরি করতে callbacks.TensorBoard ব্যবহার করুন।
def get_callbacks(name):
return [
tfdocs.modeling.EpochDots(),
tf.keras.callbacks.EarlyStopping(monitor='val_binary_crossentropy', patience=200),
tf.keras.callbacks.TensorBoard(logdir/name),
]
একইভাবে প্রতিটি মডেল একই Model.compile এবং Model.fit সেটিংস ব্যবহার করবে:
def compile_and_fit(model, name, optimizer=None, max_epochs=10000):
if optimizer is None:
optimizer = get_optimizer()
model.compile(optimizer=optimizer,
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[
tf.keras.losses.BinaryCrossentropy(
from_logits=True, name='binary_crossentropy'),
'accuracy'])
model.summary()
history = model.fit(
train_ds,
steps_per_epoch = STEPS_PER_EPOCH,
epochs=max_epochs,
validation_data=validate_ds,
callbacks=get_callbacks(name),
verbose=0)
return history
ক্ষুদ্র মডেল
একটি মডেল প্রশিক্ষণ দিয়ে শুরু করুন:
tiny_model = tf.keras.Sequential([
layers.Dense(16, activation='elu', input_shape=(FEATURES,)),
layers.Dense(1)
])
size_histories = {}
size_histories['Tiny'] = compile_and_fit(tiny_model, 'sizes/Tiny')
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 16) 464
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 481
Trainable params: 481
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.4961, binary_crossentropy:0.7294, loss:0.7294, val_accuracy:0.4840, val_binary_crossentropy:0.7200, val_loss:0.7200,
....................................................................................................
Epoch: 100, accuracy:0.5931, binary_crossentropy:0.6279, loss:0.6279, val_accuracy:0.5860, val_binary_crossentropy:0.6288, val_loss:0.6288,
....................................................................................................
Epoch: 200, accuracy:0.6157, binary_crossentropy:0.6178, loss:0.6178, val_accuracy:0.6200, val_binary_crossentropy:0.6134, val_loss:0.6134,
....................................................................................................
Epoch: 300, accuracy:0.6370, binary_crossentropy:0.6086, loss:0.6086, val_accuracy:0.6220, val_binary_crossentropy:0.6055, val_loss:0.6055,
....................................................................................................
Epoch: 400, accuracy:0.6522, binary_crossentropy:0.6008, loss:0.6008, val_accuracy:0.6260, val_binary_crossentropy:0.5997, val_loss:0.5997,
....................................................................................................
Epoch: 500, accuracy:0.6513, binary_crossentropy:0.5946, loss:0.5946, val_accuracy:0.6480, val_binary_crossentropy:0.5911, val_loss:0.5911,
....................................................................................................
Epoch: 600, accuracy:0.6636, binary_crossentropy:0.5894, loss:0.5894, val_accuracy:0.6390, val_binary_crossentropy:0.5898, val_loss:0.5898,
....................................................................................................
Epoch: 700, accuracy:0.6696, binary_crossentropy:0.5852, loss:0.5852, val_accuracy:0.6530, val_binary_crossentropy:0.5870, val_loss:0.5870,
....................................................................................................
Epoch: 800, accuracy:0.6706, binary_crossentropy:0.5824, loss:0.5824, val_accuracy:0.6590, val_binary_crossentropy:0.5850, val_loss:0.5850,
....................................................................................................
Epoch: 900, accuracy:0.6709, binary_crossentropy:0.5796, loss:0.5796, val_accuracy:0.6680, val_binary_crossentropy:0.5831, val_loss:0.5831,
....................................................................................................
Epoch: 1000, accuracy:0.6780, binary_crossentropy:0.5769, loss:0.5769, val_accuracy:0.6530, val_binary_crossentropy:0.5851, val_loss:0.5851,
....................................................................................................
Epoch: 1100, accuracy:0.6735, binary_crossentropy:0.5752, loss:0.5752, val_accuracy:0.6620, val_binary_crossentropy:0.5807, val_loss:0.5807,
....................................................................................................
Epoch: 1200, accuracy:0.6759, binary_crossentropy:0.5729, loss:0.5729, val_accuracy:0.6620, val_binary_crossentropy:0.5792, val_loss:0.5792,
....................................................................................................
Epoch: 1300, accuracy:0.6849, binary_crossentropy:0.5716, loss:0.5716, val_accuracy:0.6450, val_binary_crossentropy:0.5859, val_loss:0.5859,
....................................................................................................
Epoch: 1400, accuracy:0.6790, binary_crossentropy:0.5695, loss:0.5695, val_accuracy:0.6700, val_binary_crossentropy:0.5776, val_loss:0.5776,
....................................................................................................
