
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি দেখায় কিভাবে তিনটি উপায়ে একটি ইমেজ ডেটাসেট লোড এবং প্রিপ্রসেস করতে হয়:
- প্রথমে, আপনি উচ্চ-স্তরের কেরাস প্রিপ্রসেসিং ইউটিলিটিগুলি ব্যবহার করবেন (যেমন
tf.keras.utils.image_dataset_from_directory) এবং স্তরগুলি (যেমনtf.keras.layers.Rescaling) ডিস্কে চিত্রগুলির একটি ডিরেক্টরি পড়তে। - এরপর, আপনি tf.data ব্যবহার করে স্ক্র্যাচ থেকে আপনার নিজের ইনপুট পাইপলাইন লিখবেন।
- অবশেষে, আপনি টেনসরফ্লো ডেটাসেটে উপলব্ধ বড় ক্যাটালগ থেকে একটি ডেটাসেট ডাউনলোড করবেন।
সেটআপ
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
ফুলের ডেটাসেট ডাউনলোড করুন
এই টিউটোরিয়ালটি ফুলের কয়েক হাজার ফটোর ডেটাসেট ব্যবহার করে। ফুলের ডেটাসেটে পাঁচটি উপ-ডিরেক্টরি রয়েছে, প্রতি শ্রেণীতে একটি:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
ডাউনলোড করার পরে (218MB), আপনার কাছে এখন ফুলের ফটোগুলির একটি অনুলিপি পাওয়া উচিত। মোট 3,670টি ছবি আছে:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
প্রতিটি ডিরেক্টরিতে সেই ধরণের ফুলের ছবি রয়েছে। এখানে কিছু গোলাপ আছে:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

কেরাস ইউটিলিটি ব্যবহার করে ডেটা লোড করুন
আসুন সহায়ক tf.keras.utils.image_dataset_from_directory ইউটিলিটি ব্যবহার করে এই ছবিগুলিকে ডিস্কের বাইরে লোড করি।
একটি ডেটাসেট তৈরি করুন
লোডারের জন্য কিছু পরামিতি সংজ্ঞায়িত করুন:
batch_size = 32
img_height = 180
img_width = 180
আপনার মডেলটি বিকাশ করার সময় একটি বৈধতা বিভাজন ব্যবহার করা ভাল অনুশীলন। আপনি প্রশিক্ষণের জন্য চিত্রগুলির 80% এবং বৈধতার জন্য 20% ব্যবহার করবেন।
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
আপনি এই ডেটাসেটের class_names অ্যাট্রিবিউটে ক্লাসের নাম খুঁজে পেতে পারেন।
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
ডেটা ভিজ্যুয়ালাইজ করুন
এখানে প্রশিক্ষণ ডেটাসেট থেকে প্রথম নয়টি চিত্র রয়েছে।
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
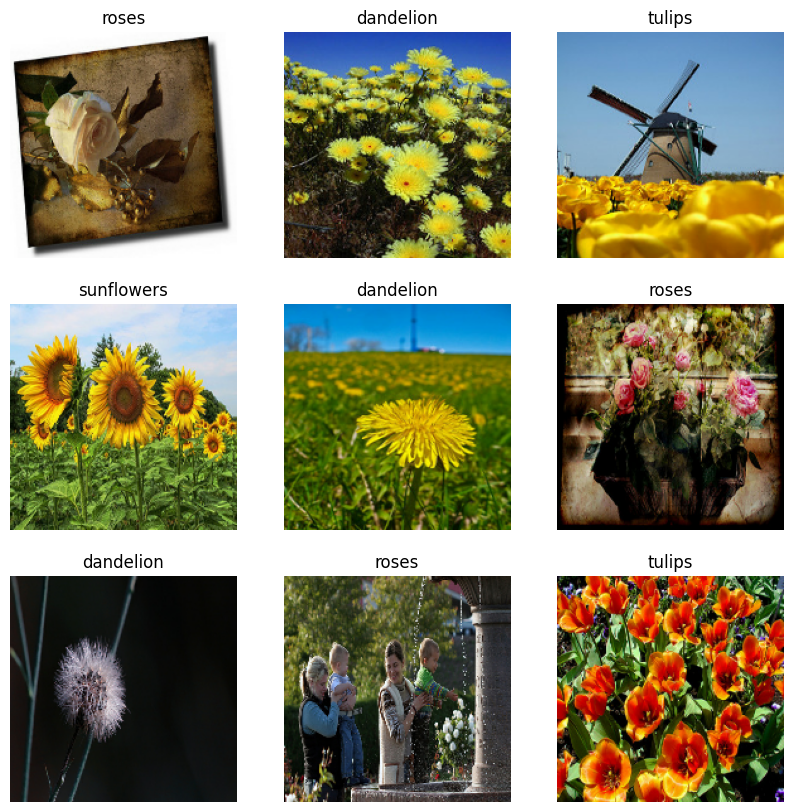
