
| | |  Lihat di GitHub Lihat di GitHub | |
Dalam aplikasi AI yang kritis terhadap keselamatan (misalnya, pengambilan keputusan medis dan mengemudi secara otonom) atau di mana data secara inheren berisik (misalnya, pemahaman bahasa alami), penting bagi pengklasifikasi mendalam untuk mengukur ketidakpastiannya secara andal. Pengklasifikasi dalam harus dapat menyadari keterbatasannya sendiri dan kapan harus menyerahkan kendali kepada ahli manusia. Tutorial ini menunjukkan bagaimana meningkatkan kemampuan deep classifier dalam mengkuantifikasi ketidakpastian menggunakan teknik yang disebut Spectral-normalized Neural Gaussian Process ( SNGP ) .
Ide inti dari SNGP adalah untuk meningkatkan kesadaran jarak pengklasifikasi yang mendalam dengan menerapkan modifikasi sederhana ke jaringan. Kesadaran jarak model adalah ukuran bagaimana probabilitas prediktifnya mencerminkan jarak antara contoh uji dan data pelatihan. Ini adalah properti yang diinginkan yang umum untuk model probablistik standar emas (misalnya, proses Gaussian dengan kernel RBF) tetapi kurang dalam model dengan jaringan saraf yang dalam. SNGP menyediakan cara sederhana untuk menyuntikkan perilaku proses Gaussian ini ke dalam pengklasifikasi yang dalam sambil mempertahankan akurasi prediktifnya.
Tutorial ini mengimplementasikan model SNGP berbasis jaringan residual dalam (ResNet) pada set data dua bulan , dan membandingkan permukaan ketidakpastiannya dengan dua pendekatan ketidakpastian populer lainnya - putus sekolah Monte Carlo dan Ansambel dalam ).
Tutorial ini mengilustrasikan model SNGP pada dataset 2D mainan. Untuk contoh penerapan SNGP ke tugas pemahaman bahasa alami dunia nyata menggunakan basis BERT, silakan lihat tutorial SNGP-BERT . Untuk implementasi model SNGP berkualitas tinggi (dan banyak metode ketidakpastian lainnya) pada berbagai kumpulan data tolok ukur (misalnya, CIFAR-100 , ImageNet , Deteksi toksisitas Jigsaw , dll), silakan lihat tolok ukur Uncertainty Baselines .
Tentang SNGP
Proses Gaussian Neural Spectral-normalized (SNGP) adalah pendekatan sederhana untuk meningkatkan kualitas ketidakpastian pengklasifikasi dalam sambil mempertahankan tingkat akurasi dan latensi yang serupa. Mengingat jaringan residual yang dalam, SNGP membuat dua perubahan sederhana pada model:
- Ini menerapkan normalisasi spektral ke lapisan residu tersembunyi.
- Ini menggantikan lapisan keluaran Padat dengan lapisan proses Gaussian.
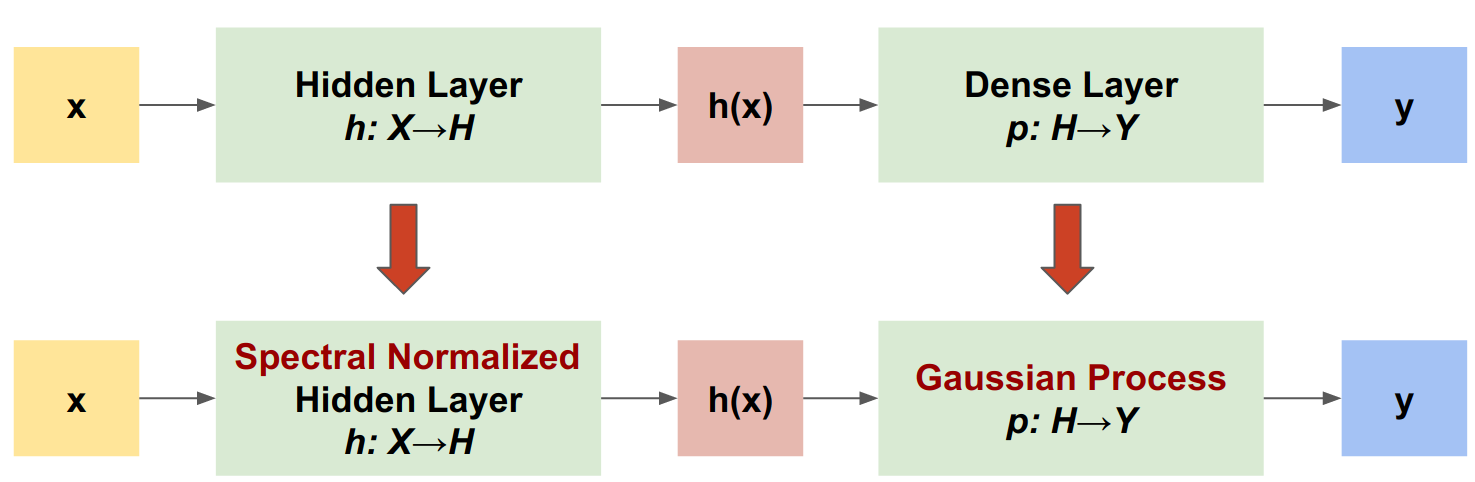
Dibandingkan dengan pendekatan ketidakpastian lainnya (misalnya, Monte Carlo dropout atau Deep ensemble), SNGP memiliki beberapa keunggulan:
- Ia bekerja untuk berbagai arsitektur berbasis residu yang canggih (misalnya, (Wide) ResNet, DenseNet, BERT, dll).
- Ini adalah metode model tunggal (yaitu, tidak bergantung pada rata-rata ansambel). Oleh karena itu SNGP memiliki tingkat latensi yang serupa sebagai jaringan deterministik tunggal, dan dapat dengan mudah diskalakan ke kumpulan data besar seperti klasifikasi ImageNet dan Jigsaw Toxic Comments .
- Ini memiliki kinerja deteksi di luar domain yang kuat karena properti kesadaran jarak .
