
| | |  Voir sur GitHub Voir sur GitHub | | |
Avez-vous déjà vu une belle fleur et vous êtes-vous demandé de quel genre de fleur il s'agissait ? Eh bien, vous n'êtes pas le premier, alors construisons un moyen d'identifier le type de fleur à partir d'une photo !
Pour classer les images, un type particulier de réseau de neurones profond, appelé un réseau de neurones convolutionnel est avéré être particulièrement puissant. Cependant, les réseaux de neurones convolutifs modernes ont des millions de paramètres. Les former à partir de zéro nécessite beaucoup de données de formation étiquetées et beaucoup de puissance de calcul (des centaines d'heures GPU ou plus). Nous n'avons qu'environ trois mille photos étiquetées et voulons passer beaucoup moins de temps, nous devons donc être plus intelligents.
Nous utiliserons une technique appelée l' apprentissage de transfert où nous prenons un réseau pré-formé (formé à environ un million d' images générales), l' utiliser pour extraire les caractéristiques et former une nouvelle couche sur le dessus pour notre propre tâche de classer les images de fleurs.
Installer
import collections
import io
import math
import os
import random
from six.moves import urllib
from IPython.display import clear_output, Image, display, HTML
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import tensorflow_hub as hub
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.metrics as sk_metrics
import time
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/compat/v2_compat.py:111: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version. Instructions for updating: non-resource variables are not supported in the long term
Le jeu de données sur les fleurs
L'ensemble de données de fleurs se compose d'images de fleurs avec 5 étiquettes de classe possibles.
Lors de l'entraînement d'un modèle d'apprentissage automatique, nous divisons nos données en ensembles de données d'entraînement et de test. Nous entraînerons le modèle sur nos données d'entraînement, puis évaluerons les performances du modèle sur des données qu'il n'a jamais vues - l'ensemble de test.
Téléchargeons nos exemples d'entraînement et de test (cela peut prendre un certain temps) et divisons-les en ensembles d'entraînement et de test.
Exécutez les deux cellules suivantes :
FLOWERS_DIR = './flower_photos'
TRAIN_FRACTION = 0.8
RANDOM_SEED = 2018
def download_images():
"""If the images aren't already downloaded, save them to FLOWERS_DIR."""
if not os.path.exists(FLOWERS_DIR):
DOWNLOAD_URL = 'http://download.tensorflow.org/example_images/flower_photos.tgz'
print('Downloading flower images from %s...' % DOWNLOAD_URL)
urllib.request.urlretrieve(DOWNLOAD_URL, 'flower_photos.tgz')
!tar xfz flower_photos.tgz
print('Flower photos are located in %s' % FLOWERS_DIR)
def make_train_and_test_sets():
"""Split the data into train and test sets and get the label classes."""
train_examples, test_examples = [], []
shuffler = random.Random(RANDOM_SEED)
is_root = True
for (dirname, subdirs, filenames) in tf.gfile.Walk(FLOWERS_DIR):
# The root directory gives us the classes
if is_root:
subdirs = sorted(subdirs)
classes = collections.OrderedDict(enumerate(subdirs))
label_to_class = dict([(x, i) for i, x in enumerate(subdirs)])
is_root = False
# The sub directories give us the image files for training.
else:
filenames.sort()
shuffler.shuffle(filenames)
full_filenames = [os.path.join(dirname, f) for f in filenames]
label = dirname.split('/')[-1]
label_class = label_to_class[label]
# An example is the image file and it's label class.
examples = list(zip(full_filenames, [label_class] * len(filenames)))
num_train = int(len(filenames) * TRAIN_FRACTION)
train_examples.extend(examples[:num_train])
test_examples.extend(examples[num_train:])
shuffler.shuffle(train_examples)
shuffler.shuffle(test_examples)
return train_examples, test_examples, classes
# Download the images and split the images into train and test sets.
download_images()
TRAIN_EXAMPLES, TEST_EXAMPLES, CLASSES = make_train_and_test_sets()
NUM_CLASSES = len(CLASSES)
print('\nThe dataset has %d label classes: %s' % (NUM_CLASSES, CLASSES.values()))
print('There are %d training images' % len(TRAIN_EXAMPLES))
print('there are %d test images' % len(TEST_EXAMPLES))
Downloading flower images from http://download.tensorflow.org/example_images/flower_photos.tgz... Flower photos are located in ./flower_photos The dataset has 5 label classes: odict_values(['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']) There are 2934 training images there are 736 test images
Explorer les données
L'ensemble de données sur les fleurs se compose d'exemples étiquetés comme des images de fleurs. Chaque exemple contient une image de fleur JPEG et l'étiquette de classe : de quel type de fleur il s'agit. Montrons quelques images avec leurs étiquettes.
