
Le pipeline TFX ti consentono di orchestrare il flusso di lavoro di machine learning (ML) su orchestratori, come: Apache Airflow, Apache Beam e Kubeflow Pipelines. Le pipeline organizzano il flusso di lavoro in una sequenza di componenti, in cui ciascun componente esegue un passaggio nel flusso di lavoro ML. I componenti standard TFX forniscono funzionalità comprovate per aiutarti a iniziare facilmente a creare un flusso di lavoro ML. Puoi anche includere componenti personalizzati nel tuo flusso di lavoro. I componenti personalizzati ti consentono di estendere il flusso di lavoro ML:
- Creazione di componenti personalizzati per soddisfare le tue esigenze, ad esempio l'acquisizione di dati da un sistema proprietario.
- Applicazione di aumento, sovracampionamento o downsampling dei dati.
- Eseguire il rilevamento delle anomalie in base agli intervalli di confidenza o all'errore di riproduzione del codificatore automatico.
- Interfacciamento con sistemi esterni come help desk per avvisi e monitoraggio.
- Applicazione di etichette a esempi senza etichetta.
- Integrazione di strumenti creati con linguaggi diversi da Python nel flusso di lavoro ML, ad esempio l'esecuzione di analisi dei dati utilizzando R.
Combinando componenti standard e componenti personalizzati, puoi creare un flusso di lavoro ML che soddisfi le tue esigenze sfruttando al tempo stesso le best practice integrate nei componenti standard TFX.
Questa guida descrive i concetti necessari per comprendere i componenti personalizzati TFX e i diversi modi in cui è possibile creare componenti personalizzati.
Anatomia di un componente TFX
Questa sezione fornisce una panoramica di alto livello della composizione di un componente TFX. Se non conosci le pipeline TFX, apprendi i concetti fondamentali leggendo la guida per comprendere le pipeline TFX .
I componenti TFX sono composti da una specifica del componente e da una classe di esecutore che sono impacchettati in una classe di interfaccia del componente.
Una specifica del componente definisce il contratto di input e output del componente. Questo contratto specifica gli artefatti di input e output del componente e i parametri utilizzati per l'esecuzione del componente.
La classe esecutore di un componente fornisce l'implementazione del lavoro svolto dal componente.
Una classe di interfaccia del componente combina la specifica del componente con l'esecutore per l'utilizzo come componente in una pipeline TFX.
Componenti TFX in fase di esecuzione
Quando una pipeline esegue un componente TFX, il componente viene eseguito in tre fasi:
- Innanzitutto, il driver utilizza la specifica del componente per recuperare gli artefatti richiesti dall'archivio dei metadati e passarli al componente.
- Successivamente, l'Esecutore esegue il lavoro del componente.
- Quindi l'editore utilizza la specifica del componente e i risultati dell'esecutore per archiviare gli output del componente nell'archivio dei metadati.
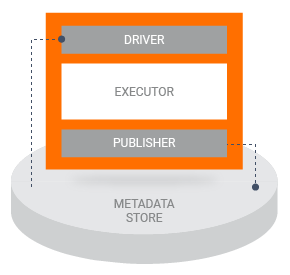
La maggior parte delle implementazioni dei componenti personalizzati non richiedono la personalizzazione del driver o del server di pubblicazione. In genere, le modifiche al driver e al server di pubblicazione dovrebbero essere necessarie solo se desideri modificare l'interazione tra i componenti della pipeline e l'archivio dei metadati. Se desideri modificare solo gli input, gli output o i parametri del tuo componente, devi solo modificare le specifiche del componente .
Tipi di componenti personalizzati
Esistono tre tipi di componenti personalizzati: componenti basati su funzioni Python, componenti basati su contenitore e componenti completamente personalizzati. Le sezioni seguenti descrivono i diversi tipi di componenti e i casi in cui è necessario utilizzare ciascun approccio.
Componenti basati su funzioni Python
I componenti basati su funzioni Python sono più facili da creare rispetto ai componenti basati su contenitori o ai componenti completamente personalizzati. La specifica del componente è definita negli argomenti della funzione Python utilizzando annotazioni di tipo che descrivono se un argomento è un artefatto di input, un artefatto di output o un parametro. Il corpo della funzione definisce l'esecutore del componente. L'interfaccia del componente viene definita aggiungendo il decoratore @component alla tua funzione.
Decorando la tua funzione con il decoratore @component e definendo gli argomenti della funzione con annotazioni di tipo, puoi creare un componente senza la complessità di creare una specifica del componente, un esecutore e un'interfaccia del componente.
Scopri come creare componenti basati su funzioni Python .
Componenti basati su contenitori
I componenti basati su container offrono la flessibilità necessaria per integrare codice scritto in qualsiasi linguaggio nella pipeline, purché sia possibile eseguire tale codice in un container Docker. Per creare un componente basato su contenitore, devi creare un'immagine del contenitore Docker che contenga il codice eseguibile del componente. Quindi devi chiamare la funzione create_container_component per definire:
- Gli input, gli output e i parametri delle specifiche del componente.
- L'immagine del contenitore e il comando eseguito dall'esecutore del componente.
Questa funzione restituisce un'istanza di un componente che puoi includere nella definizione della pipeline.
Questo approccio è più complesso rispetto alla creazione di un componente basato su funzioni Python, poiché richiede il confezionamento del codice come immagine contenitore. Questo approccio è particolarmente adatto per includere codice non Python nella pipeline o per creare componenti Python con ambienti runtime o dipendenze complessi.
Scopri come creare componenti basati su contenitori .
Componenti completamente personalizzati
I componenti completamente personalizzati consentono di creare componenti definendo la specifica del componente, l'esecutore e le classi dell'interfaccia del componente. Questo approccio consente di riutilizzare ed estendere un componente standard per adattarlo alle proprie esigenze.
Se un componente esistente è definito con gli stessi input e output del componente personalizzato che stai sviluppando, puoi semplicemente sovrascrivere la classe Executor del componente esistente. Ciò significa che è possibile riutilizzare la specifica di un componente e implementare un nuovo esecutore che deriva da un componente esistente. In questo modo si riutilizzano le funzionalità integrate nei componenti esistenti e si implementa solo la funzionalità richiesta.
Se tuttavia gli input e gli output del nuovo componente sono unici, è possibile definire una specifica del componente completamente nuova.
Questo approccio è il migliore per riutilizzare le specifiche dei componenti e gli esecutori esistenti.
Scopri come creare componenti completamente personalizzati .