Epoch: 1500, accuracy:0.6824, binary_crossentropy:0.5681, loss:0.5681, val_accuracy:0.6730, val_binary_crossentropy:0.5761, val_loss:0.5761,
....................................................................................................
Epoch: 1600, accuracy:0.6828, binary_crossentropy:0.5669, loss:0.5669, val_accuracy:0.6690, val_binary_crossentropy:0.5766, val_loss:0.5766,
....................................................................................................
Epoch: 1700, accuracy:0.6874, binary_crossentropy:0.5657, loss:0.5657, val_accuracy:0.6600, val_binary_crossentropy:0.5774, val_loss:0.5774,
....................................................................................................
Epoch: 1800, accuracy:0.6845, binary_crossentropy:0.5655, loss:0.5655, val_accuracy:0.6780, val_binary_crossentropy:0.5752, val_loss:0.5752,
....................................................................................................
Epoch: 1900, accuracy:0.6837, binary_crossentropy:0.5644, loss:0.5644, val_accuracy:0.6790, val_binary_crossentropy:0.5753, val_loss:0.5753,
....................................................................................................
Epoch: 2000, accuracy:0.6853, binary_crossentropy:0.5632, loss:0.5632, val_accuracy:0.6780, val_binary_crossentropy:0.5753, val_loss:0.5753,
....................................................................................................
Epoch: 2100, accuracy:0.6871, binary_crossentropy:0.5625, loss:0.5625, val_accuracy:0.6670, val_binary_crossentropy:0.5769, val_loss:0.5769,
...................................
এখন মডেলটি কীভাবে করেছে তা পরীক্ষা করুন:
plotter = tfdocs.plots.HistoryPlotter(metric = 'binary_crossentropy', smoothing_std=10)
plotter.plot(size_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
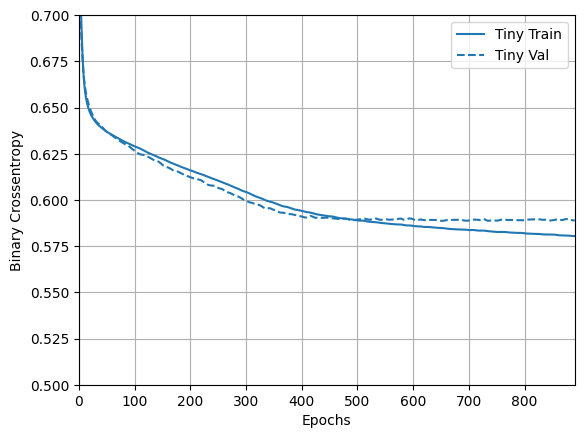
ছোট মডেল
আপনি ছোট মডেলের পারফরম্যান্সকে হারাতে পারেন কিনা তা দেখতে, ধীরে ধীরে কিছু বড় মডেলকে প্রশিক্ষণ দিন।
প্রতিটি 16 ইউনিট সহ দুটি লুকানো স্তর চেষ্টা করুন:
small_model = tf.keras.Sequential([
# `input_shape` is only required here so that `.summary` works.
layers.Dense(16, activation='elu', input_shape=(FEATURES,)),
layers.Dense(16, activation='elu'),
layers.Dense(1)
])
size_histories['Small'] = compile_and_fit(small_model, 'sizes/Small')
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 16) 464
dense_3 (Dense) (None, 16) 272
dense_4 (Dense) (None, 1) 17
=================================================================
Total params: 753
Trainable params: 753
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.4864, binary_crossentropy:0.7769, loss:0.7769, val_accuracy:0.4930, val_binary_crossentropy:0.7211, val_loss:0.7211,
....................................................................................................
Epoch: 100, accuracy:0.6386, binary_crossentropy:0.6052, loss:0.6052, val_accuracy:0.6020, val_binary_crossentropy:0.6177, val_loss:0.6177,
....................................................................................................
Epoch: 200, accuracy:0.6697, binary_crossentropy:0.5829, loss:0.5829, val_accuracy:0.6310, val_binary_crossentropy:0.6018, val_loss:0.6018,
....................................................................................................
Epoch: 300, accuracy:0.6838, binary_crossentropy:0.5721, loss:0.5721, val_accuracy:0.6490, val_binary_crossentropy:0.5940, val_loss:0.5940,
....................................................................................................
Epoch: 400, accuracy:0.6911, binary_crossentropy:0.5656, loss:0.5656, val_accuracy:0.6430, val_binary_crossentropy:0.5985, val_loss:0.5985,
....................................................................................................
Epoch: 500, accuracy:0.6930, binary_crossentropy:0.5607, loss:0.5607, val_accuracy:0.6430, val_binary_crossentropy:0.6028, val_loss:0.6028,
.........................
