
Bu eğitimde, makine öğrenimi (ML) için veri ön işlemeyi uygulamak amacıyla TensorFlow Transform'un ( tf.Transform kitaplığı) nasıl kullanılacağı gösterilir. TensorFlow için tf.Transform kitaplığı, veri ön işleme ardışık düzenleri aracılığıyla hem örnek düzeyinde hem de tam geçişli veri dönüşümlerini tanımlamanıza olanak tanır. Bu işlem hatları Apache Beam ile verimli bir şekilde yürütülür ve model sunulurken olduğu gibi tahmin sırasında da aynı dönüşümleri uygulamak için yan ürünler olarak bir TensorFlow grafiği oluştururlar.
Bu eğitimde , Dataflow'un Apache Beam için çalıştırıcı olarak kullanıldığı uçtan uca bir örnek sağlanmaktadır. BigQuery , Dataflow, Vertex AI ve TensorFlow Keras API'sine aşina olduğunuzu varsayar. Ayrıca Jupyter Notebooks'u kullanma konusunda Vertex AI Workbench gibi bir miktar deneyiminiz olduğunu da varsayar.
Bu eğitimde ayrıca , Makine Öğrenimi için Veri ön işleme: seçenekler ve öneriler bölümünde açıklandığı gibi Google Cloud'daki ön işleme türleri, zorluklar ve seçenekler kavramlarına aşina olduğunuz varsayılmaktadır.
Hedefler
-
tf.Transformkitaplığını kullanarak Apache Beam işlem hattını uygulayın. - İşlem hattını Dataflow'da çalıştırın.
-
tf.Transformkütüphanesini kullanarak TensorFlow modelini uygulayın. - Tahminler için modeli eğitin ve kullanın.
Maliyetler
Bu eğitimde Google Cloud'un aşağıdaki faturalandırılabilir bileşenleri kullanılır:
Tüm gün boyunca her kaynağı kullandığınızı varsayarak, bu öğreticiyi çalıştırmanın maliyetini tahmin etmek için önceden yapılandırılmış fiyatlandırma hesaplayıcıyı kullanın.
Başlamadan önce
Google Cloud konsolundaki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun .
Bulut projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını nasıl kontrol edeceğinizi öğrenin.
Dataflow, Vertex AI ve Notebooks API'lerini etkinleştirin. API'leri etkinleştirin
Bu çözüm için Jupyter not defterleri
Aşağıdaki Jupyter not defterleri uygulama örneğini göstermektedir:
- Not Defteri 1, veri ön işlemeyi kapsar. Ayrıntılar daha sonra Apache Beam boru hattının uygulanması bölümünde verilmektedir.
- Not Defteri 2 model eğitimini kapsar. Ayrıntılar daha sonra TensorFlow modelinin uygulanması bölümünde verilmektedir.
Aşağıdaki bölümlerde bu not defterlerini kopyalayacak ve ardından uygulama örneğinin nasıl çalıştığını öğrenmek için not defterlerini çalıştıracaksınız.
Kullanıcı tarafından yönetilen not defterleri örneğini başlatın
Google Cloud konsolunda Vertex AI Workbench sayfasına gidin.
Kullanıcı tarafından yönetilen not defterleri sekmesinde +Yeni not defteri'ni tıklayın.
Bulut sunucusu türü olarak GPU'suz TensorFlow Enterprise 2.8'i (LTS ile) seçin.
Oluştur'u tıklayın.
Not defterini oluşturduktan sonra JupyterLab proxy'sinin başlatılmasının tamamlanmasını bekleyin. Hazır olduğunda not defteri adının yanında JupyterLab'ı Aç görüntülenir.
Not defterini klonla
Kullanıcı tarafından yönetilen not defterleri sekmesinde , not defteri adının yanında JupyterLab'ı Aç'a tıklayın. JupyterLab arayüzü yeni bir sekmede açılır.
JupyterLab'da Derleme Önerilir iletişim kutusu görüntülenirse, önerilen derlemeyi reddetmek için İptal'e tıklayın.
Başlatıcı sekmesinde Terminal'e tıklayın.
Terminal penceresinde not defterini kopyalayın:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
Apache Beam ardışık düzenini uygulama
Bu bölüm ve sonraki bölüm Veri Akışında işlem hattını çalıştırma Not Defteri 1 için genel bakış ve bağlam sağlar. Not defteri, verileri ön işlemek için tf.Transform kitaplığının nasıl kullanılacağını açıklayan pratik bir örnek sağlar. Bu örnekte, çeşitli girdilere dayalı olarak bebek ağırlıklarını tahmin etmek için kullanılan Natality veri kümesi kullanılmaktadır. Veriler BigQuery'deki genel doğum tablosunda depolanır.
