
Fairness Indicators برای حمایت از تیمها در ارزیابی و بهبود مدلها برای نگرانیهای انصاف در مشارکت با ابزار گستردهتر Tensorflow طراحی شده است. این ابزار در حال حاضر به طور فعال توسط بسیاری از محصولات ما به صورت داخلی استفاده می شود، و اکنون در نسخه بتا در دسترس است تا برای موارد استفاده خودتان امتحان کنید.
شاخص های انصاف چیست؟
Fairness Indicators کتابخانهای است که محاسبه آسان معیارهای انصاف را برای طبقهبندیکنندههای باینری و چند کلاسه امکانپذیر میسازد. بسیاری از ابزارهای موجود برای ارزیابی نگرانی های انصاف در مجموعه داده ها و مدل های مقیاس بزرگ به خوبی کار نمی کنند. در گوگل برای ما مهم است که ابزارهایی داشته باشیم که بتوانند روی سیستم های میلیارد کاربر کار کنند. نشانگرهای انصاف به شما این امکان را می دهد که در هر اندازه مورد استفاده ارزیابی کنید.
به طور خاص، شاخصهای انصاف شامل توانایی زیر است:
- توزیع مجموعه داده ها را ارزیابی کنید
- ارزیابی عملکرد مدل، برش در گروه های تعریف شده از کاربران
- با فواصل اطمینان و ارزیابی در آستانه های متعدد، نسبت به نتایج خود مطمئن باشید
- برای کشف علل ریشهای و فرصتهای بهبود، در بخشهای جداگانه فرو بروید
دانلود بسته پیپ شامل:
استفاده از شاخص های انصاف با مدل های تنسورفلو
داده ها
برای اجرای Fairness Indicators با TFMA، مطمئن شوید که مجموعه داده ارزیابی برای ویژگی هایی که می خواهید برش بزنید برچسب گذاری شده است. اگر ویژگیهای برش دقیقی را برای نگرانیهای انصاف خود ندارید، میتوانید سعی کنید مجموعهای از ارزیابی را پیدا کنید که دارد، یا ویژگیهای پراکسی را در مجموعه ویژگیهای خود در نظر بگیرید که ممکن است تفاوتهای نتیجه را برجسته کند. برای راهنمایی بیشتر، اینجا را ببینید.
مدل
می توانید از کلاس Tensorflow Estimator برای ساخت مدل خود استفاده کنید. پشتیبانی از مدل های Keras به زودی در TFMA ارائه می شود. اگر میخواهید TFMA را روی مدل Keras اجرا کنید، لطفاً بخش «TFMA مدل-Agnostic» را در زیر ببینید.
پس از آموزش برآوردگر شما، باید یک مدل ذخیره شده را برای اهداف ارزیابی صادر کنید. برای کسب اطلاعات بیشتر، راهنمای TFMA را ببینید.
پیکربندی Slices
در مرحله بعد، برش هایی را که می خواهید ارزیابی کنید، تعریف کنید:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
اگر می خواهید برش های متقاطع را ارزیابی کنید (به عنوان مثال، هم رنگ خز و هم ارتفاع)، می توانید موارد زیر را تنظیم کنید:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
محاسبه معیارهای انصاف
یک Callback Fairness Indicators را به لیست metrics_callback اضافه کنید. در فراخوانی، میتوانید فهرستی از آستانههایی را که مدل در آنها ارزیابی میشود، تعریف کنید.
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
قبل از اجرای پیکربندی، تعیین کنید که آیا می خواهید محاسبه فواصل اطمینان را فعال کنید یا خیر. فواصل اطمینان با استفاده از بوت استرپ پواسون محاسبه می شود و نیاز به محاسبه مجدد بیش از 20 نمونه دارد.