Kelemahan dari metode ini adalah:
Ketidakpastian prediktif dari SNGP dihitung menggunakan pendekatan Laplace . Oleh karena itu secara teoritis, ketidakpastian posterior SNGP berbeda dari proses Gaussian eksak.
Pelatihan SNGP membutuhkan langkah reset kovarians di awal epoch baru. Ini dapat menambahkan sedikit kerumitan ekstra ke jalur pelatihan. Tutorial ini menunjukkan cara sederhana untuk mengimplementasikannya menggunakan callback Keras.
Mempersiapkan
pip install --use-deprecated=legacy-resolver tf-models-official
# refresh pkg_resources so it takes the changes into account.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
import matplotlib.pyplot as plt
import matplotlib.colors as colors
import sklearn.datasets
import numpy as np
import tensorflow as tf
import official.nlp.modeling.layers as nlp_layers
Tentukan makro visualisasi
plt.rcParams['figure.dpi'] = 140
DEFAULT_X_RANGE = (-3.5, 3.5)
DEFAULT_Y_RANGE = (-2.5, 2.5)
DEFAULT_CMAP = colors.ListedColormap(["#377eb8", "#ff7f00"])
DEFAULT_NORM = colors.Normalize(vmin=0, vmax=1,)
DEFAULT_N_GRID = 100
Kumpulan data dua bulan
Buat dataset pelatihan dan evaluasi dari dataset two moon .
def make_training_data(sample_size=500):
"""Create two moon training dataset."""
train_examples, train_labels = sklearn.datasets.make_moons(
n_samples=2 * sample_size, noise=0.1)
# Adjust data position slightly.
train_examples[train_labels == 0] += [-0.1, 0.2]
train_examples[train_labels == 1] += [0.1, -0.2]
return train_examples, train_labels
Evaluasi perilaku prediktif model di seluruh ruang input 2D.
def make_testing_data(x_range=DEFAULT_X_RANGE, y_range=DEFAULT_Y_RANGE, n_grid=DEFAULT_N_GRID):
"""Create a mesh grid in 2D space."""
# testing data (mesh grid over data space)
x = np.linspace(x_range[0], x_range[1], n_grid)
y = np.linspace(y_range[0], y_range[1], n_grid)
xv, yv = np.meshgrid(x, y)
return np.stack([xv.flatten(), yv.flatten()], axis=-1)
Untuk mengevaluasi ketidakpastian model, tambahkan set data di luar domain (OOD) milik kelas ketiga. Model tidak pernah melihat contoh OOD ini selama pelatihan.
def make_ood_data(sample_size=500, means=(2.5, -1.75), vars=(0.01, 0.01)):
return np.random.multivariate_normal(
means, cov=np.diag(vars), size=sample_size)
# Load the train, test and OOD datasets.
train_examples, train_labels = make_training_data(
sample_size=500)
test_examples = make_testing_data()
ood_examples = make_ood_data(sample_size=500)
# Visualize
pos_examples = train_examples[train_labels == 0]
neg_examples = train_examples[train_labels == 1]
plt.figure(figsize=(7, 5.5))
plt.scatter(pos_examples[:, 0], pos_examples[:, 1], c="#377eb8", alpha=0.5)
plt.scatter(neg_examples[:, 0], neg_examples[:, 1], c="#ff7f00", alpha=0.5)
plt.scatter(ood_examples[:, 0], ood_examples[:, 1], c="red", alpha=0.1)
plt.legend(["Postive", "Negative", "Out-of-Domain"])
plt.ylim(DEFAULT_Y_RANGE)
plt.xlim(DEFAULT_X_RANGE)
plt.show()

Di sini warna biru dan jingga mewakili kelas positif dan negatif, dan warna merah mewakili data OOD. Sebuah model yang mengkuantifikasi ketidakpastian dengan baik diharapkan menjadi percaya diri ketika dekat dengan data pelatihan (yaitu, \(p(x_{test})\) mendekati 0 atau 1), dan menjadi tidak pasti ketika jauh dari wilayah data pelatihan (yaitu, \(p(x_{test})\) mendekati 0,5 ).
Model deterministik
Tentukan model
Mulai dari model deterministik (dasar): jaringan residual multi-layer (ResNet) dengan regularisasi putus sekolah.
class DeepResNet(tf.keras.Model):
"""Defines a multi-layer residual network."""
def __init__(self, num_classes, num_layers=3, num_hidden=128,
dropout_rate=0.1, **classifier_kwargs):
super().__init__()
# Defines class meta data.
self.num_hidden = num_hidden
self.num_layers = num_layers
self.dropout_rate = dropout_rate
self.classifier_kwargs = classifier_kwargs
# Defines the hidden layers.
self.input_layer = tf.keras.layers.Dense(self.num_hidden, trainable=False)
self.dense_layers = [self.make_dense_layer() for _ in range(num_layers)]
# Defines the output layer.
self.classifier = self.make_output_layer(num_classes)
def call(self, inputs):
# Projects the 2d input data to high dimension.
hidden = self.input_layer(inputs)
# Computes the resnet hidden representations.
for i in range(self.num_layers):
resid = self.dense_layers[i](hidden)
resid = tf.keras.layers.Dropout(self.dropout_rate)(resid)
hidden += resid
return self.classifier(hidden)
def make_dense_layer(self):
"""Uses the Dense layer as the hidden layer."""
return tf.keras.layers.Dense(self.num_hidden, activation="relu")
def make_output_layer(self, num_classes):
"""Uses the Dense layer as the output layer."""
return tf.keras.layers.Dense(
num_classes, **self.classifier_kwargs)
Tutorial ini menggunakan ResNet 6-layer dengan 128 unit tersembunyi.
resnet_config = dict(num_classes=2, num_layers=6, num_hidden=128)
resnet_model = DeepResNet(**resnet_config)
resnet_model.build((None, 2))
resnet_model.summary()
Model: "deep_res_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) multiple 384
dense_1 (Dense) multiple 16512
dense_2 (Dense) multiple 16512
dense_3 (Dense) multiple 16512
dense_4 (Dense) multiple 16512
dense_5 (Dense) multiple 16512
dense_6 (Dense) multiple 16512
dense_7 (Dense) multiple 258
=================================================================
Total params: 99,714
Trainable params: 99,330
Non-trainable params: 384
_________________________________________________________________
Model kereta api
Konfigurasikan parameter pelatihan untuk menggunakan SparseCategoricalCrossentropy sebagai fungsi kerugian dan pengoptimal Adam.