Afficher des images étiquetées
def get_label(example):
"""Get the label (number) for given example."""
return example[1]
def get_class(example):
"""Get the class (string) of given example."""
return CLASSES[get_label(example)]
def get_encoded_image(example):
"""Get the image data (encoded jpg) of given example."""
image_path = example[0]
return tf.gfile.GFile(image_path, 'rb').read()
def get_image(example):
"""Get image as np.array of pixels for given example."""
return plt.imread(io.BytesIO(get_encoded_image(example)), format='jpg')
def display_images(images_and_classes, cols=5):
"""Display given images and their labels in a grid."""
rows = int(math.ceil(len(images_and_classes) / cols))
fig = plt.figure()
fig.set_size_inches(cols * 3, rows * 3)
for i, (image, flower_class) in enumerate(images_and_classes):
plt.subplot(rows, cols, i + 1)
plt.axis('off')
plt.imshow(image)
plt.title(flower_class)
NUM_IMAGES = 15
display_images([(get_image(example), get_class(example))
for example in TRAIN_EXAMPLES[:NUM_IMAGES]])

Construire le modèle
Nous allons charger un TF-Hub d' image Module fonction de vecteur, pile un classificateur linéaire, et ajouter des opérations de formation et d' évaluation. La cellule suivante crée un graphique TF décrivant le modèle et son entraînement, mais n'exécute pas l'entraînement (ce sera la prochaine étape).
LEARNING_RATE = 0.01
tf.reset_default_graph()
# Load a pre-trained TF-Hub module for extracting features from images. We've
# chosen this particular module for speed, but many other choices are available.
image_module = hub.Module('https://tfhub.dev/google/imagenet/mobilenet_v2_035_128/feature_vector/2')
# Preprocessing images into tensors with size expected by the image module.
encoded_images = tf.placeholder(tf.string, shape=[None])
image_size = hub.get_expected_image_size(image_module)
def decode_and_resize_image(encoded):
decoded = tf.image.decode_jpeg(encoded, channels=3)
decoded = tf.image.convert_image_dtype(decoded, tf.float32)
return tf.image.resize_images(decoded, image_size)
batch_images = tf.map_fn(decode_and_resize_image, encoded_images, dtype=tf.float32)
# The image module can be applied as a function to extract feature vectors for a
# batch of images.
features = image_module(batch_images)
def create_model(features):
"""Build a model for classification from extracted features."""
# Currently, the model is just a single linear layer. You can try to add
# another layer, but be careful... two linear layers (when activation=None)
# are equivalent to a single linear layer. You can create a nonlinear layer
# like this:
# layer = tf.layers.dense(inputs=..., units=..., activation=tf.nn.relu)
layer = tf.layers.dense(inputs=features, units=NUM_CLASSES, activation=None)
return layer
# For each class (kind of flower), the model outputs some real number as a score
# how much the input resembles this class. This vector of numbers is often
# called the "logits".
logits = create_model(features)
labels = tf.placeholder(tf.float32, [None, NUM_CLASSES])
# Mathematically, a good way to measure how much the predicted probabilities
# diverge from the truth is the "cross-entropy" between the two probability
# distributions. For numerical stability, this is best done directly from the
# logits, not the probabilities extracted from them.
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=labels)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# Let's add an optimizer so we can train the network.
optimizer = tf.train.GradientDescentOptimizer(learning_rate=LEARNING_RATE)
train_op = optimizer.minimize(loss=cross_entropy_mean)
# The "softmax" function transforms the logits vector into a vector of
# probabilities: non-negative numbers that sum up to one, and the i-th number
# says how likely the input comes from class i.
probabilities = tf.nn.softmax(logits)
