
ওভারভিউ
টেনসরফ্লো মডেল অ্যানালাইসিস (TFMA) হল মডেল মূল্যায়ন করার জন্য একটি লাইব্রেরি।
- জন্য : মেশিন লার্নিং ইঞ্জিনিয়ার বা ডেটা সায়েন্টিস্ট
- যারা : তাদের TensorFlow মডেল বিশ্লেষণ এবং বুঝতে চান
- এটি হল : একটি স্বতন্ত্র লাইব্রেরি বা একটি TFX পাইপলাইনের উপাদান৷
- যে : প্রশিক্ষণে সংজ্ঞায়িত একই মেট্রিক্সে বিতরণ করা পদ্ধতিতে বিপুল পরিমাণ ডেটার মডেলগুলিকে মূল্যায়ন করে। এই মেট্রিকগুলিকে ডেটার স্লাইসগুলির সাথে তুলনা করা হয় এবং Jupyter বা Colab নোটবুকে ভিজ্যুয়ালাইজ করা হয়।
- অসদৃশ : কিছু মডেল আত্মদর্শন সরঞ্জাম যেমন টেনসরবোর্ড যা মডেল আত্মদর্শন অফার করে
TFMA Apache Beam ব্যবহার করে প্রচুর পরিমাণে ডেটার উপর বিতরণ পদ্ধতিতে তার গণনা সম্পাদন করে। নিম্নলিখিত বিভাগগুলি বর্ণনা করে কিভাবে একটি মৌলিক TFMA মূল্যায়ন পাইপলাইন সেটআপ করতে হয়। অন্তর্নিহিত বাস্তবায়ন সম্পর্কে আর্কিটেকচার আরও বিশদ দেখুন।
আপনি যদি শুধু ঝাঁপিয়ে পড়তে এবং শুরু করতে চান, তাহলে আমাদের কোলাব নোটবুকটি দেখুন।
এই পৃষ্ঠাটি tensorflow.org থেকেও দেখা যেতে পারে।
মডেলের ধরন সমর্থিত
TFMA টেনসরফ্লো ভিত্তিক মডেলগুলিকে সমর্থন করার জন্য ডিজাইন করা হয়েছে, তবে অন্যান্য কাঠামোকে সমর্থন করার জন্য সহজেই প্রসারিত করা যেতে পারে। ঐতিহাসিকভাবে, TFMA ব্যবহার করার জন্য একটি EvalSavedModel তৈরি করা প্রয়োজন ছিল, কিন্তু TFMA এর সর্বশেষ সংস্করণ ব্যবহারকারীর চাহিদার উপর নির্ভর করে একাধিক ধরনের মডেলকে সমর্থন করে। একটি EvalSavedModel সেট আপ করা শুধুমাত্র তখনই প্রয়োজন হবে যদি একটি tf.estimator ভিত্তিক মডেল ব্যবহার করা হয় এবং কাস্টম প্রশিক্ষণের সময় মেট্রিক্সের প্রয়োজন হয়।
উল্লেখ্য যে TFMA এখন সার্ভিং মডেলের উপর ভিত্তি করে চলে, তাই TFMA আর স্বয়ংক্রিয়ভাবে প্রশিক্ষণের সময় যোগ করা মেট্রিক্সের মূল্যায়ন করবে না। এই ক্ষেত্রে ব্যতিক্রম হল যদি একটি কেরাস মডেল ব্যবহার করা হয় যেহেতু কেরাস সংরক্ষিত মডেলের পাশাপাশি ব্যবহৃত মেট্রিকগুলি সংরক্ষণ করে। যাইহোক, যদি এটি একটি কঠিন প্রয়োজন হয়, সর্বশেষ TFMA পিছনের দিকে সামঞ্জস্যপূর্ণ যেমন একটি EvalSavedModel এখনও একটি TFMA পাইপলাইনে চালানো যেতে পারে।
নিম্নলিখিত টেবিলটি ডিফল্টরূপে সমর্থিত মডেলগুলির সংক্ষিপ্ত বিবরণ দেয়:
| মডেলের ধরন | প্রশিক্ষণের সময় মেট্রিক্স | পোস্ট ট্রেনিং মেট্রিক্স |
|---|---|---|
| TF2 (কেরা) | Y* | Y |
| TF2 (জেনারিক) | N/A | Y |
| EvalSavedModel (আনুমানিক) | Y | Y |
