| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Questo notebook dimostra l'uso degli strumenti di inferenza approssimata TFP per incorporare un modello di osservazione (non gaussiano) durante l'adattamento e la previsione con modelli di serie temporali strutturali (STS). In questo esempio, utilizzeremo un modello di osservazione di Poisson per lavorare con dati di conteggio discreti.
import time
import matplotlib.pyplot as plt
import numpy as np
import tensorflow.compat.v2 as tf
import tensorflow_probability as tfp
from tensorflow_probability import bijectors as tfb
from tensorflow_probability import distributions as tfd
tf.enable_v2_behavior()
Dati sintetici
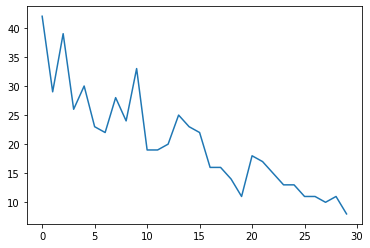
Per prima cosa genereremo alcuni dati di conteggio sintetici:
num_timesteps = 30
observed_counts = np.round(3 + np.random.lognormal(np.log(np.linspace(
num_timesteps, 5, num=num_timesteps)), 0.20, size=num_timesteps))
observed_counts = observed_counts.astype(np.float32)
plt.plot(observed_counts)
[<matplotlib.lines.Line2D at 0x7f940ae958d0>]
Modello
Specifichiamo un modello semplice con un trend lineare che cammina in modo casuale:
def build_model(approximate_unconstrained_rates):
trend = tfp.sts.LocalLinearTrend(
observed_time_series=approximate_unconstrained_rates)
return tfp.sts.Sum([trend],
observed_time_series=approximate_unconstrained_rates)
Invece di operare sulla serie temporale osservata, questo modello opererà sulla serie di parametri di velocità di Poisson che governano le osservazioni.
Poiché i tassi di Poisson devono essere positivi, utilizzeremo un biiettore per trasformare il modello STS a valori reali in una distribuzione su valori positivi. Il Softplus trasformazione \(y = \log(1 + \exp(x))\) è una scelta naturale, dal momento che è quasi lineare per valori positivi, ma altre scelte come Exp (che trasforma la normale camminata casuale in una passeggiata casuale lognormale) sono anche possibili.
positive_bijector = tfb.Softplus() # Or tfb.Exp()
# Approximate the unconstrained Poisson rate just to set heuristic priors.
# We could avoid this by passing explicit priors on all model params.
approximate_unconstrained_rates = positive_bijector.inverse(
tf.convert_to_tensor(observed_counts) + 0.01)
sts_model = build_model(approximate_unconstrained_rates)
Per utilizzare l'inferenza approssimata per un modello di osservazione non gaussiano, codificheremo il modello STS come TFP JointDistribution. Le variabili casuali in questa distribuzione congiunta sono i parametri del modello STS, le serie temporali dei tassi di Poisson latenti e i conteggi osservati.
def sts_with_poisson_likelihood_model():
# Encode the parameters of the STS model as random variables.
param_vals = []
for param in sts_model.parameters:
param_val = yield param.prior
param_vals.append(param_val)
# Use the STS model to encode the log- (or inverse-softplus)
# rate of a Poisson.
unconstrained_rate = yield sts_model.make_state_space_model(
num_timesteps, param_vals)
rate = positive_bijector.forward(unconstrained_rate[..., 0])
observed_counts = yield tfd.Poisson(rate, name='observed_counts')
model = tfd.JointDistributionCoroutineAutoBatched(sts_with_poisson_likelihood_model)
Preparazione per l'inferenza
Vogliamo dedurre le quantità non osservate nel modello, dati i conteggi osservati. Innanzitutto, condizioniamo la densità logaritmica articolare sui conteggi osservati.
pinned_model = model.experimental_pin(observed_counts=observed_counts)
Avremo anche bisogno di un biiettore vincolante per garantire che l'inferenza rispetti i vincoli sui parametri del modello STS (ad esempio, le scale devono essere positive).
constraining_bijector = pinned_model.experimental_default_event_space_bijector()
Inferenza con HMC
Useremo HMC (nello specifico, NUTS) per campionare dal giunto posteriore sui parametri del modello e sui tassi latenti.