Not Defteri 1'i Çalıştır
JupyterLab arayüzünde Dosya > Yoldan aç öğesine tıklayın ve ardından aşağıdaki yolu girin:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbDüzenle > Tüm çıktıları temizle'yi tıklayın.
Gerekli paketleri yükle bölümünde,
pip install apache-beamkomutunu çalıştırmak için ilk hücreyi çalıştırın.Çıktının son kısmı şu şekildedir:
Successfully installed ...Çıktıdaki bağımlılık hatalarını göz ardı edebilirsiniz. Henüz çekirdeği yeniden başlatmanıza gerek yok.
pip install tensorflow-transformkomutunu çalıştırmak için ikinci hücreyi çalıştırın. Çıktının son kısmı şu şekildedir:Successfully installed ... Note: you may need to restart the kernel to use updated packages.Çıktıdaki bağımlılık hatalarını göz ardı edebilirsiniz.
Çekirdek > Çekirdeği Yeniden Başlat öğesine tıklayın.
Yüklü paketleri onaylayın ve paketleri Dataflow kapsayıcılarına yüklemek için setup.py oluşturun bölümlerindeki hücreleri yürütün.
Genel bayrakları ayarla bölümünde,
PROJECTveBUCKETyanında,your-projectBulut proje kimliğinizle değiştirin ve ardından hücreyi yürütün.Geriye kalan tüm hücreleri not defterindeki son hücre aracılığıyla yürütün. Her hücrede ne yapılacağı hakkında bilgi için not defterindeki talimatlara bakın.
Boru hattına genel bakış
Not defteri örneğinde Dataflow, verileri hazırlamak ve dönüşüm yapıtlarını üretmek için tf.Transform işlem hattını uygun ölçekte çalıştırır. Bu belgenin sonraki bölümlerinde işlem hattındaki her adımı gerçekleştiren işlevler açıklanmaktadır. Genel boru hattı adımları aşağıdaki gibidir:
- BigQuery'den eğitim verilerini okuyun.
-
tf.Transformkitaplığını kullanarak eğitim verilerini analiz edin ve dönüştürün. - Dönüştürülen eğitim verilerini Cloud Storage'a TFRecord formatında yazın.
- BigQuery'den değerlendirme verilerini okuyun.
- 2. adımda oluşturulan
transform_fngrafiğini kullanarak değerlendirme verilerini dönüştürün. - Dönüştürülen eğitim verilerini Cloud Storage'a TFRecord formatında yazın.
- Daha sonra modeli oluşturmak ve dışa aktarmak için kullanılacak dönüşüm yapıtlarını Cloud Storage'a yazın.
Aşağıdaki örnek, genel ardışık düzen için Python kodunu gösterir. Aşağıdaki bölümlerde her adıma ilişkin açıklamalar ve kod listeleri verilmektedir.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
BigQuery'den ham eğitim verilerini okuyun
İlk adım, read_from_bq işlevini kullanarak BigQuery'den ham eğitim verilerini okumaktır. Bu işlev, BigQuery'den çıkarılan bir raw_dataset nesnesini döndürür. Bir data_size değeri iletirsiniz ve train veya eval step değerini iletirsiniz. BigQuery kaynak sorgusu, aşağıdaki örnekte gösterildiği gibi get_source_query işlevi kullanılarak oluşturulur:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
tf.Transform ön işlemesini gerçekleştirmeden önce, Harita, Filtre, Grup ve Pencere işleme dahil olmak üzere tipik Apache Beam tabanlı işlemleri gerçekleştirmeniz gerekebilir. Örnekte kod, BigQuery'den okunan kayıtları beam.Map(prep_bq_row) yöntemini kullanarak temizler; burada prep_bq_row özel bir işlevdir. Bu özel işlev, kategorik bir özelliğin sayısal kodunu insan tarafından okunabilen etiketlere dönüştürür.
