
TensorFlow के एक प्रमुख घटक का एक उदाहरण विस्तारित
 GitHub पर स्रोत देखें
GitHub पर स्रोत देखेंयह उदाहरण कोलाब नोटबुक दिखाता है कि कैसे आपके डेटासेट की जांच और कल्पना करने के लिए TensorFlow डेटा सत्यापन (TFDV) का उपयोग किया जा सकता है। इसमें वर्णनात्मक आँकड़ों को देखना, एक स्कीमा का उल्लेख करना, विसंगतियों की जाँच करना और उन्हें ठीक करना और हमारे डेटासेट में बहाव और तिरछा की जाँच करना शामिल है। आपके डेटासेट की विशेषताओं को समझना महत्वपूर्ण है, जिसमें यह भी शामिल है कि यह आपकी उत्पादन पाइपलाइन में समय के साथ कैसे बदल सकता है। अपने डेटा में विसंगतियों को देखना और यह सुनिश्चित करने के लिए कि वे सुसंगत हैं, अपने प्रशिक्षण, मूल्यांकन और सेवा डेटासेट की तुलना करना भी महत्वपूर्ण है।
हम शिकागो शहर द्वारा जारी टैक्सी ट्रिप डेटासेट के डेटा का उपयोग करेंगे।
Google BigQuery में डेटासेट के बारे में और पढ़ें । BigQuery UI में संपूर्ण डेटासेट एक्सप्लोर करें.
डेटासेट में कॉलम हैं:
| पिकअप_समुदाय_क्षेत्र | किराया | ट्रिप_स्टार्ट_माह |
| यात्रा_शुरू_घंटा | यात्रा_शुरू_दिन | ट्रिप_स्टार्ट_टाइमस्टैम्प |
| पिकअप_अक्षांश | पिकअप_देशांतर | ड्रॉपऑफ_अक्षांश |
| ड्रॉपऑफ_देशांतर | ट्रिप_मील | पिकअप_सेंसस_ट्रैक्ट |
| ड्रॉपऑफ़_सेंसस_ट्रैक्ट | भुगतान के प्रकार | कंपनी |
| यात्रा_सेकंड | ड्रॉपऑफ़_समुदाय_क्षेत्र | टिप्स |
पैकेज स्थापित करें और आयात करें
TensorFlow डेटा सत्यापन के लिए पैकेज स्थापित करें।
पिप अपग्रेड करें
स्थानीय रूप से चलते समय सिस्टम में पिप को अपग्रेड करने से बचने के लिए, यह सुनिश्चित करने के लिए जांचें कि हम कोलाब में चल रहे हैं। स्थानीय प्रणालियों को निश्चित रूप से अलग से अपग्रेड किया जा सकता है।
try:
import colab
!pip install --upgrade pip
except:
pass
डेटा सत्यापन पैकेज स्थापित करें
TensorFlow डेटा सत्यापन पैकेज और निर्भरताएँ स्थापित करें, जिसमें कुछ मिनट लगते हैं। आप असंगत निर्भरता संस्करणों के संबंध में चेतावनियां और त्रुटियां देख सकते हैं, जिनका समाधान आप अगले भाग में करेंगे।
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
TensorFlow आयात करें और अद्यतन पैकेज पुनः लोड करें