আপনি model.fit -এ পাস করে এই ডেটাসেটগুলি ব্যবহার করে একটি মডেলকে প্রশিক্ষণ দিতে পারেন (পরে এই টিউটোরিয়ালে দেখানো হয়েছে)। আপনি যদি চান, আপনি নিজেও ডেটাসেটের উপর পুনরাবৃত্তি করতে পারেন এবং চিত্রগুলির ব্যাচগুলি পুনরুদ্ধার করতে পারেন:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch আকৃতির একটি টেনসর (32, 180, 180, 3) । এটি 180x180x3 আকৃতির 32টি চিত্রের একটি ব্যাচ (শেষ মাত্রাটি RGB রঙের চ্যানেলকে বোঝায়)। label_batch আকৃতির একটি টেনসর (32,) , এগুলি 32টি চিত্রের সাথে সম্পর্কিত লেবেল।
numpy.ndarray-এ রূপান্তর করতে আপনি এই numpy.ndarray .numpy() কল করতে পারেন।
ডেটা স্ট্যান্ডার্ডাইজ করুন
RGB চ্যানেলের মানগুলি [0, 255] পরিসরে। এটি একটি নিউরাল নেটওয়ার্কের জন্য আদর্শ নয়; সাধারণভাবে আপনার ইনপুট মান ছোট করার চেষ্টা করা উচিত।
এখানে, আপনি tf.keras.layers.Rescaling ব্যবহার করে মানগুলিকে [0, 1] পরিসরে মানানসই করবেন:
normalization_layer = tf.keras.layers.Rescaling(1./255)
এই স্তরটি ব্যবহার করার দুটি উপায় রয়েছে। আপনি Dataset.map কল করে এটি ডেটাসেটে প্রয়োগ করতে পারেন:
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
অথবা, আপনি স্থাপনাকে সহজ করতে আপনার মডেল সংজ্ঞার ভিতরে স্তরটি অন্তর্ভুক্ত করতে পারেন। আপনি এখানে দ্বিতীয় পদ্ধতি ব্যবহার করবেন।
কর্মক্ষমতা জন্য ডেটাসেট কনফিগার করুন
আসুন বাফার করা প্রিফেচিং ব্যবহার করা নিশ্চিত করি যাতে আপনি I/O ব্লক না হয়েই ডিস্ক থেকে ডেটা পেতে পারেন। ডেটা লোড করার সময় এই দুটি গুরুত্বপূর্ণ পদ্ধতি ব্যবহার করা উচিত:
-
Dataset.cacheপ্রথম যুগে ডিস্ক থেকে লোড করার পরে মেমরিতে রাখে। এটি নিশ্চিত করবে যে ডেটাসেটটি আপনার মডেলকে প্রশিক্ষণ দেওয়ার সময় বাধা হয়ে দাঁড়ায় না। আপনার ডেটাসেট মেমরিতে ফিট করার জন্য খুব বড় হলে, আপনি একটি পারফরম্যান্ট অন-ডিস্ক ক্যাশে তৈরি করতে এই পদ্ধতিটি ব্যবহার করতে পারেন। -
Dataset.prefetchপ্রশিক্ষণের সময় ডেটা প্রিপ্রসেসিং এবং মডেল এক্সিকিউশন ওভারল্যাপ করে।
আগ্রহী পাঠকরা tf.data API গাইডের সাথে বেটার পারফরম্যান্সের প্রিফেচিং বিভাগে ডিস্কে কীভাবে ডেটা ক্যাশে করতে হয় তা উভয় পদ্ধতি সম্পর্কে আরও শিখতে পারেন।
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
একটি মডেল প্রশিক্ষণ
সম্পূর্ণতার জন্য, আপনি দেখাবেন কীভাবে আপনার তৈরি করা ডেটাসেটগুলি ব্যবহার করে একটি সাধারণ মডেলকে প্রশিক্ষণ দেওয়া যায়।
