
Przykład kluczowego komponentu TensorFlow Extended
 Wyświetl źródło na GitHub
Wyświetl źródło na GitHubTen przykładowy notatnik colab ilustruje, jak TensorFlow Data Validation (TFDV) może być używany do badania i wizualizacji zestawu danych. Obejmuje to przeglądanie statystyk opisowych, wnioskowanie o schemacie, sprawdzanie i naprawianie anomalii oraz sprawdzanie dryfu i pochylenia w naszym zbiorze danych. Ważne jest, aby zrozumieć charakterystykę zestawu danych, w tym sposób, w jaki może się on zmieniać w czasie w potoku produkcyjnym. Ważne jest również, aby szukać anomalii w danych i porównywać zestawy danych do trenowania, oceny i udostępniania, aby upewnić się, że są one spójne.
Wykorzystamy dane z zestawu danych Taxi Trips udostępnionego przez miasto Chicago.
Przeczytaj więcej o zbiorze danych w Google BigQuery . Przeglądaj pełny zbiór danych w interfejsie użytkownika BigQuery .
Kolumny w zbiorze danych to:
| pickup_community_area | opłata | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| szerokość_odbioru | długość_odbioru | dropoff_latitude |
| dropoff_longitude | podróż_mile | pickup_census_tract |
| dropoff_census_tract | typ płatności | Spółka |
| trip_seconds | dropoff_community_area | porady |
Instaluj i importuj pakiety
Zainstaluj pakiety do weryfikacji danych TensorFlow.
Ulepsz Pip
Aby uniknąć aktualizacji Pip w systemie uruchomionym lokalnie, upewnij się, że działamy w Colab. Systemy lokalne można oczywiście aktualizować oddzielnie.
try:
import colab
!pip install --upgrade pip
except:
pass
Zainstaluj pakiety sprawdzania poprawności danych
Zainstaluj pakiety i zależności TensorFlow Data Validation, co zajmuje kilka minut. Możesz zobaczyć ostrzeżenia i błędy dotyczące niezgodnych wersji zależności, które rozwiążesz w następnej sekcji.
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
Importuj TensorFlow i przeładuj zaktualizowane pakiety
Poprzedni krok aktualizuje pakiety domyślne w środowisku Gooogle Colab, więc musisz ponownie załadować zasoby pakietu, aby rozwiązać nowe zależności.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
Przed kontynuowaniem sprawdź wersje TensorFlow i Data Validation.
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
Załaduj zbiór danych
Nasz zbiór danych pobierzemy z Google Cloud Storage.
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
Oblicz i wizualizuj statystyki
Najpierw użyjemy tfdv.generate_statistics_from_csv do obliczenia statystyk dla naszych danych treningowych. (zignoruj zgryźliwe ostrzeżenia)
TFDV może obliczać statystyki opisowe, które zapewniają szybki przegląd danych pod kątem występujących cech i kształtów ich rozkładu wartości.
Wewnętrznie TFDV wykorzystuje platformę przetwarzania równoległego danych Apache Beam do skalowania obliczeń statystycznych na dużych zbiorach danych. W przypadku aplikacji, które chcą głębiej zintegrować się z TFDV (np. dołączyć generowanie statystyk na końcu potoku generowania danych), interfejs API udostępnia również funkcję Beam PTransform do generowania statystyk.