पिछला चरण Google Colab परिवेश में डिफ़ॉल्ट पैकेज को अपडेट करता है, इसलिए आपको नई निर्भरता को हल करने के लिए पैकेज संसाधनों को फिर से लोड करना होगा।
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
आगे बढ़ने से पहले TensorFlow के संस्करण और डेटा सत्यापन की जाँच करें।
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
डेटासेट लोड करें
हम अपना डेटासेट Google क्लाउड स्टोरेज से डाउनलोड करेंगे।
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
आँकड़ों की गणना और कल्पना करें
सबसे पहले हम अपने प्रशिक्षण डेटा के आंकड़ों की गणना करने के लिए tfdv.generate_statistics_from_csv का उपयोग करेंगे। (तड़क-भड़क वाली चेतावनियों पर ध्यान न दें)
टीएफडीवी वर्णनात्मक आंकड़ों की गणना कर सकता है जो मौजूद सुविधाओं और उनके मूल्य वितरण के आकार के संदर्भ में डेटा का त्वरित अवलोकन प्रदान करते हैं।
आंतरिक रूप से, TFDV बड़े डेटासेट पर आँकड़ों की गणना को मापने के लिए Apache Beam के डेटा-समानांतर प्रसंस्करण ढांचे का उपयोग करता है। उन अनुप्रयोगों के लिए जो टीएफडीवी के साथ गहराई से एकीकृत करना चाहते हैं (उदाहरण के लिए, डेटा-जनरेशन पाइपलाइन के अंत में सांख्यिकी पीढ़ी संलग्न करें), एपीआई सांख्यिकी पीढ़ी के लिए बीम पीट्रांसफॉर्म को भी उजागर करता है।
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
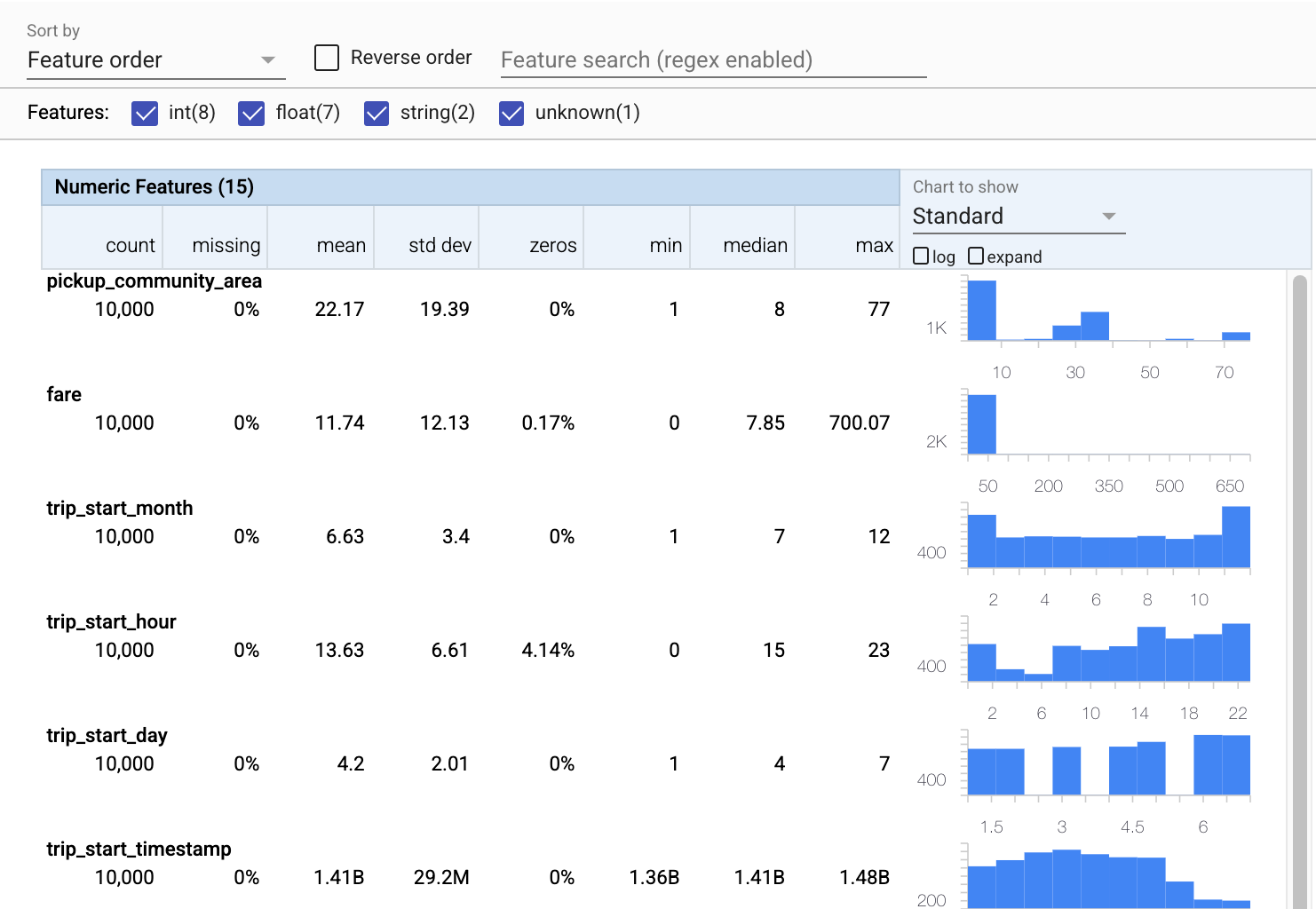
अब आइए tfdv.visualize_statistics का उपयोग करें, जो हमारे प्रशिक्षण डेटा का एक संक्षिप्त दृश्य बनाने के लिए Facets का उपयोग करता है:
- ध्यान दें कि संख्यात्मक विशेषताओं और श्रेणीबद्ध विशेषताओं को अलग-अलग विज़ुअलाइज़ किया जाता है, और चार्ट प्रत्येक सुविधा के लिए वितरण दिखाते हुए प्रदर्शित होते हैं।
- ध्यान दें कि अनुपलब्ध या शून्य मान वाली विशेषताएं एक दृश्य संकेतक के रूप में लाल रंग में प्रतिशत प्रदर्शित करती हैं कि उन सुविधाओं में उदाहरणों के साथ समस्या हो सकती है। प्रतिशत उन उदाहरणों का प्रतिशत है जिनमें उस सुविधा के लिए अनुपलब्ध या शून्य मान हैं।
- ध्यान दें कि
