
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
একটি রিগ্রেশন সমস্যায়, লক্ষ্য হল একটি ক্রমাগত মানের আউটপুট, যেমন একটি মূল্য বা সম্ভাব্যতার পূর্বাভাস। এটিকে একটি শ্রেণিবিন্যাসের সমস্যার সাথে তুলনা করুন, যেখানে লক্ষ্য হল শ্রেণির তালিকা থেকে একটি শ্রেণি নির্বাচন করা (উদাহরণস্বরূপ, যেখানে একটি ছবিতে একটি আপেল বা একটি কমলা রয়েছে, ছবিতে কোন ফলটি রয়েছে তা সনাক্ত করা)।
এই টিউটোরিয়ালটি ক্লাসিক অটো MPG ডেটাসেট ব্যবহার করে এবং 1970-এর দশকের শেষের দিকে এবং 1980-এর দশকের প্রথম দিকের অটোমোবাইলগুলির জ্বালানী দক্ষতার পূর্বাভাস দেওয়ার জন্য মডেলগুলি কীভাবে তৈরি করতে হয় তা প্রদর্শন করে৷ এটি করার জন্য, আপনি সেই সময়ের থেকে অনেক অটোমোবাইলের বিবরণ সহ মডেলগুলি প্রদান করবেন। এই বিবরণে সিলিন্ডার, স্থানচ্যুতি, অশ্বশক্তি এবং ওজনের মতো বৈশিষ্ট্যগুলি অন্তর্ভুক্ত রয়েছে।
এই উদাহরণটি Keras API ব্যবহার করে। (আরো জানতে কেরাস টিউটোরিয়াল এবং গাইড দেখুন।)
# Use seaborn for pairplot.pip install -q seaborn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# Make NumPy printouts easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
2.8.0-rc1
অটো MPG ডেটাসেট
ডেটাসেটটি UCI মেশিন লার্নিং রিপোজিটরি থেকে পাওয়া যায়।
ডেটা পান
প্রথমে পান্ডা ব্যবহার করে ডেটাসেট ডাউনলোড এবং আমদানি করুন:
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()
ডেটা পরিষ্কার করুন
ডেটাসেটে কয়েকটি অজানা মান রয়েছে:
dataset.isna().sum()
MPG 0 Cylinders 0 Displacement 0 Horsepower 6 Weight 0 Acceleration 0 Model Year 0 Origin 0 dtype: int64
এই প্রাথমিক টিউটোরিয়ালটিকে সহজ রাখতে সেই সারিগুলি বাদ দিন:
dataset = dataset.dropna()
"Origin" কলামটি শ্রেণীবদ্ধ, সংখ্যাসূচক নয়। তাই পরবর্তী ধাপ হল pd.get_dummies এর সাথে কলামের মানগুলিকে এক-হট এনকোড করা।
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, columns=['Origin'], prefix='', prefix_sep='')
dataset.tail()
প্রশিক্ষণ এবং পরীক্ষার সেটে ডেটা বিভক্ত করুন
এখন, ডেটাসেটটিকে একটি প্রশিক্ষণ সেট এবং একটি পরীক্ষা সেটে বিভক্ত করুন। আপনি আপনার মডেলের চূড়ান্ত মূল্যায়নে পরীক্ষার সেট ব্যবহার করবেন।
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
ডেটা পরিদর্শন করুন
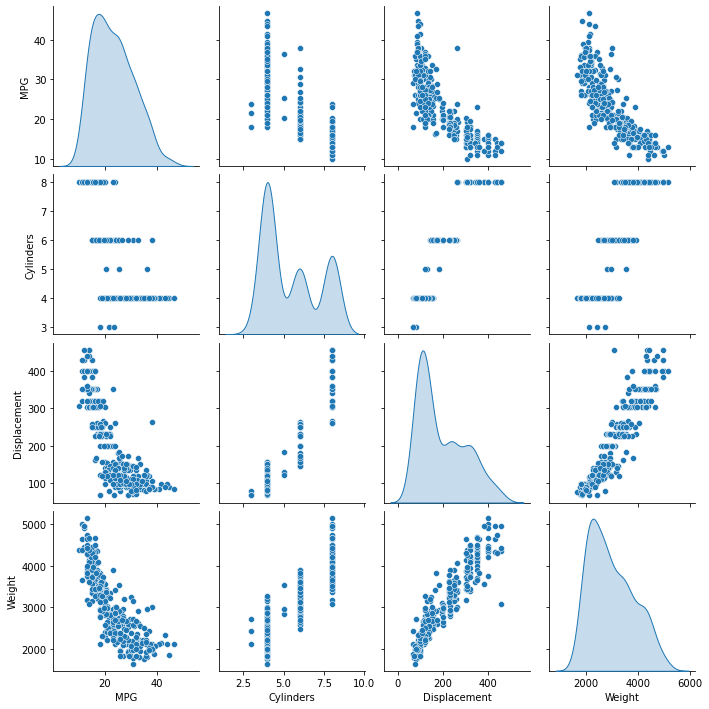
প্রশিক্ষণ সেট থেকে কয়েক জোড়া কলামের যৌথ বিতরণ পর্যালোচনা করুন।
উপরের সারিটি পরামর্শ দেয় যে জ্বালানী দক্ষতা (MPG) হল অন্য সমস্ত প্যারামিটারের একটি ফাংশন। অন্যান্য সারিগুলি নির্দেশ করে যে তারা একে অপরের ফাংশন।
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
<seaborn.axisgrid.PairGrid at 0x7f6bfdae9850>
এর সামগ্রিক পরিসংখ্যানও পরীক্ষা করা যাক। নোট করুন কিভাবে প্রতিটি বৈশিষ্ট্য একটি খুব ভিন্ন পরিসর কভার করে:
train_dataset.describe().transpose()
লেবেল থেকে বৈশিষ্ট্য বিভক্ত
বৈশিষ্ট্যগুলি থেকে লক্ষ্য মান - "লেবেল" - আলাদা করুন৷ এই লেবেলটি সেই মান যা আপনি মডেলটিকে ভবিষ্যদ্বাণী করতে প্রশিক্ষণ দেবেন।
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('MPG')
test_labels = test_features.pop('MPG')
স্বাভাবিককরণ
পরিসংখ্যানের সারণীতে প্রতিটি বৈশিষ্ট্যের পরিসর কতটা আলাদা তা দেখা সহজ:
train_dataset.describe().transpose()[['mean', 'std']]
বিভিন্ন স্কেল এবং রেঞ্জ ব্যবহার করে এমন বৈশিষ্ট্যগুলিকে স্বাভাবিক করার জন্য এটি ভাল অনুশীলন।
এটি গুরুত্বপূর্ণ একটি কারণ হল বৈশিষ্ট্যগুলি মডেলের ওজন দ্বারা গুণিত হয়৷ সুতরাং, আউটপুটগুলির স্কেল এবং গ্রেডিয়েন্টের স্কেল ইনপুটগুলির স্কেল দ্বারা প্রভাবিত হয়।
যদিও একটি মডেল বৈশিষ্ট্য স্বাভাবিককরণ ছাড়া একত্রিত হতে পারে , স্বাভাবিককরণ প্রশিক্ষণকে অনেক বেশি স্থিতিশীল করে তোলে।
স্বাভাবিককরণ স্তর
tf.keras.layers.Normalization হল আপনার মডেলে বৈশিষ্ট্য স্বাভাবিককরণ যোগ করার একটি পরিষ্কার এবং সহজ উপায়।
প্রথম ধাপ হল স্তর তৈরি করা:
normalizer = tf.keras.layers.Normalization(axis=-1)
তারপর, Normalization.adapt কল করে ডেটাতে প্রিপ্রসেসিং লেয়ারের অবস্থা ফিট করুন:
normalizer.adapt(np.array(train_features))
গড় এবং প্রকরণ গণনা করুন, এবং তাদের স্তরে সংরক্ষণ করুন:
print(normalizer.mean.numpy())
[[ 5.478 195.318 104.869 2990.252 15.559 75.898 0.178 0.197
0.624]]
যখন স্তরটিকে কল করা হয়, এটি প্রতিটি বৈশিষ্ট্য স্বাধীনভাবে স্বাভাবিক করার সাথে ইনপুট ডেটা ফেরত দেয়:
first = np.array(train_features[:1])
with np.printoptions(precision=2, suppress=True):
print('First example:', first)
print()
print('Normalized:', normalizer(first).numpy())
First example: [[ 4. 90. 75. 2125. 14.5 74. 0. 0. 1. ]] Normalized: [[-0.87 -1.01 -0.79 -1.03 -0.38 -0.52 -0.47 -0.5 0.78]]
লিনিয়ার রিগ্রেশন
একটি গভীর নিউরাল নেটওয়ার্ক মডেল তৈরি করার আগে, এক এবং একাধিক ভেরিয়েবল ব্যবহার করে লিনিয়ার রিগ্রেশন দিয়ে শুরু করুন।
একটি পরিবর্তনশীল সহ রৈখিক রিগ্রেশন
'Horsepower' থেকে 'MPG' ভবিষ্যদ্বাণী করতে একটি একক-ভেরিয়েবল লিনিয়ার রিগ্রেশন দিয়ে শুরু করুন।
tf.keras সহ একটি মডেলের প্রশিক্ষণ সাধারণত মডেল আর্কিটেকচার সংজ্ঞায়িত করে শুরু হয়। একটি tf.keras.Sequential মডেল ব্যবহার করুন, যা ধাপগুলির একটি ক্রম প্রতিনিধিত্ব করে ।
আপনার একক-ভেরিয়েবল লিনিয়ার রিগ্রেশন মডেলে দুটি ধাপ রয়েছে:
-
tf.keras.layers.Normalizationpreprocessing লেয়ার ব্যবহার করে'Horsepower'ইনপুট বৈশিষ্ট্যগুলিকে স্বাভাবিক করুন। - একটি লিনিয়ার লেয়ার (
tf.keras.layers.Dense) ব্যবহার করে 1টি আউটপুট তৈরি করতে একটি লিনিয়ার ট্রান্সফর্মেশন (\(y = mx+b\)) প্রয়োগ করুন।