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
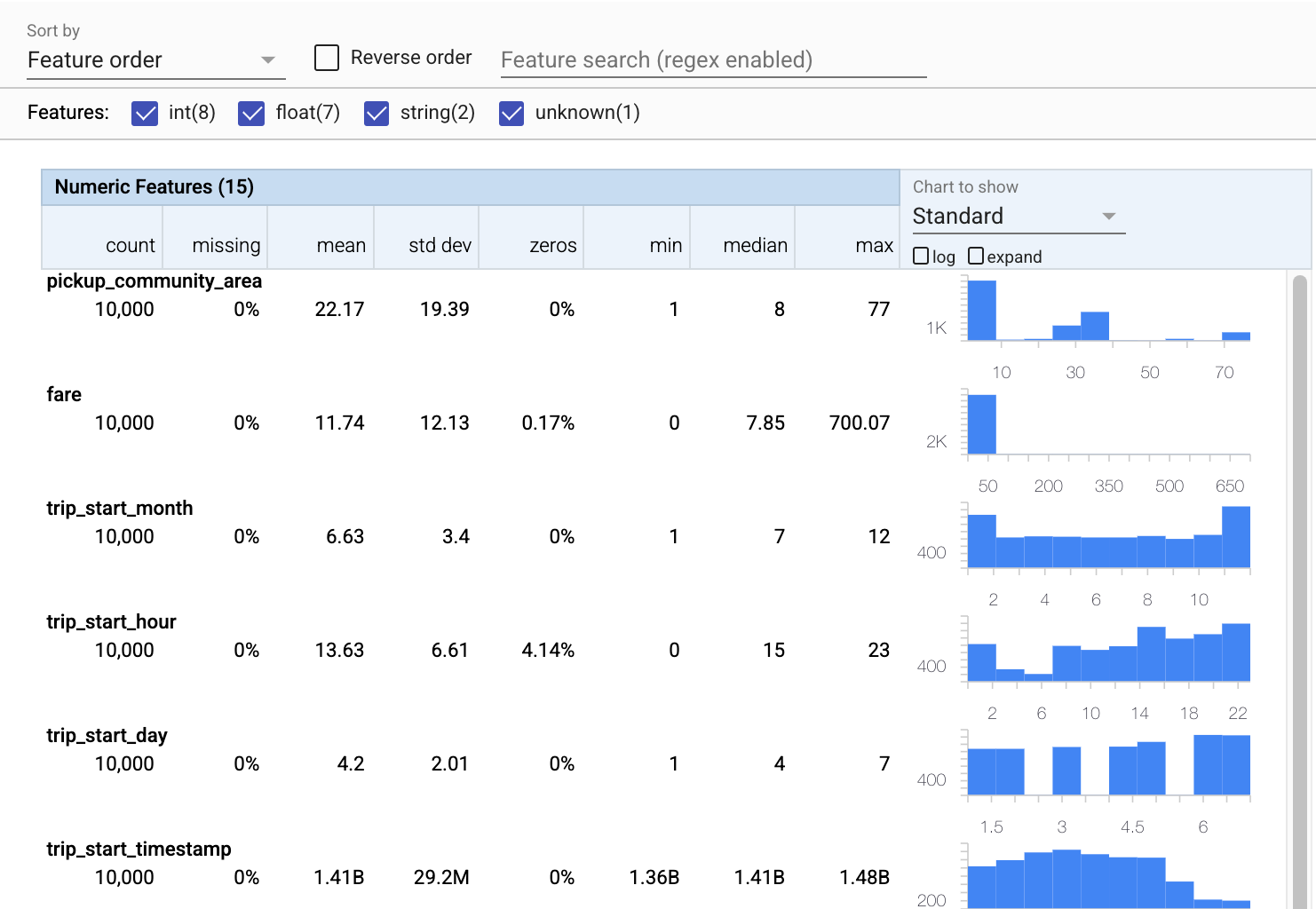
Teraz tfdv.visualize_statistics , który wykorzystuje Facets do stworzenia zwięzłej wizualizacji naszych danych treningowych:
- Zwróć uwagę, że cechy liczbowe i cechy kategoryczne są wizualizowane osobno oraz że wyświetlane są wykresy przedstawiające rozkłady dla każdej cechy.
- Zwróć uwagę, że funkcje z brakującymi lub zerowymi wartościami wyświetlają procent na czerwono jako wizualny wskaźnik, że mogą występować problemy z przykładami w tych funkcjach. Procent to procent przykładów, które mają brakujące lub zerowe wartości dla tej funkcji.
- Zauważ, że nie ma przykładów z wartościami dla
pickup_census_tract. To okazja do redukcji wymiarów! - Spróbuj kliknąć „rozwiń” nad wykresami, aby zmienić sposób wyświetlania
- Spróbuj najechać kursorem na słupki na wykresach, aby wyświetlić zakresy i liczby segmentów
- Spróbuj przełączać się między skalą logarytmiczną a liniową i zauważ, jak skala logarytmiczna ujawnia znacznie więcej szczegółów na temat funkcji kategorialnej
payment_type - Spróbuj wybrać „kwantyle” z menu „Wykres do pokazania” i najedź kursorem na znaczniki, aby wyświetlić procenty kwantyli
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
Wywnioskować schemat
Teraz tfdv.infer_schema do stworzenia schematu dla naszych danych. Schemat definiuje ograniczenia dla danych, które są istotne dla ML. Przykładowe ograniczenia obejmują typ danych każdej funkcji, niezależnie od tego, czy jest to numeryczny, czy kategoryczny, albo częstotliwość jego obecności w danych. Dla cech kategorycznych schemat definiuje również domenę - listę dopuszczalnych wartości. Ponieważ pisanie schematu może być żmudnym zadaniem, szczególnie w przypadku zestawów danych z wieloma funkcjami, TFDV zapewnia metodę generowania początkowej wersji schematu na podstawie statystyk opisowych.