pickup_census_tractके मानों के साथ कोई उदाहरण नहीं है। यह आयामीता में कमी का अवसर है! - प्रदर्शन बदलने के लिए चार्ट के ऊपर "विस्तार" पर क्लिक करने का प्रयास करें
- बकेट रेंज और काउंट प्रदर्शित करने के लिए चार्ट में बार पर होवर करने का प्रयास करें
- लॉग और लीनियर स्केल के बीच स्विच करने का प्रयास करें, और ध्यान दें कि कैसे लॉग स्केल
payment_typeश्रेणीबद्ध सुविधा के बारे में अधिक विवरण प्रकट करता है - "दिखाने के लिए चार्ट" मेनू से "मात्राएं" चुनने का प्रयास करें, और मात्रात्मक प्रतिशत दिखाने के लिए मार्करों पर होवर करें
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
एक स्कीमा का अनुमान लगाएं
अब हमारे डेटा के लिए एक स्कीमा बनाने के लिए tfdv.infer_schema का उपयोग करते हैं। एक स्कीमा डेटा के लिए बाधाओं को परिभाषित करता है जो एमएल के लिए प्रासंगिक हैं। उदाहरण बाधाओं में प्रत्येक सुविधा का डेटा प्रकार शामिल है, चाहे वह संख्यात्मक हो या श्रेणीबद्ध, या डेटा में इसकी उपस्थिति की आवृत्ति। स्पष्ट विशेषताओं के लिए स्कीमा डोमेन को भी परिभाषित करती है - स्वीकार्य मूल्यों की सूची। चूंकि एक स्कीमा लिखना एक कठिन काम हो सकता है, विशेष रूप से बहुत सारी विशेषताओं वाले डेटासेट के लिए, टीएफडीवी वर्णनात्मक आंकड़ों के आधार पर स्कीमा का प्रारंभिक संस्करण उत्पन्न करने के लिए एक विधि प्रदान करता है।
स्कीमा को सही करना महत्वपूर्ण है क्योंकि हमारी बाकी उत्पादन पाइपलाइन उस स्कीमा पर निर्भर होगी जो TFDV सही होने के लिए उत्पन्न करती है। स्कीमा डेटा के लिए दस्तावेज़ीकरण भी प्रदान करती है, और इसलिए उपयोगी है जब विभिन्न डेवलपर्स एक ही डेटा पर काम करते हैं। आइए अनुमानित स्कीमा प्रदर्शित करने के लिए tfdv.display_schema का उपयोग करें ताकि हम इसकी समीक्षा कर सकें।
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
त्रुटियों के लिए मूल्यांकन डेटा की जाँच करें
अभी तक हम केवल प्रशिक्षण डेटा देख रहे हैं। यह महत्वपूर्ण है कि हमारा मूल्यांकन डेटा हमारे प्रशिक्षण डेटा के अनुरूप हो, जिसमें यह एक ही स्कीमा का उपयोग करता है। यह भी महत्वपूर्ण है कि मूल्यांकन डेटा में हमारे संख्यात्मक विशेषताओं के लिए हमारे प्रशिक्षण डेटा के समान मूल्यों के उदाहरण शामिल