
| | |  Lihat di GitHub Lihat di GitHub | |
CoLab ini adalah demonstrasi menggunakan Tensorflow Hub untuk klasifikasi teks dalam non-Inggris / bahasa lokal. Di sini kita memilih Bangla sebagai bahasa lokal dan menggunakan pretrained embeddings kata untuk memecahkan klasifikasi tugas yang multi mana kita mengklasifikasikan Bangla artikel berita di 5 kategori. Embeddings The pretrained untuk Bangla berasal dari fastText yang merupakan perpustakaan oleh Facebook dengan merilis vektor kata pretrained untuk 157 bahasa.
Kami akan menggunakan eksportir embedding pretrained TF-Hub untuk mengubah embeddings kata untuk modul teks embedding pertama dan kemudian menggunakan modul untuk melatih classifier dengan tf.keras , tingkat tinggi user friendly API Tensorflow untuk membangun model pembelajaran yang mendalam. Meskipun kami menggunakan penyematan fastText di sini, penyematan lain yang telah dilatih sebelumnya dari tugas lain dapat dilakukan dan dengan cepat mendapatkan hasil dengan hub Tensorflow.
Mempersiapkan
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
Himpunan data
Kami akan menggunakan Bard (Bangla Pasal Dataset) yang memiliki sekitar 376.226 artikel yang dikumpulkan dari portal berita yang berbeda Bangla dan diberi label dengan 5 kategori: ekonomi, negara, internasional, olahraga, dan hiburan. Kami men-download file dari Google Drive ini ( bit.ly/BARD_DATASET ) link mengacu dari ini repositori GitHub.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
Ekspor vektor kata yang telah dilatih sebelumnya ke modul TF-Hub
TF-Hub menyediakan beberapa script yang berguna untuk mengkonversi embeddings kata untuk TF-hub modul embedding teks di sini . Untuk membuat modul untuk Bangla atau bahasa lainnya, kita hanya perlu men-download kata embedding .txt atau .vec file ke direktori yang sama dengan export_v2.py dan menjalankan script.
Eksportir membaca vektor embedding dan ekspor ke sebuah Tensorflow SavedModel . SavedModel berisi program TensorFlow lengkap termasuk bobot dan grafik. TF-Hub dapat memuat SavedModel sebagai modul , yang akan kita gunakan untuk membangun model untuk klasifikasi teks. Karena kita menggunakan tf.keras untuk membangun model, kita akan menggunakan hub.KerasLayer , yang menyediakan pembungkus untuk modul TF-Hub untuk digunakan sebagai lapisan Keras.
Pertama kita akan mendapatkan embeddings kata kami dari fastText dan eksportir embedding dari TF-Hub repo .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
Kemudian, kita akan menjalankan skrip eksportir pada file embedding kita. Karena penyematan fastText memiliki baris header dan cukup besar (sekitar 3,3 GB untuk Bangla setelah mengonversi ke modul), kami mengabaikan baris pertama dan mengekspor hanya 100.000 token pertama ke modul penyematan teks.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
Modul penyematan teks mengambil sekumpulan kalimat dalam tensor string 1D sebagai input dan mengeluarkan vektor penyematan bentuk (batch_size, embedding_dim) yang sesuai dengan kalimat. Ini memroses input dengan memisahkan spasi. Embeddings kata dikombinasikan untuk embeddings kalimat dengan sqrtn combiner (Lihat di sini ). Untuk demonstrasi kami memberikan daftar kata-kata Bangla sebagai masukan dan mendapatkan vektor embedding yang sesuai.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
Konversikan ke Kumpulan Data Tensorflow
Karena dataset ini benar-benar besar bukannya memuat seluruh dataset dalam memori kita akan menggunakan generator untuk menghasilkan sampel dalam run-time dalam batch menggunakan Tensorflow Dataset fungsi. Datasetnya juga sangat tidak seimbang, jadi sebelum menggunakan generator, kita akan mengocok dataset tersebut.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
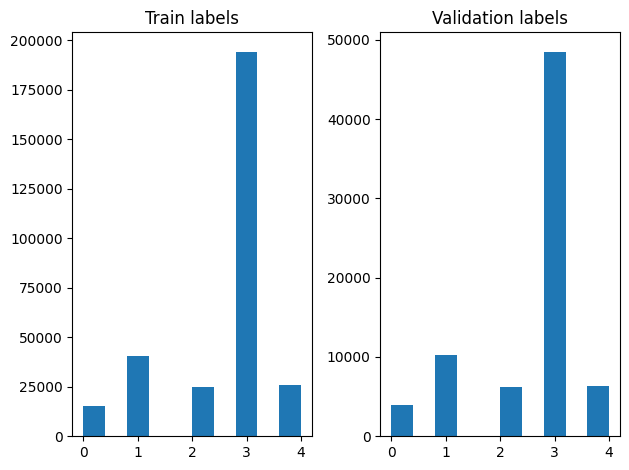
Kami dapat memeriksa distribusi label dalam contoh pelatihan dan validasi setelah pengacakan.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
Untuk membuat Dataset menggunakan generator, pertama kita menulis fungsi generator yang berbunyi setiap artikel dari file_paths dan label dari array label, dan hasil satu pelatihan contoh pada setiap langkah. Kami melewati fungsi generator ini ke tf.data.Dataset.from_generator metode dan menentukan jenis output. Setiap contoh pelatihan adalah tuple yang berisi sebuah artikel dari tf.string tipe data dan satu-panas label dikodekan. Kami membagi dataset dengan split kereta-validasi dari 80-20 menggunakan tf.data.Dataset.skip dan tf.data.Dataset.take metode.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
Pelatihan dan Evaluasi Model
Karena kita telah menambahkan pembungkus sekitar modul kami untuk menggunakannya sebagai salah lapisan lainnya di Keras, kita dapat membuat kecil Sequential Model yang merupakan tumpukan linear lapisan. Kita bisa menambahkan teks kami embedding modul dengan model.add sama seperti lapisan lainnya. Kami mengkompilasi model dengan menentukan kerugian dan pengoptimal dan melatihnya selama 10 epoch. The tf.keras API dapat menangani Tensorflow dataset sebagai masukan, sehingga kami dapat melewati contoh Dataset dengan metode cocok untuk model pelatihan. Karena kita menggunakan generator fungsi, tf.data akan menangani menghasilkan sampel, batching mereka dan memberi mereka makan untuk model.