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metrics = tf.keras.metrics.SparseCategoricalAccuracy(),
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
train_config = dict(loss=loss, metrics=metrics, optimizer=optimizer)
Latih model untuk 100 epoch dengan ukuran batch 128.
fit_config = dict(batch_size=128, epochs=100)
resnet_model.compile(**train_config)
resnet_model.fit(train_examples, train_labels, **fit_config)
Epoch 1/100 8/8 [==============================] - 1s 4ms/step - loss: 1.1251 - sparse_categorical_accuracy: 0.5050 Epoch 2/100 8/8 [==============================] - 0s 3ms/step - loss: 0.5538 - sparse_categorical_accuracy: 0.6920 Epoch 3/100 8/8 [==============================] - 0s 3ms/step - loss: 0.2881 - sparse_categorical_accuracy: 0.9160 Epoch 4/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1923 - sparse_categorical_accuracy: 0.9370 Epoch 5/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1550 - sparse_categorical_accuracy: 0.9420 Epoch 6/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1403 - sparse_categorical_accuracy: 0.9450 Epoch 7/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1269 - sparse_categorical_accuracy: 0.9430 Epoch 8/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1208 - sparse_categorical_accuracy: 0.9460 Epoch 9/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1158 - sparse_categorical_accuracy: 0.9510 Epoch 10/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1103 - sparse_categorical_accuracy: 0.9490 Epoch 11/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1051 - sparse_categorical_accuracy: 0.9510 Epoch 12/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1053 - sparse_categorical_accuracy: 0.9510 Epoch 13/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1013 - sparse_categorical_accuracy: 0.9450 Epoch 14/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0967 - sparse_categorical_accuracy: 0.9500 Epoch 15/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0991 - sparse_categorical_accuracy: 0.9530 Epoch 16/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0984 - sparse_categorical_accuracy: 0.9500 Epoch 17/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0982 - sparse_categorical_accuracy: 0.9480 Epoch 18/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0918 - sparse_categorical_accuracy: 0.9510 Epoch 19/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0903 - sparse_categorical_accuracy: 0.9500 Epoch 20/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0883 - sparse_categorical_accuracy: 0.9510 Epoch 21/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0870 - sparse_categorical_accuracy: 0.9530 Epoch 22/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0884 - sparse_categorical_accuracy: 0.9560 Epoch 23/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0850 - sparse_categorical_accuracy: 0.9540 Epoch 24/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0808 - sparse_categorical_accuracy: 0.9580 Epoch 25/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0773 - sparse_categorical_accuracy: 0.9560 Epoch 26/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0801 - sparse_categorical_accuracy: 0.9590 Epoch 27/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0779 - sparse_categorical_accuracy: 0.9580 Epoch 28/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0807 - sparse_categorical_accuracy: 0.9580 Epoch 29/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0820 - sparse_categorical_accuracy: 0.9570 Epoch 30/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0730 - sparse_categorical_accuracy: 0.9600 Epoch 31/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0782 - sparse_categorical_accuracy: 0.9590 Epoch 32/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0704 - sparse_categorical_accuracy: 0.9600 Epoch 33/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0709 - sparse_categorical_accuracy: 0.9610 Epoch 34/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0758 - sparse_categorical_accuracy: 0.9580 Epoch 35/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0702 - sparse_categorical_accuracy: 0.9610 Epoch 36/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0688 - sparse_categorical_accuracy: 0.9600 Epoch 37/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0675 - sparse_categorical_accuracy: 0.9630 Epoch 38/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0636 - sparse_categorical_accuracy: 0.9690 Epoch 39/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0677 - sparse_categorical_accuracy: 0.9610 Epoch 40/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0702 - sparse_categorical_accuracy: 0.9650 Epoch 41/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0614 - sparse_categorical_accuracy: 0.9690 Epoch 42/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0663 - sparse_categorical_accuracy: 0.9680 Epoch 43/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0626 - sparse_categorical_accuracy: 0.9740 Epoch 44/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0590 - sparse_categorical_accuracy: 0.9760 Epoch 45/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0573 - sparse_categorical_accuracy: 0.9780 Epoch 46/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0568 - sparse_categorical_accuracy: 0.9770 Epoch 47/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0595 - sparse_categorical_accuracy: 0.9780 Epoch 48/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0482 - sparse_categorical_accuracy: 0.9840 Epoch 49/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0515 - sparse_categorical_accuracy: 0.9820 Epoch 50/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0525 - sparse_categorical_accuracy: 0.9830 Epoch 51/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0507 - sparse_categorical_accuracy: 0.9790 Epoch 52/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0433 - sparse_categorical_accuracy: 0.9850 Epoch 53/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0511 - sparse_categorical_accuracy: 0.9820 Epoch 54/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0501 - sparse_categorical_accuracy: 0.9820 Epoch 55/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0440 - sparse_categorical_accuracy: 0.9890 Epoch 56/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0438 - sparse_categorical_accuracy: 0.9850 Epoch 57/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0438 - sparse_categorical_accuracy: 0.9880 Epoch 58/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0416 - sparse_categorical_accuracy: 0.9860 Epoch 59/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0479 - sparse_categorical_accuracy: 0.9860 Epoch 60/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0434 - sparse_categorical_accuracy: 0.9860 Epoch 61/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0414 - sparse_categorical_accuracy: 0.9880 Epoch 62/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0402 - sparse_categorical_accuracy: 0.9870 Epoch 