compute_confidence_intervals = True
خط لوله ارزیابی TFMA را اجرا کنید:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
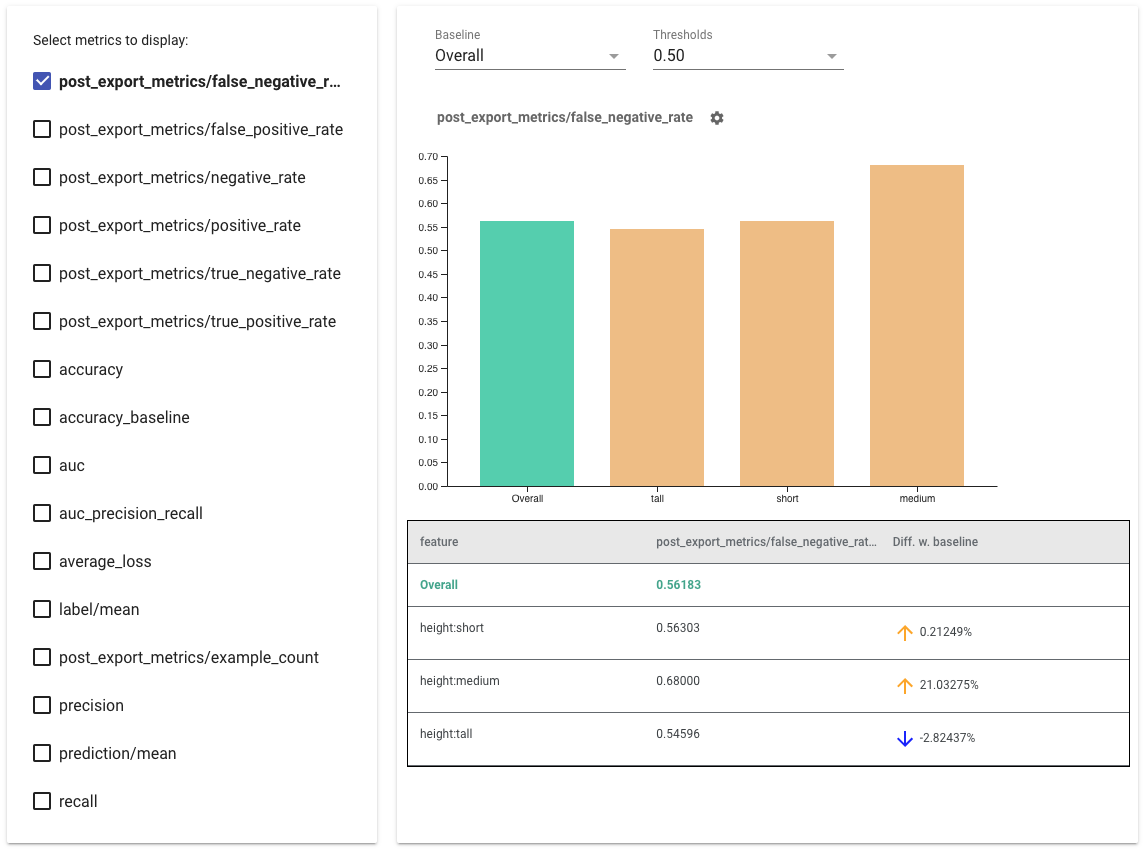
شاخص های انصاف را ارائه دهید
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
نکاتی برای استفاده از شاخص های انصاف:
- با علامت زدن کادرهای سمت چپ ، معیارهایی را برای نمایش انتخاب کنید . نمودارهای جداگانه برای هر یک از معیارها به ترتیب در ویجت ظاهر می شوند.
- با استفاده از انتخابگر کشویی، برش پایه، اولین نوار روی نمودار را تغییر دهید . دلتاها با این مقدار پایه محاسبه خواهند شد.
- آستانه ها را با استفاده از انتخابگر کشویی انتخاب کنید . می توانید چند آستانه را در یک نمودار مشاهده کنید. آستانههای انتخابشده پررنگ میشوند، و میتوانید روی آستانه پررنگ کلیک کنید تا انتخاب آن لغو شود.
- ماوس را روی یک نوار نگه دارید تا معیارهای آن برش را ببینید.
- با استفاده از ستون "Diff w. baseline"، که درصد اختلاف بین برش فعلی و خط مبنا را مشخص می کند، نابرابری ها را با خط مبنا شناسایی کنید .
- نقاط داده یک برش را با استفاده از ابزار What-If به طور عمیق کاوش کنید. برای مثال اینجا را ببینید.
ارائه شاخص های انصاف برای مدل های چندگانه
برای مقایسه مدل ها می توان از شاخص های انصاف نیز استفاده کرد. به جای ارسال در یک eval_result، یک شی multi_eval_results را ارسال کنید، که یک فرهنگ لغت نگاشت دو نام مدل به اشیاء eval_result است.