Questo sarà significativamente più lento rispetto all'adattamento di un modello STS standard con HMC, poiché oltre ai parametri del modello (relativamente piccolo numero di) dobbiamo anche dedurre l'intera serie di tassi di Poisson. Quindi eseguiremo un numero relativamente piccolo di passaggi; per le applicazioni in cui la qualità dell'inferenza è fondamentale, potrebbe avere senso aumentare questi valori o eseguire più catene.
Configurazione del campionatore
# Allow external control of sampling to reduce test runtimes.
num_results = 500 # @param { isTemplate: true}
num_results = int(num_results)
num_burnin_steps = 100 # @param { isTemplate: true}
num_burnin_steps = int(num_burnin_steps)
Innanzitutto specifichiamo un campionatore, e quindi utilizzare sample_chain per eseguire quel kernel campionamento ai campioni produrre.
sampler = tfp.mcmc.TransformedTransitionKernel(
tfp.mcmc.NoUTurnSampler(
target_log_prob_fn=pinned_model.unnormalized_log_prob,
step_size=0.1),
bijector=constraining_bijector)
adaptive_sampler = tfp.mcmc.DualAveragingStepSizeAdaptation(
inner_kernel=sampler,
num_adaptation_steps=int(0.8 * num_burnin_steps),
target_accept_prob=0.75)
initial_state = constraining_bijector.forward(
type(pinned_model.event_shape)(
*(tf.random.normal(part_shape)
for part_shape in constraining_bijector.inverse_event_shape(
pinned_model.event_shape))))
# Speed up sampling by tracing with `tf.function`.
@tf.function(autograph=False, jit_compile=True)
def do_sampling():
return tfp.mcmc.sample_chain(
kernel=adaptive_sampler,
current_state=initial_state,
num_results=num_results,
num_burnin_steps=num_burnin_steps,
trace_fn=None)
t0 = time.time()
samples = do_sampling()
t1 = time.time()
print("Inference ran in {:.2f}s.".format(t1-t0))
Inference ran in 24.83s.
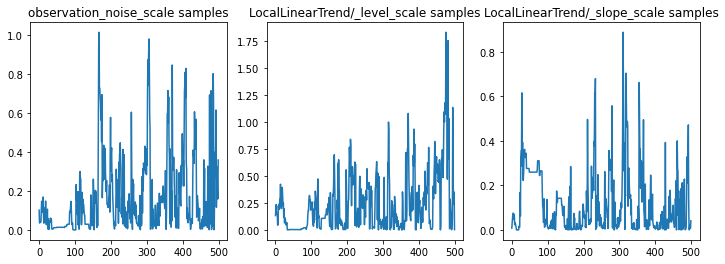
Possiamo controllare l'integrità dell'inferenza esaminando le tracce dei parametri. In questo caso sembrano aver esplorato più spiegazioni per i dati, il che è positivo, anche se più campioni sarebbero utili per giudicare quanto bene la catena si sta mescolando.
f = plt.figure(figsize=(12, 4))
for i, param in enumerate(sts_model.parameters):
ax = f.add_subplot(1, len(sts_model.parameters), i + 1)
ax.plot(samples[i])
ax.set_title("{} samples".format(param.name))
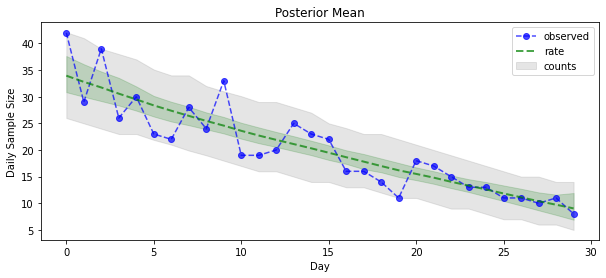
Ora per il payoff: vediamo il posteriore sui tassi di Poisson! Tracciamo anche l'intervallo predittivo dell'80% sui conteggi osservati e possiamo verificare che questo intervallo sembri contenere circa l'80% dei conteggi che abbiamo effettivamente osservato.