মাঝারি মডেল
এখন প্রতিটি 64টি ইউনিট সহ 3টি লুকানো স্তর চেষ্টা করুন:
medium_model = tf.keras.Sequential([
layers.Dense(64, activation='elu', input_shape=(FEATURES,)),
layers.Dense(64, activation='elu'),
layers.Dense(64, activation='elu'),
layers.Dense(1)
])
এবং একই ডেটা ব্যবহার করে মডেলকে প্রশিক্ষণ দিন:
size_histories['Medium'] = compile_and_fit(medium_model, "sizes/Medium")
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_5 (Dense) (None, 64) 1856
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 64) 4160
dense_8 (Dense) (None, 1) 65
=================================================================
Total params: 10,241
Trainable params: 10,241
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5017, binary_crossentropy:0.6840, loss:0.6840, val_accuracy:0.4790, val_binary_crossentropy:0.6723, val_loss:0.6723,
....................................................................................................
Epoch: 100, accuracy:0.7173, binary_crossentropy:0.5221, loss:0.5221, val_accuracy:0.6470, val_binary_crossentropy:0.6111, val_loss:0.6111,
....................................................................................................
Epoch: 200, accuracy:0.7884, binary_crossentropy:0.4270, loss:0.4270, val_accuracy:0.6390, val_binary_crossentropy:0.7045, val_loss:0.7045,
..............................................................
বড় মডেল
একটি ব্যায়াম হিসাবে, আপনি একটি আরও বড় মডেল তৈরি করতে পারেন, এবং দেখুন এটি কত দ্রুত ওভারফিটিং শুরু করে। এর পরে, আসুন এই বেঞ্চমার্কে এমন একটি নেটওয়ার্ক যুক্ত করি যার অনেক বেশি ক্ষমতা রয়েছে, সমস্যাটির চেয়ে অনেক বেশি:
large_model = tf.keras.Sequential([
layers.Dense(512, activation='elu', input_shape=(FEATURES,)),
layers.Dense(512, activation='elu'),
layers.Dense(512, activation='elu'),
layers.Dense(512, activation='elu'),
layers.Dense(1)
])
এবং, আবার, একই ডেটা ব্যবহার করে মডেলকে প্রশিক্ষণ দিন:
size_histories['large'] = compile_and_fit(large_model, "sizes/large")
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_9 (Dense) (None, 512) 14848
dense_10 (Dense) (None, 512) 262656
dense_11 (Dense) (None, 512) 262656
dense_12 (Dense) (None, 512) 262656
dense_13 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5145, binary_crossentropy:0.7740, loss:0.7740, val_accuracy:0.4980, val_binary_crossentropy:0.6793, val_loss:0.6793,
....................................................................................................
Epoch: 100, accuracy:1.0000, binary_crossentropy:0.0020, loss:0.0020, val_accuracy:0.6600, val_binary_crossentropy:1.8540, val_loss:1.8540,
....................................................................................................
Epoch: 200, accuracy:1.0000, binary_crossentropy:0.0001, loss:0.0001, val_accuracy:0.6560, val_binary_crossentropy:2.5293, val_loss:2.5293,
..........................
প্রশিক্ষণ এবং বৈধতা ক্ষতি প্লট
কঠিন লাইনগুলি প্রশিক্ষণের ক্ষতি দেখায়, এবং ড্যাশ করা লাইনগুলি বৈধতা ক্ষতি দেখায় (মনে রাখবেন: একটি কম বৈধতা হ্রাস একটি ভাল মডেল নির্দেশ করে)।