Model
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
Pelatihan
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
Evaluasi
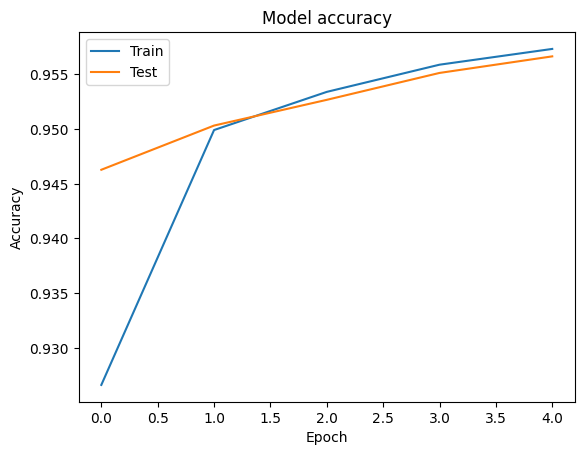
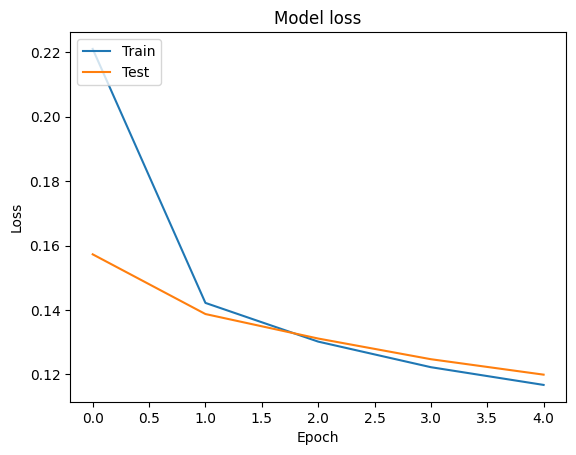
Kita bisa memvisualisasikan akurasi dan kehilangan kurva untuk data pelatihan dan validasi menggunakan tf.keras.callbacks.History objek dikembalikan oleh tf.keras.Model.fit metode, yang berisi kerugian dan akurasi nilai untuk setiap zaman.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
Ramalan
Kita bisa mendapatkan prediksi untuk data validasi dan memeriksa matriks kebingungan untuk melihat kinerja model untuk masing-masing dari 5 kelas. Karena tf.keras.Model.predict metode mengembalikan array nd untuk probabilitas untuk masing-masing kelas, mereka dapat dikonversi ke label kelas menggunakan np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
Bandingkan Kinerja
Sekarang kita dapat mengambil label yang benar untuk data validasi dari labels dan membandingkannya dengan prediksi kami untuk mendapatkan classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
Kami juga dapat membandingkan kinerja model kami dengan hasil yang dipublikasikan diperoleh asli kertas , yang memiliki 0,96 presisi .suatu penulis asli dijelaskan banyak langkah preprocessing dilakukan pada dataset, seperti menjatuhkan tanda baca dan angka, menghapus top 25 paling kata-kata berhenti frequest. Seperti yang kita lihat di classification_report , kami juga berhasil mendapatkan presisi dan akurasi 0,96 setelah pelatihan hanya 5 zaman tanpa preprocessing apapun!
Dalam contoh ini, ketika kita menciptakan lapisan Keras dari modul embedding kami, kami mengatur parameter trainable=False , yang berarti bobot embedding tidak akan diperbarui selama pelatihan. Cobalah pengaturan untuk True mencapai sekitar 97% akurasi menggunakan dataset ini setelah hanya 2 zaman.