63/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0376 - sparse_categorical_accuracy: 0.9890 Epoch 64/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0337 - sparse_categorical_accuracy: 0.9900 Epoch 65/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0309 - sparse_categorical_accuracy: 0.9910 Epoch 66/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0336 - sparse_categorical_accuracy: 0.9910 Epoch 67/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0389 - sparse_categorical_accuracy: 0.9870 Epoch 68/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0333 - sparse_categorical_accuracy: 0.9920 Epoch 69/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0331 - sparse_categorical_accuracy: 0.9890 Epoch 70/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0346 - sparse_categorical_accuracy: 0.9900 Epoch 71/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0367 - sparse_categorical_accuracy: 0.9880 Epoch 72/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0283 - sparse_categorical_accuracy: 0.9920 Epoch 73/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0315 - sparse_categorical_accuracy: 0.9930 Epoch 74/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0271 - sparse_categorical_accuracy: 0.9900 Epoch 75/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0257 - sparse_categorical_accuracy: 0.9920 Epoch 76/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0289 - sparse_categorical_accuracy: 0.9900 Epoch 77/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0264 - sparse_categorical_accuracy: 0.9900 Epoch 78/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0272 - sparse_categorical_accuracy: 0.9910 Epoch 79/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0336 - sparse_categorical_accuracy: 0.9880 Epoch 80/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0249 - sparse_categorical_accuracy: 0.9900 Epoch 81/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0216 - sparse_categorical_accuracy: 0.9930 Epoch 82/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0279 - sparse_categorical_accuracy: 0.9890 Epoch 83/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0261 - sparse_categorical_accuracy: 0.9920 Epoch 84/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0235 - sparse_categorical_accuracy: 0.9920 Epoch 85/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0236 - sparse_categorical_accuracy: 0.9930 Epoch 86/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0219 - sparse_categorical_accuracy: 0.9920 Epoch 87/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0196 - sparse_categorical_accuracy: 0.9920 Epoch 88/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0215 - sparse_categorical_accuracy: 0.9900 Epoch 89/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0223 - sparse_categorical_accuracy: 0.9900 Epoch 90/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0200 - sparse_categorical_accuracy: 0.9950 Epoch 91/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0250 - sparse_categorical_accuracy: 0.9900 Epoch 92/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0160 - sparse_categorical_accuracy: 0.9940 Epoch 93/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0203 - sparse_categorical_accuracy: 0.9930 Epoch 94/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0203 - sparse_categorical_accuracy: 0.9930 Epoch 95/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0172 - sparse_categorical_accuracy: 0.9960 Epoch 96/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0209 - sparse_categorical_accuracy: 0.9940 Epoch 97/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0179 - sparse_categorical_accuracy: 0.9920 Epoch 98/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0195 - sparse_categorical_accuracy: 0.9940 Epoch 99/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0165 - sparse_categorical_accuracy: 0.9930 Epoch 100/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0170 - sparse_categorical_accuracy: 0.9950 <keras.callbacks.History at 0x7ff7ac5c8fd0>
Visualisasikan ketidakpastian
def plot_uncertainty_surface(test_uncertainty, ax, cmap=None):
"""Visualizes the 2D uncertainty surface.
For simplicity, assume these objects already exist in the memory:
test_examples: Array of test examples, shape (num_test, 2).
train_labels: Array of train labels, shape (num_train, ).
train_examples: Array of train examples, shape (num_train, 2).
Arguments:
test_uncertainty: Array of uncertainty scores, shape (num_test,).
ax: A matplotlib Axes object that specifies a matplotlib figure.
cmap: A matplotlib colormap object specifying the palette of the
predictive surface.
Returns:
pcm: A matplotlib PathCollection object that contains the palette
information of the uncertainty plot.
"""
# Normalize uncertainty for better visualization.
test_uncertainty = test_uncertainty / np.max(test_uncertainty)
# Set view limits.
ax.set_ylim(DEFAULT_Y_RANGE)
ax.set_xlim(DEFAULT_X_RANGE)
# Plot normalized uncertainty surface.
pcm = ax.imshow(
np.reshape(test_uncertainty, [DEFAULT_N_GRID, DEFAULT_N_GRID]),
cmap=cmap,
origin="lower",
extent=DEFAULT_X_RANGE + DEFAULT_Y_RANGE,
vmin=DEFAULT_NORM.vmin,
vmax=DEFAULT_NORM.vmax,
interpolation='bicubic',
aspect='auto')
# Plot training data.
ax.scatter(train_examples[:, 0], train_examples[:, 1],
c=train_labels, cmap=DEFAULT_CMAP, alpha=0.5)
ax.scatter(ood_examples[:, 0], ood_examples[:, 1], c="red", alpha=0.1)
return pcm
Sekarang visualisasikan prediksi model deterministik. Pertama plot probabilitas kelas:
\[p(x) = softmax(logit(x))\]
resnet_logits = resnet_model(test_examples)
resnet_probs = tf.nn.softmax(resnet_logits, axis=-1)[:, 0] # Take the probability for class 0.
_, ax = plt.subplots(figsize=(7, 5.5))
pcm = plot_uncertainty_surface(resnet_probs, ax=ax)
plt.colorbar(pcm, ax=ax)
plt.title("Class Probability, Deterministic Model")
plt.show()

Dalam plot ini, kuning dan ungu adalah probabilitas prediktif untuk dua kelas. Model deterministik melakukan pekerjaan yang baik dalam mengklasifikasikan dua kelas yang diketahui (biru dan oranye) dengan batas keputusan nonlinier. Namun, ini tidak mengetahui jarak , dan mengklasifikasikan contoh red out-of-domain (OOD) yang tidak pernah dilihat dengan percaya diri sebagai kelas oranye.
Visualisasikan ketidakpastian model dengan menghitung varians prediktif :
\[var(x) = p(x) * (1 - p(x))\]
resnet_uncertainty = resnet_probs * (1 - resnet_probs)
_, ax = plt.subplots(figsize=(7, 5.5))
pcm = plot_uncertainty_surface(resnet_uncertainty, ax=ax)
plt.colorbar(pcm, ax=ax)
plt.title("Predictive Uncertainty, Deterministic Model")
plt.show()

Dalam plot ini, kuning menunjukkan ketidakpastian tinggi, dan ungu menunjukkan ketidakpastian rendah. Ketidakpastian ResNet deterministik hanya bergantung pada jarak contoh uji dari batas keputusan. Hal ini menyebabkan model menjadi terlalu percaya diri ketika keluar dari domain pelatihan. Bagian selanjutnya menunjukkan bagaimana SNGP berperilaku berbeda pada dataset ini.