| কোনটিই নয় (pd.DataFrame, ইত্যাদি) | N/A | Y |
- ট্রেনিং টাইম মেট্রিক্স ট্রেনিং টাইমে সংজ্ঞায়িত এবং মডেলের সাথে সংরক্ষিত মেট্রিক্সকে বোঝায় (হয় TFMA EvalSavedModel বা keras সংরক্ষিত মডেল)। পোস্ট ট্রেনিং মেট্রিক্স
tfma.MetricConfigএর মাধ্যমে যোগ করা মেট্রিককে বোঝায়। - জেনেরিক TF2 মডেল হল কাস্টম মডেল যা স্বাক্ষর রপ্তানি করে যা অনুমানের জন্য ব্যবহার করা যেতে পারে এবং কেরা বা অনুমানকারীর উপর ভিত্তি করে নয়।
এই বিভিন্ন ধরনের মডেল সেটআপ এবং কনফিগার করার বিষয়ে আরও তথ্যের জন্য FAQ দেখুন।
সেটআপ
একটি মূল্যায়ন চালানোর আগে, একটি ছোট পরিমাণ সেটআপ প্রয়োজন। প্রথমত, একটি tfma.EvalConfig অবজেক্টকে অবশ্যই সংজ্ঞায়িত করতে হবে যা মডেল, মেট্রিক্স এবং স্লাইসগুলির জন্য নির্দিষ্টকরণ প্রদান করে যা মূল্যায়ন করা হবে। দ্বিতীয়ত একটি tfma.EvalSharedModel তৈরি করতে হবে যা মূল্যায়নের সময় ব্যবহার করা প্রকৃত মডেল (বা মডেল) নির্দেশ করে। একবার এগুলিকে সংজ্ঞায়িত করা হলে, একটি উপযুক্ত ডেটাসেটের সাথে tfma.run_model_analysis কল করে মূল্যায়ন করা হয়। আরো বিস্তারিত জানার জন্য, সেটআপ গাইড দেখুন।
একটি TFX পাইপলাইনের মধ্যে চললে, TFX মূল্যায়নকারী উপাদান হিসাবে চালানোর জন্য TFMA কনফিগার করার জন্য TFX নির্দেশিকা দেখুন।
উদাহরণ
একক মডেল মূল্যায়ন
নিম্নলিখিতটি একটি পরিবেশন মডেলের মূল্যায়ন করতে tfma.run_model_analysis ব্যবহার করে। প্রয়োজনীয় বিভিন্ন সেটিংসের ব্যাখ্যার জন্য সেটআপ গাইড দেখুন।
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
বিতরণকৃত মূল্যায়নের জন্য, একটি বিতরণ করা রানার ব্যবহার করে একটি Apache Beam পাইপলাইন তৈরি করুন। পাইপলাইনে, মূল্যায়নের জন্য এবং ফলাফল লিখতে tfma.ExtractEvaluateAndWriteResults ব্যবহার করুন। tfma.load_eval_result ব্যবহার করে ভিজ্যুয়ালাইজেশনের জন্য ফলাফল লোড করা যেতে পারে।
যেমন:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
মডেলের বৈধতা
একজন প্রার্থী এবং বেসলাইনের বিপরীতে মডেল যাচাই করতে, একটি থ্রেশহোল্ড সেটিং অন্তর্ভুক্ত করতে কনফিগারেশন আপডেট করুন এবং tfma.run_model_analysis এ দুটি মডেল পাস করুন।
যেমন:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
ভিজ্যুয়ালাইজেশন
TFMA মূল্যায়নের ফলাফলগুলি টিএফএমএ-তে অন্তর্ভুক্ত ফ্রন্টএন্ড উপাদানগুলি ব্যবহার করে জুপিটার নোটবুকে ভিজ্যুয়ালাইজ করা যেতে পারে। যেমন:
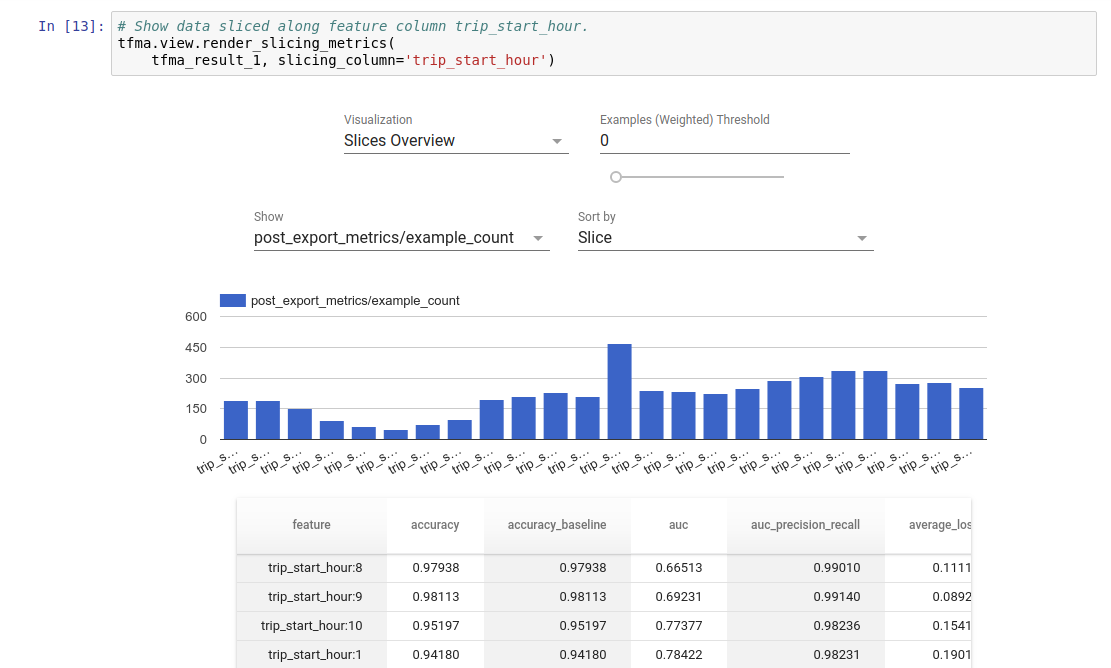 .
.