ইনপুট সংখ্যা হয় input_shape আর্গুমেন্ট দ্বারা সেট করা যেতে পারে, অথবা স্বয়ংক্রিয়ভাবে যখন মডেলটি প্রথমবার চালানো হয়।
প্রথমে, 'Horsepower' বৈশিষ্ট্য দিয়ে তৈরি একটি NumPy অ্যারে তৈরি করুন। তারপর, tf.keras.layers.Normalization instantiate করুন এবং horsepower ডেটার সাথে এর অবস্থা ফিট করুন:
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = layers.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)
কেরাস অনুক্রমিক মডেল তৈরি করুন:
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])
horsepower_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense (Dense) (None, 1) 2
=================================================================
Total params: 5
Trainable params: 2
Non-trainable params: 3
_________________________________________________________________
এই মডেলটি 'Horsepower' থেকে 'MPG' ভবিষ্যদ্বাণী করবে।
প্রথম 10টি 'হর্সপাওয়ার' মানগুলিতে অপ্রশিক্ষিত মডেলটি চালান। আউটপুট ভাল হবে না, তবে লক্ষ্য করুন যে এটির প্রত্যাশিত আকার রয়েছে (10, 1) :
horsepower_model.predict(horsepower[:10])
array([[-1.186],
[-0.67 ],
[ 2.189],
[-1.662],
[-1.504],
[-0.59 ],
[-1.782],
[-1.504],
[-0.392],
[-0.67 ]], dtype=float32)
মডেলটি তৈরি হয়ে গেলে, Model.compile পদ্ধতি ব্যবহার করে প্রশিক্ষণ পদ্ধতি কনফিগার করুন। কম্পাইল করার জন্য সবচেয়ে গুরুত্বপূর্ণ আর্গুমেন্ট হল loss এবং optimizer , যেহেতু এগুলি নির্ধারণ করে কী অপ্টিমাইজ করা হবে ( mean_absolute_error ) এবং কীভাবে ( tf.keras.optimizers.Adam ব্যবহার করে)।
horsepower_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
100টি যুগের জন্য প্রশিক্ষণ কার্যকর করতে Model.fit ব্যবহার করুন:
%%time
history = horsepower_model.fit(
train_features['Horsepower'],
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.79 s, sys: 797 ms, total: 5.59 s Wall time: 3.8 s
history অবজেক্টে সঞ্চিত পরিসংখ্যান ব্যবহার করে মডেলের প্রশিক্ষণের অগ্রগতি কল্পনা করুন:
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, 10])
plt.xlabel('Epoch')
plt.ylabel('Error [MPG]')
plt.legend()
plt.grid(True)
plot_loss(history)

পরের জন্য পরীক্ষার সেটে ফলাফল সংগ্রহ করুন:
test_results = {}
test_results['horsepower_model'] = horsepower_model.evaluate(
test_features['Horsepower'],
test_labels, verbose=0)
যেহেতু এটি একটি একক পরিবর্তনশীল রিগ্রেশন, তাই ইনপুটের একটি ফাংশন হিসাবে মডেলের ভবিষ্যদ্বাণীগুলি দেখতে সহজ:
x = tf.linspace(0.0, 250, 251)
y = horsepower_model.predict(x)
def plot_horsepower(x, y):
plt.scatter(train_features['Horsepower'], train_labels, label='Data')
plt.plot(x, y, color='k', label='Predictions')
