
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি দেখায় কিভাবে ফুলের ছবি শ্রেণীবদ্ধ করা যায়। এটি একটি tf.keras.Sequential মডেল ব্যবহার করে একটি ইমেজ ক্লাসিফায়ার তৈরি করে এবং tf.keras.utils.image_dataset_from_directory ব্যবহার করে ডেটা লোড করে। আপনি নিম্নলিখিত ধারণাগুলির সাথে বাস্তব অভিজ্ঞতা অর্জন করবেন:
- দক্ষতার সাথে একটি ডেটাসেট অফ ডিস্ক লোড হচ্ছে।
- অতিরিক্ত ফিটিং সনাক্ত করা এবং ডেটা বৃদ্ধি এবং ড্রপআউট সহ এটি প্রশমিত করার কৌশল প্রয়োগ করা।
এই টিউটোরিয়ালটি একটি মৌলিক মেশিন লার্নিং ওয়ার্কফ্লো অনুসরণ করে:
- তথ্য পরীক্ষা এবং বুঝতে
- একটি ইনপুট পাইপলাইন তৈরি করুন
- মডেল তৈরি করুন
- মডেলকে প্রশিক্ষণ দিন
- মডেল পরীক্ষা করুন
- মডেলটি উন্নত করুন এবং প্রক্রিয়াটি পুনরাবৃত্তি করুন
TensorFlow এবং অন্যান্য লাইব্রেরি আমদানি করুন
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
ডেটাসেট ডাউনলোড করুন এবং অন্বেষণ করুন
এই টিউটোরিয়ালটি ফুলের প্রায় 3,700টি ফটোর ডেটাসেট ব্যবহার করে। ডেটাসেটে পাঁচটি সাব-ডিরেক্টরি রয়েছে, প্রতি ক্লাসে একটি:
flower_photo/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
ডাউনলোড করার পরে, আপনার কাছে এখন উপলভ্য ডেটাসেটের একটি অনুলিপি থাকা উচিত। মোট 3,670টি ছবি আছে:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
এখানে কিছু গোলাপ আছে:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

PIL.Image.open(str(roses[1]))

এবং কিছু টিউলিপ:
tulips = list(data_dir.glob('tulips/*'))
PIL.Image.open(str(tulips[0]))

PIL.Image.open(str(tulips[1]))
কেরাস ইউটিলিটি ব্যবহার করে ডেটা লোড করুন
আসুন সহায়ক tf.keras.utils.image_dataset_from_directory ইউটিলিটি ব্যবহার করে এই ছবিগুলিকে ডিস্কের বাইরে লোড করি। এটি আপনাকে ডিস্কে থাকা চিত্রগুলির একটি ডিরেক্টরি থেকে tf.data.Dataset এ নিয়ে যাবে মাত্র কয়েক লাইনের কোডে। আপনি চাইলে, লোড এবং প্রিপ্রসেস ইমেজ টিউটোরিয়ালটিতে গিয়ে স্ক্র্যাচ থেকে আপনার নিজস্ব ডেটা লোডিং কোডও লিখতে পারেন।
একটি ডেটাসেট তৈরি করুন
লোডারের জন্য কিছু পরামিতি সংজ্ঞায়িত করুন:
batch_size = 32
img_height = 180
img_width = 180
আপনার মডেলটি বিকাশ করার সময় একটি বৈধতা বিভাজন ব্যবহার করা ভাল অনুশীলন। আসুন প্রশিক্ষণের জন্য 80% চিত্র ব্যবহার করি, এবং 20% যাচাইকরণের জন্য।
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
আপনি এই ডেটাসেটের class_names অ্যাট্রিবিউটে ক্লাসের নাম খুঁজে পেতে পারেন। এগুলি বর্ণানুক্রমিক ক্রমে ডিরেক্টরির নামের সাথে মিলে যায়।