हैं, ताकि मूल्यांकन के दौरान नुकसान की सतह का हमारा कवरेज प्रशिक्षण के दौरान लगभग समान हो। श्रेणीबद्ध विशेषताओं के लिए भी यही सच है। अन्यथा, हमारे पास ऐसे प्रशिक्षण मुद्दे हो सकते हैं जिन्हें मूल्यांकन के दौरान पहचाना नहीं गया है, क्योंकि हमने अपने नुकसान की सतह के हिस्से का मूल्यांकन नहीं किया है।
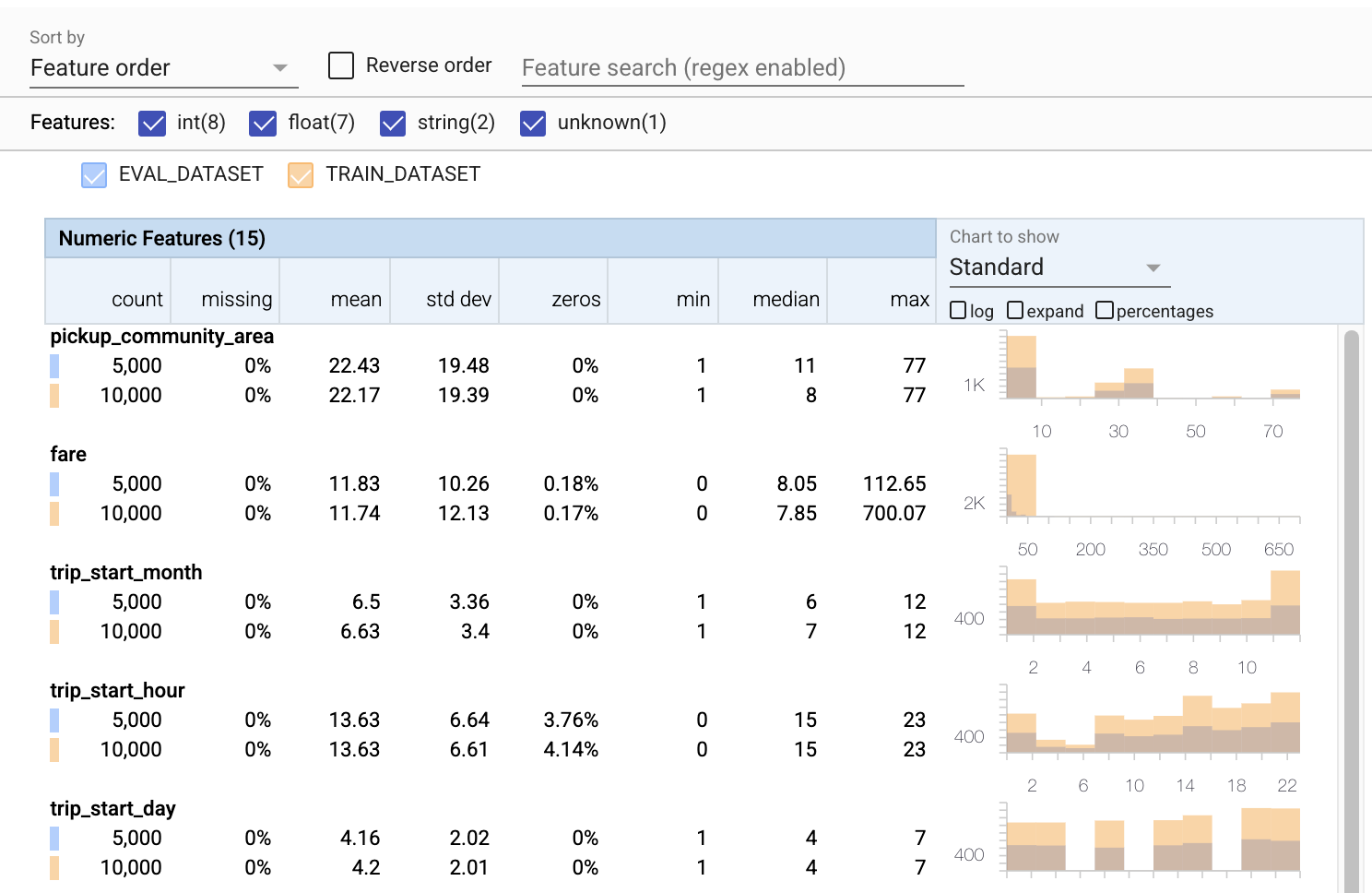
- ध्यान दें कि प्रत्येक सुविधा में अब प्रशिक्षण और मूल्यांकन डेटासेट दोनों के आंकड़े शामिल हैं।
- ध्यान दें कि चार्ट में अब प्रशिक्षण और मूल्यांकन दोनों डेटासेट हैं, जिससे उनकी तुलना करना आसान हो गया है।
- ध्यान दें कि चार्ट में अब एक प्रतिशत दृश्य शामिल है, जिसे लॉग या डिफ़ॉल्ट रैखिक पैमानों के साथ जोड़ा जा सकता है।
- ध्यान दें कि
trip_milesके लिए माध्य और माध्यिका प्रशिक्षण बनाम मूल्यांकन डेटासेट के लिए भिन्न हैं। क्या इससे समस्याएं होंगी? - वाह, प्रशिक्षण बनाम मूल्यांकन डेटासेट के लिए अधिकतम
tipsबहुत भिन्न हैं। क्या इससे समस्याएं होंगी? - न्यूमेरिक फीचर्स चार्ट पर एक्सपैंड पर क्लिक करें और लॉग स्केल चुनें।
trip_secondsसुविधा की समीक्षा करें, और अधिकतम में अंतर देखें। क्या मूल्यांकन में नुकसान की सतह के कुछ हिस्से छूट जाएंगे?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
मूल्यांकन विसंगतियों के लिए जाँच करें
क्या हमारा मूल्यांकन डेटासेट हमारे प्रशिक्षण डेटासेट से स्कीमा से मेल खाता है? यह स्पष्ट विशेषताओं के लिए विशेष रूप से महत्वपूर्ण है, जहां हम स्वीकार्य मूल्यों की सीमा की पहचान करना चाहते हैं।
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
स्कीमा में मूल्यांकन विसंगतियों को ठीक करें
उफ़! ऐसा लगता है कि हमारे मूल्यांकन डेटा में company के लिए कुछ नए मूल्य हैं, जो हमारे प्रशिक्षण डेटा में नहीं थे। हमारे पास payment_type के लिए एक नया मान भी है। इन्हें विसंगतियों के रूप में माना जाना चाहिए, लेकिन हम उनके बारे में क्या करने का निर्णय लेते हैं, यह डेटा के हमारे डोमेन ज्ञान पर निर्भर करता है। यदि कोई विसंगति वास्तव में डेटा त्रुटि का संकेत देती है, तो अंतर्निहित डेटा को ठीक किया जाना चाहिए। अन्यथा, हम eval डेटासेट में मानों को शामिल करने के लिए केवल स्कीमा को अपडेट कर सकते हैं।
