
 GitHub에서소스 보기 GitHub에서소스 보기 |
그래디언트 부스팅 모델 훈련에 대한 전체 연습은 부스트 트리 튜토리얼을 확인하세요. 이 튜토리얼에서는 다음을 수행합니다.
- 부스트 트리 모델을 로컬 및 전역으로 해석하는 방법 알아보기
- 부스트 트리 모델이 데이터세트와 얼마나 잘 맞는지 직관적으로 이해하기
부스트 트리 모델을 로컬 및 전역으로 해석하는 방법
로컬 해석 가능성은 개별 예제 수준에서 모델의 예측에 대한 이해를 의미하는 반면, 전역 해석 가능성은 모델 전체에 대한 이해를 의미합니다. 이러한 기법은 머신러닝(ML) 실무자가 모델 개발 단계에서 바이어스와 버그를 감지하는 데 도움이 될 수 있습니다.
로컬 해석 가능성을 위해 인스턴스별 기여도를 생성하고 시각화하는 방법을 배우게 됩니다. 특성 중요도와의 구분을 위해 이러한 값을 방향성 특성 기여(DFC)라고 부릅니다.
전역 해석 가능성을 위해 이득 기반의 특성 중요도인 순열 특성 중요도를 검색 및 시각화하고 집계된 DFC도 표시합니다.
titanic 데이터세트 로드하기
여기서는 titanic 데이터세트를 이용하며 (다소 음산한) 목표는 성별, 나이, 등급 등과 같은 특징을 고려하여 승객 생존을 예측하는 것입니다.
pip install -q statsmodelsimport numpy as np
import pandas as pd
from IPython.display import clear_output
# Load dataset.
dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')
dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
import tensorflow as tf
tf.random.set_seed(123)
특성에 대한 설명은 이전 튜토리얼을 검토하세요.
특성 열, input_fn을 만들고 예측 도구 훈련시키기
데이터 전처리
원래 숫자 열을 그대로 사용하고 원핫-인코딩 범주별 변수를 사용하여 특성 열을 만듭니다.
fc = tf.feature_column
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
def one_hot_cat_column(feature_name, vocab):
return fc.indicator_column(
fc.categorical_column_with_vocabulary_list(feature_name,
vocab))
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
# Need to one-hot encode categorical features.
vocabulary = dftrain[feature_name].unique()
feature_columns.append(one_hot_cat_column(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
feature_columns.append(fc.numeric_column(feature_name,
dtype=tf.float32))
입력 파이프라인 빌드하기
Pandas로부터 직접 데이터를 읽기 위해 tf.data API에서 from_tensor_slices 메서드를 사용하여 입력 함수를 생성합니다.
# Use entire batch since this is such a small dataset.
NUM_EXAMPLES = len(y_train)
def make_input_fn(X, y, n_epochs=None, shuffle=True):
def input_fn():
dataset = tf.data.Dataset.from_tensor_slices((X.to_dict(orient='list'), y))
if shuffle:
dataset = dataset.shuffle(NUM_EXAMPLES)
# For training, cycle thru dataset as many times as need (n_epochs=None).
dataset = (dataset
.repeat(n_epochs)
.batch(NUM_EXAMPLES))
return dataset
return input_fn
# Training and evaluation input functions.
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, shuffle=False, n_epochs=1)
모델 훈련하기
params = {
'n_trees': 50,
'max_depth': 3,
'n_batches_per_layer': 1,
# You must enable center_bias = True to get DFCs. This will force the model to
# make an initial prediction before using any features (e.g. use the mean of
# the training labels for regression or log odds for classification when
# using cross entropy loss).
'center_bias': True
}
est = tf.estimator.BoostedTreesClassifier(feature_columns, **params)
# Train model.
est.train(train_input_fn, max_steps=100)
# Evaluation.
results = est.evaluate(eval_input_fn)
clear_output()
pd.Series(results).to_frame()
성능상의 이유로 데이터가 메모리에 맞는 경우 boosted_trees_classifier_train_in_memory 함수를 사용하는 것이 좋습니다. 그러나 훈련 시간이 중요하지 않거나 데이터세트가 매우 커서 분산 훈련을 수행하려는 경우 위에 표시된 tf.estimator.BoostedTrees API를 사용하세요.
이 메서드를 사용할 때는 메서드가 전체 데이터세트에서 작동하므로 입력 데이터를 배치 처리하지 않아야 합니다.
in_memory_params = dict(params)
in_memory_params['n_batches_per_layer'] = 1
# In-memory input_fn does not use batching.
def make_inmemory_train_input_fn(X, y):
y = np.expand_dims(y, axis=1)
def input_fn():
return dict(X), y
return input_fn
train_input_fn = make_inmemory_train_input_fn(dftrain, y_train)
# Train the model.
est = tf.estimator.BoostedTreesClassifier(
feature_columns,
train_in_memory=True,
**in_memory_params)
est.train(train_input_fn)
print(est.evaluate(eval_input_fn))
INFO:tensorflow:Using default config.
WARNING:tensorflow:Using temporary folder as model directory: /tmp/tmp3yc0aq6c
INFO:tensorflow:Using config: {'_model_dir': '/tmp/tmp3yc0aq6c', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_session_creation_timeout_secs': 7200, '_service': None, '_cluster_spec': ClusterSpec({}), '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Create CheckpointSaverHook.