একটি বৃহত্তর মডেল তৈরি করার সময় এটি আরও শক্তি দেয়, যদি এই শক্তিটি কোনওভাবে সীমাবদ্ধ না হয় তবে এটি সহজেই প্রশিক্ষণ সেটে ওভারফিট করতে পারে।
এই উদাহরণে, সাধারণত, শুধুমাত্র "Tiny" মডেলটি সম্পূর্ণভাবে অতিরিক্ত ফিটিং এড়াতে পরিচালনা করে এবং প্রতিটি বড় মডেলের ডেটা আরও দ্রুত ওভারফিট করে। এটি "large" মডেলের জন্য এতটাই গুরুতর হয়ে ওঠে যে সত্যিই কী ঘটছে তা দেখতে আপনাকে প্লটটিকে লগ-স্কেলে স্যুইচ করতে হবে।
এটি স্পষ্ট হয় যদি আপনি প্লট করেন এবং প্রশিক্ষণের মেট্রিক্সের সাথে বৈধতা মেট্রিক্সের তুলনা করেন।
- সামান্য পার্থক্য থাকাটাই স্বাভাবিক।
- যদি উভয় মেট্রিক একই দিকে চলে, সবকিছু ঠিক আছে।
- প্রশিক্ষণ মেট্রিক উন্নতি করতে থাকাকালীন যদি বৈধতা মেট্রিক স্থবির হতে শুরু করে, আপনি সম্ভবত ওভারফিটিং এর কাছাকাছি।
- যদি বৈধতা মেট্রিক ভুল দিকে যাচ্ছে, মডেলটি স্পষ্টভাবে ওভারফিটিং।
plotter.plot(size_histories)
a = plt.xscale('log')
plt.xlim([5, max(plt.xlim())])
plt.ylim([0.5, 0.7])
plt.xlabel("Epochs [Log Scale]")
Text(0.5, 0, 'Epochs [Log Scale]')
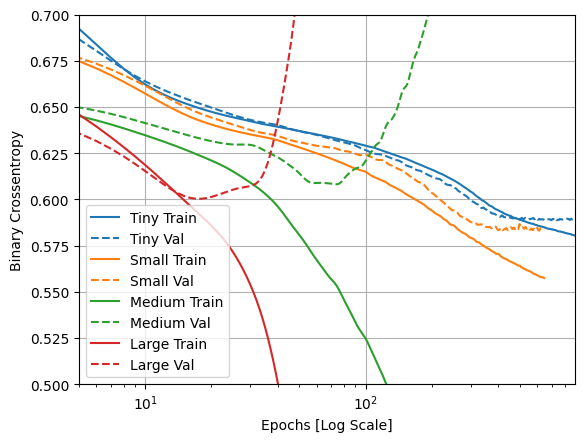
টেনসরবোর্ডে দেখুন
এই মডেলরা সবাই প্রশিক্ষণের সময় টেনসরবোর্ড লগ লিখেছিল।
একটি নোটবুকের ভিতরে একটি এমবেডেড টেনসরবোর্ড ভিউয়ার খুলুন:
#docs_infra: no_execute
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Open an embedded TensorBoard viewer
%tensorboard --logdir {logdir}/sizes
আপনি TensorBoard.dev- এ এই নোটবুকের আগের রানের ফলাফল দেখতে পারেন।
TensorBoard.dev হল সবার সাথে ML পরীক্ষা হোস্টিং, ট্র্যাকিং এবং শেয়ার করার জন্য একটি পরিচালিত অভিজ্ঞতা।
এটি সুবিধার জন্য একটি <iframe> -এও অন্তর্ভুক্ত:
display.IFrame(
src="https://tensorboard.dev/experiment/vW7jmmF9TmKmy3rbheMQpw/#scalars&_smoothingWeight=0.97",
width="100%", height="800px")
আপনি যদি TensorBoard ফলাফলগুলি ভাগ করতে চান তবে আপনি নিম্নলিখিতগুলিকে একটি কোড-সেলে অনুলিপি করে TensorBoard.dev- এ লগগুলি আপলোড করতে পারেন৷
tensorboard dev upload --logdir {logdir}/sizes
ওভারফিটিং প্রতিরোধ করার কৌশল
এই বিভাগের বিষয়বস্তুতে প্রবেশ করার আগে তুলনা করার জন্য একটি বেসলাইন হিসাবে ব্যবহার করার জন্য উপরের "Tiny" মডেল থেকে প্রশিক্ষণ লগগুলি অনুলিপি করুন।
shutil.rmtree(logdir/'regularizers/Tiny', ignore_errors=True)
shutil.copytree(logdir/'sizes/Tiny', logdir/'regularizers/Tiny')
PosixPath('/tmp/tmpn1rdh98q/tensorboard_logs/regularizers/Tiny')
regularizer_histories = {}
regularizer_histories['Tiny'] = size_histories['Tiny']
ওজন নিয়মিতকরণ যোগ করুন
আপনি ওকামের রেজার নীতির সাথে পরিচিত হতে পারেন: কোনো কিছুর জন্য দুটি ব্যাখ্যা দেওয়া হলে, ব্যাখ্যাটি সবচেয়ে বেশি সঠিক হতে পারে "সরল" একটি, যেটি সবচেয়ে কম অনুমান করে। এটি নিউরাল নেটওয়ার্কগুলির দ্বারা শেখা মডেলগুলির ক্ষেত্রেও প্রযোজ্য: কিছু প্রশিক্ষণের ডেটা এবং একটি নেটওয়ার্ক আর্কিটেকচারের ভিত্তিতে, একাধিক সেট ওজনের মান (একাধিক মডেল) রয়েছে যা ডেটা ব্যাখ্যা করতে পারে, এবং সহজ মডেলগুলি জটিলগুলির তুলনায় অতিরিক্ত ফিট হওয়ার সম্ভাবনা কম।