Model SNGP
Tentukan model SNGP
Sekarang mari kita implementasikan model SNGP. Baik komponen SNGP, SpectralNormalization dan RandomFeatureGaussianProcess , tersedia di lapisan bawaan tensorflow_model .
Mari kita lihat kedua komponen ini lebih detail. (Anda juga dapat melompat ke bagian Model SNGP untuk melihat bagaimana model lengkap diimplementasikan.)
Pembungkus Normalisasi Spektral
SpectralNormalization adalah pembungkus lapisan Keras. Itu dapat diterapkan ke lapisan Padat yang ada seperti ini:
dense = tf.keras.layers.Dense(units=10)
dense = nlp_layers.SpectralNormalization(dense, norm_multiplier=0.9)
Normalisasi spektral mengatur bobot tersembunyi \(W\) dengan secara bertahap memandu norma spektralnya (yaitu, nilai eigen terbesar dari \(W\)) menuju nilai target norm_multiplier .
Lapisan Proses Gaussian (GP)
RandomFeatureGaussianProcess mengimplementasikan aproksimasi berbasis fitur acak ke model proses Gaussian yang dapat dilatih dari ujung ke ujung dengan jaringan saraf yang dalam. Di bawah tenda, lapisan proses Gaussian mengimplementasikan jaringan dua lapisan:
\[logits(x) = \Phi(x) \beta, \quad \Phi(x)=\sqrt{\frac{2}{M} } * cos(Wx + b)\]
Di sini \(x\) adalah input, dan \(W\) dan \(b\) adalah bobot beku yang diinisialisasi secara acak dari distribusi Gaussian dan seragam. (Oleh karena itu \(\Phi(x)\) disebut "fitur acak".) \(\beta\) adalah bobot kernel yang dapat dipelajari mirip dengan berat lapisan Padat.
batch_size = 32
input_dim = 1024
num_classes = 10
gp_layer = nlp_layers.RandomFeatureGaussianProcess(units=num_classes,
num_inducing=1024,
normalize_input=False,
scale_random_features=True,
gp_cov_momentum=-1)
Parameter utama dari lapisan GP adalah:
-
units: Dimensi dari output logits. -
num_inducing: Dimensi \(M\) dari bobot tersembunyi \(W\). Standar ke 1024. -
normalize_input: Apakah akan menerapkan normalisasi lapisan ke input \(x\). -
scale_random_features: Apakah akan menerapkan skala \(\sqrt{2/M}\) ke output tersembunyi.
-
gp_cov_momentummengontrol bagaimana model kovarians dihitung. Jika diatur ke nilai positif (misalnya, 0,999), matriks kovarians dihitung menggunakan pembaruan rata-rata bergerak berbasis momentum (mirip dengan normalisasi batch). Jika diatur ke -1, matriks kovarians diperbarui tanpa momentum.
Diberikan input batch dengan shape (batch_size, input_dim) , lapisan GP mengembalikan tensor logits (shape (batch_size, num_classes) ) untuk prediksi, dan juga covmat tensor (shape (batch_size, batch_size) ) yang merupakan matriks kovarians posterior dari log batch.
embedding = tf.random.normal(shape=(batch_size, input_dim))
logits, covmat = gp_layer(embedding)
Secara teoritis, dimungkinkan untuk memperluas algoritme untuk menghitung nilai varians yang berbeda untuk kelas yang berbeda (seperti yang diperkenalkan dalam makalah SNGP asli ). Namun, ini sulit untuk menskalakan masalah dengan ruang keluaran yang besar (misalnya, ImageNet atau pemodelan bahasa).
Model SNGP lengkap
Mengingat kelas dasar DeepResNet , model SNGP dapat diimplementasikan dengan mudah dengan memodifikasi lapisan tersembunyi dan keluaran jaringan sisa. Untuk kompatibilitas dengan Keras model.fit() API, ubah juga metode call() model sehingga hanya mengeluarkan logits selama pelatihan.
class DeepResNetSNGP(DeepResNet):
def __init__(self, spec_norm_bound=0.9, **kwargs):
self.spec_norm_bound = spec_norm_bound
super().__init__(**kwargs)
def make_dense_layer(self):
"""Applies spectral normalization to the hidden layer."""
dense_layer = super().make_dense_layer()
return nlp_layers.SpectralNormalization(
dense_layer, norm_multiplier=self.spec_norm_bound)
def make_output_layer(self, num_classes):
"""Uses Gaussian process as the output layer."""
return nlp_layers.RandomFeatureGaussianProcess(
num_classes,
gp_cov_momentum=-1,
**self.classifier_kwargs)
def call(self, inputs, training=False, return_covmat=False):
# Gets logits and covariance matrix from GP layer.
logits, covmat = super().call(inputs)
# Returns only logits during training.
if not training and return_covmat:
return logits, covmat
return logits
Gunakan arsitektur yang sama dengan model deterministik.
resnet_config
{'num_classes': 2, 'num_layers': 6, 'num_hidden': 128}
sngp_model = DeepResNetSNGP(**resnet_config)
sngp_model.build((None, 2))
sngp_model.summary()
Model: "deep_res_net_sngp"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_9 (Dense) multiple 384
spectral_normalization_1 (S multiple 16768
pectralNormalization)
spectral_normalization_2 (S multiple 16768
pectralNormalization)
spectral_normalization_3 (S multiple 16768
pectralNormalization)
spectral_normalization_4 (S multiple 16768
pectralNormalization)
spectral_normalization_5 (S multiple 16768
pectralNormalization)
spectral_normalization_6 (S multiple 16768
pectralNormalization)
random_feature_gaussian_pro multiple 1182722
cess (RandomFeatureGaussian
Process)
=================================================================
Total params: 1,283,714
Trainable params: 101,120
Non-trainable params: 1,182,594
_________________________________________________________________
Terapkan panggilan balik Keras untuk mengatur ulang matriks kovarians di awal zaman baru.