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
ডেটা ভিজ্যুয়ালাইজ করুন
এখানে প্রশিক্ষণ ডেটাসেট থেকে প্রথম নয়টি চিত্র রয়েছে:
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
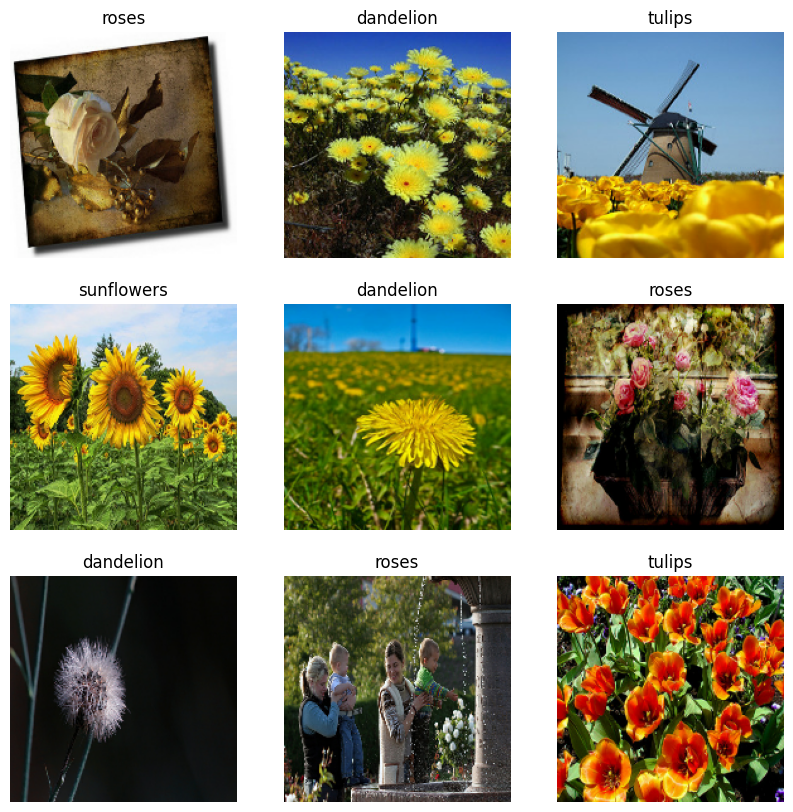
আপনি এই ডেটাসেটগুলি ব্যবহার করে একটি মডেলকে কিছুক্ষণের মধ্যে Model.fit এ পাস করে প্রশিক্ষণ দেবেন। আপনি যদি চান, আপনি নিজেও ডেটাসেটের উপর পুনরাবৃত্তি করতে পারেন এবং চিত্রগুলির ব্যাচগুলি পুনরুদ্ধার করতে পারেন:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch আকৃতির একটি টেনসর (32, 180, 180, 3) । এটি 180x180x3 আকৃতির 32টি চিত্রের একটি ব্যাচ (শেষ মাত্রাটি RGB রঙের চ্যানেলকে বোঝায়)। label_batch আকৃতির একটি টেনসর (32,) , এগুলি 32টি চিত্রের সাথে সম্পর্কিত লেবেল।
.numpy() image_batch labels_batch numpy.ndarray
কর্মক্ষমতা জন্য ডেটাসেট কনফিগার করুন
আসুন বাফার করা প্রিফেচিং ব্যবহার করা নিশ্চিত করি যাতে আপনি I/O ব্লক না হয়েই ডিস্ক থেকে ডেটা পেতে পারেন। ডেটা লোড করার সময় এই দুটি গুরুত্বপূর্ণ পদ্ধতি ব্যবহার করা উচিত:
-
Dataset.cacheপ্রথম যুগে ডিস্ক থেকে লোড করার পরে মেমরিতে রাখে। এটি নিশ্চিত করবে যে ডেটাসেটটি আপনার মডেলকে প্রশিক্ষণ দেওয়ার সময় বাধা হয়ে দাঁড়ায় না। আপনার ডেটাসেট মেমরিতে ফিট করার জন্য খুব বড় হলে, আপনি একটি পারফরম্যান্ট অন-ডিস্ক ক্যাশে তৈরি করতে এই পদ্ধতিটি ব্যবহার করতে পারেন। -
Dataset.prefetchপ্রশিক্ষণের সময় ডেটা প্রিপ্রসেসিং এবং মডেল এক্সিকিউশন ওভারল্যাপ করে।
আগ্রহী পাঠকরা tf.data API গাইডের সাথে বেটার পারফরম্যান্সের প্রিফেচিং বিভাগে ডিস্কে কীভাবে ডেটা ক্যাশে করতে হয় তা উভয় পদ্ধতি সম্পর্কে আরও শিখতে পারেন।
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
ডেটা স্ট্যান্ডার্ডাইজ করুন
RGB চ্যানেলের মানগুলি [0, 255] পরিসরে। এটি একটি নিউরাল নেটওয়ার্কের জন্য আদর্শ নয়; সাধারণভাবে আপনার ইনপুট মান ছোট করার চেষ্টা করা উচিত।
এখানে, আপনি tf.keras.layers.Rescaling ব্যবহার করে মানগুলিকে [0, 1] পরিসরে মানানসই করবেন:
normalization_layer = layers.Rescaling(1./255)
এই স্তরটি ব্যবহার করার দুটি উপায় রয়েছে। আপনি Dataset.map কল করে এটি ডেটাসেটে প্রয়োগ করতে পারেন:
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 1.0
অথবা, আপনি আপনার মডেল সংজ্ঞার ভিতরে স্তরটি অন্তর্ভুক্ত করতে পারেন, যা স্থাপনাকে সহজ করতে পারে। এখানে দ্বিতীয় পদ্ধতি ব্যবহার করা যাক.