WARNING:tensorflow:Issue encountered when serializing resources.
Type is unsupported, or the types of the items don't match field type in CollectionDef. Note this is a warning and probably safe to ignore.
'_Resource' object has no attribute 'name'
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
WARNING:tensorflow:Issue encountered when serializing resources.
Type is unsupported, or the types of the items don't match field type in CollectionDef. Note this is a warning and probably safe to ignore.
'_Resource' object has no attribute 'name'
INFO:tensorflow:Calling checkpoint listeners before saving checkpoint 0...
INFO:tensorflow:Saving checkpoints for 0 into /tmp/tmp3yc0aq6c/model.ckpt.
WARNING:tensorflow:Issue encountered when serializing resources.
Type is unsupported, or the types of the items don't match field type in CollectionDef. Note this is a warning and probably safe to ignore.
'_Resource' object has no attribute 'name'
INFO:tensorflow:Calling checkpoint listeners after saving checkpoint 0...
INFO:tensorflow:loss = 0.6931472, step = 0
WARNING:tensorflow:It seems that global step (tf.train.get_global_step) has not been increased. Current value (could be stable): 0 vs previous value: 0. You could increase the global step by passing tf.train.get_global_step() to Optimizer.apply_gradients or Optimizer.minimize.
INFO:tensorflow:global_step/sec: 95.5791
INFO:tensorflow:loss = 0.34396845, step = 99 (1.047 sec)
INFO:tensorflow:Calling checkpoint listeners before saving checkpoint 153...
INFO:tensorflow:Saving checkpoints for 153 into /tmp/tmp3yc0aq6c/model.ckpt.
WARNING:tensorflow:Issue encountered when serializing resources.
Type is unsupported, or the types of the items don't match field type in CollectionDef. Note this is a warning and probably safe to ignore.
'_Resource' object has no attribute 'name'
INFO:tensorflow:Calling checkpoint listeners after saving checkpoint 153...
INFO:tensorflow:Loss for final step: 0.32042706.
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:43Z
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Inference Time : 0.51770s
INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:44
INFO:tensorflow:Saving dict for global step 153: accuracy = 0.81439394, accuracy_baseline = 0.625, auc = 0.86853385, auc_precision_recall = 0.8522887, average_loss = 0.4158357, global_step = 153, label/mean = 0.375, loss = 0.4158357, precision = 0.7604167, prediction/mean = 0.38813925, recall = 0.7373737
WARNING:tensorflow:Issue encountered when serializing resources.
Type is unsupported, or the types of the items don't match field type in CollectionDef. Note this is a warning and probably safe to ignore.
'_Resource' object has no attribute 'name'
INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153
{'accuracy': 0.81439394, 'accuracy_baseline': 0.625, 'auc': 0.86853385, 'auc_precision_recall': 0.8522887, 'average_loss': 0.4158357, 'label/mean': 0.375, 'loss': 0.4158357, 'precision': 0.7604167, 'prediction/mean': 0.38813925, 'recall': 0.7373737, 'global_step': 153}
모델 해석 및 플롯하기
import matplotlib.pyplot as plt
import seaborn as sns
sns_colors = sns.color_palette('colorblind')
로컬 해석 가능성
다음으로 Palczewska 등과 Saabas가 랜덤 포레스트 해석(Interpreting Random Forests)에서 설명한 접근 방식을 사용하여 개별 예측을 설명하는 방향성 특성 기여(DFC)를 출력합니다(이 메서드는 treeinterpreter 패키지의 랜덤 포레스트에 대한 scikit-learn에서도 이용할 수 있음). DFC는 다음을 사용하여 생성됩니다.
pred_dicts = list(est.experimental_predict_with_explanations(pred_input_fn))
(참고: 앞의 experimental 부분을 삭제하기 전에 API를 수정할 수 있으므로 이 메서드의 이름은 experimental로 지정됩니다.)
pred_dicts = list(est.experimental_predict_with_explanations(eval_input_fn))
INFO:tensorflow:Using config: {'_model_dir': '/tmp/tmp3yc0aq6c', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_session_creation_timeout_secs': 7200, '_service': None, '_cluster_spec': ClusterSpec({}), '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
# Create DFC Pandas dataframe.
labels = y_eval.values
probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])
df_dfc = pd.DataFrame([pred['dfc'] for pred in pred_dicts])
df_dfc.describe().T
DFC의 좋은 특성은 기여도의 합계 + 바이어스가 주어진 예에 대한 예측과 같다는 것입니다.
# Sum of DFCs + bias == probabality.
bias = pred_dicts[0]['bias']
dfc_prob = df_dfc.sum(axis=1) + bias
np.testing.assert_almost_equal(dfc_prob.values,
probs.values)
개별 승객에 대한 DFC를 플롯합니다. 기여도 방향성에 따라 색상 코딩으로 플롯을 멋지게 만들고 그림에 특성 값을 추가하겠습니다.