Ayrıca BigQuery'den çıkarılan raw_data nesnesini analiz etmek ve dönüştürmek amacıyla tf.Transform kitaplığını kullanmak için raw_data ve raw_metadata nesnelerinden oluşan bir demet olan bir raw_dataset nesnesi oluşturmanız gerekir. raw_metadata nesnesi, create_raw_metadata işlevi kullanılarak aşağıdaki şekilde oluşturulur:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
Not defterinde bu yöntemi tanımlayan hücrenin hemen ardından gelen hücreyi çalıştırdığınızda raw_metadata.schema nesnesinin içeriği görüntülenir. Aşağıdaki sütunları içerir:
-
gestation_weeks(tür:FLOAT) -
is_male(tür:BYTES) -
mother_age(tür:FLOAT) -
mother_race(tür:BYTES) -
plurality(tür:FLOAT) -
weight_pounds(tür:FLOAT)
Ham eğitim verilerini dönüştürün
ML'ye hazırlamak için eğitim verilerinin girdi ham özelliklerine tipik ön işleme dönüşümleri uygulamak istediğinizi düşünün. Bu dönüşümler, aşağıdaki tabloda gösterildiği gibi hem tam geçişli hem de örnek düzeyindeki işlemleri içerir:
| Giriş özelliği | Dönüşüm | İstatistikler gerekli | Tip | Çıkış özelliği |
|---|---|---|---|---|
weight_pound | Hiçbiri | Hiçbiri | Yok | weight_pound |
mother_age | Normalleştir | demek, var | Tam geçiş | mother_age_normalized |
mother_age | Eşit boyutlu paketleme | yüzdelik dilimler | Tam geçiş | mother_age_bucketized |
mother_age | Günlüğü hesapla | Hiçbiri | Örnek düzeyinde | mother_age_log |
plurality | Tek veya çoklu bebek olup olmadığını belirtin | Hiçbiri | Örnek düzeyinde | is_multiple |
is_multiple | Nominal değerleri sayısal indekse dönüştürün | kelime bilgisi | Tam geçiş | is_multiple_index |
gestation_weeks | 0 ile 1 arasında ölçeklendirme | minimum, maksimum | Tam geçiş | gestation_weeks_scaled |
mother_race | Nominal değerleri sayısal indekse dönüştürün | kelime bilgisi | Tam geçiş | mother_race_index |
is_male | Nominal değerleri sayısal indekse dönüştürün | kelime bilgisi | Tam geçiş | is_male_index |
Bu dönüşümler, bir tensör sözlüğü ( input_features ) bekleyen ve işlenmiş özelliklerin bir sözlüğünü ( output_features ) döndüren bir preprocess_fn işlevinde uygulanır.
Aşağıdaki kod, tf.Transform tam geçişli dönüşüm API'lerini ( tft. ile öneklenmiştir) ve TensorFlow ( tf. ile öneklenmiştir) örnek düzeyindeki işlemleri kullanarak preprocess_fn işlevinin uygulanmasını gösterir:
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
tf.Transform çerçevesi, önceki örnekte yer alan dönüşümlere ek olarak aşağıdaki tabloda listelenenler de dahil olmak üzere başka dönüşümlere de sahiptir:
| Dönüşüm | Şunlar için geçerlidir: | Tanım |
|---|---|---|
scale_by_min_max | Sayısal özellikler | Sayısal bir sütunu [ output_min , output_max ] aralığına ölçeklendirir |
scale_to_0_1 | Sayısal özellikler | Giriş sütununun [ 0 , 1 ] aralığına sahip olacak şekilde ölçeklendirildiği bir sütunu döndürür |
scale_to_z_score | Sayısal özellikler | Ortalaması 0 ve varyansı 1 olan standartlaştırılmış bir sütunu döndürür |
tfidf | Metin özellikleri | X'teki terimleri terim sıklığına * ters belge sıklığına eşler |
compute_and_apply_vocabulary | Kategorik özellikler | Kategorik bir özellik için bir sözcük dağarcığı oluşturur ve bu sözcük dağarcığını kullanarak onu bir tamsayıya eşler |
ngrams | Metin özellikleri | N-gramlardan oluşan bir SparseTensor oluşturur |
hash_strings | Kategorik özellikler | Dizeleri kovalara hashler |
pca | Sayısal özellikler | Önyargılı kovaryans kullanarak veri kümesindeki PCA'yı hesaplar |
bucketize | Sayısal özellikler | Her girişe bir grup dizini atanmış, eşit boyutlu (niceliklere dayalı) gruplara ayrılmış bir sütun döndürür |
preprocess_fn işlevinde uygulanan dönüşümleri ardışık düzenin önceki adımında üretilen raw_train_dataset nesnesine uygulamak için AnalyzeAndTransformDataset yöntemini kullanırsınız. Bu yöntem girdi olarak raw_dataset nesnesini bekler, preprocess_fn işlevini uygular ve transformed_dataset nesnesini ve transform_fn grafiğini üretir. Aşağıdaki kod bu işlemi göstermektedir:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
Dönüşümler ham verilere iki aşamada uygulanır: analiz aşaması ve dönüşüm aşaması. Bu belgenin ilerleyen kısımlarında yer alan Şekil 3, AnalyzeAndTransformDataset yönteminin, AnalyzeDataset yöntemine ve TransformDataset yöntemine nasıl ayrıştırıldığını gösterir.