जब तक हम अपना मूल्यांकन डेटासेट नहीं बदलते, हम सब कुछ ठीक नहीं कर सकते, लेकिन हम स्कीमा में उन चीजों को ठीक कर सकते हैं जिन्हें हम स्वीकार करने में सहज हैं। इसमें विशेष सुविधाओं के लिए क्या है और क्या विसंगति नहीं है, के बारे में हमारे दृष्टिकोण को शिथिल करना, साथ ही स्पष्ट सुविधाओं के लिए अनुपलब्ध मानों को शामिल करने के लिए हमारे स्कीमा को अपडेट करना शामिल है। TFDV ने हमें यह पता लगाने में सक्षम किया है कि हमें क्या ठीक करना है।
आइए उन सुधारों को अभी करें, और फिर एक बार और समीक्षा करें।
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
अरे, वो देखो! हमने सत्यापित किया कि प्रशिक्षण और मूल्यांकन डेटा अब सुसंगत हैं! धन्यवाद टीएफडीवी;)
स्कीमा वातावरण
हमने इस उदाहरण के लिए एक 'सर्विंग' डेटासेट को भी विभाजित किया है, इसलिए हमें उसे भी जांचना चाहिए। डिफ़ॉल्ट रूप से एक पाइपलाइन में सभी डेटासेट को एक ही स्कीमा का उपयोग करना चाहिए, लेकिन अक्सर अपवाद होते हैं। उदाहरण के लिए, पर्यवेक्षित शिक्षण में हमें अपने डेटासेट में लेबल शामिल करने की आवश्यकता होती है, लेकिन जब हम अनुमान के लिए मॉडल की सेवा करते हैं तो लेबल शामिल नहीं होंगे। कुछ मामलों में मामूली स्कीमा भिन्नताएं पेश करना आवश्यक है।
ऐसी आवश्यकताओं को व्यक्त करने के लिए वातावरण का उपयोग किया जा सकता है। विशेष रूप से, स्कीमा में सुविधाओं को default_environment , in_environment और not_in_environment का उपयोग करके परिवेशों के एक सेट के साथ जोड़ा जा सकता है।
उदाहरण के लिए, इस डेटासेट में tips सुविधा को प्रशिक्षण के लिए लेबल के रूप में शामिल किया गया है, लेकिन यह सेवा डेटा में मौजूद नहीं है। निर्दिष्ट परिवेश के बिना, यह एक विसंगति के रूप में दिखाई देगा।
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