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
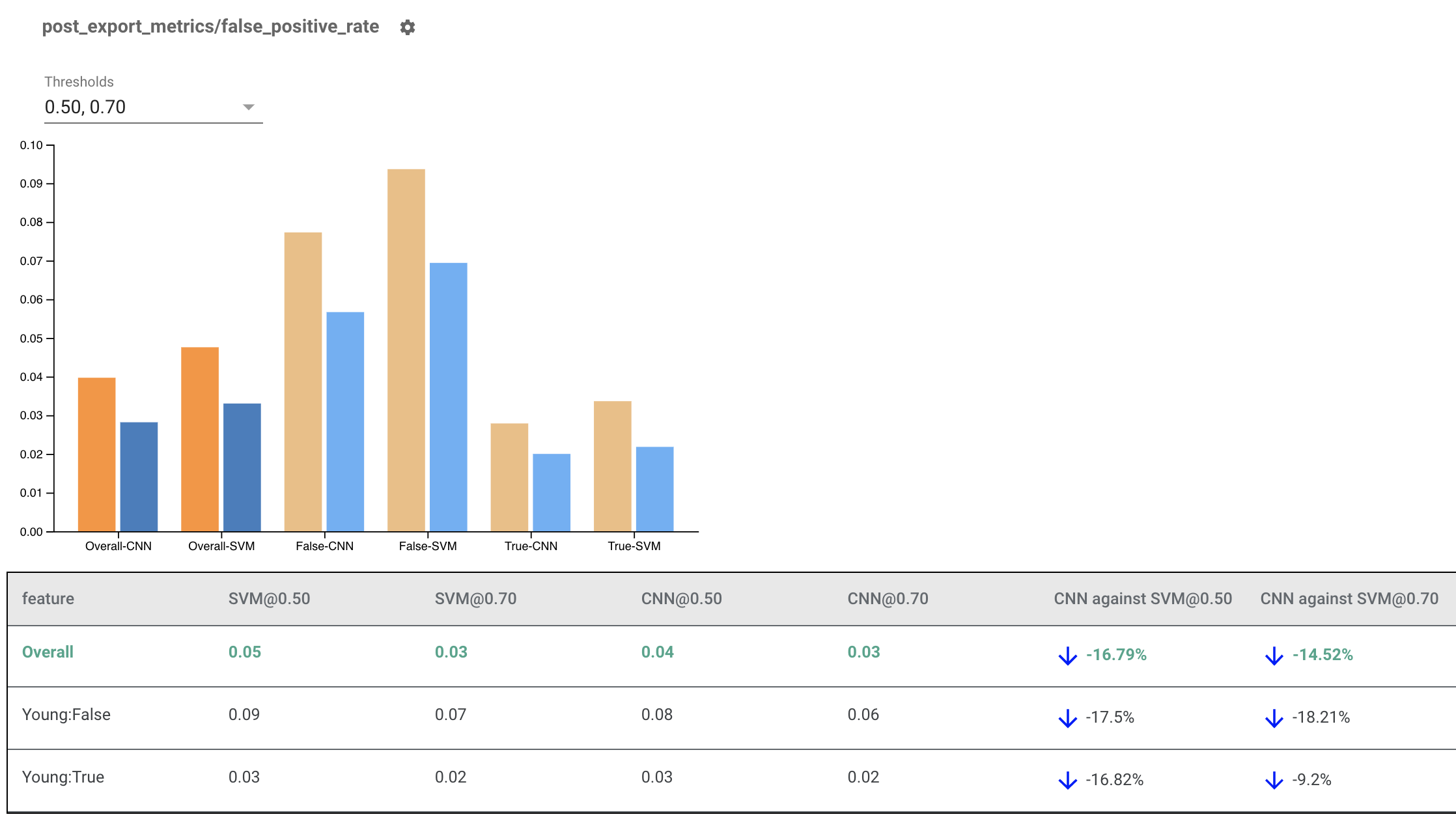
مقایسه مدل را می توان در کنار مقایسه آستانه استفاده کرد. به عنوان مثال، می توانید دو مدل را در دو مجموعه آستانه مقایسه کنید تا ترکیب بهینه را برای معیارهای انصاف خود بیابید.