# Boilerplate code for plotting :)
def _get_color(value):
"""To make positive DFCs plot green, negative DFCs plot red."""
green, red = sns.color_palette()[2:4]
if value >= 0: return green
return red
def _add_feature_values(feature_values, ax):
"""Display feature's values on left of plot."""
x_coord = ax.get_xlim()[0]
OFFSET = 0.15
for y_coord, (feat_name, feat_val) in enumerate(feature_values.items()):
t = plt.text(x_coord, y_coord - OFFSET, '{}'.format(feat_val), size=12)
t.set_bbox(dict(facecolor='white', alpha=0.5))
from matplotlib.font_manager import FontProperties
font = FontProperties()
font.set_weight('bold')
t = plt.text(x_coord, y_coord + 1 - OFFSET, 'feature\nvalue',
fontproperties=font, size=12)
def plot_example(example):
TOP_N = 8 # View top 8 features.
sorted_ix = example.abs().sort_values()[-TOP_N:].index # Sort by magnitude.
example = example[sorted_ix]
colors = example.map(_get_color).tolist()
ax = example.to_frame().plot(kind='barh',
color=[colors],
legend=None,
alpha=0.75,
figsize=(10,6))
ax.grid(False, axis='y')
ax.set_yticklabels(ax.get_yticklabels(), size=14)
# Add feature values.
_add_feature_values(dfeval.iloc[ID][sorted_ix], ax)
return ax
# Plot results.
ID = 182
example = df_dfc.iloc[ID] # Choose ith example from evaluation set.
TOP_N = 8 # View top 8 features.
sorted_ix = example.abs().sort_values()[-TOP_N:].index
ax = plot_example(example)
ax.set_title('Feature contributions for example {}\n pred: {:1.2f}; label: {}'.format(ID, probs[ID], labels[ID]))
ax.set_xlabel('Contribution to predicted probability', size=14)
plt.show()
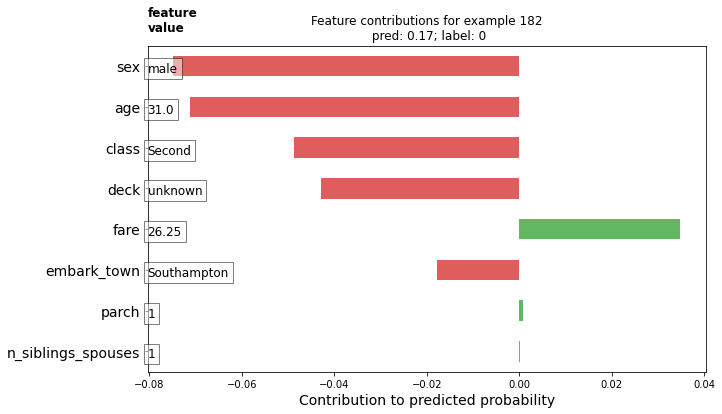
기여도가 클수록 모형 예측에 더 큰 영향을 미칩니다. 음의 기여도는 이 예제의 특성 값이 모델의 예측을 감소시킨 반면 양의 값은 예측의 증가에 기여함을 나타냅니다.
또한 바이올린 플롯을 사용하여 예제의 DFC를 전체 분포와 비교하여 플롯할 수도 있습니다.
# Boilerplate plotting code.
def dist_violin_plot(df_dfc, ID):
# Initialize plot.
fig, ax = plt.subplots(1, 1, figsize=(10, 6))
# Create example dataframe.
TOP_N = 8 # View top 8 features.
example = df_dfc.iloc[ID]
ix = example.abs().sort_values()[-TOP_N:].index
example = example[ix]
example_df = example.to_frame(name='dfc')
# Add contributions of entire distribution.
parts=ax.violinplot([df_dfc[w] for w in ix],
vert=False,
showextrema=False,
widths=0.7,
positions=np.arange(len(ix)))
face_color = sns_colors[0]
alpha = 0.15
for pc in parts['bodies']:
pc.set_facecolor(face_color)
pc.set_alpha(alpha)
# Add feature values.
_add_feature_values(dfeval.iloc[ID][sorted_ix], ax)
# Add local contributions.
ax.scatter(example,
np.arange(example.shape[0]),
color=sns.color_palette()[2],
s=100,
marker="s",
label='contributions for example')
# Legend
# Proxy plot, to show violinplot dist on legend.
ax.plot([0,0], [1,1], label='eval set contributions\ndistributions',
color=face_color, alpha=alpha, linewidth=10)
legend = ax.legend(loc='lower right', shadow=True, fontsize='x-large',
frameon=True)
legend.get_frame().set_facecolor('white')
# Format plot.
ax.set_yticks(np.arange(example.shape[0]))
ax.set_yticklabels(example.index)
ax.grid(False, axis='y')
ax.set_xlabel('Contribution to predicted probability', size=14)
이 예를 플롯합니다.
dist_violin_plot(df_dfc, ID)
plt.title('Feature contributions for example {}\n pred: {:1.2f}; label: {}'.format(ID, probs[ID], labels[ID]))
plt.show()
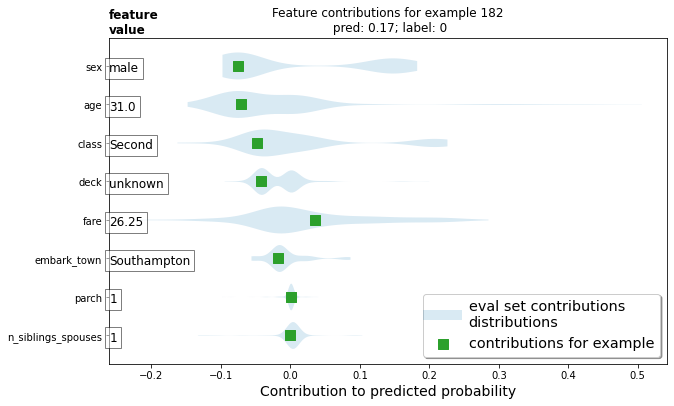
마지막으로 LIME 및 shap와 같은 타사 도구도 모델의 개별 예측을 이해하는 데 도움이 될 수 있습니다.