param_samples = samples[:-1]
unconstrained_rate_samples = samples[-1][..., 0]
rate_samples = positive_bijector.forward(unconstrained_rate_samples)
plt.figure(figsize=(10, 4))
mean_lower, mean_upper = np.percentile(rate_samples, [10, 90], axis=0)
pred_lower, pred_upper = np.percentile(np.random.poisson(rate_samples),
[10, 90], axis=0)
_ = plt.plot(observed_counts, color="blue", ls='--', marker='o', label='observed', alpha=0.7)
_ = plt.plot(np.mean(rate_samples, axis=0), label='rate', color="green", ls='dashed', lw=2, alpha=0.7)
_ = plt.fill_between(np.arange(0, 30), mean_lower, mean_upper, color='green', alpha=0.2)
_ = plt.fill_between(np.arange(0, 30), pred_lower, pred_upper, color='grey', label='counts', alpha=0.2)
plt.xlabel("Day")
plt.ylabel("Daily Sample Size")
plt.title("Posterior Mean")
plt.legend()
<matplotlib.legend.Legend at 0x7f93ffd35550>
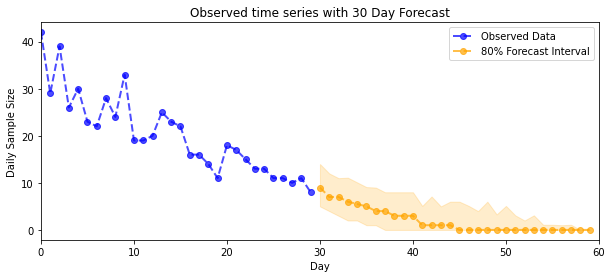
previsione
Per prevedere i conteggi osservati, utilizzeremo gli strumenti STS standard per costruire una distribuzione di previsione sui tassi latenti (in uno spazio non vincolato, sempre poiché STS è progettato per modellare dati con valori reali), quindi passeremo le previsioni campionate attraverso un'osservazione di Poisson modello:
def sample_forecasted_counts(sts_model, posterior_latent_rates,
posterior_params, num_steps_forecast,
num_sampled_forecasts):
# Forecast the future latent unconstrained rates, given the inferred latent
# unconstrained rates and parameters.
unconstrained_rates_forecast_dist = tfp.sts.forecast(sts_model,
observed_time_series=unconstrained_rate_samples,
parameter_samples=posterior_params,
num_steps_forecast=num_steps_forecast)
# Transform the forecast to positive-valued Poisson rates.
rates_forecast_dist = tfd.TransformedDistribution(
unconstrained_rates_forecast_dist,
positive_bijector)
# Sample from the forecast model following the chain rule:
# P(counts) = P(counts | latent_rates)P(latent_rates)
sampled_latent_rates = rates_forecast_dist.sample(num_sampled_forecasts)
sampled_forecast_counts = tfd.Poisson(rate=sampled_latent_rates).sample()
return sampled_forecast_counts, sampled_latent_rates
forecast_samples, rate_samples = sample_forecasted_counts(
sts_model,
posterior_latent_rates=unconstrained_rate_samples,
posterior_params=param_samples,
# Days to forecast:
num_steps_forecast=30,
num_sampled_forecasts=100)
forecast_samples = np.squeeze(forecast_samples)
def plot_forecast_helper(data, forecast_samples, CI=90):
"""Plot the observed time series alongside the forecast."""
plt.figure(figsize=(10, 4))
forecast_median = np.median(forecast_samples, axis=0)
num_steps = len(data)
num_steps_forecast = forecast_median.shape[-1]
plt.plot(np.arange(num_steps), data, lw=2, color='blue', linestyle='--', marker='o',
label='Observed Data', alpha=0.7)
forecast_steps = np.arange(num_steps, num_steps+num_steps_forecast)
CI_interval = [(100 - CI)/2, 100 - (100 - CI)/2]
lower, upper = np.percentile(forecast_samples, CI_interval, axis=0)
plt.plot(forecast_steps, forecast_median, lw=2, ls='--', marker='o', color='orange',
label=str(CI) + '% Forecast Interval', alpha=0.7)
plt.fill_between(forecast_steps,
lower,
upper, color='orange', alpha=0.2)
plt.xlim([0, num_steps+num_steps_forecast])
ymin, ymax = min(np.min(forecast_samples), np.min(data)), max(np.max(forecast_samples), np.max(data))
yrange = ymax-ymin
plt.title("{}".format('Observed time series with ' + str(num_steps_forecast) + ' Day Forecast'))
plt.xlabel('Day')
plt.ylabel('Daily Sample Size')
plt.legend()
plot_forecast_helper(observed_counts, forecast_samples, CI=80)
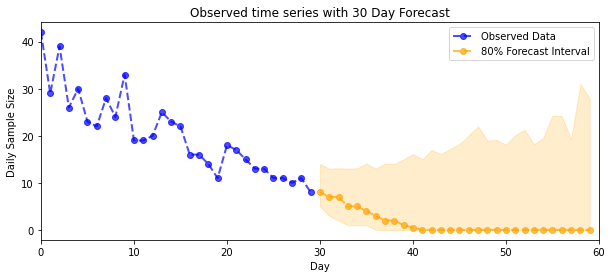
VI inferenza
Variazionale deduzione può essere problematico quando dedurre una serie a tempo pieno, come i nostri conteggi approssimativi (in contrasto con solo i parametri di una serie storica, come nei modelli STS standard). L'assunzione standard che le variabili abbiano posteriori indipendenti è del tutto sbagliata, poiché ogni timestep è correlato con i suoi vicini, il che può portare a sottovalutare l'incertezza. Per questo motivo, HMC può essere una scelta migliore per l'inferenza approssimativa su serie temporali complete. Tuttavia, VI può essere un po' più veloce e può essere utile per la prototipazione di modelli o nei casi in cui si può dimostrare empiricamente che le sue prestazioni sono "sufficientemente buone".