Prawidłowe ustalenie schematu jest ważne, ponieważ reszta naszego potoku produkcyjnego będzie polegać na schemacie generowanym przez TFDV, aby był poprawny. Schemat zawiera również dokumentację danych, dlatego jest przydatny, gdy różni deweloperzy pracują na tych samych danych. Użyjmy tfdv.display_schema , aby wyświetlić wywnioskowany schemat, abyśmy mogli go przejrzeć.
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Sprawdź dane oceny pod kątem błędów
Do tej pory przyglądaliśmy się tylko danym treningowym. Ważne jest, aby nasze dane oceny były zgodne z naszymi danymi treningowymi, w tym używa tego samego schematu. Ważne jest również, aby dane oceny zawierały przykłady mniej więcej tych samych zakresów wartości dla naszych cech liczbowych, co dane treningowe, tak aby nasze pokrycie powierzchni strat podczas oceny było mniej więcej takie samo jak podczas treningu. To samo dotyczy cech kategorycznych. W przeciwnym razie możemy mieć problemy z treningiem, które nie zostały zidentyfikowane podczas oceny, ponieważ nie oszacowaliśmy części naszej powierzchni straty.
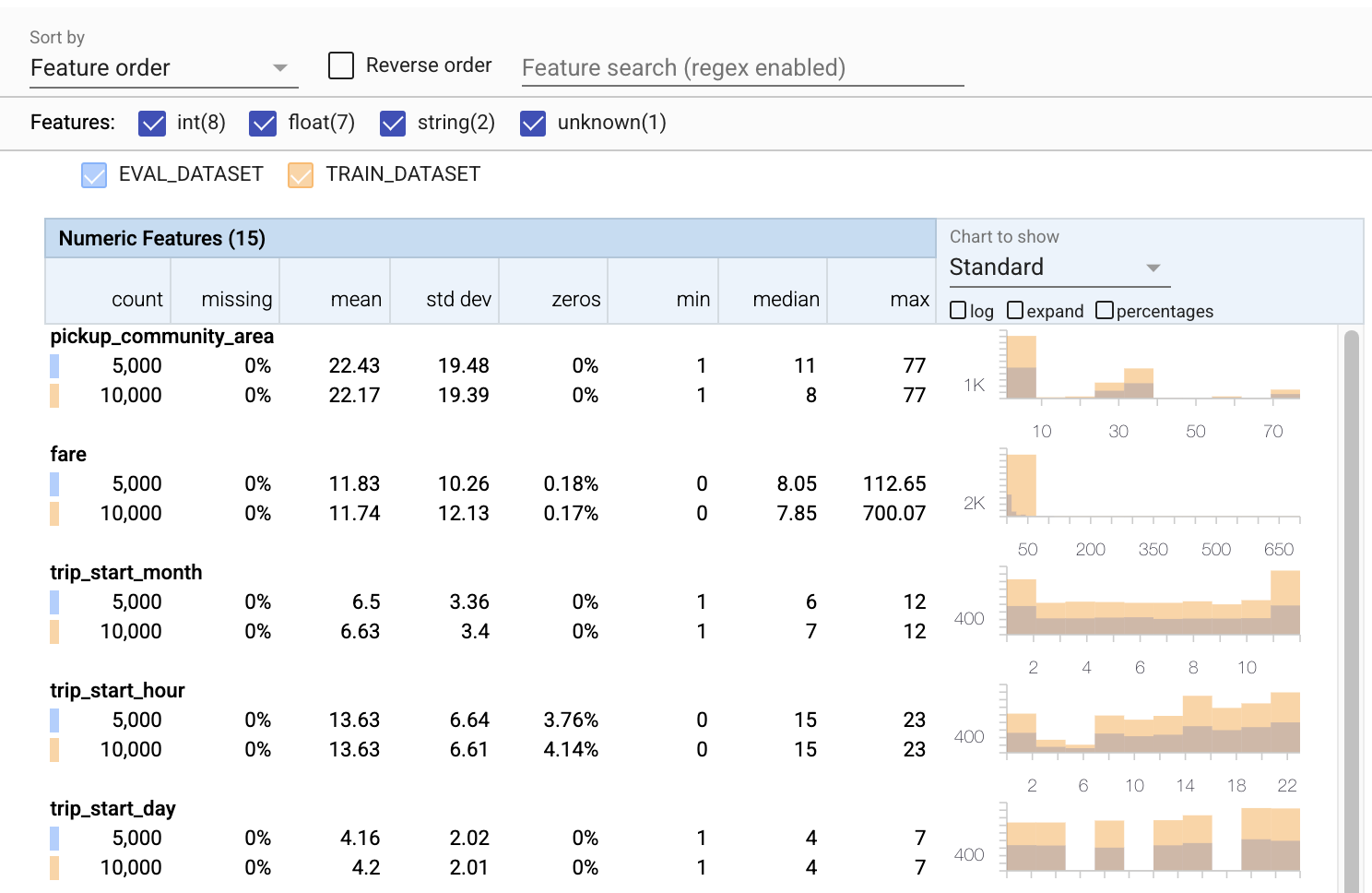
- Zauważ, że każda funkcja zawiera teraz statystyki zarówno dla zestawów danych uczących, jak i ewaluacyjnych.