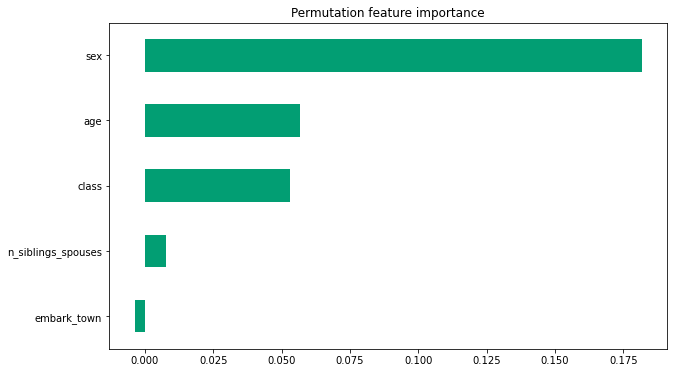
전역 특성 중요도
또한, 개별 예측을 연구하는 대신 모델 전체를 이해해야 할 수도 있습니다. 다음 내용을 계산하고 사용합니다.
est.experimental_feature_importances를 사용한 이득 기반의 특성 중요도- 순열 중요도
est.experimental_predict_with_explanations를 사용하여 DFC 집계
이득 기반 특성 중요도는 특정한 특성을 분할할 때 손실 변화를 측정하는 반면, 순열 특성 중요도는 각 특성을 하나씩 셔플하고 셔플된 특성에 모델 성능의 변화를 기여하는 식으로 평가 세트에서 모델 성능을 평가하여 계산됩니다.
일반적으로, 순열 특성 중요도는 이득 기반의 특성 중요도보다 선호되지만 잠재적인 예측 도구 변수가 측정 크기나 범주 수에서 변화하는 상황에 있고 특성이 서로 연관된 경우에 두 메서드 모두 신뢰도가 떨어질 수 있습니다(출처). 심층 개요 및 여러 특성 중요도 유형에 대한 유익한 논의 내용을 보려면 이 문서를 살펴보세요.
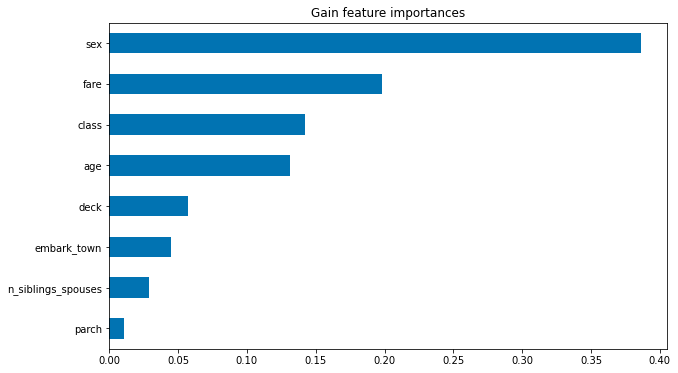
이득 기반 특성 중요도
이득 기반 특성 중요도는 est.experimental_feature_importances를 사용하여 TensorFlow 부스트 트리 예측 도구에 내장되어 있습니다.
importances = est.experimental_feature_importances(normalize=True)
df_imp = pd.Series(importances)
# Visualize importances.
N = 8
ax = (df_imp.iloc[0:N][::-1]
.plot(kind='barh',
color=sns_colors[0],
title='Gain feature importances',
figsize=(10, 6)))
ax.grid(False, axis='y')
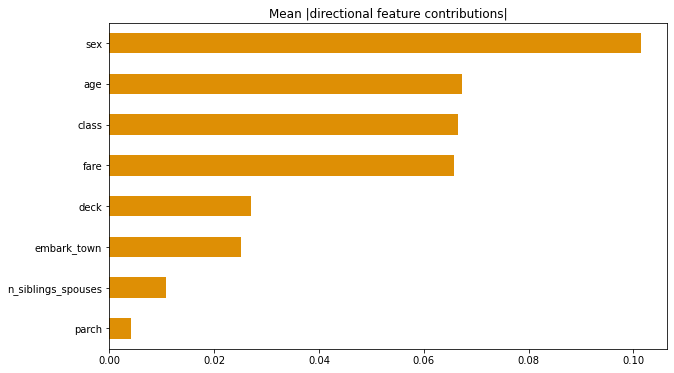
절대 DFC 평균화하기
DFC의 절대값을 평균화하여 전역 수준에서의 영향을 이해할 수도 있습니다.