# We choose the highest one as the predicted class.
prediction = tf.argmax(probabilities, 1)
correct_prediction = tf.equal(prediction, tf.argmax(labels, 1))
# The accuracy will allow us to eval on our test set.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
WARNING:tensorflow:From /tmp/ipykernel_3995/2879154528.py:20: calling map_fn (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version. Instructions for updating: Use fn_output_signature instead WARNING:tensorflow:From /tmp/ipykernel_3995/2879154528.py:20: calling map_fn (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version. Instructions for updating: Use fn_output_signature instead INFO:tensorflow:Saver not created because there are no variables in the graph to restore INFO:tensorflow:Saver not created because there are no variables in the graph to restore /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:34: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead. /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/legacy_tf_layers/core.py:255: UserWarning: `layer.apply` is deprecated and will be removed in a future version. Please use `layer.__call__` method instead. return layer.apply(inputs)
Former le réseau
Maintenant que notre modèle est construit, entraînons-le et voyons comment il se comporte sur notre ensemble de test.
# How long will we train the network (number of batches).
NUM_TRAIN_STEPS = 100
# How many training examples we use in each step.
TRAIN_BATCH_SIZE = 10
# How often to evaluate the model performance.
EVAL_EVERY = 10
def get_batch(batch_size=None, test=False):
"""Get a random batch of examples."""
examples = TEST_EXAMPLES if test else TRAIN_EXAMPLES
batch_examples = random.sample(examples, batch_size) if batch_size else examples
return batch_examples
def get_images_and_labels(batch_examples):
images = [get_encoded_image(e) for e in batch_examples]
one_hot_labels = [get_label_one_hot(e) for e in batch_examples]
return images, one_hot_labels
def get_label_one_hot(example):
"""Get the one hot encoding vector for the example."""
one_hot_vector = np.zeros(NUM_CLASSES)
np.put(one_hot_vector, get_label(example), 1)
return one_hot_vector
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(NUM_TRAIN_STEPS):
# Get a random batch of training examples.
train_batch = get_batch(batch_size=TRAIN_BATCH_SIZE)
batch_images, batch_labels = get_images_and_labels(train_batch)
# Run the train_op to train the model.
train_loss, _, train_accuracy = sess.run(
[cross_entropy_mean, train_op, accuracy],
feed_dict={encoded_images: batch_images, labels: batch_labels})
is_final_step = (i == (NUM_TRAIN_STEPS - 1))
if i % EVAL_EVERY == 0 or is_final_step:
# Get a batch of test examples.
test_batch = get_batch(batch_size=None, test=True)
batch_images, batch_labels = get_images_and_labels(test_batch)
# Evaluate how well our model performs on the test set.
test_loss, test_accuracy, test_prediction, correct_predicate = sess.run(
[cross_entropy_mean, accuracy, prediction, correct_prediction],
feed_dict={encoded_images: batch_images, labels: batch_labels})
print('Test accuracy at step %s: %.2f%%' % (i, (test_accuracy * 100)))
Test accuracy at step 0: 22.01% Test accuracy at step 10: 52.04% Test accuracy at step 20: 63.99% Test accuracy at step 30: 69.97% Test accuracy at step 40: 74.59% Test accuracy at step 50: 75.00% Test accuracy at step 60: 75.00% Test accuracy at step 70: 78.26% Test accuracy at step 80: 80.98% Test accuracy at step 90: 79.21% Test accuracy at step 99: 80.30%
def show_confusion_matrix(test_labels, predictions):
"""Compute confusion matrix and normalize."""
confusion = sk_metrics.confusion_matrix(
np.argmax(test_labels, axis=1), predictions)
confusion_normalized = confusion.astype("float") / confusion.sum(axis=1)
axis_labels = list(CLASSES.values())
ax = sns.heatmap(
confusion_normalized, xticklabels=axis_labels, yticklabels=axis_labels,
cmap='Blues', annot=True, fmt='.2f', square=True)
plt.title("Confusion matrix")
plt.ylabel("True label")
plt.xlabel("Predicted label")
show_confusion_matrix(batch_labels, test_prediction)
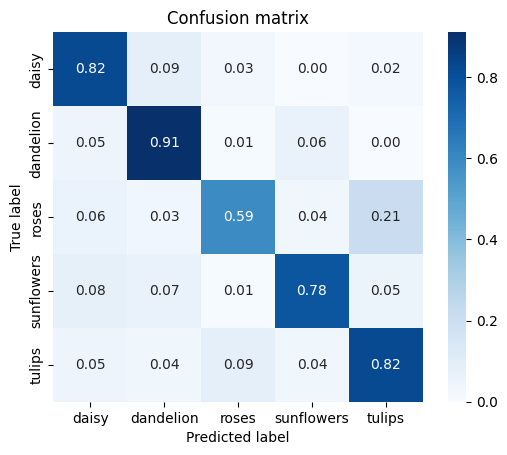
Prédictions incorrectes
Examinons de plus près les exemples de test sur lesquels notre modèle s'est trompé.