हम नीचे दी गई tips की विशेषता से निपटेंगे। हमारे यात्रा सेकंड में हमारे पास एक INT मान भी है, जहां हमारे स्कीमा को FLOAT की उम्मीद है। हमें उस अंतर से अवगत कराकर, टीएफडीवी प्रशिक्षण और सेवा के लिए डेटा उत्पन्न करने के तरीके में विसंगतियों को उजागर करने में मदद करता है। इस तरह की समस्याओं से अनजान होना बहुत आसान है जब तक कि मॉडल का प्रदर्शन प्रभावित न हो, कभी-कभी विनाशकारी रूप से। यह एक महत्वपूर्ण मुद्दा हो भी सकता है और नहीं भी, लेकिन किसी भी मामले में यह आगे की जांच का कारण होना चाहिए।
इस मामले में, हम INT मानों को FLOATs में सुरक्षित रूप से परिवर्तित कर सकते हैं, इसलिए हम TFDV को इस प्रकार का अनुमान लगाने के लिए हमारे स्कीमा का उपयोग करने के लिए कहना चाहते हैं। चलो अब ऐसा करते हैं।
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
अब हमारे पास केवल tips सुविधा है (जो हमारा लेबल है) एक विसंगति ('कॉलम गिरा') के रूप में दिखाई दे रही है। बेशक हम अपने सर्विंग डेटा में लेबल होने की उम्मीद नहीं करते हैं, तो चलिए TFDV को इसे अनदेखा करने के लिए कहते हैं।
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
बहाव और तिरछा के लिए जाँच करें
यह जाँचने के अलावा कि क्या डेटासेट स्कीमा में निर्धारित अपेक्षाओं के अनुरूप है, TFDV बहाव और तिरछा का पता लगाने के लिए कार्यात्मकता भी प्रदान करता है। TFDV स्कीमा में निर्दिष्ट ड्रिफ्ट/स्क्यू तुलनित्र के आधार पर विभिन्न डेटासेट के आँकड़ों की तुलना करके यह जाँच करता है।
अभिप्राय
ड्रिफ्ट डिटेक्शन श्रेणीबद्ध सुविधाओं के लिए और डेटा के लगातार स्पैन (यानी स्पैन एन और स्पैन एन + 1 के बीच) के बीच समर्थित है, जैसे कि प्रशिक्षण डेटा के विभिन्न दिनों के बीच। हम एल-इन्फिनिटी दूरी के संदर्भ में बहाव व्यक्त करते हैं, और आप थ्रेशोल्ड दूरी निर्धारित कर सकते हैं ताकि जब बहाव स्वीकार्य से अधिक हो तो आपको चेतावनी प्राप्त हो। सही दूरी निर्धारित करना आम तौर पर एक पुनरावृत्ति प्रक्रिया है जिसके लिए डोमेन ज्ञान और प्रयोग की आवश्यकता होती है।
तिरछा
TFDV आपके डेटा में तीन अलग-अलग प्रकार के तिरछापन का पता लगा सकता है - स्कीमा तिरछा, फ़ीचर तिरछा और वितरण तिरछा।
स्कीमा तिरछा
स्कीमा तिरछा तब होता है जब प्रशिक्षण और सेवा डेटा एक ही स्कीमा के अनुरूप नहीं होते हैं। प्रशिक्षण और सेवा डेटा दोनों से एक ही स्कीमा का पालन करने की अपेक्षा की जाती है। दोनों के बीच कोई भी अपेक्षित विचलन (जैसे कि लेबल सुविधा केवल प्रशिक्षण डेटा में मौजूद है लेकिन सेवा में नहीं है) को स्कीमा में परिवेश फ़ील्ड के माध्यम से निर्दिष्ट किया जाना चाहिए।