plt.xlabel('Horsepower')
plt.ylabel('MPG')
plt.legend()
plot_horsepower(x, y)

একাধিক ইনপুট সহ লিনিয়ার রিগ্রেশন
আপনি একাধিক ইনপুটের উপর ভিত্তি করে ভবিষ্যদ্বাণী করতে প্রায় অভিন্ন সেটআপ ব্যবহার করতে পারেন। এই মডেলটি এখনও একই \(y = mx+b\) করে \(m\) একটি ম্যাট্রিক্স এবং \(b\) একটি ভেক্টর।
প্রথম স্তরটি normalizer ( tf.keras.layers.Normalization(axis=-1) ) দিয়ে আবার একটি দ্বি-পদক্ষেপ কেরাস সিকোয়েন্সিয়াল মডেল তৈরি করুন যা আপনি আগে সংজ্ঞায়িত করেছেন এবং পুরো ডেটাসেটের সাথে মানিয়ে নিয়েছেন:
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
আপনি যখন ইনপুটগুলির একটি ব্যাচে Model.predict কল করেন, এটি প্রতিটি উদাহরণের জন্য units=1 আউটপুট তৈরি করে:
linear_model.predict(train_features[:10])
array([[ 0.441],
[ 1.522],
[ 0.188],
[ 1.169],
[ 0.058],
[ 0.965],
[ 0.034],
[-0.674],
[ 0.437],
[-0.37 ]], dtype=float32)
আপনি যখন মডেলটিকে কল করবেন, তখন এর ওজন ম্যাট্রিক্স তৈরি করা হবে-চেক করুন যে kernel ওজন ( \(m\) এ \(y=mx+b\)) এর আকৃতি রয়েছে (9, 1) :
linear_model.layers[1].kernel
<tf.Variable 'dense_1/kernel:0' shape=(9, 1) dtype=float32, numpy=
array([[-0.702],
[ 0.307],
[ 0.114],
[ 0.233],
[ 0.244],
[ 0.322],
[-0.725],
[-0.151],
[ 0.407]], dtype=float32)>
Model.compile দিয়ে মডেলটি কনফিগার করুন এবং 100টি যুগের জন্য Model.fit এর সাথে ট্রেন করুন:
linear_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
%%time
history = linear_model.fit(
train_features,
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.89 s, sys: 740 ms, total: 5.63 s Wall time: 3.75 s
এই রিগ্রেশন মডেলের সমস্ত ইনপুট ব্যবহার করে horsepower_model তুলনায় অনেক কম প্রশিক্ষণ এবং বৈধতা ত্রুটি অর্জন করে, যার একটি ইনপুট ছিল:
plot_loss(history)

পরের জন্য পরীক্ষার সেটে ফলাফল সংগ্রহ করুন:
test_results['linear_model'] = linear_model.evaluate(
test_features, test_labels, verbose=0)
একটি গভীর নিউরাল নেটওয়ার্কের সাথে রিগ্রেশন (DNN)
পূর্ববর্তী বিভাগে, আপনি একক এবং একাধিক ইনপুটের জন্য দুটি লিনিয়ার মডেল প্রয়োগ করেছেন।
এখানে, আপনি একক-ইনপুট এবং একাধিক-ইনপুট DNN মডেলগুলি বাস্তবায়ন করবেন।
কিছু "লুকানো" অ-রৈখিক স্তর অন্তর্ভুক্ত করার জন্য মডেলটি প্রসারিত করা ছাড়া কোডটি মূলত একই। এখানে "লুকানো" নামটির অর্থ সরাসরি ইনপুট বা আউটপুটগুলির সাথে সংযুক্ত নয়৷
এই মডেলগুলিতে লিনিয়ার মডেলের চেয়ে আরও কয়েকটি স্তর থাকবে:
- স্বাভাবিকীকরণ স্তর, আগের মতো (একটি-ইনপুট মডেলের জন্য
horsepower_normalizerএবং একাধিক-ইনপুট মডেলের জন্যnormalizerসহ)। - ReLU (
relu) সক্রিয়করণ ফাংশন নন-লিনিয়ারিটির সাথে দুটি লুকানো, নন-লিনিয়ার,Denseস্তর। - একটি রৈখিক