এই প্রসঙ্গে একটি "সাধারণ মডেল" হল একটি মডেল যেখানে প্যারামিটার মানগুলির বন্টন কম এনট্রপি থাকে (বা সম্পূর্ণভাবে কম প্যারামিটার সহ একটি মডেল, যেমনটি আমরা উপরের বিভাগে দেখেছি)। এইভাবে ওভারফিটিং প্রশমিত করার একটি সাধারণ উপায় হল একটি নেটওয়ার্কের জটিলতার উপর সীমাবদ্ধতা তৈরি করা যার ওজনকে শুধুমাত্র ছোট মান নিতে বাধ্য করা, যা ওজনের মানগুলির বন্টনকে আরও "নিয়মিত" করে তোলে। একে "ওজন নিয়মিতকরণ" বলা হয়, এবং এটি করা হয় নেটওয়ার্কের লস ফাংশনে বড় ওজনের সাথে যুক্ত একটি খরচ যোগ করে। এই খরচ দুটি স্বাদে আসে:
L1 নিয়মিতকরণ , যেখানে যোগ করা খরচ ওজন সহগগুলির পরম মানের সমানুপাতিক (অর্থাৎ যাকে ওজনের "L1 আদর্শ" বলা হয়)।
L2 নিয়মিতকরণ , যেখানে যোগ করা খরচ ওজন সহগগুলির মানের বর্গক্ষেত্রের সমানুপাতিক (অর্থাৎ যাকে ওজনের বর্গক্ষেত্র "L2 আদর্শ" বলা হয়)। L2 নিয়মিতকরণকে নিউরাল নেটওয়ার্কের পরিপ্রেক্ষিতে ওজন ক্ষয়ও বলা হয়। ভিন্ন নাম আপনাকে বিভ্রান্ত করতে দেবেন না: ওজন ক্ষয় গাণিতিকভাবে L2 নিয়মিতকরণের মতোই।
L1 নিয়মিতকরণ একটি স্পার্স মডেলকে উৎসাহিত করে ওজনকে ঠিক শূন্যের দিকে ঠেলে দেয়। L2 রেগুলারাইজেশন ওজনের প্যারামিটারগুলিকে স্পার্স না করে শাস্তি দেবে কারণ ছোট ওজনের জন্য জরিমানা শূন্য হয়ে যায়- L2 যে কারণে বেশি সাধারণ।
tf.keras এ, কীওয়ার্ড আর্গুমেন্ট হিসাবে স্তরগুলিতে ওজন নিয়মিতকরণের উদাহরণগুলি পাস করে ওজন নিয়মিতকরণ যোগ করা হয়। এখন L2 ওজন নিয়মিত যোগ করা যাক।
l2_model = tf.keras.Sequential([
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001),
input_shape=(FEATURES,)),
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(1)
])
regularizer_histories['l2'] = compile_and_fit(l2_model, "regularizers/l2")
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_14 (Dense) (None, 512) 14848
dense_15 (Dense) (None, 512) 262656
dense_16 (Dense) (None, 512) 262656
dense_17 (Dense) (None, 512) 262656
dense_18 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5126, binary_crossentropy:0.7481, loss:2.2415, val_accuracy:0.4950, val_binary_crossentropy:0.6707, val_loss:2.0653,
....................................................................................................
Epoch: 100, accuracy:0.6625, binary_crossentropy:0.5945, loss:0.6173, val_accuracy:0.6400, val_binary_crossentropy:0.5871, val_loss:0.6100,
....................................................................................................
Epoch: 200, accuracy:0.6690, binary_crossentropy:0.5864, loss:0.6079, val_accuracy:0.6650, val_binary_crossentropy:0.5856, val_loss:0.6076,
....................................................................................................
Epoch: 300, accuracy:0.6790, binary_crossentropy:0.5762, loss:0.5976, val_accuracy:0.6550, val_binary_crossentropy:0.5881, val_loss:0.6095,
....................................................................................................
Epoch: 400, accuracy:0.6843, binary_crossentropy:0.5697, loss:0.5920, val_accuracy:0.6650, val_binary_crossentropy:0.5878, val_loss:0.6101,
....................................................................................................
Epoch: 500, accuracy:0.6897, binary_crossentropy:0.5651, loss:0.5907, val_accuracy:0.6890, val_binary_crossentropy:0.5798, val_loss:0.6055,
....................................................................................................