Analiz aşaması
Analiz aşamasında, dönüşümler için gerekli istatistikleri hesaplamak amacıyla ham eğitim verileri tam geçişli bir süreçte analiz edilir. Bu, ortalamanın, varyansın, minimumun, maksimumun, niceliklerin ve kelime dağarcığının hesaplanmasını içerir. Analiz süreci ham bir veri kümesi (ham veriler artı ham meta veriler) bekler ve iki çıktı üretir:
-
transform_fn: analiz aşamasından hesaplanan istatistikleri ve örnek düzeyinde işlemler olarak dönüştürme mantığını (istatistikleri kullanan) içeren bir TensorFlow grafiği. Daha sonra Grafiği kaydetme bölümünde tartışıldığı gibi,transform_fngrafiği, modelserving_fnişlevine eklenmek üzere kaydedilir. Bu, aynı dönüşümün çevrimiçi tahmin veri noktalarına uygulanmasını mümkün kılar. -
transform_metadata: dönüşümden sonra verilerin beklenen şemasını açıklayan bir nesne.
Analiz aşaması aşağıdaki diyagramda gösterilmektedir, şekil 1:

tf.Transform analiz aşaması. tf.Transform çözümleyicileri min , max , sum , size , mean , var , covariance , quantiles , vocabulary ve pca içerir.
Dönüşüm aşaması
Dönüştürme aşamasında, analiz aşaması tarafından üretilen transform_fn grafiği, dönüştürülmüş eğitim verilerini üretmek amacıyla ham eğitim verilerini örnek düzeyinde bir süreçte dönüştürmek için kullanılır. Dönüştürülen eğitim verileri, transformed_train_dataset kümesi veri kümesini üretmek için dönüştürülmüş meta verilerle (analiz aşaması tarafından üretilen) eşleştirilir.
Dönüşüm aşaması aşağıdaki diyagramda gösterilmektedir, şekil 2:

tf.Transform dönüşüm aşaması. Özellikleri önceden işlemek için, preprocess_fn işlevinin uygulanmasında gerekli tensorflow_transform dönüşümlerini (kodda tft olarak içe aktarılan) çağırırsınız. Örneğin, tft.scale_to_z_score işlemlerini çağırdığınızda, tf.Transform kütüphanesi bu işlev çağrısını ortalama ve varyans analizörlerine çevirir, analiz aşamasında istatistikleri hesaplar ve daha sonra bu istatistikleri dönüşüm aşamasında sayısal özelliği normalleştirmek için uygular. Bunların tümü, AnalyzeAndTransformDataset(preprocess_fn) yöntemi çağrılarak otomatik olarak yapılır.
Bu çağrı tarafından üretilen transformed_metadata.schema varlığı aşağıdaki sütunları içerir:
-
gestation_weeks_scaled(tür:FLOAT) -
is_male_index(tür:INT, is_categorical:True) -
is_multiple_index(tür:INT, is_categorical:True) -
mother_age_bucketized(tür:INT, is_categorical:True) -
mother_age_log(tür:FLOAT) -
mother_age_normalized(tür:FLOAT) -
mother_race_index(tür:INT, is_categorical:True) -
weight_pounds(tür:FLOAT)
Bu serinin ilk bölümündeki Ön İşleme operasyonlarında açıklandığı gibi özellik dönüşümü, kategorik özellikleri sayısal bir gösterime dönüştürür. Dönüşüm sonrasında kategorik özellikler tamsayı değerlerle temsil edilir. transformed_metadata.schema varlığında, INT türü sütunlar için is_categorical bayrağı, sütunun kategorik bir özelliği mi yoksa gerçek sayısal bir özelliği mi temsil ettiğini gösterir.
Dönüştürülen eğitim verilerini yazın
Eğitim verileri, analiz ve dönüştürme aşamaları boyunca preprocess_fn işleviyle önceden işlendikten sonra, verileri TensorFlow modelini eğitmek için kullanılacak bir havuza yazabilirsiniz. Apache Beam ardışık düzenini Dataflow kullanarak çalıştırdığınızda havuz Cloud Storage'dır. Aksi takdirde, havuz yerel disktir. Verileri sabit genişlikte formatlanmış dosyalardan oluşan bir CSV dosyası olarak yazabilseniz de TensorFlow veri kümeleri için önerilen dosya formatı TFRecord formatıdır. Bu, tf.train.Example protokol arabellek mesajlarından oluşan basit, kayıt odaklı bir ikili formattır.