Denseএকক-আউটপুট স্তর।
উভয় মডেল একই প্রশিক্ষণ পদ্ধতি ব্যবহার করবে যাতে compile পদ্ধতিটি নীচের build_and_compile_model ফাংশনে অন্তর্ভুক্ত করা হয়।
def build_and_compile_model(norm):
model = keras.Sequential([
norm,
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
model.compile(loss='mean_absolute_error',
optimizer=tf.keras.optimizers.Adam(0.001))
return model
একটি DNN এবং একটি একক ইনপুট ব্যবহার করে রিগ্রেশন
ইনপুট হিসাবে শুধুমাত্র 'Horsepower' এবং স্বাভাবিককরণ স্তর হিসাবে horsepower_normalizer (আগে সংজ্ঞায়িত) সহ একটি DNN মডেল তৈরি করুন:
dnn_horsepower_model = build_and_compile_model(horsepower_normalizer)
এই মডেলটিতে রৈখিক মডেলের তুলনায় বেশ কয়েকটি বেশি প্রশিক্ষণযোগ্য পরামিতি রয়েছে:
dnn_horsepower_model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense_2 (Dense) (None, 64) 128
dense_3 (Dense) (None, 64) 4160
dense_4 (Dense) (None, 1) 65
=================================================================
Total params: 4,356
Trainable params: 4,353
Non-trainable params: 3
_________________________________________________________________
Model.fit এর সাথে মডেলকে প্রশিক্ষণ দিন:
%%time
history = dnn_horsepower_model.fit(
train_features['Horsepower'],
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.07 s, sys: 691 ms, total: 5.76 s Wall time: 3.92 s
এই মডেলটি রৈখিক একক-ইনপুট horsepower_model চেয়ে কিছুটা ভালো করে:
plot_loss(history)

আপনি যদি ভবিষ্যদ্বাণীগুলিকে 'Horsepower' এর একটি ফাংশন হিসাবে প্লট করেন, তাহলে আপনার লক্ষ্য করা উচিত যে এই মডেলটি লুকানো স্তরগুলির দ্বারা প্রদত্ত অরৈখিকতার সুবিধা নেয়:
x = tf.linspace(0.0, 250, 251)
y = dnn_horsepower_model.predict(x)
plot_horsepower(x, y)

পরের জন্য পরীক্ষার সেটে ফলাফল সংগ্রহ করুন:
test_results['dnn_horsepower_model'] = dnn_horsepower_model.evaluate(
test_features['Horsepower'], test_labels,
verbose=0)
একটি DNN এবং একাধিক ইনপুট ব্যবহার করে রিগ্রেশন
সমস্ত ইনপুট ব্যবহার করে আগের প্রক্রিয়াটি পুনরাবৃত্তি করুন। মডেলের কার্যকারিতা বৈধকরণ ডেটাসেটে সামান্য উন্নতি করে।
dnn_model = build_and_compile_model(normalizer)
dnn_model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization (Normalizatio (None, 9) 19
n)
dense_5 (Dense) (None, 64) 640
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 1) 65
=================================================================
Total params: 4,884
Trainable params: 4,865
Non-trainable params: 19
_________________________________________________________________
%%time
history = dnn_model.fit(
train_features,