Epoch: 600, accuracy:0.6945, binary_crossentropy:0.5610, loss:0.5864, val_accuracy:0.6820, val_binary_crossentropy:0.5772, val_loss:0.6026,
..........................................................
l2(0.001) মানে স্তরের ওজন ম্যাট্রিক্সের প্রতিটি সহগ নেটওয়ার্কের মোট ক্ষতির সাথে 0.001 * weight_coefficient_value**2 যোগ করবে।
তাই আমরা সরাসরি binary_crossentropy পর্যবেক্ষণ করছি। কারণ এটিতে এই নিয়মিতকরণের উপাদানটি মিশ্রিত নেই।
সুতরাং, L2 নিয়মিতকরণ জরিমানা সহ একই "Large" মডেলটি আরও ভাল পারফর্ম করে:
plotter.plot(regularizer_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
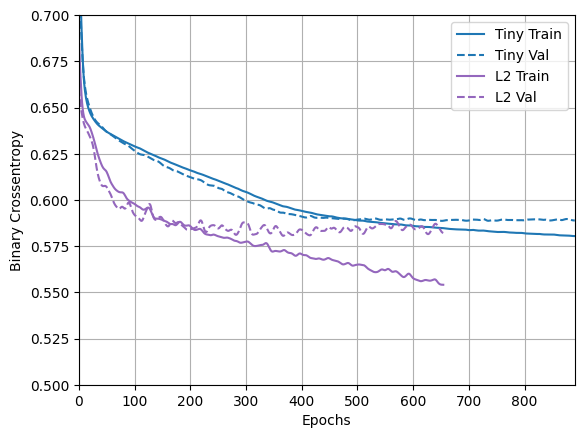
আপনি দেখতে পাচ্ছেন, "L2" নিয়মিত মডেলটি এখন "Tiny" মডেলের সাথে অনেক বেশি প্রতিযোগিতামূলক। এই "L2" মডেলটি একই সংখ্যক পরামিতি থাকা সত্ত্বেও "Large" মডেলের তুলনায় ওভারফিটিংয়ের জন্য অনেক বেশি প্রতিরোধী।
অধিক তথ্য
এই ধরণের নিয়মিতকরণ সম্পর্কে দুটি গুরুত্বপূর্ণ বিষয় লক্ষ্য করা যায়।
প্রথম: আপনি যদি নিজের প্রশিক্ষণ লুপ লিখছেন, তাহলে আপনাকে অবশ্যই মডেলটিকে তার নিয়মিতকরণের ক্ষতির জন্য জিজ্ঞাসা করতে হবে।
result = l2_model(features)
regularization_loss=tf.add_n(l2_model.losses)
দ্বিতীয়: এই বাস্তবায়ন মডেলের ক্ষতির জন্য ওজন জরিমানা যোগ করে এবং তারপরে একটি আদর্শ অপ্টিমাইজেশন পদ্ধতি প্রয়োগ করে কাজ করে।
একটি দ্বিতীয় পদ্ধতি রয়েছে যা পরিবর্তে শুধুমাত্র কাঁচা ক্ষতির উপর অপ্টিমাইজার চালায়, এবং তারপর গণনা করা পদক্ষেপটি প্রয়োগ করার সময় অপ্টিমাইজারটি কিছু ওজন ক্ষয়ও প্রয়োগ করে। এই "Decoupled Weight Decay" optimizers.FTRL এবং optimizers.AdamW এর মতো অপ্টিমাইজারগুলিতে দেখা যায়।
ড্রপআউট যোগ করুন
ড্রপআউট হল নিউরাল নেটওয়ার্কগুলির জন্য সবচেয়ে কার্যকর এবং সর্বাধিক ব্যবহৃত নিয়মিতকরণ কৌশলগুলির মধ্যে একটি, যা হিন্টন এবং টরন্টো বিশ্ববিদ্যালয়ের ছাত্রদের দ্বারা তৈরি করা হয়েছে৷
ড্রপআউটের স্বজ্ঞাত ব্যাখ্যা হল যে নেটওয়ার্কের পৃথক নোডগুলি অন্যের আউটপুটের উপর নির্ভর করতে পারে না, তাই প্রতিটি নোডকে অবশ্যই তাদের নিজস্ব উপযোগী বৈশিষ্ট্যগুলি আউটপুট করতে হবে।
ড্রপআউট, একটি স্তরে প্রয়োগ করা হয়, প্রশিক্ষণের সময় এলোমেলোভাবে "ড্রপ আউট" (অর্থাৎ শূন্যে সেট করা) স্তরটির বেশ কয়েকটি আউটপুট বৈশিষ্ট্য থাকে। ধরা যাক একটি প্রদত্ত স্তর প্রশিক্ষণের সময় প্রদত্ত ইনপুট নমুনার জন্য সাধারণত একটি ভেক্টর [0.2, 0.5, 1.3, 0.8, 1.1] ফেরত দেয়; ড্রপআউট প্রয়োগ করার পরে, এই ভেক্টরটিতে এলোমেলোভাবে বিতরণ করা কয়েকটি শূন্য এন্ট্রি থাকবে, যেমন [0, 0.5, 1.3, 0, 1.1]।
"ড্রপআউট রেট" হল সেই বৈশিষ্ট্যগুলির ভগ্নাংশ যা শূন্য করা হচ্ছে; এটি সাধারণত 0.2 এবং 0.5 এর মধ্যে সেট করা হয়। পরীক্ষার সময়, কোনো ইউনিট বাদ দেওয়া হয় না, এবং পরিবর্তে স্তরের আউটপুট মানগুলিকে ড্রপআউট হারের সমান একটি ফ্যাক্টর দ্বারা স্কেল করা হয়, যাতে প্রশিক্ষণের সময়ের চেয়ে বেশি ইউনিট সক্রিয় থাকে তার ভারসাম্য বজায় রাখতে।
tf.keras এ আপনি ড্রপআউট স্তরের মাধ্যমে নেটওয়ার্কে ড্রপআউট প্রবর্তন করতে পারেন, যা ঠিক আগে স্তরের আউটপুটে প্রয়োগ করা হয়।
আমাদের নেটওয়ার্কে দুটি ড্রপআউট স্তর যুক্ত করা যাক তারা ওভারফিটিং কমাতে কতটা ভাল করে তা দেখতে:
dropout_model = tf.keras.Sequential([
