
| | |  הצג ב-GitHub הצג ב-GitHub | |
Colab זוהי הדגמה של שימוש Hub Tensorflow לסיווג הטקסט הלא-אנגלית / שפות מקומיות. כאן אנו בוחרים באנגלה כשפת המקומית ולהשתמש pretrained מילת שיבוצים לפתור משימת סיווג multiclass היכן נסווג כתבות חדשות באנגלה ב 5 קטגוריות. שיבוצי pretrained עבור באנגלה מגיעים fastText שהינה ספרייה ידי פייסבוק עם וקטורי מילת pretrained שוחררו עבור 157 שפות.
נשתמש יצואן הטבעת pretrained של TF-Hub להמרת המילה שיבוצים למודול הטבעת טקסט הראשון ולאחר מכן להשתמש במודול להכשיר מסווג עם tf.keras , API הידידותי למשתמש הרמה הגבוהה של Tensorflow לבנות מודלים למידה עמוקים. גם אם אנחנו משתמשים בהטמעות של fastText כאן, אפשר לייצא כל הטמעה אחרת שהוכשרה מראש ממשימות אחרות ולקבל תוצאות במהירות עם Tensorflow hub.
להכין
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
מערך נתונים
נשתמש BARD (בסיס הנתונים סעיף באנגלה) אשר יש סביב 376,226 מאמרים שנאספו פורטלי חדשות באנגלה שונים שכותרתו עם 5 קטגוריות: כלכלה, מדינה, בינלאומי, ספורט, ובידור. אנו להוריד את הקובץ מ- Google Drive זו ( bit.ly/BARD_DATASET ) קישור מתייחס מ זה מאגר GitHub.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
ייצא וקטורי מילים מאומנים מראש למודול TF-Hub
TF-Hub מספק כמה סקריפטים שימושיים להמרת מילת שיבוצים כדי מודולים הטבעת טקסט TF-רכזת כאן . כדי להפוך את מודול עבור באנגלה או בכל שפה אחרת, אנחנו פשוט צריכים להוריד את המילה הטבעה .txt או .vec הקובץ באותה ספרייה כמו export_v2.py ולהפעיל את התסריט.
היצואן קורא את וקטורי הטבעה ומייצא אותו Tensorflow SavedModel . SavedModel מכיל תוכנית TensorFlow מלאה הכוללת משקלים וגרף. TF-Hub יכול לטעון את SavedModel בתור מודול , אשר נשתמש כדי לבנות מודל לסיווג הטקסט. מאז אנחנו משתמשים tf.keras לבנות מודל, נשתמש hub.KerasLayer , המספקת מעטפת עבור מודול TF-Hub לשימוש כשכבה Keras.
ראשית נקבל שיבוצי המילה שלנו fastText ויצואנית הטבעה מ-Hub TF ריפה .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
לאחר מכן, נריץ את סקריפט היצואן בקובץ ההטמעה שלנו. מכיוון שלטבעות fastText יש שורת כותרת והן די גדולות (בסביבות 3.3 ג'יגה-בייט לבנגלה לאחר המרה למודול), אנו מתעלמים מהשורה הראשונה ומייצאים רק את 100,000 האסימונים הראשונים למודול הטבעת הטקסט.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
מודול הטבעת הטקסט לוקח אצווה של משפטים בטנזור 1D של מחרוזות כקלט ומוציא את וקטורי הטבעה של הצורה (batch_size, embedding_dim) התואמים למשפטים. זה מעבד מראש את הקלט על ידי פיצול על רווחים. שיבוצי Word משולבים שיבוצי משפט עם sqrtn combiner (ראה כאן ). להדגמה אנו מעבירים רשימה של מילים באנגלה כקלט ומקבלים את וקטורי ההטמעה המתאימים.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
המר למערך נתונים של Tensorflow
מאז במערך הוא באמת גדול במקום העלאה במערך כולו בזיכרון נשתמש מחולל להניב דגימות זמן ריצה בקבוצות באמצעות מערך נתונים Tensorflow פונקציות. מערך הנתונים גם מאוד לא מאוזן, לכן, לפני השימוש במחולל, נערבב את מערך הנתונים.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
נוכל לבדוק את התפלגות התוויות בדוגמאות ההדרכה והתיקוף לאחר הדשדוש.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
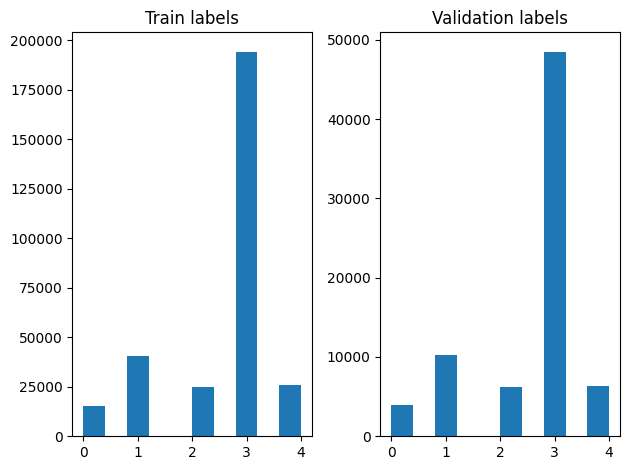
כדי ליצור מערך נתונים באמצעות גנרטור, אנחנו הראשונים לכתוב פונקציה גנרטור אשר קורא לכל המאמרים מן file_paths ואת התוויות מן המערך התווית, והתשואות למשל אימון אחד בכל שלב. אנחנו עוברים פונקצית גנרטור זו אלי tf.data.Dataset.from_generator השיטה ולציין את סוגי הפלט. כול למשל אימונים הוא tuple המכיל מאמר של tf.string סוג נתוני תווית מקודדת-חם אחד. אנו לפצל את הנתונים עם פיצול הרכבת אימות של 80-20 באמצעות tf.data.Dataset.skip ו tf.data.Dataset.take שיטות.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
הדרכה והערכה של מודלים
מכיוון שאנו כבר הוספנו מעטפת סביב מודול שלנו להשתמש בו כמו כול שכבה אחרת Keras, נוכל ליצור קטן סדרתית מודל שהוא ערימה ליניארי של שכבות. אנחנו יכולים להוסיף מודול שיבוץ הטקסט שלנו עם model.add בדיוק כמו כל שכבה אחרת. אנו מרכיבים את המודל על ידי ציון האובדן והאופטימיזציה ומאמנים אותו למשך 10 עידנים. tf.keras API יכול להתמודד מערכי נתוני Tensorflow כקלט, כדי שנוכל להעביר מופע של מערך נתונים לשיטה בכושר לאימוני מודל. מאז אנחנו משתמשים בפונקציית מחולל, tf.data יטפל יצירת דגימות, batching אותם ומאכילים אותם למודל.