# Plot.
dfc_mean = df_dfc.abs().mean()
N = 8
sorted_ix = dfc_mean.abs().sort_values()[-N:].index # Average and sort by absolute.
ax = dfc_mean[sorted_ix].plot(kind='barh',
color=sns_colors[1],
title='Mean |directional feature contributions|',
figsize=(10, 6))
ax.grid(False, axis='y')
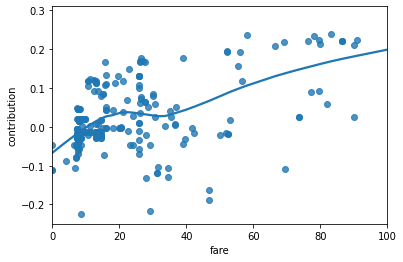
특성 값이 달라지면 DFC가 어떻게 변하는지도 확인할 수 있습니다.
FEATURE = 'fare'
feature = pd.Series(df_dfc[FEATURE].values, index=dfeval[FEATURE].values).sort_index()
ax = sns.regplot(feature.index.values, feature.values, lowess=True)
ax.set_ylabel('contribution')
ax.set_xlabel(FEATURE)
ax.set_xlim(0, 100)
plt.show()
/home/kbuilder/.local/lib/python3.6/site-packages/seaborn/_decorators.py:43: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation. FutureWarning
순열 특성 중요도
def permutation_importances(est, X_eval, y_eval, metric, features):
"""Column by column, shuffle values and observe effect on eval set.
source: http://explained.ai/rf-importance/index.html
A similar approach can be done during training. See "Drop-column importance"
in the above article."""
baseline = metric(est, X_eval, y_eval)
imp = []
for col in features:
save = X_eval[col].copy()
X_eval[col] = np.random.permutation(X_eval[col])
m = metric(est, X_eval, y_eval)
X_eval[col] = save
imp.append(baseline - m)
return np.array(imp)
def accuracy_metric(est, X, y):
"""TensorFlow estimator accuracy."""
eval_input_fn = make_input_fn(X,
y=y,
shuffle=False,
n_epochs=1)
return est.evaluate(input_fn=eval_input_fn)['accuracy']
features = CATEGORICAL_COLUMNS + NUMERIC_COLUMNS
importances = permutation_importances(est, dfeval, y_eval, accuracy_metric,
features)
df_imp = pd.Series(importances, index=features)
sorted_ix = df_imp.abs().sort_values().index
ax = df_imp[sorted_ix][-5:].plot(kind='barh', color=sns_colors[2], figsize=(10, 6))
ax.grid(False, axis='y')
ax.set_title('Permutation feature importance')
plt.show()
INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:46Z INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Inference Time : 0.49798s INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:47 INFO:tensorflow:Saving dict for global step 153: accuracy = 0.81439394, accuracy_baseline = 0.625, auc = 0.86853385, auc_precision_recall = 0.8522887, average_loss = 0.4158357, global_step = 153, label/mean = 0.375, loss = 0.4158357, precision = 0.7604167, prediction/mean = 0.38813925, recall = 0.7373737 INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:48Z INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Inference Time : 0.49648s INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:48 INFO:tensorflow:Saving dict for global step 153: accuracy = 0.63257575, accuracy_baseline = 0.625, auc = 0.6774105, auc_precision_recall = 0.5461383, average_loss = 0.7087227, global_step = 153, label/mean = 0.375, loss = 0.7087227, precision = 0.5102041, prediction/mean = 0.38512942, recall = 0.5050505 INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:49Z INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Inference