class ResetCovarianceCallback(tf.keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs=None):
"""Resets covariance matrix at the begining of the epoch."""
if epoch > 0:
self.model.classifier.reset_covariance_matrix()
Tambahkan panggilan balik ini ke kelas model DeepResNetSNGP .
class DeepResNetSNGPWithCovReset(DeepResNetSNGP):
def fit(self, *args, **kwargs):
"""Adds ResetCovarianceCallback to model callbacks."""
kwargs["callbacks"] = list(kwargs.get("callbacks", []))
kwargs["callbacks"].append(ResetCovarianceCallback())
return super().fit(*args, **kwargs)
Model kereta api
Gunakan tf.keras.model.fit untuk melatih model.
sngp_model = DeepResNetSNGPWithCovReset(**resnet_config)
sngp_model.compile(**train_config)
sngp_model.fit(train_examples, train_labels, **fit_config)
Epoch 1/100 8/8 [==============================] - 2s 5ms/step - loss: 0.6223 - sparse_categorical_accuracy: 0.9570 Epoch 2/100 8/8 [==============================] - 0s 4ms/step - loss: 0.5310 - sparse_categorical_accuracy: 0.9980 Epoch 3/100 8/8 [==============================] - 0s 4ms/step - loss: 0.4766 - sparse_categorical_accuracy: 0.9990 Epoch 4/100 8/8 [==============================] - 0s 5ms/step - loss: 0.4346 - sparse_categorical_accuracy: 0.9980 Epoch 5/100 8/8 [==============================] - 0s 5ms/step - loss: 0.4015 - sparse_categorical_accuracy: 0.9980 Epoch 6/100 8/8 [==============================] - 0s 5ms/step - loss: 0.3757 - sparse_categorical_accuracy: 0.9990 Epoch 7/100 8/8 [==============================] - 0s 4ms/step - loss: 0.3525 - sparse_categorical_accuracy: 0.9990 Epoch 8/100 8/8 [==============================] - 0s 4ms/step - loss: 0.3305 - sparse_categorical_accuracy: 0.9990 Epoch 9/100 8/8 [==============================] - 0s 5ms/step - loss: 0.3144 - sparse_categorical_accuracy: 0.9980 Epoch 10/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2975 - sparse_categorical_accuracy: 0.9990 Epoch 11/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2832 - sparse_categorical_accuracy: 0.9990 Epoch 12/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2707 - sparse_categorical_accuracy: 0.9990 Epoch 13/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2568 - sparse_categorical_accuracy: 0.9990 Epoch 14/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2470 - sparse_categorical_accuracy: 0.9970 Epoch 15/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2361 - sparse_categorical_accuracy: 0.9990 Epoch 16/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2271 - sparse_categorical_accuracy: 0.9990 Epoch 17/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2182 - sparse_categorical_accuracy: 0.9990 Epoch 18/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2097 - sparse_categorical_accuracy: 0.9990 Epoch 19/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2018 - sparse_categorical_accuracy: 0.9990 Epoch 20/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1940 - sparse_categorical_accuracy: 0.9980 Epoch 21/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1892 - sparse_categorical_accuracy: 0.9990 Epoch 22/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1821 - sparse_categorical_accuracy: 0.9980 Epoch 23/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1768 - sparse_categorical_accuracy: 0.9990 Epoch 24/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1702 - sparse_categorical_accuracy: 0.9980 Epoch 25/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1664 - sparse_categorical_accuracy: 0.9990 Epoch 26/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1604 - sparse_categorical_accuracy: 0.9990 Epoch 27/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1565 - sparse_categorical_accuracy: 0.9990 Epoch 28/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1517 - sparse_categorical_accuracy: 0.9990 Epoch 29/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1469 - sparse_categorical_accuracy: 0.9990 Epoch 30/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1431 - sparse_categorical_accuracy: 0.9980 Epoch 31/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1385 - sparse_categorical_accuracy: 0.9980 Epoch 32/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1351 - sparse_categorical_accuracy: 0.9990 Epoch 33/100 8/8 [==============================] - 0s 5ms/step - loss: 0.1312 - sparse_categorical_accuracy: 0.9980 Epoch 34/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1289 - sparse_categorical_accuracy: 0.9990 Epoch 35/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1254 - sparse_categorical_accuracy: 0.9980 Epoch 36/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1223 - sparse_categorical_accuracy: 0.9980 Epoch 37/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1180 - sparse_categorical_accuracy: 0.9990 Epoch 38/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1167 - sparse_categorical_accuracy: 0.9990 Epoch 39/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1132 - sparse_categorical_accuracy: 0.9980 Epoch 40/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1110 - sparse_categorical_accuracy: 0.9990 Epoch 41/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1075 - sparse_categorical_accuracy: 0.9990 Epoch 42/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1067 - sparse_categorical_accuracy: 0.9990 Epoch 43/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1034 - sparse_categorical_accuracy: 0.9990 Epoch 44/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1006 - sparse_categorical_accuracy: 0.9990 Epoch 45/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0991 - sparse_categorical_accuracy: 0.9990 Epoch 46/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0963 - sparse_categorical_accuracy: 0.9990 Epoch 47/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0943 - sparse_categorical_accuracy: 0.9980 Epoch 48/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0925 - sparse_categorical_accuracy: 0.9990 Epoch 49/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0905 - sparse_categorical_accuracy: 0.9990 Epoch 50/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0889 - sparse_categorical_accuracy: 0.9990 Epoch 51/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0863 - sparse_categorical_accuracy: 0.9980 Epoch 52/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0847 - sparse_categorical_accuracy: 0.9990 Epoch 53/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0831 - sparse_categorical_accuracy: 0.9980 Epoch 54/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0818 - sparse_categorical_accuracy: 0.9990 Epoch 55/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0799 - sparse_categorical_accuracy: 0.9990 Epoch 56/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0780 - sparse_categorical_accuracy: 0.9990 Epoch 57/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0768 - sparse_categorical_accuracy: 0.9990 Epoch 58/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0751 - sparse_categorical_accuracy: 0.9990 Epoch 59/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0748 - sparse_categorical_accuracy: 0.9990 Epoch 60/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0723 - sparse_categorical_accuracy: 0.9990 Epoch 61/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0712 - sparse_categorical_accuracy: 0.9990 Epoch 62/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0701 - sparse_categorical_accuracy: 0.9990 Epoch 63/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0701 - sparse_categorical_accuracy: 0.9990 Epoch 64/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0683 - sparse_categorical_accuracy: 0.9990 Epoch 65/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0665 - sparse_categorical_accuracy: 0.9990 Epoch 66/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0661 - sparse_categorical_accuracy: 0.9990 Epoch 67/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0636 - sparse_categorical_accuracy: 0.9990 Epoch 68/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0631 - sparse_categorical_accuracy: 0.9990 Epoch 69/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0620 - sparse_categorical_accuracy: 0.9990 Epoch 70/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0606 - sparse_categorical_accuracy: 0.9990 Epoch 71/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0601 - sparse_categorical_accuracy: 0.9980 Epoch 72/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0590 - sparse_categorical_accuracy: 0.9990 Epoch 73/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0586 - sparse_categorical_accuracy: 0.9990 Epoch 74/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0574 - sparse_categorical_accuracy: 0.9990 Epoch 75/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0565 - sparse_categorical_accuracy: 1.0000 Epoch 76/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0559 - sparse_categorical_accuracy: 0.9990 Epoch 77/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0549 - sparse_categorical_accuracy: 0.9990 Epoch 78/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0534 - sparse_categorical_accuracy: 1.0000 Epoch 79/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0532 - sparse_categorical_accuracy: 0.9990 Epoch 80/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0519 - sparse_categorical_accuracy: 1.0000 Epoch 81/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0511 - sparse_categorical_accuracy: 1.0000 Epoch 82/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0508 - sparse_categorical_accuracy: 0.9990 Epoch 83/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0499 - sparse_categorical_accuracy: 1.0000 Epoch 84/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0490 - sparse_categorical_accuracy: 1.0000 Epoch 85/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0490 - sparse_categorical_accuracy: 0.9990 Epoch 86/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0470 - sparse_categorical_accuracy: 1.0000 Epoch 87/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0468 - sparse_categorical_accuracy: 1.0000 Epoch 88/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0468 - sparse_categorical_accuracy: 1.0000 Epoch 89/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0453 - sparse_categorical_accuracy: 1.0000 Epoch 90/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0448 - sparse_categorical_accuracy: 1.0000 Epoch 91/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0441 - sparse_categorical_accuracy: 1.0000 Epoch 92/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0434 - sparse_categorical_accuracy: 1.0000 Epoch 93/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0431 - sparse_categorical_accuracy: 1.0000 Epoch 94/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0424 - sparse_categorical_accuracy: 1.0000 Epoch 95/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0420 - sparse_categorical_accuracy: 1.0000 Epoch 96/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0415 - sparse_categorical_accuracy: 1.0000 Epoch 97/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0409 - sparse_categorical_accuracy: 1.0000 Epoch 98/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0401 - sparse_categorical_accuracy: 1.0000 Epoch 99/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0396 - sparse_categorical_accuracy: 1.0000 Epoch 100/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0392 - sparse_categorical_accuracy: 1.0000 <keras.callbacks.History at 0x7ff7ac0f83d0>
Visualisasikan ketidakpastian
Pertama, hitung logit dan varians prediktif.
sngp_logits, sngp_covmat = sngp_model(test_examples, return_covmat=True)
sngp_variance = tf.linalg.diag_part(sngp_covmat)[:, None]
Sekarang hitung probabilitas prediksi posterior. Metode klasik untuk menghitung probabilitas prediktif dari model probabilistik adalah dengan menggunakan sampling Monte Carlo, yaitu,
\[E(p(x)) = \frac{1}{M} \sum_{m=1}^M logit_m(x), \]
di mana \(M\) adalah ukuran sampel, dan \(logit_m(x)\) adalah sampel acak dari SNGP posterior l10n \(MultivariateNormal\)( sngp_logits , sngp_covmat ). Namun, pendekatan ini bisa lambat untuk aplikasi yang sensitif terhadap latensi seperti mengemudi otonom atau penawaran waktu nyata. Sebagai gantinya, dapat memperkirakan \(E(p(x))\) menggunakan metode mean-field :
\[E(p(x)) \approx softmax(\frac{logit(x)}{\sqrt{1+ \lambda * \sigma^2(x)} })\]
di mana \(\sigma^2(x)\) adalah varians SNGP, dan \(\lambda\) sering dipilih sebagai \(\pi/8\) atau \(3/\pi^2\).
sngp_logits_adjusted = sngp_logits / tf.sqrt(1. + (np.pi / 8.) * sngp_variance)
sngp_probs = tf.nn.softmax(sngp_logits_adjusted, axis=-1)[:, 0]
Metode mean-field ini diimplementasikan sebagai fungsi built-in layers.gaussian_process.mean_field_logits :
def compute_posterior_mean_probability(logits, covmat, lambda_param=np.pi / 8.):
# Computes uncertainty-adjusted logits using the built-in method.
logits_adjusted = nlp_layers.gaussian_process.mean_field_logits(
logits, covmat, mean_field_factor=lambda_param)
return tf.nn.softmax(logits_adjusted, axis=-1)[:, 0]
sngp_logits, sngp_covmat = sngp_model(test_examples, return_covmat=True)
sngp_probs = compute_posterior_mean_probability(sngp_logits, sngp_covmat)
Ringkasan SNGP
def plot_predictions(pred_probs, model_name=""):
"""Plot normalized class probabilities and predictive uncertainties."""