- Zwróć uwagę, że wykresy zawierają teraz zarówno zestawy danych treningowych, jak i ewaluacyjnych, co ułatwia ich porównywanie.
- Zauważ, że wykresy zawierają teraz widok procentowy, który można łączyć z logarytmem lub domyślnymi skalami liniowymi.
- Zwróć uwagę, że średnia i mediana dla
trip_milessą różne dla zestawów danych uczących i ewaluacyjnych. Czy to spowoduje problemy? - Wow, maksymalne
tipssą bardzo różne w przypadku treningu w porównaniu z zestawami danych ewaluacyjnych. Czy to spowoduje problemy? - Kliknij rozwiń na wykresie Funkcje numeryczne i wybierz skalę logarytmiczną. Przejrzyj funkcję
trip_secondsi zwróć uwagę na różnicę w max. Czy ocena pominie części powierzchni ubytku?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
Sprawdź anomalie oceny
Czy nasz zestaw danych ewaluacyjnych jest zgodny ze schematem z naszego zestawu danych szkoleniowych? Jest to szczególnie ważne w przypadku cech kategorycznych, gdzie chcemy określić zakres dopuszczalnych wartości.
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
Napraw anomalie oceny w schemacie
Ups! Wygląda na to, że w naszych danych ewaluacyjnych mamy nowe wartości dla company , których nie mieliśmy w naszych danych szkoleniowych. Mamy również nową wartość dla payment_type . Należy to uznać za anomalie, ale to, co zdecydujemy się z nimi zrobić, zależy od naszej domeny wiedzy o danych. Jeśli anomalia rzeczywiście wskazuje na błąd danych, należy naprawić dane bazowe. W przeciwnym razie możemy po prostu zaktualizować schemat, aby uwzględnić wartości w eval dataset.
Dopóki nie zmienimy naszego zestawu danych oceny, nie możemy naprawić wszystkiego, ale możemy naprawić rzeczy w schemacie, które akceptujemy. Obejmuje to rozluźnienie naszego poglądu na to, co jest, a co nie jest anomalią dla poszczególnych funkcji, a także aktualizację naszego schematu w celu uwzględnienia brakujących wartości dla funkcji kategorycznych. TFDV pozwoliło nam odkryć, co musimy naprawić.
Wprowadźmy teraz te poprawki, a potem jeszcze raz przejrzyjmy.
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
Hej, spójrz na to! Sprawdziliśmy, że dane dotyczące szkolenia i oceny są teraz spójne! Dzięki TFDV ;)
Środowiska schematu
W tym przykładzie wydzieliliśmy również zbiór danych „obsługujących”, więc powinniśmy to również sprawdzić. Domyślnie wszystkie zestawy danych w potoku powinny używać tego samego schematu, ale często zdarzają się wyjątki. Na przykład w nadzorowanym uczeniu się musimy uwzględnić etykiety w naszym zbiorze danych, ale gdy służymy modelowi do wnioskowania, etykiety nie zostaną uwzględnione. W niektórych przypadkach konieczne jest wprowadzenie niewielkich zmian w schemacie.
Do wyrażenia takich wymagań można użyć środowisk . W szczególności funkcje w schemacie mogą być skojarzone z zestawem środowisk przy użyciu default_environment , in_environment i not_in_environment .
Na przykład w tym zbiorze danych funkcja tips jest uwzględniona jako etykieta szkolenia, ale brakuje jej w danych o wyświetlaniu. Bez określonego środowiska pojawi się jako anomalia.