- Y a-t-il des exemples mal étiquetés dans notre ensemble de test ?
- Y a-t-il des données erronées dans l'ensemble de test - des images qui ne sont pas réellement des images de fleurs ?
- Y a-t-il des images où vous pouvez comprendre pourquoi le modèle s'est trompé ?
incorrect = [
(example, CLASSES[prediction])
for example, prediction, is_correct in zip(test_batch, test_prediction, correct_predicate)
if not is_correct
]
display_images(
[(get_image(example), "prediction: {0}\nlabel:{1}".format(incorrect_prediction, get_class(example)))
for (example, incorrect_prediction) in incorrect[:20]])

Exercices : Améliorez le modèle !
Nous avons formé un modèle de base, essayons maintenant de l'améliorer pour obtenir une meilleure précision. (N'oubliez pas que vous devrez réexécuter les cellules lorsque vous apporterez une modification.)
Exercice 1 : Essayez un autre modèle d'image.
Avec TF-Hub, essayer quelques modèles d'images différents est simple. Il suffit de remplacer le "https://tfhub.dev/google/imagenet/mobilenet_v2_050_128/feature_vector/2" poignée dans le hub.Module() appel avec une poignée de module différent et exécutez à nouveau tout le code. Vous pouvez voir tous les modules d'image disponibles à tfhub.dev .
Un bon choix pourrait être l' un des autres modules MobileNet V2 . La plupart des modules - y compris les modules MobileNet - ont été formés sur l' ensemble de données IMAGEnet qui contient plus de 1 million d' images et 1000 classes. Le choix d'une architecture de réseau offre un compromis entre vitesse et précision de classification : des modèles comme MobileNet ou NASNet Mobile sont rapides et petits, des architectures plus traditionnelles comme Inception et ResNet ont été conçues pour la précision.
Pour la plus grande architecture de lancement V3, vous pouvez également explorer les avantages de la pré-formation sur un domaine plus proche de votre tâche: il est également disponible en tant que module de formation sur l'ensemble de données iNaturalist des plantes et des animaux.
Exercice 2 : ajouter un calque masqué.
Empiler une couche cachée entre des éléments d'image extraites et le classificateur linéaire (en fonction create_model() ci - dessus). Pour créer une couche cachée non linéaire par exemple 100 noeuds, l' utilisation tf.layers.dense avec les unités fixées à 100 et un ensemble d'activation pour tf.nn.relu . La modification de la taille de la couche cachée affecte-t-elle la précision du test ? L'ajout d'une deuxième couche cachée améliore-t-il la précision ?
Exercice 3 : Modifier les hyperparamètres.
Est -ce que de plus en plus d'étapes de formation améliore la précision finale? Pouvez - vous changer le taux d'apprentissage pour rendre votre Converge modèle plus rapidement? Est -ce que la taille du lot de formation affecte les performances de votre modèle?
Exercice 4 : essayez un autre optimiseur.
Remplacez le GradientDescentOptimizer de base avec un plus optimiseur de sophistiquer, par exemple AdagradOptimizer . Cela fait-il une différence dans votre formation de mannequin ? Si vous voulez en savoir plus sur les avantages des différents algorithmes d'optimisation, consultez ce post .
Vous voulez en savoir plus ?
Si vous êtes intéressé par une version plus avancée de ce tutoriel, consultez le tutoriel recyclage image tensorflow qui vous guide à travers la visualisation de la formation à l' aide TensorBoard, des techniques avancées comme jeu de données augmentation en déformant les images, et en remplaçant les fleurs DataSet pour apprendre un classificateur d'image sur votre propre jeu de données.
Vous pouvez en savoir plus sur tensorflow à tensorflow.org et consultez la documentation API TF-Hub est disponible à tensorflow.org/hub . Trouvez des tensorflow modules Hub à tfhub.dev y compris plusieurs modules de fonction d'images vectorielles et modules Embedding texte.
Consultez également le Machine Learning Crash Course qui est de Google rapide, introduction pratique à l' apprentissage de la machine.