layers.Dense(512, activation='elu', input_shape=(FEATURES,)),
layers.Dropout(0.5),
layers.Dense(512, activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, activation='elu'),
layers.Dropout(0.5),
layers.Dense(1)
])
regularizer_histories['dropout'] = compile_and_fit(dropout_model, "regularizers/dropout")
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_19 (Dense) (None, 512) 14848
dropout (Dropout) (None, 512) 0
dense_20 (Dense) (None, 512) 262656
dropout_1 (Dropout) (None, 512) 0
dense_21 (Dense) (None, 512) 262656
dropout_2 (Dropout) (None, 512) 0
dense_22 (Dense) (None, 512) 262656
dropout_3 (Dropout) (None, 512) 0
dense_23 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.4961, binary_crossentropy:0.8110, loss:0.8110, val_accuracy:0.5330, val_binary_crossentropy:0.6900, val_loss:0.6900,
....................................................................................................
Epoch: 100, accuracy:0.6557, binary_crossentropy:0.5961, loss:0.5961, val_accuracy:0.6710, val_binary_crossentropy:0.5788, val_loss:0.5788,
....................................................................................................
Epoch: 200, accuracy:0.6871, binary_crossentropy:0.5622, loss:0.5622, val_accuracy:0.6860, val_binary_crossentropy:0.5856, val_loss:0.5856,
....................................................................................................
Epoch: 300, accuracy:0.7246, binary_crossentropy:0.5121, loss:0.5121, val_accuracy:0.6820, val_binary_crossentropy:0.5927, val_loss:0.5927,
............
plotter.plot(regularizer_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
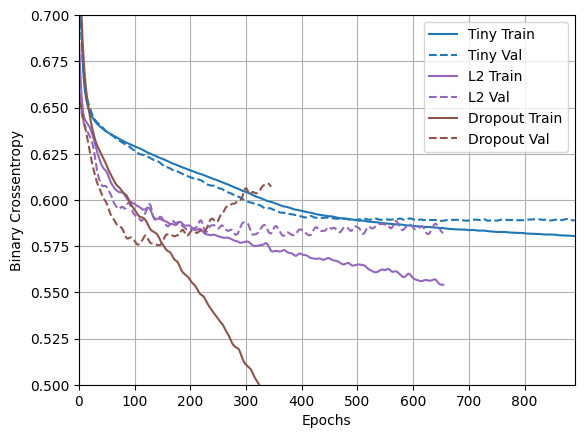
এই প্লট থেকে এটা স্পষ্ট যে এই দুটি নিয়মিতকরণ পদ্ধতিই "Large" মডেলের আচরণকে উন্নত করে। কিন্তু এটি এখনও "Tiny" বেসলাইনকে হারাতে পারে না।
পরবর্তীতে তাদের উভয়কে একসাথে চেষ্টা করুন এবং দেখুন এটি আরও ভাল করে কিনা।
সম্মিলিত L2 + ড্রপআউট
combined_model = tf.keras.Sequential([
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu', input_shape=(FEATURES,)),
layers.Dropout(0.5),
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu'),
layers.Dropout(0.5),
layers.Dense(1)
])
regularizer_histories['combined'] = compile_and_fit(combined_model, "regularizers/combined")
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_24 (Dense) (None, 512) 14848
dropout_4 (Dropout) (None, 512) 0
dense_25 (Dense) (None, 512) 262656
dropout_5 (Dropout) (None, 512) 0
dense_26 (Dense) (None, 512) 262656
dropout_6 (Dropout) (None, 512) 0
dense_27 (Dense) (None, 512) 262656
dropout_7 (Dropout) (None, 512) 0
dense_28 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5090, binary_crossentropy:0.8064, loss:0.9648, val_accuracy:0.4660, val_binary_crossentropy:0.6877, val_loss:0.8454,
....................................................................................................