tf.keras.layers.Conv2D ) থাকে যার প্রতিটিতে সর্বোচ্চ পুলিং লেয়ার ( tf.keras.layers.MaxPooling2D ) থাকে। একটি সম্পূর্ণ-সংযুক্ত স্তর রয়েছে ( tf.keras.layers.Dense ) যার উপরে 128টি ইউনিট রয়েছে যা একটি ReLU অ্যাক্টিভেশন ফাংশন ( 'relu' ) দ্বারা সক্রিয় করা হয়েছে। এই মডেলটি কোনোভাবেই টিউন করা হয়নি—লক্ষ্য হল আপনার তৈরি করা ডেটাসেটগুলি ব্যবহার করে মেকানিক্স দেখানো। চিত্র শ্রেণীবিভাগ সম্পর্কে আরও জানতে, চিত্র শ্রেণীবিভাগ টিউটোরিয়াল দেখুন।
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
tf.keras.optimizers.Adam অপ্টিমাইজার এবং tf.keras.losses.SparseCategoricalCrossentropy ক্ষতি ফাংশন চয়ন করুন। প্রতিটি প্রশিক্ষণ যুগের জন্য প্রশিক্ষণ এবং যাচাইকরণের নির্ভুলতা দেখতে, Model.compile এ metrics আর্গুমেন্ট পাস করুন।
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
আপনি লক্ষ্য করতে পারেন যে প্রশিক্ষণের নির্ভুলতার তুলনায় যাচাইকরণের নির্ভুলতা কম, এটি নির্দেশ করে যে আপনার মডেলটি ওভারফিটিং। আপনি এই টিউটোরিয়ালে ওভারফিটিং এবং কীভাবে এটি কমাতে হয় সে সম্পর্কে আরও শিখতে পারেন।
সূক্ষ্ম নিয়ন্ত্রণের জন্য tf.data ব্যবহার করা
উপরের কেরাস প্রিপ্রসেসিং tf.keras.utils.image_dataset_from_directory — চিত্রগুলির একটি ডিরেক্টরি থেকে একটি tf.data.Dataset তৈরি করার একটি সুবিধাজনক উপায়।
সূক্ষ্ম শস্য নিয়ন্ত্রণের জন্য, আপনি tf.data ব্যবহার করে আপনার নিজের ইনপুট পাইপলাইন লিখতে পারেন। আপনি আগে ডাউনলোড করা TGZ ফাইল থেকে ফাইল পাথ দিয়ে শুরু করে এই বিভাগটি দেখায় যে কীভাবে এটি করতে হয়।
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
ফাইলের ট্রি স্ট্রাকচার একটি class_names তালিকা কম্পাইল করতে ব্যবহার করা যেতে পারে।
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
প্রশিক্ষণ এবং বৈধতা সেটে ডেটাসেট বিভক্ত করুন:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
আপনি নিম্নলিখিত হিসাবে প্রতিটি ডেটাসেটের দৈর্ঘ্য প্রিন্ট করতে পারেন:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
একটি সংক্ষিপ্ত ফাংশন লিখুন যা একটি ফাইল পাথকে একটি (img, label) জোড়ায় রূপান্তর করে:
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
image, label জোড়ার একটি ডেটাসেট তৈরি করতে Dataset.map ব্যবহার করুন:
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
কর্মক্ষমতা জন্য ডেটাসেট কনফিগার করুন
এই ডেটাসেটের সাথে একটি মডেলকে প্রশিক্ষণ দিতে আপনি ডেটা চাইবেন:
- ভালভাবে এলোমেলো হতে.
- ব্যাচ করা.
- ব্যাচ যত তাড়াতাড়ি সম্ভব উপলব্ধ করা হবে.