फ़ीचर तिरछा
फ़ीचर स्क्यू तब होता है जब एक मॉडल जिस फीचर वैल्यू पर ट्रेन करता है, वह फीचर वैल्यू से अलग होता है, जिसे वह सर्विंग टाइम पर देखता है। उदाहरण के लिए, ऐसा तब हो सकता है जब:
- एक डेटा स्रोत जो कुछ सुविधा मान प्रदान करता है, उसे प्रशिक्षण और सेवा समय के बीच संशोधित किया जाता है
- प्रशिक्षण और सेवा के बीच सुविधाओं को उत्पन्न करने के लिए अलग-अलग तर्क हैं। उदाहरण के लिए, यदि आप केवल दो कोड पथों में से किसी एक में कुछ परिवर्तन लागू करते हैं।
वितरण तिरछा
वितरण तिरछा तब होता है जब प्रशिक्षण डेटासेट का वितरण सेवारत डेटासेट के वितरण से काफी भिन्न होता है। वितरण तिरछा के प्रमुख कारणों में से एक प्रशिक्षण डेटासेट उत्पन्न करने के लिए विभिन्न कोड या विभिन्न डेटा स्रोतों का उपयोग कर रहा है। एक अन्य कारण एक दोषपूर्ण नमूना तंत्र है जो प्रशिक्षण के लिए सेवारत डेटा का एक गैर-प्रतिनिधि उप-नमूना चुनता है।
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
इस उदाहरण में हम कुछ बहाव देखते हैं, लेकिन यह हमारे द्वारा निर्धारित सीमा से काफी नीचे है।
स्कीमा को फ्रीज करें
अब जबकि स्कीमा की समीक्षा की गई है और क्यूरेट किया गया है, हम इसकी "जमे हुए" स्थिति को दर्शाने के लिए इसे एक फ़ाइल में संग्रहीत करेंगे।
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
टीएफडीवी का उपयोग कब करें
TFDV को केवल आपकी प्रशिक्षण पाइपलाइन की शुरुआत के लिए लागू करना आसान है, जैसा कि हमने यहां किया था, लेकिन वास्तव में इसके कई उपयोग हैं। यहाँ कुछ और है:
- अनुमान के लिए नए डेटा का सत्यापन यह सुनिश्चित करने के लिए कि हमें अचानक से खराब सुविधाएँ प्राप्त होने शुरू नहीं हुई हैं
- यह सुनिश्चित करने के लिए कि हमारे मॉडल ने निर्णय सतह के उस हिस्से पर प्रशिक्षित किया है, अनुमान के लिए नए डेटा को मान्य करना
- यह सुनिश्चित करने के लिए कि हमने कुछ गलत नहीं किया है, हमारे डेटा को बदलने और फीचर इंजीनियरिंग (शायद TensorFlow Transform का उपयोग करके) करने के बाद सत्यापित करना