Time : 0.48758s INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:49 INFO:tensorflow:Saving dict for global step 153: accuracy = 0.8068182, accuracy_baseline = 0.625, auc = 0.86685026, auc_precision_recall = 0.8444691, average_loss = 0.4260245, global_step = 153, label/mean = 0.375, loss = 0.4260245, precision = 0.7352941, prediction/mean = 0.40035293, recall = 0.75757575 INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:50Z INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Inference Time : 0.49514s INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:51 INFO:tensorflow:Saving dict for global step 153: accuracy = 0.81439394, accuracy_baseline = 0.625, auc = 0.86951333, auc_precision_recall = 0.8505372, average_loss = 0.41566578, global_step = 153, label/mean = 0.375, loss = 0.41566578, precision = 0.7604167, prediction/mean = 0.3888284, recall = 0.7373737 INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:51Z INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Inference Time : 0.49809s INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:52 INFO:tensorflow:Saving dict for global step 153: accuracy = 0.7613636, accuracy_baseline = 0.625, auc = 0.8230487, auc_precision_recall = 0.7399776, average_loss = 0.5045701, global_step = 153, label/mean = 0.375, loss = 0.5045701, precision = 0.7093023, prediction/mean = 0.3743065, recall = 0.61616164 INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:52Z INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Inference Time : 0.50164s INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:53 INFO:tensorflow:Saving dict for global step 153: accuracy = 0.81060606, accuracy_baseline = 0.625, auc = 0.8620141, auc_precision_recall = 0.8375165, average_loss = 0.42860302, global_step = 153, label/mean = 0.375, loss = 0.42860302, precision = 0.7752809, prediction/mean = 0.38649824, recall = 0.6969697 INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:53Z INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Inference Time : 0.49174s INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:54 INFO:tensorflow:Saving dict for global step 153: accuracy = 0.8181818, accuracy_baseline = 0.625, auc = 0.8647689, auc_precision_recall = 0.84176147, average_loss = 0.42195407, global_step = 153, label/mean = 0.375, loss = 0.42195407, precision = 0.7741935, prediction/mean = 0.3810864, recall = 0.72727275 INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:55Z INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Inference Time : 0.48163s INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:55 INFO:tensorflow:Saving dict for global step 153: accuracy = 0.81439394, accuracy_baseline = 0.625, auc = 0.86853385, auc_precision_recall = 0.8522887, average_loss = 0.4158357, global_step = 153, label/mean = 0.375, loss = 0.4158357, precision = 0.7604167, prediction/mean = 0.38813925, recall = 0.7373737 INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:56Z INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Inference