এই বৈশিষ্ট্যগুলি tf.data API ব্যবহার করে যোগ করা যেতে পারে। আরও বিশদ বিবরণের জন্য, ইনপুট পাইপলাইন পারফরম্যান্স গাইড দেখুন।
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
ডেটা ভিজ্যুয়ালাইজ করুন
আপনি পূর্বে তৈরি করা ডেটাসেটটির অনুরূপভাবে এই ডেটাসেটটিকে কল্পনা করতে পারেন:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
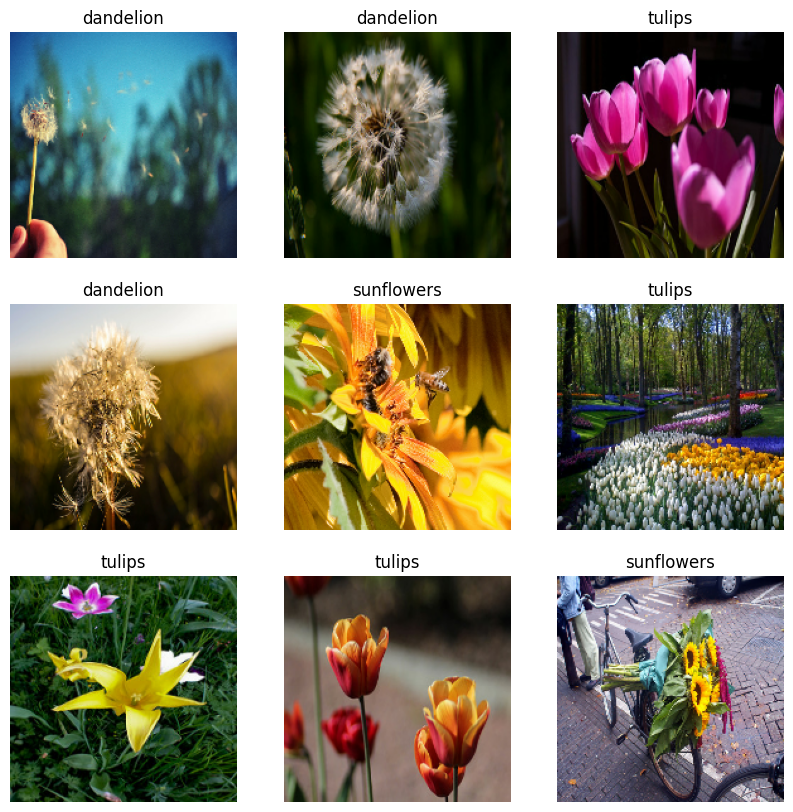
মডেল প্রশিক্ষণ চালিয়ে যান
আপনি এখন উপরে tf.keras.utils.image_dataset_from_directory দ্বারা তৈরি করা একটি অনুরূপ tf.data.Dataset তৈরি করেছেন। আপনি এটি দিয়ে মডেল প্রশিক্ষণ চালিয়ে যেতে পারেন। আগের মতো, আপনি চলমান সময়কে ছোট রাখতে মাত্র কয়েকটি যুগের জন্য প্রশিক্ষণ দেবেন।
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
টেনসরফ্লো ডেটাসেট ব্যবহার করা
এখন পর্যন্ত, এই টিউটোরিয়ালটি ডিস্ক থেকে ডেটা লোড করার উপর দৃষ্টি নিবদ্ধ করেছে। এছাড়াও আপনি TensorFlow ডেটাসেট-এ সহজে ডাউনলোড করা যায় এমন ডেটাসেটের বড় ক্যাটালগ অন্বেষণ করে ব্যবহার করার জন্য একটি ডেটাসেট খুঁজে পেতে পারেন।
আপনি আগে যেমন ফ্লাওয়ারস ডেটাসেট অফ ডিস্ক লোড করেছেন, এখন টেনসরফ্লো ডেটাসেটের সাথে এটি আমদানি করা যাক।
টেনসরফ্লো ডেটাসেট ব্যবহার করে ফুলের ডেটাসেট ডাউনলোড করুন:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
ফুলের ডেটাসেটের পাঁচটি শ্রেণী রয়েছে:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
ডেটাসেট থেকে একটি ছবি পুনরুদ্ধার করুন:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

আগের মত, ব্যাচ, শাফেল, এবং কর্মক্ষমতা জন্য প্রশিক্ষণ, বৈধতা, এবং পরীক্ষা সেট কনফিগার করতে মনে রাখবেন:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
আপনি ডেটা অগমেন্টেশন টিউটোরিয়ালটিতে গিয়ে ফুল ডেটাসেট এবং টেনসরফ্লো ডেটাসেটগুলির সাথে কাজ করার একটি সম্পূর্ণ উদাহরণ খুঁজে পেতে পারেন।
পরবর্তী পদক্ষেপ
এই টিউটোরিয়ালটি ডিস্ক থেকে ছবি লোড করার দুটি উপায় দেখিয়েছে। প্রথমে, আপনি কেরাস প্রিপ্রসেসিং লেয়ার এবং ইউটিলিটি ব্যবহার করে একটি ইমেজ ডেটাসেট লোড এবং প্রিপ্রসেস করতে শিখেছেন। এরপর, আপনি শিখেছেন কিভাবে tf.data ব্যবহার করে স্ক্র্যাচ থেকে একটি ইনপুট পাইপলাইন লিখতে হয়। অবশেষে, আপনি শিখেছেন কিভাবে টেনসরফ্লো ডেটাসেট থেকে একটি ডেটাসেট ডাউনলোড করতে হয়।
আপনার পরবর্তী পদক্ষেপের জন্য:
- আপনি কীভাবে ডেটা অগমেন্টেশন যোগ করবেন তা শিখতে পারেন।
-
tf.dataসম্পর্কে আরও জানতে, আপনি tf.data: বিল্ড টেনসরফ্লো ইনপুট পাইপলাইন গাইড দেখতে পারেন।