মডেল তৈরি করুন
tf.keras.layers.Conv2D ) থাকে যার প্রতিটিতে সর্বোচ্চ পুলিং লেয়ার ( tf.keras.layers.MaxPooling2D ) থাকে। একটি সম্পূর্ণ-সংযুক্ত স্তর রয়েছে ( tf.keras.layers.Dense ) যার উপরে 128টি ইউনিট রয়েছে যা একটি ReLU অ্যাক্টিভেশন ফাংশন ( 'relu' ) দ্বারা সক্রিয় করা হয়েছে। এই মডেলটি উচ্চ নির্ভুলতার জন্য টিউন করা হয়নি—এই টিউটোরিয়ালটির লক্ষ্য হল একটি আদর্শ পদ্ধতি দেখানো।
num_classes = len(class_names)
model = Sequential([
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
মডেল কম্পাইল করুন
এই টিউটোরিয়ালের জন্য, tf.keras.optimizers.Adam অপ্টিমাইজার এবং tf.keras.losses.SparseCategoricalCrossentropy ক্ষতি ফাংশন নির্বাচন করুন। প্রতিটি প্রশিক্ষণ যুগের জন্য প্রশিক্ষণ এবং যাচাইকরণের নির্ভুলতা দেখতে, Model.compile এ metrics আর্গুমেন্ট পাস করুন।
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
মডেল সারাংশ
মডেলের Model.summary পদ্ধতি ব্যবহার করে নেটওয়ার্কের সমস্ত স্তর দেখুন:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_1 (Rescaling) (None, 180, 180, 3) 0
conv2d (Conv2D) (None, 180, 180, 16) 448
max_pooling2d (MaxPooling2D (None, 90, 90, 16) 0
)
conv2d_1 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_1 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_2 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_2 (MaxPooling (None, 22, 22, 64) 0
2D)
flatten (Flatten) (None, 30976) 0
dense (Dense) (None, 128) 3965056
dense_1 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
মডেলকে প্রশিক্ষণ দিন
epochs=10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/10 92/92 [==============================] - 3s 16ms/step - loss: 1.2769 - accuracy: 0.4489 - val_loss: 1.0457 - val_accuracy: 0.5804 Epoch 2/10 92/92 [==============================] - 1s 11ms/step - loss: 0.9386 - accuracy: 0.6328 - val_loss: 0.9665 - val_accuracy: 0.6158 Epoch 3/10 92/92 [==============================] - 1s 11ms/step - loss: 0.7390 - accuracy: 0.7200 - val_loss: 0.8768 - val_accuracy: 0.6540 Epoch 4/10 92/92 [==============================] - 1s 11ms/step - loss: 0.5649 - accuracy: 0.7963 - val_loss: 0.9258 - val_accuracy: 0.6540 Epoch 5/10 92/92 [==============================] - 1s 11ms/step - loss: 0.3662 - accuracy: 0.8733 - val_loss: 1.1734 - val_accuracy: 0.6267 Epoch 6/10 92/92 [==============================] - 1s 11ms/step - loss: 0.2169 - accuracy: 0.9343 - val_loss: 1.3728 - val_accuracy: 0.6499 Epoch 7/10 92/92 [==============================] - 