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Poniżej omówimy funkcję tips . Mamy również wartość INT w sekundach naszej podróży, gdzie nasz schemat oczekiwał wartości FLOAT. Uświadamiając nam tę różnicę, TFDV pomaga odkryć niespójności w sposobie generowania danych do szkolenia i obsługi. Bardzo łatwo jest nie zdawać sobie sprawy z takich problemów, dopóki wydajność modelu nie ucierpi, czasami katastrofalnie. Może to być poważny problem, ale nie musi, ale w każdym przypadku powinno to być powodem do dalszego zbadania.
W takim przypadku możemy bezpiecznie przekonwertować wartości INT na FLOAT, więc chcemy powiedzieć TFDV, aby użył naszego schematu do wywnioskowania typu. Zróbmy to teraz.
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
Teraz mamy tylko funkcję tips (która jest naszą etykietą) wyświetlaną jako anomalia („Upuszczona kolumna”). Oczywiście nie spodziewamy się, że nasze dane o wyświetlaniu będą zawierały etykiety, więc powiedzmy TFDV, aby to zignorował.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
Sprawdź dryf i przekrzywienie
Oprócz sprawdzania, czy zestaw danych jest zgodny z oczekiwaniami określonymi w schemacie, TFDV zapewnia również funkcje wykrywania dryfu i pochylenia. TFDV przeprowadza tę kontrolę, porównując statystyki różnych zestawów danych na podstawie komparatorów dryfu/skosu określonych w schemacie.
Dryf
Wykrywanie dryfu jest obsługiwane dla cech kategorialnych i między kolejnymi przedziałami danych (tj. między przedziałem N a przedziałem N+1), na przykład między różnymi dniami danych treningowych. Dryf wyrażamy w postaci odległości L-nieskończoności , a odległość progową można ustawić tak, aby otrzymywać ostrzeżenia, gdy dryf jest wyższy niż dopuszczalny. Ustawienie prawidłowej odległości jest zazwyczaj procesem iteracyjnym, wymagającym znajomości domeny i eksperymentowania.
Krzywy
TFDV może wykryć trzy różne rodzaje pochylenia danych — pochylenie schematu, pochylenie funkcji i pochylenie dystrybucji.
Pochylenie schematu
Pochylenie schematu występuje, gdy dane uczące i obsługujące nie są zgodne z tym samym schematem. Oczekuje się, że zarówno dane dotyczące uczenia, jak i udostępniania będą zgodne z tym samym schematem. Wszelkie oczekiwane odchylenia między tymi dwoma (takie jak funkcja etykiety występująca tylko w danych uczących, ale nie w udostępnianiu) należy określić za pomocą pola środowiska w schemacie.
Pochylenie funkcji
Pochylenie cech występuje, gdy wartości cech, na których trenuje model, różnią się od wartości cech, które widzi w czasie udostępniania. Na przykład może się to zdarzyć, gdy:
- Źródło danych, które zapewnia pewne wartości funkcji, jest modyfikowane między treningiem a czasem wyświetlania
- Istnieje inna logika generowania funkcji między szkoleniem a serwowaniem. Na przykład, jeśli zastosujesz jakieś przekształcenie tylko w jednej z dwóch ścieżek kodu.
Pochylenie dystrybucji
Pochylenie dystrybucji występuje, gdy dystrybucja uczącego zestawu danych znacznie różni się od dystrybucji obsługującego zestawu danych. Jedną z głównych przyczyn przekrzywienia rozkładu jest używanie innego kodu lub różnych źródeł danych do generowania zestawu danych uczących. Innym powodem jest wadliwy mechanizm próbkowania, który wybiera niereprezentatywną podpróbkę danych obsługujących do trenowania.
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
W tym przykładzie widzimy pewne dryfowanie, ale jest ono znacznie poniżej ustawionego przez nas progu.
Zatrzymaj schemat
Teraz, gdy schemat został sprawdzony i wyselekcjonowany, przechowamy go w pliku, aby odzwierciedlić jego „zamrożony” stan.
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
Kiedy używać TFDV
Łatwo jest myśleć, że TFDV stosuje się tylko na początku potoku szkoleniowego, tak jak to zrobiliśmy tutaj, ale w rzeczywistości ma wiele zastosowań. Oto kilka innych:
- Sprawdzanie poprawności nowych danych w celu wnioskowania, aby upewnić się, że nie zaczęliśmy nagle otrzymywać złych funkcji
- Sprawdzanie poprawności nowych danych w celu wnioskowania, aby upewnić się, że nasz model został przeszkolony na tej części powierzchni decyzyjnej
- Sprawdzanie poprawności naszych danych po ich przekształceniu i wykonaniu inżynierii funkcji (prawdopodobnie przy użyciu TensorFlow Transform ), aby upewnić się, że nie zrobiliśmy nic złego