Per adattare il nostro modello con VI, costruiamo e ottimizziamo semplicemente un surrogato posteriore:
surrogate_posterior = tfp.experimental.vi.build_factored_surrogate_posterior(
event_shape=pinned_model.event_shape,
bijector=constraining_bijector)
# Allow external control of optimization to reduce test runtimes.
num_variational_steps = 1000 # @param { isTemplate: true}
num_variational_steps = int(num_variational_steps)
t0 = time.time()
losses = tfp.vi.fit_surrogate_posterior(pinned_model.unnormalized_log_prob,
surrogate_posterior,
optimizer=tf.optimizers.Adam(0.1),
num_steps=num_variational_steps)
t1 = time.time()
print("Inference ran in {:.2f}s.".format(t1-t0))
Inference ran in 11.37s.
plt.plot(losses)
plt.title("Variational loss")
_ = plt.xlabel("Steps")
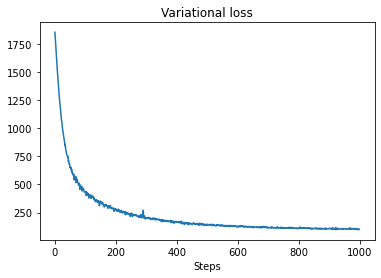
posterior_samples = surrogate_posterior.sample(50)
param_samples = posterior_samples[:-1]
unconstrained_rate_samples = posterior_samples[-1][..., 0]
rate_samples = positive_bijector.forward(unconstrained_rate_samples)
plt.figure(figsize=(10, 4))
mean_lower, mean_upper = np.percentile(rate_samples, [10, 90], axis=0)
pred_lower, pred_upper = np.percentile(
np.random.poisson(rate_samples), [10, 90], axis=0)
_ = plt.plot(observed_counts, color='blue', ls='--', marker='o',
label='observed', alpha=0.7)
_ = plt.plot(np.mean(rate_samples, axis=0), label='rate', color='green',
ls='dashed', lw=2, alpha=0.7)
_ = plt.fill_between(
np.arange(0, 30), mean_lower, mean_upper, color='green', alpha=0.2)
_ = plt.fill_between(np.arange(0, 30), pred_lower, pred_upper, color='grey',
label='counts', alpha=0.2)
plt.xlabel('Day')
plt.ylabel('Daily Sample Size')
plt.title('Posterior Mean')
plt.legend()
<matplotlib.legend.Legend at 0x7f93ff4735c0>
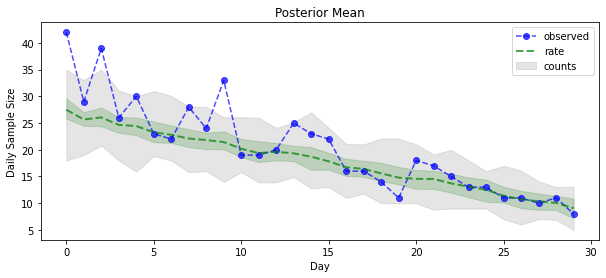
forecast_samples, rate_samples = sample_forecasted_counts(
sts_model,
posterior_latent_rates=unconstrained_rate_samples,
posterior_params=param_samples,
# Days to forecast:
num_steps_forecast=30,
num_sampled_forecasts=100)
forecast_samples = np.squeeze(forecast_samples)
plot_forecast_helper(observed_counts, forecast_samples, CI=80)