استفاده از شاخصهای انصاف با مدلهای غیر تنسورفلو
برای حمایت بهتر از مشتریانی که مدلها و جریانهای کاری متفاوتی دارند، ما یک کتابخانه ارزیابی ایجاد کردهایم که نسبت به مدل در حال ارزیابی ناشناس است.
هر کسی که بخواهد سیستم یادگیری ماشین خود را ارزیابی کند، میتواند از آن استفاده کند، به خصوص اگر مدلهای غیر مبتنی بر TensorFlow دارید. با استفاده از Apache Beam Python SDK، می توانید یک باینری ارزیابی TFMA مستقل ایجاد کنید و سپس آن را برای تجزیه و تحلیل مدل خود اجرا کنید.
داده ها
این مرحله برای ارائه مجموعه داده ای است که می خواهید ارزیابی ها روی آن اجرا شوند. باید در قالب پروتو tf.Example دارای برچسبها، پیشبینیها و سایر ویژگیهایی باشد که ممکن است بخواهید روی آنها تکه تکه کنید.
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
مدل
به جای تعیین یک مدل، شما یک پیکربندی و استخراج کننده مدل agnostic eval برای تجزیه و ارائه داده های مورد نیاز TFMA برای محاسبه معیارها ایجاد می کنید. مشخصات ModelAgnosticConfig ویژگیها، پیشبینیها و برچسبهایی را که باید از نمونههای ورودی استفاده شوند، تعریف میکند.
برای این کار، یک نقشه ویژگی با کلیدهایی که همه ویژگیها از جمله برچسبها و کلیدهای پیشبینی و مقادیر نشاندهنده نوع داده ویژگی را نشان میدهند، ایجاد کنید.
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
با استفاده از کلیدهای برچسب، کلیدهای پیش بینی و نقشه ویژگی، یک پیکربندی آگنوستیک مدل ایجاد کنید.
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
Extractor Model Agnostic را راه اندازی کنید
استخراج کننده برای استخراج ویژگی ها، برچسب ها و پیش بینی ها از ورودی با استفاده از پیکربندی مدل آگنوستیک استفاده می شود. و اگر میخواهید دادههای خود را برش دهید، باید مشخصات کلید slice را نیز تعریف کنید که حاوی اطلاعاتی درباره ستونهایی است که میخواهید برش بزنید.
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
محاسبه معیارهای انصاف
بهعنوان بخشی از EvalSharedModel ، میتوانید تمام معیارهایی را که میخواهید مدل شما بر اساس آنها ارزیابی شود، ارائه کنید. معیارها در قالب بازخوانی سنجهها مانند مواردی که در post_export_metrics یا fairness_indicators تعریف شدهاند ارائه میشوند.
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
همچنین از یک construct_fn استفاده میکند که برای ایجاد یک نمودار tensorflow برای انجام ارزیابی استفاده میشود.
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
هنگامی که همه چیز تنظیم شد، از یکی از توابع ExtractEvaluate یا ExtractEvaluateAndWriteResults ارائه شده توسط model_eval_lib برای ارزیابی مدل استفاده کنید.
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
در نهایت، با استفاده از دستورالعملهای بخش «شاخصهای عادلانه ارائه» در بالا، رندر کنید.
نمونه های بیشتر
فهرست نمونههای شاخصهای انصاف حاوی چندین مثال است:
- Fairness_Indicators_Example_Colab.ipynb یک نمای کلی از Fairness Indicators در تحلیل مدل TensorFlow و نحوه استفاده از آن با یک مجموعه داده واقعی ارائه می دهد. این نوت بوک همچنین دارای اعتبارسنجی داده های TensorFlow و What-If Tool هستند، دو ابزار برای تجزیه و تحلیل مدل های TensorFlow که با نشانگرهای انصاف بسته بندی شده اند.
- Fairness_Indicators_on_TF_Hub.ipynb نحوه استفاده از Fairness Indicators را برای مقایسه مدل های آموزش دیده در جاسازی های متن مختلف نشان می دهد. این نوت بوک از جاسازیهای متنی از TensorFlow Hub ، کتابخانه TensorFlow برای انتشار، کشف و استفاده مجدد از اجزای مدل استفاده میکند.
- Fairness_Indicators_TensorBoard_Plugin_Example_Colab.ipynb نحوه تجسم نشانگرهای انصاف را در TensorBoard نشان می دهد.