דֶגֶם
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
הַדְרָכָה
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
הַעֲרָכָה
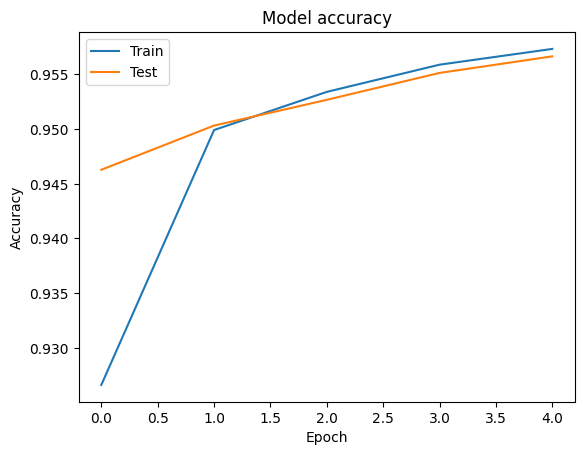
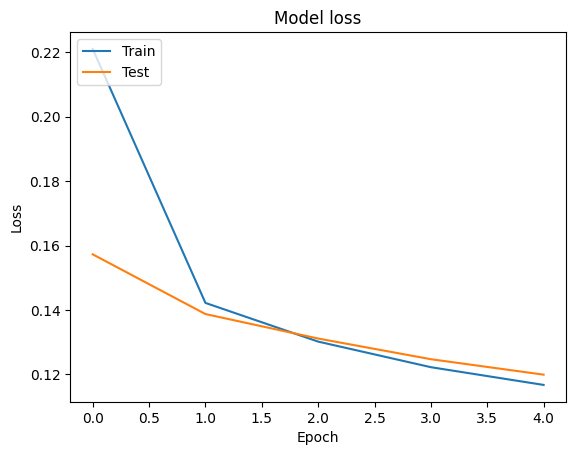
אנחנו יכולים לדמיין את עקומות דיוק ואובדן נתונים הכשרה ותיקוף באמצעות tf.keras.callbacks.History האובייקט המוחזר על ידי tf.keras.Model.fit השיטה, אשר מכיל את הערך אובדן ודיוק לכל התקופה.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
נְבוּאָה
אנו יכולים לקבל את התחזיות עבור נתוני האימות ולבדוק את מטריצת הבלבול כדי לראות את ביצועי המודל עבור כל אחת מ-5 המחלקות. מכיוון tf.keras.Model.predict השיטה מחזירה מערך nd עבור ההסתברויות עבור כל מחלקה, הם יכולים להיות מומרים תוויות לכיתה באמצעות np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
השווה ביצועים
עכשיו אנחנו יכולים לקחת את התוויות הנכונות עבור אימות הנתונים מ labels ולהשוות אותם עם התחזיות שלנו כדי לקבל classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
אנחנו יכולים גם להשוות את הביצועים של המודל שלנו עם התוצאות שפורסמו שהושגו במקור הנייר , אשר היה מחברים מקוריים 0.96 הדיוק .the תארו צעדים מקדימים רבים שבוצעו על בסיס נתון, כגון השמטת סימני פיסוק ומספרים, הסרת מילות מעכבות frequest ביותר העליון 25. כפי שאנו רואים את classification_report , אנו גם מצליחים לקבל 0.96 דיוק ודיוק אחרי אימון רק 5 תקופות ללא כל עיבוד מקדים!
בדוגמא זו, כאשר יצרנו את שכבת Keras ממודול ההטבעה שלנו, אנו קובעים את הפרמטר trainable=False , כלומר משקולות הטבעה לא עודכנו במהלך אימונים. נסה להגדיר אותו True כדי להגיע בסביבות 97% דיוק באמצעות מערך הנתונים הזה אחרי רק 2 תקופות.