1s 11ms/step - loss: 0.1191 - accuracy: 0.9629 - val_loss: 1.3791 - val_accuracy: 0.6471 Epoch 8/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0497 - accuracy: 0.9871 - val_loss: 1.8002 - val_accuracy: 0.6390 Epoch 9/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0372 - accuracy: 0.9922 - val_loss: 1.8545 - val_accuracy: 0.6390 Epoch 10/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0715 - accuracy: 0.9813 - val_loss: 2.0656 - val_accuracy: 0.6049
প্রশিক্ষণ ফলাফল কল্পনা করুন
প্রশিক্ষণ এবং বৈধতা সেটে ক্ষতি এবং নির্ভুলতার প্লট তৈরি করুন:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
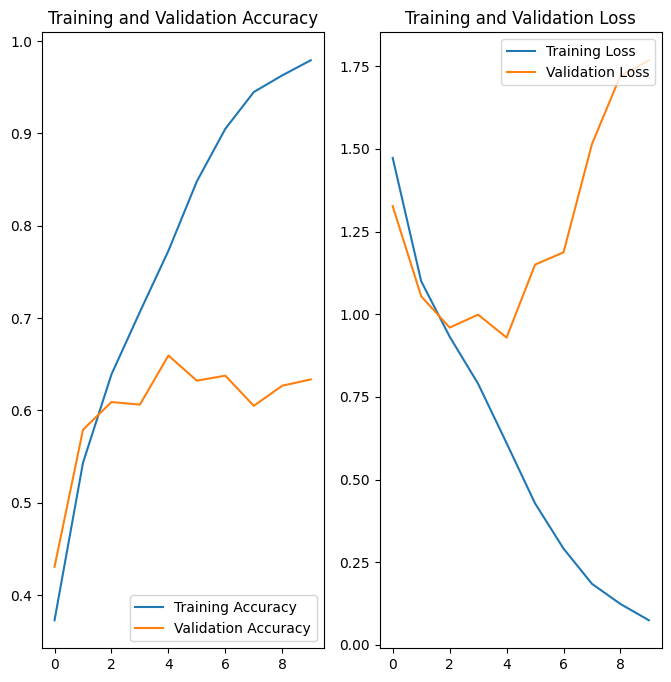
প্লটগুলি দেখায় যে প্রশিক্ষণের নির্ভুলতা এবং বৈধতা নির্ভুলতা বড় মার্জিন দ্বারা বন্ধ, এবং মডেলটি বৈধতা সেটে প্রায় 60% নির্ভুলতা অর্জন করেছে।
আসুন পরিদর্শন করি কি ভুল হয়েছে এবং মডেলের সামগ্রিক কর্মক্ষমতা বাড়ানোর চেষ্টা করুন।
ওভারফিটিং
উপরের প্লটগুলিতে, প্রশিক্ষণের যথার্থতা সময়ের সাথে সাথে রৈখিকভাবে বৃদ্ধি পাচ্ছে, যেখানে প্রশিক্ষণ প্রক্রিয়ায় বৈধতা নির্ভুলতা প্রায় 60% স্টল করে। এছাড়াও, প্রশিক্ষণ এবং বৈধতা নির্ভুলতার মধ্যে নির্ভুলতার পার্থক্য লক্ষণীয়— ওভারফিটিং এর একটি চিহ্ন।
যখন অল্প সংখ্যক প্রশিক্ষণের উদাহরণ থাকে, তখন মডেলটি কখনও কখনও প্রশিক্ষণের উদাহরণ থেকে আওয়াজ বা অবাঞ্ছিত বিবরণ থেকে শেখে- এমন পরিমাণে যে এটি নতুন উদাহরণগুলিতে মডেলের কার্যকারিতাকে নেতিবাচকভাবে প্রভাবিত করে। এই ঘটনাটি ওভারফিটিং হিসাবে পরিচিত। এর মানে হল যে মডেলটির একটি নতুন ডেটাসেটে সাধারণীকরণ করা কঠিন হবে।
প্রশিক্ষণ প্রক্রিয়ায় ওভারফিটিংয়ের বিরুদ্ধে লড়াই করার একাধিক উপায় রয়েছে। এই টিউটোরিয়ালে, আপনি ডেটা অগমেন্টেশন ব্যবহার করবেন এবং আপনার মডেলে ড্রপআউট যোগ করবেন।
তথ্য বৃদ্ধি
ওভারফিটিং সাধারণত ঘটে যখন অল্প সংখ্যক প্রশিক্ষণের উদাহরণ থাকে। ডেটা অগমেন্টেশন আপনার বিদ্যমান উদাহরণগুলি থেকে অতিরিক্ত প্রশিক্ষণ ডেটা তৈরি করার পদ্ধতি গ্রহণ করে যা এলোমেলো রূপান্তরগুলি ব্যবহার করে যা বিশ্বাসযোগ্য-সুদর্শন চিত্রগুলি তৈরি করে। এটি মডেলটিকে ডেটার আরও দিকগুলি প্রকাশ করতে এবং আরও ভালভাবে সাধারণীকরণ করতে সহায়তা করে৷
আপনি নিম্নলিখিত কেরাস প্রিপ্রসেসিং স্তরগুলি ব্যবহার করে ডেটা অগমেন্টেশন বাস্তবায়ন করবেন: tf.keras.layers.RandomFlip , tf.keras.layers.RandomRotation , এবং tf.keras.layers.RandomZoom । এগুলি অন্যান্য স্তরের মতো আপনার মডেলের ভিতরে অন্তর্ভুক্ত করা যেতে পারে এবং GPU-তে চালানো যেতে পারে।
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.1),
]
)
একই ছবিতে একাধিকবার ডেটা অগমেন্টেশন প্রয়োগ করে কয়েকটি বর্ধিত উদাহরণ দেখতে কেমন তা কল্পনা করা যাক:
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")

আপনি এক মুহূর্তের মধ্যে একটি মডেল প্রশিক্ষণের জন্য ডেটা বৃদ্ধি ব্যবহার করবেন।
বাদ পড়া
ওভারফিটিং কমানোর আরেকটি কৌশল হল নেটওয়ার্কে ড্রপআউট নিয়মিতকরণ চালু করা।
আপনি যখন একটি স্তরে ড্রপআউট প্রয়োগ করেন, তখন প্রশিক্ষণ প্রক্রিয়া চলাকালীন এটি এলোমেলোভাবে (অ্যাক্টিভেশনকে শূন্যে সেট করে) স্তর থেকে বেশ কয়েকটি আউটপুট ইউনিট ড্রপ আউট হয়ে যায়। ড্রপআউট তার ইনপুট মান হিসাবে একটি ভগ্নাংশ সংখ্যা নেয়, যেমন 0.1, 0.2, 0.4, ইত্যাদি আকারে। এর অর্থ হল প্রয়োগকৃত স্তর থেকে এলোমেলোভাবে আউটপুট ইউনিটের 10%, 20% বা 40% বাদ দেওয়া।
আসুন tf.keras.layers.Dropout সহ একটি নতুন নিউরাল নেটওয়ার্ক তৈরি করি। বর্ধিত চিত্রগুলি ব্যবহার করে প্রশিক্ষণ দেওয়ার আগে ড্রপআউট করি:
model = Sequential([
data_augmentation,
layers.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
মডেল কম্পাইল এবং প্রশিক্ষণ
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential_1 (Sequential) (None, 180, 180, 3) 0
rescaling_2 (Rescaling) (None, 180, 180, 3) 0
conv2d_3 (Conv2D) (None, 180, 180, 16) 448
max_pooling2d_3 (MaxPooling (None, 90, 90, 16) 0
2D)
conv2d_4 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_4 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_5 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_5 (MaxPooling (None, 22, 22, 64) 0
2D)
dropout (Dropout) (None, 22, 22, 64) 0
flatten_1 (Flatten) (None, 30976) 0
dense_2 (Dense) (None, 128) 3965056
dense_3 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
epochs = 15
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/15 92/92 [==============================] - 2s 14ms/step - loss: 1.3840 - accuracy: 0.3999 - val_loss: 1.0967 - val_accuracy: 0.5518 Epoch 2/15 92/92 [==============================] - 1s 12ms/step - loss: 1.1152 - accuracy: 0.5395 - val_loss: 1.1123 - val_accuracy: 0.5545 Epoch 3/15 92/92 [==============================] - 1s 12ms/step - loss: 1.0049 - accuracy: 0.6052 - val_loss: 0.9544 - val_accuracy: 0.6253 Epoch 4/15 92/92 [==============================] - 1s 12ms/step - loss: 0.9452 - accuracy: 0.6257 - val_loss: 0.9681 - val_accuracy: 0.6213 Epoch 5/15 92/92 [==============================] - 1s 12ms/step - loss: 0.8804 - accuracy: 0.6591 - val_loss: 0.8450 - val_accuracy: 0.6798 Epoch 6/15 92/92 [==============================] - 1s 12ms/step - loss: 0.8001 - accuracy: 0.6945 - val_loss: 