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.08 s, sys: 725 ms, total: 5.8 s Wall time: 3.94 s
plot_loss(history)

পরীক্ষার সেটে ফলাফল সংগ্রহ করুন:
test_results['dnn_model'] = dnn_model.evaluate(test_features, test_labels, verbose=0)
কর্মক্ষমতা
যেহেতু সমস্ত মডেলকে প্রশিক্ষিত করা হয়েছে, আপনি তাদের পরীক্ষা সেটের কার্যকারিতা পর্যালোচনা করতে পারেন:
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
এই ফলাফলগুলি প্রশিক্ষণের সময় পর্যবেক্ষণ করা বৈধতা ত্রুটির সাথে মেলে।
ভবিষৎবাণী কর
আপনি এখন Keras Model.predict ব্যবহার করে পরীক্ষা সেটে dnn_model দিয়ে ভবিষ্যদ্বাণী করতে পারেন এবং ক্ষতি পর্যালোচনা করতে পারেন:
test_predictions = dnn_model.predict(test_features).flatten()
a = plt.axes(aspect='equal')
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
lims = [0, 50]
plt.xlim(lims)
plt.ylim(lims)
_ = plt.plot(lims, lims)
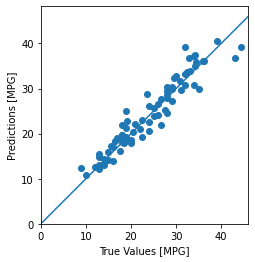
এটি প্রদর্শিত হয় যে মডেল যুক্তিসঙ্গতভাবে ভাল ভবিষ্যদ্বাণী.
এখন, ত্রুটি বিতরণ পরীক্ষা করুন:
error = test_predictions - test_labels
plt.hist(error, bins=25)
plt.xlabel('Prediction Error [MPG]')
_ = plt.ylabel('Count')
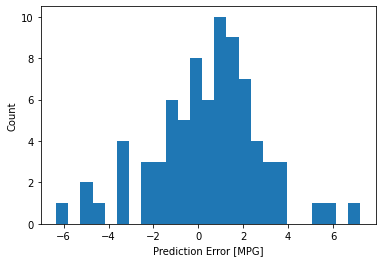
আপনি যদি মডেলটির সাথে খুশি হন তবে Model.save সাথে পরবর্তী ব্যবহারের জন্য এটি সংরক্ষণ করুন:
dnn_model.save('dnn_model')
2022-01-26 07:26:13.372245: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: dnn_model/assets
আপনি যদি মডেলটি পুনরায় লোড করেন তবে এটি অভিন্ন আউটপুট দেয়:
reloaded = tf.keras.models.load_model('dnn_model')
test_results['reloaded'] = reloaded.evaluate(
test_features, test_labels, verbose=0)
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
উপসংহার
এই নোটবুক একটি রিগ্রেশন সমস্যা পরিচালনা করার জন্য কয়েকটি কৌশল চালু করেছে। এখানে আরও কিছু টিপস রয়েছে যা সাহায্য করতে পারে:
- গড় বর্গক্ষেত্র ত্রুটি (MSE) (
tf.losses.MeanSquaredError) এবং গড় পরম ত্রুটি (MAE) (tf.losses.MeanAbsoluteError) হল রিগ্রেশন সমস্যার জন্য ব্যবহৃত সাধারণ ক্ষতি ফাংশন। MAE বহিরাগতদের প্রতি কম সংবেদনশীল। শ্রেণীবিন্যাস সমস্যার জন্য বিভিন্ন ক্ষতি ফাংশন ব্যবহার করা হয়। - একইভাবে, রিগ্রেশনের জন্য ব্যবহৃত মূল্যায়ন মেট্রিক্স শ্রেণীবিভাগ থেকে পৃথক।
- যখন সাংখ্যিক ইনপুট ডেটা বৈশিষ্ট্যগুলির বিভিন্ন পরিসরের মান থাকে, তখন প্রতিটি বৈশিষ্ট্যকে একই পরিসরে স্বাধীনভাবে স্কেল করা উচিত।
- ডিএনএন মডেলগুলির জন্য ওভারফিটিং একটি সাধারণ সমস্যা, যদিও এই টিউটোরিয়ালের জন্য এটি কোনও সমস্যা ছিল না। এই বিষয়ে আরও সাহায্যের জন্য ওভারফিট এবং আন্ডারফিট টিউটোরিয়াল দেখুন।
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.