Time : 0.49761s INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:56 INFO:tensorflow:Saving dict for global step 153: accuracy = 0.75757575, accuracy_baseline = 0.625, auc = 0.8072238, auc_precision_recall = 0.78729653, average_loss = 0.48916933, global_step = 153, label/mean = 0.375, loss = 0.48916933, precision = 0.7058824, prediction/mean = 0.3727151, recall = 0.6060606 INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2020-11-12T03:12:57Z INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmp3yc0aq6c/model.ckpt-153 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Inference Time : 0.50330s INFO:tensorflow:Finished evaluation at 2020-11-12-03:12:58 INFO:tensorflow:Saving dict for global step 153: accuracy = 0.81439394, accuracy_baseline = 0.625, auc = 0.8542087, auc_precision_recall = 0.8415934, average_loss = 0.43299174, global_step = 153, label/mean = 0.375, loss = 0.43299174, precision = 0.7777778, prediction/mean = 0.37881836, recall = 0.7070707 INFO:tensorflow:Saving 'checkpoint_path' summary for global step 153: /tmp/tmp3yc0aq6c/model.ckpt-153
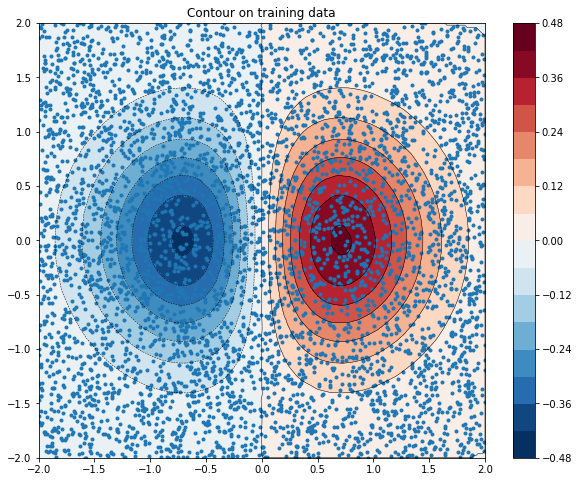
모델 피팅 시각화하기
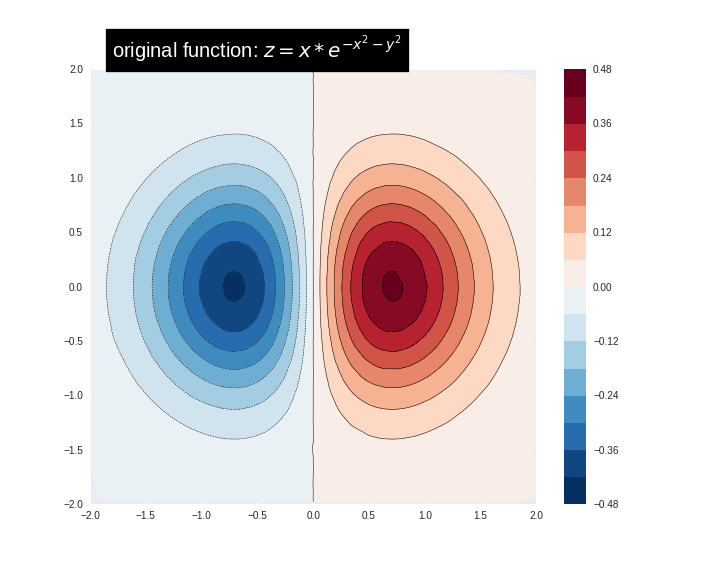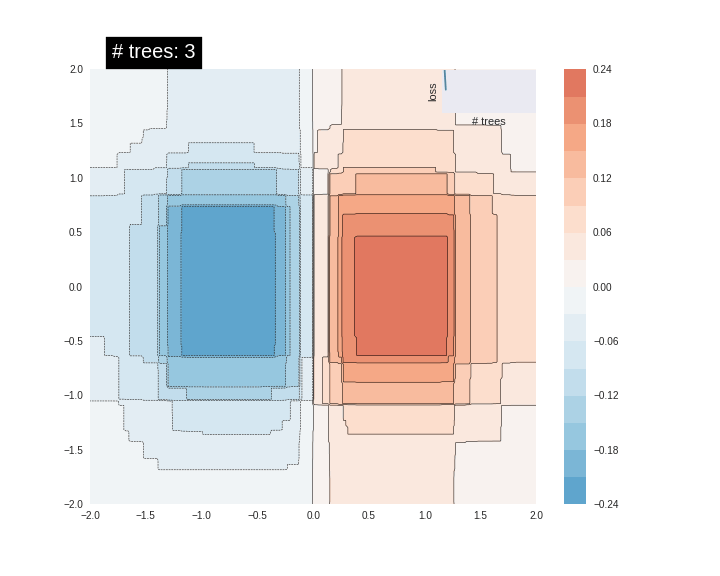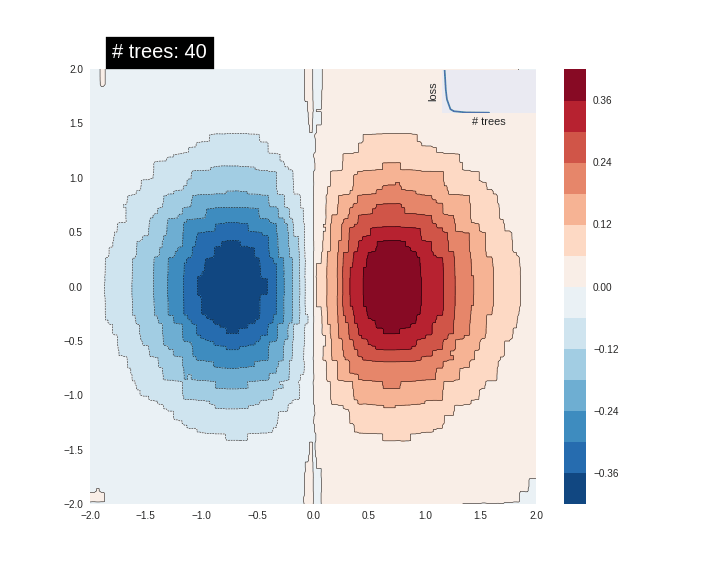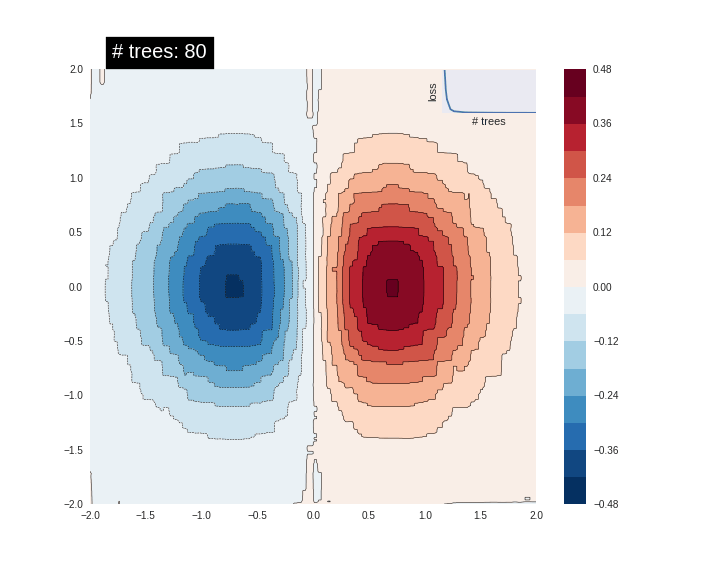
먼저 다음 공식을 사용하여 훈련 데이터를 시뮬레이션/생성하겠습니다.
\[z=x* e^{-x^2 - y^2}\]
여기서 (z)는 예측하려는 종속 변수이고 (x) 및 (y)는 특성입니다.
from numpy.random import uniform, seed
from scipy.interpolate import griddata
# Create fake data
seed(0)
npts = 5000
x = uniform(-2, 2, npts)
y = uniform(-2, 2, npts)
z = x*np.exp(-x**2 - y**2)
xy = np.zeros((2,np.size(x)))
xy[0] = x
xy[1] = y
xy = xy.T
# Prep data for training.
df = pd.DataFrame({'x': x, 'y': y, 'z': z})
xi = np.linspace(-2.0, 2.0, 200),
yi = np.linspace(-2.1, 2.1, 210),
xi,yi = np.meshgrid(xi, yi)
df_predict = pd.DataFrame({
'x' : xi.flatten(),
'y' : yi.flatten(),
})
predict_shape = xi.shape
def plot_contour(x, y, z, **kwargs):
# Grid the data.
plt.figure(figsize=(10, 8))
# Contour the gridded data, plotting dots at the nonuniform data points.
CS = plt.contour(x, y, z, 15, linewidths=0.5, colors='k')
CS = plt.contourf(x, y, z, 15,
vmax=abs(zi).max(), vmin=-abs(zi).max(), cmap='RdBu_r')
plt.colorbar() # Draw colorbar.
# Plot data points.
plt.xlim(-2, 2)
plt.ylim(-2, 2)
함수를 시각화할 수 있습니다. 붉은 색은 더 큰 함수 값에 해당합니다.
zi = griddata(xy, z, (xi, yi), method='linear', fill_value='0')
plot_contour(xi, yi, zi)
plt.scatter(df.x, df.y, marker='.')
plt.title('Contour on training data')
plt.show()
fc = [tf.feature_column.numeric_column('x'),
tf.feature_column.numeric_column('y')]
def predict(est):
"""Predictions from a given estimator."""
predict_input_fn = lambda: tf.data.Dataset.from_tensors(dict(df_predict))
preds = np.array([p['predictions'][0] for p in est.predict(predict_input_fn)])
return preds.reshape(predict_shape)
먼저 선형 모델을 데이터에 맞춥니다.
train_input_fn = make_input_fn(df, df.z)
est = tf.estimator.LinearRegressor(fc)
est.train(train_input_fn, max_steps=500);
INFO:tensorflow:Using default config.