# Compute predictive uncertainty.
uncertainty = pred_probs * (1. - pred_probs)
# Initialize the plot axes.
fig, axs = plt.subplots(1, 2, figsize=(14, 5))
# Plots the class probability.
pcm_0 = plot_uncertainty_surface(pred_probs, ax=axs[0])
# Plots the predictive uncertainty.
pcm_1 = plot_uncertainty_surface(uncertainty, ax=axs[1])
# Adds color bars and titles.
fig.colorbar(pcm_0, ax=axs[0])
fig.colorbar(pcm_1, ax=axs[1])
axs[0].set_title(f"Class Probability, {model_name}")
axs[1].set_title(f"(Normalized) Predictive Uncertainty, {model_name}")
plt.show()
Satukan semuanya. Seluruh prosedur (pelatihan, evaluasi dan perhitungan ketidakpastian) dapat dilakukan hanya dalam lima baris:
def train_and_test_sngp(train_examples, test_examples):
sngp_model = DeepResNetSNGPWithCovReset(**resnet_config)
sngp_model.compile(**train_config)
sngp_model.fit(train_examples, train_labels, verbose=0, **fit_config)
sngp_logits, sngp_covmat = sngp_model(test_examples, return_covmat=True)
sngp_probs = compute_posterior_mean_probability(sngp_logits, sngp_covmat)
return sngp_probs
sngp_probs = train_and_test_sngp(train_examples, test_examples)
Visualisasikan probabilitas kelas (kiri) dan ketidakpastian prediktif (kanan) dari model SNGP.
plot_predictions(sngp_probs, model_name="SNGP")

Ingat bahwa dalam plot probabilitas kelas (kiri), kuning dan ungu adalah probabilitas kelas. Ketika dekat dengan domain data pelatihan, SNGP dengan benar mengklasifikasikan contoh dengan keyakinan tinggi (yaitu, menetapkan probabilitas mendekati 0 atau 1). Ketika jauh dari data pelatihan, SNGP secara bertahap menjadi kurang percaya diri, dan probabilitas prediktifnya menjadi mendekati 0,5 sedangkan ketidakpastian model (dinormalisasi) naik menjadi 1.
Bandingkan ini dengan permukaan ketidakpastian model deterministik:
plot_predictions(resnet_probs, model_name="Deterministic")

Seperti disebutkan sebelumnya, model deterministik tidak sadar jarak . Ketidakpastiannya ditentukan oleh jarak contoh uji dari batas keputusan. Ini mengarahkan model untuk menghasilkan prediksi yang terlalu percaya diri untuk contoh di luar domain (merah).
Perbandingan dengan pendekatan ketidakpastian lainnya
Bagian ini membandingkan ketidakpastian SNGP dengan putus sekolah Monte Carlo dan Deep ensemble .
Kedua metode ini didasarkan pada rata-rata Monte Carlo dari beberapa model deterministik lewatan ke depan. Pertama-tama atur ukuran ansambel \(M\).
num_ensemble = 10
putus sekolah Monte Carlo
Mengingat jaringan saraf terlatih dengan lapisan Dropout, putus sekolah Monte Carlo menghitung probabilitas prediksi rata-rata
\[E(p(x)) = \frac{1}{M}\sum_{m=1}^M softmax(logit_m(x))\]
dengan rata-rata pada beberapa umpan maju yang diaktifkan Dropout \(\{logit_m(x)\}_{m=1}^M\).
def mc_dropout_sampling(test_examples):
# Enable dropout during inference.
return resnet_model(test_examples, training=True)
# Monte Carlo dropout inference.
dropout_logit_samples = [mc_dropout_sampling(test_examples) for _ in range(num_ensemble)]
dropout_prob_samples = [tf.nn.softmax(dropout_logits, axis=-1)[:, 0] for dropout_logits in dropout_logit_samples]
dropout_probs = tf.reduce_mean(dropout_prob_samples, axis=0)
dropout_probs = tf.reduce_mean(dropout_prob_samples, axis=0)
plot_predictions(dropout_probs, model_name="MC Dropout")

Ansambel yang dalam
Ansambel dalam adalah metode canggih (tapi mahal) untuk ketidakpastian pembelajaran yang mendalam. Untuk melatih ansambel Deep, pertama-tama latih anggota ansambel \(M\) .
# Deep ensemble training
resnet_ensemble = []
for _ in range(num_ensemble):
resnet_model = DeepResNet(**resnet_config)
resnet_model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
resnet_model.fit(train_examples, train_labels, verbose=0, **fit_config)
resnet_ensemble.append(resnet_model)
Kumpulkan log dan hitung probabilitas prediksi rata-rata l10n \(E(p(x)) = \frac{1}{M}\sum_{m=1}^M softmax(logit_m(x))\).
# Deep ensemble inference
ensemble_logit_samples = [model(test_examples) for model in resnet_ensemble]
ensemble_prob_samples = [tf.nn.softmax(logits, axis=-1)[:, 0] for logits in ensemble_logit_samples]
ensemble_probs = tf.reduce_mean(ensemble_prob_samples, axis=0)
plot_predictions(ensemble_probs, model_name="Deep ensemble")

Baik MC Dropout dan Deep ensemble meningkatkan kemampuan ketidakpastian model dengan membuat batas keputusan menjadi kurang pasti. Namun, mereka berdua mewarisi keterbatasan jaringan dalam deterministik dalam kurangnya kesadaran jarak.
Ringkasan
Dalam tutorial ini, Anda memiliki:
- Menerapkan model SNGP pada pengklasifikasi dalam untuk meningkatkan kesadaran jaraknya.
- Melatih model SNGP end-to-end menggunakan Keras
model.fit()API. - Memvisualisasikan perilaku ketidakpastian SNGP.
- Membandingkan perilaku ketidakpastian antara SNGP, putus sekolah Monte Carlo dan model ensemble yang dalam.
Sumber daya dan bacaan lebih lanjut
- Lihat tutorial SNGP-BERT untuk contoh penerapan SNGP pada model BERT untuk pemahaman bahasa alami yang sadar akan ketidakpastian.
- Lihat Garis Dasar Ketidakpastian untuk penerapan model SNGP (dan banyak metode ketidakpastian lainnya) pada berbagai macam kumpulan data benchmark (misalnya, CIFAR , ImageNet , Deteksi toksisitas Jigsaw , dll).
- Untuk pemahaman yang lebih dalam tentang metode SNGP, lihat makalah Estimasi Ketidakpastian Sederhana dan Berprinsip dengan Pembelajaran Mendalam Deterministik melalui Kesadaran Jarak Jauh .