0.8715 - val_accuracy: 0.6594 Epoch 7/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7736 - accuracy: 0.6965 - val_loss: 0.8059 - val_accuracy: 0.6935 Epoch 8/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7477 - accuracy: 0.7078 - val_loss: 0.8292 - val_accuracy: 0.6812 Epoch 9/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7053 - accuracy: 0.7251 - val_loss: 0.7743 - val_accuracy: 0.6989 Epoch 10/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6884 - accuracy: 0.7340 - val_loss: 0.7867 - val_accuracy: 0.6907 Epoch 11/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6536 - accuracy: 0.7469 - val_loss: 0.7732 - val_accuracy: 0.6785 Epoch 12/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6456 - accuracy: 0.7500 - val_loss: 0.7801 - val_accuracy: 0.6907 Epoch 13/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5941 - accuracy: 0.7735 - val_loss: 0.7185 - val_accuracy: 0.7330 Epoch 14/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5824 - accuracy: 0.7735 - val_loss: 0.7282 - val_accuracy: 0.7357 Epoch 15/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5771 - accuracy: 0.7851 - val_loss: 0.7308 - val_accuracy: 0.7343
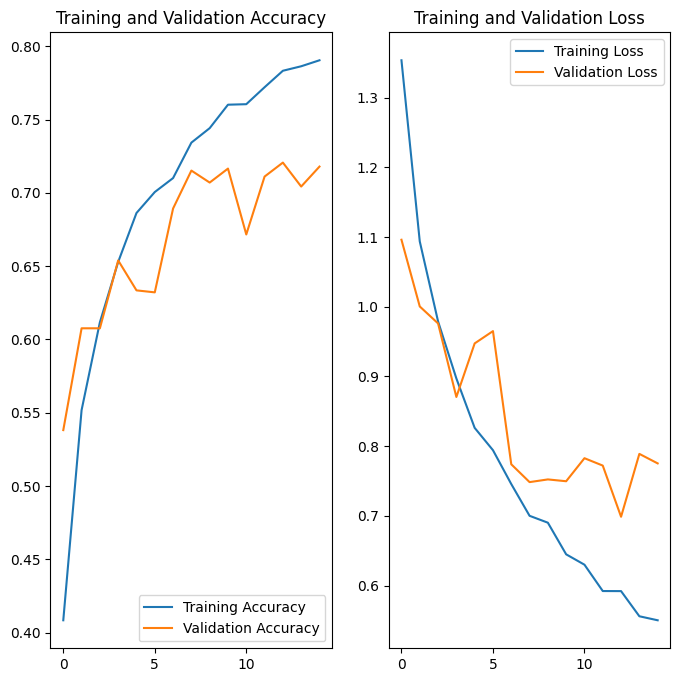
প্রশিক্ষণ ফলাফল কল্পনা করুন
ডেটা অগমেন্টেশন এবং tf.keras.layers.Dropout প্রয়োগ করার পরে, আগের তুলনায় কম ওভারফিটিং আছে, এবং প্রশিক্ষণ এবং যাচাইকরণের সঠিকতা কাছাকাছি সারিবদ্ধ:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
নতুন তথ্য ভবিষ্যদ্বাণী
অবশেষে, আসুন আমাদের মডেলটিকে এমন একটি চিত্রকে শ্রেণিবদ্ধ করতে ব্যবহার করি যা প্রশিক্ষণ বা বৈধতা সেটে অন্তর্ভুক্ত ছিল না।
sunflower_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg"
sunflower_path = tf.keras.utils.get_file('Red_sunflower', origin=sunflower_url)
img = tf.keras.utils.load_img(
sunflower_path, target_size=(img_height, img_width)
)
img_array = tf.keras.utils.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batch
predictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])
print(
"This image most likely belongs to {} with a {:.2f} percent confidence."
.format(class_names[np.argmax(score)], 100 * np.max(score))
)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg 122880/117948 [===============================] - 0s 0us/step 131072/117948 [=================================] - 0s 0us/step This image most likely belongs to sunflowers with a 89.13 percent confidence.