WARNING:tensorflow:Using temporary folder as model directory: /tmp/tmpc4d4x6rb
INFO:tensorflow:Using config: {'_model_dir': '/tmp/tmpc4d4x6rb', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_session_creation_timeout_secs': 7200, '_service': None, '_cluster_spec': ClusterSpec({}), '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow_estimator/python/estimator/canned/linear.py:1481: Layer.add_variable (from tensorflow.python.keras.engine.base_layer_v1) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `layer.add_weight` method instead.
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/keras/optimizer_v2/ftrl.py:112: calling Constant.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Create CheckpointSaverHook.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Calling checkpoint listeners before saving checkpoint 0...
INFO:tensorflow:Saving checkpoints for 0 into /tmp/tmpc4d4x6rb/model.ckpt.
INFO:tensorflow:Calling checkpoint listeners after saving checkpoint 0...
INFO:tensorflow:loss = 0.024857903, step = 0
INFO:tensorflow:global_step/sec: 302.205
INFO:tensorflow:loss = 0.021111207, step = 100 (0.332 sec)
INFO:tensorflow:global_step/sec: 328.818
INFO:tensorflow:loss = 0.018250467, step = 200 (0.304 sec)
INFO:tensorflow:global_step/sec: 326.44
INFO:tensorflow:loss = 0.017796298, step = 300 (0.306 sec)
INFO:tensorflow:global_step/sec: 332.579
INFO:tensorflow:loss = 0.0199083, step = 400 (0.301 sec)
INFO:tensorflow:Calling checkpoint listeners before saving checkpoint 500...
INFO:tensorflow:Saving checkpoints for 500 into /tmp/tmpc4d4x6rb/model.ckpt.
INFO:tensorflow:Calling checkpoint listeners after saving checkpoint 500...
INFO:tensorflow:Loss for final step: 0.019099703.
<tensorflow_estimator.python.estimator.canned.linear.LinearRegressorV2 at 0x7f3cb41b54e0>
plot_contour(xi, yi, predict(est))
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:Layer linear/linear_model is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because its dtype defaults to floatx.
If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.
To change all layers to have dtype float64 by default, call `tf.keras.backend.set_floatx('float64')`. To change just this layer, pass dtype='float64' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/tmpc4d4x6rb/model.ckpt-500
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
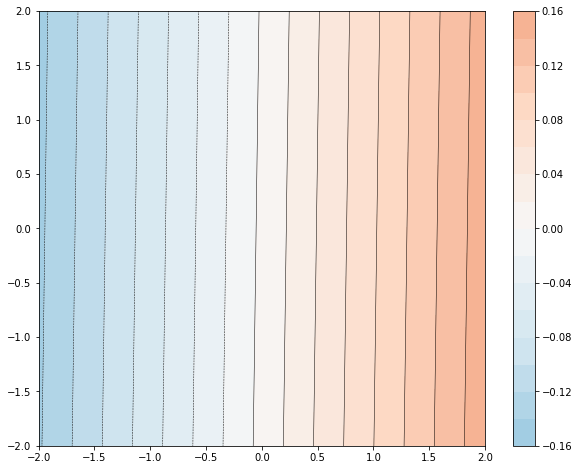
잘 맞지 않습니다. 다음으로 GBDT 모델을 데이터에 맞추고 모델이 함수에 얼마나 잘 맞는지 이해해 보겠습니다.
n_trees = 37
est = tf.estimator.BoostedTreesRegressor(fc, n_batches_per_layer=1, n_trees=n_trees)
est.train(train_input_fn, max_steps=500)
clear_output()
plot_contour(xi, yi, predict(est))
plt.text(-1.8, 2.1, '# trees: {}'.format(n_trees), color='w', backgroundcolor='black', size=20)
plt.show()
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmpmez_f6nm/model.ckpt-222 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op.
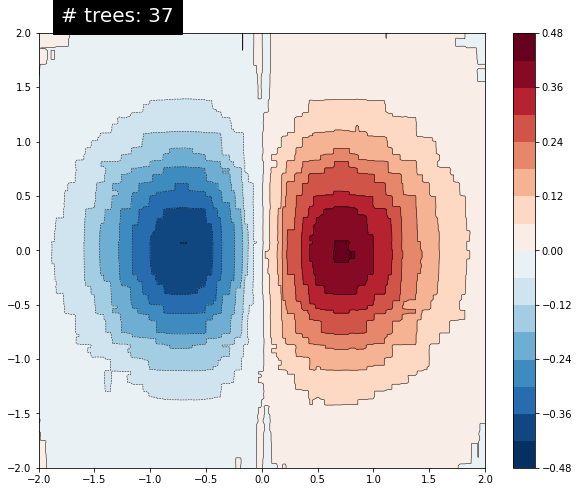
트리 수를 늘리면 모델의 예측이 기본 함수에 더 근접합니다.
결론
이 튜토리얼에서는 방향성 특성 기여도와 특성 중요도 기법을 이용하여 부스트 트리 모델을 해석하는 방법에 대해 배웠습니다. 이러한 기법은 특성이 모델의 예측에 미치는 영향에 대한 통찰력을 제공합니다. 마지막으로, 여러 모델에 대한 의사 결정 표면(decision surface)을 살펴봄으로써 부스트 트리 모델이 복잡한 함수에 어떻게 맞춰지는지 직관적으로 파악했습니다.