Epoch: 100, accuracy:0.6445, binary_crossentropy:0.6050, loss:0.6350, val_accuracy:0.6630, val_binary_crossentropy:0.5871, val_loss:0.6169,
....................................................................................................
Epoch: 200, accuracy:0.6660, binary_crossentropy:0.5932, loss:0.6186, val_accuracy:0.6880, val_binary_crossentropy:0.5722, val_loss:0.5975,
....................................................................................................
Epoch: 300, accuracy:0.6697, binary_crossentropy:0.5818, loss:0.6100, val_accuracy:0.6900, val_binary_crossentropy:0.5614, val_loss:0.5895,
....................................................................................................
Epoch: 400, accuracy:0.6749, binary_crossentropy:0.5742, loss:0.6046, val_accuracy:0.6870, val_binary_crossentropy:0.5576, val_loss:0.5881,
....................................................................................................
Epoch: 500, accuracy:0.6854, binary_crossentropy:0.5703, loss:0.6029, val_accuracy:0.6970, val_binary_crossentropy:0.5458, val_loss:0.5784,
....................................................................................................
Epoch: 600, accuracy:0.6806, binary_crossentropy:0.5673, loss:0.6015, val_accuracy:0.6980, val_binary_crossentropy:0.5453, val_loss:0.5795,
....................................................................................................
Epoch: 700, accuracy:0.6937, binary_crossentropy:0.5583, loss:0.5938, val_accuracy:0.6870, val_binary_crossentropy:0.5477, val_loss:0.5832,
....................................................................................................
Epoch: 800, accuracy:0.6911, binary_crossentropy:0.5576, loss:0.5947, val_accuracy:0.7000, val_binary_crossentropy:0.5446, val_loss:0.5817,
.......................
plotter.plot(regularizer_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
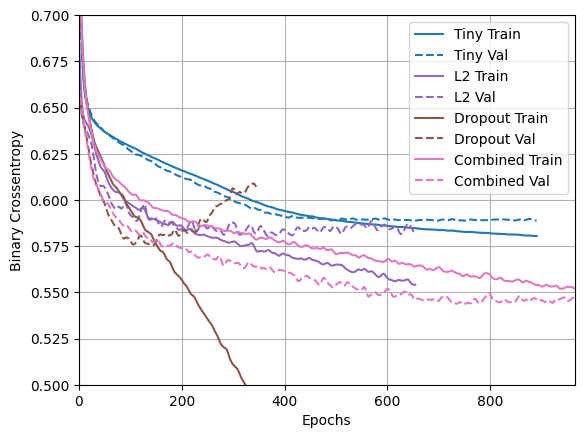
"Combined" নিয়মিতকরণ সহ এই মডেলটি স্পষ্টতই এখন পর্যন্ত সেরা।
টেনসরবোর্ডে দেখুন
এই মডেলগুলি টেনসরবোর্ড লগগুলিও রেকর্ড করেছে৷
একটি নোটবুকের ভিতরে একটি এমবেডেড টেনসরবোর্ড ভিউয়ার খুলতে, একটি কোড-সেলে নিম্নলিখিতটি অনুলিপি করুন:
%tensorboard --logdir {logdir}/regularizers
আপনি TensorDoard.dev- এ এই নোটবুকের আগের রানের ফলাফল দেখতে পারেন।
এটি সুবিধার জন্য একটি <iframe> -এও অন্তর্ভুক্ত:
display.IFrame(
src="https://tensorboard.dev/experiment/fGInKDo8TXes1z7HQku9mw/#scalars&_smoothingWeight=0.97",
width = "100%",
height="800px")
এটি এর সাথে আপলোড করা হয়েছিল:
tensorboard dev upload --logdir {logdir}/regularizers
উপসংহার
রিক্যাপ করার জন্য: এখানে নিউরাল নেটওয়ার্কে ওভারফিটিং প্রতিরোধ করার সবচেয়ে সাধারণ উপায় রয়েছে:
- আরো প্রশিক্ষণ তথ্য পান.
- নেটওয়ার্কের ক্ষমতা হ্রাস করুন।
- ওজন নিয়মিতকরণ যোগ করুন।
- ড্রপআউট যোগ করুন।
দুটি গুরুত্বপূর্ণ পন্থা এই নির্দেশিকায় অন্তর্ভুক্ত নয়:
- তথ্য-বর্ধন
- ব্যাচ স্বাভাবিকীকরণ
মনে রাখবেন যে প্রতিটি পদ্ধতি নিজেই সাহায্য করতে পারে, তবে প্রায়শই তাদের একত্রিত করা আরও কার্যকর হতে পারে।
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.