Her tf.train.Example kaydı bir veya daha fazla özellik içerir. Bunlar, eğitim için modele beslendiklerinde tensörlere dönüştürülür. Aşağıdaki kod, dönüştürülen veri kümesini belirtilen konumdaki TFRecord dosyalarına yazar:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
Değerlendirme verilerini okuyun, dönüştürün ve yazın
Eğitim verilerini dönüştürüp transform_fn grafiğini oluşturduktan sonra bunu değerlendirme verilerini dönüştürmek için kullanabilirsiniz. Öncelikle BigQuery'den ham eğitim verilerini okuma bölümünde açıklanan read_from_bq işlevini kullanarak ve step parametresi için bir eval değeri ileterek BigQuery'den değerlendirme verilerini okuyup temizlersiniz. Daha sonra, ham değerlendirme veri kümesini ( raw_dataset ) beklenen dönüştürülmüş biçime ( transformed_dataset ) dönüştürmek için aşağıdaki kodu kullanırsınız:
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
Değerlendirme verilerini dönüştürdüğünüzde, hem transform_fn grafiğindeki mantığı hem de eğitim verilerindeki analiz aşamasından hesaplanan istatistikleri kullanarak yalnızca örnek düzeyindeki işlemler uygulanır. Başka bir deyişle, değerlendirme verilerindeki sayısal özelliklerin z-puanı normalleştirmesinin ortalaması ve varyansı gibi yeni istatistikleri hesaplamak için değerlendirme verilerini tam geçişli bir şekilde analiz etmezsiniz. Bunun yerine, değerlendirme verilerini örnek düzeyinde dönüştürmek için eğitim verilerinden hesaplanan istatistikleri kullanırsınız.
Bu nedenle, istatistikleri hesaplamak ve verileri dönüştürmek için eğitim verileri bağlamında AnalyzeAndTransform yöntemini kullanırsınız. Aynı zamanda, değerlendirme verilerinin dönüştürülmesi bağlamında TransformDataset yöntemini kullanarak yalnızca eğitim verileri üzerinde hesaplanan istatistikleri kullanarak verileri dönüştürürsünüz.
Daha sonra, eğitim süreci sırasında TensorFlow modelini değerlendirmek için verileri bir havuza (çalıştırıcıya bağlı olarak Cloud Storage veya yerel disk) TFRecord formatında yazarsınız. Bunu yapmak için Dönüştürülen eğitim verilerini yazma bölümünde açıklanan write_tfrecords işlevini kullanırsınız. Aşağıdaki diyagram, şekil 3, eğitim verilerinin analiz aşamasında üretilen transform_fn grafiğinin, değerlendirme verilerini dönüştürmek için nasıl kullanıldığını gösterir.

transform_fn grafiğini kullanarak değerlendirme verilerini dönüştürme.Grafiği kaydet
tf.Transform ön işleme hattındaki son adım, analiz aşaması tarafından üretilen transform_fn grafiğini içeren yapıtları eğitim verileri üzerinde depolamaktır. Yapıtların saklanmasına ilişkin kod aşağıdaki write_transform_artefacts işlevinde gösterilmektedir:
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
Bu yapılar daha sonra model eğitimi ve sunum amacıyla dışa aktarma için kullanılacaktır. Bir sonraki bölümde gösterildiği gibi aşağıdaki eserler de üretilir:
-
saved_model.pb: ham veri noktalarını dönüştürülmüş formata dönüştürmek için model hizmet arayüzüne eklenecek olan dönüştürme mantığını (transform_fngrafiği) içeren TensorFlow grafiğini temsil eder. -
variables: eğitim verilerinin analiz aşaması sırasında hesaplanan istatistikleri içerir vesaved_model.pbyapıtındaki dönüştürme mantığında kullanılır. -
assets: girdi ham nominal değerini sayısal bir dizine dönüştürmek için sunum sırasında kullanılacak,compute_and_apply_vocabularyyöntemiyle işlenen her kategorik özellik için bir tane olmak üzere sözcük dosyaları içerir. -
transformed_metadata: dönüştürülmüş verilerin şemasını açıklayanschema.jsondosyasını içeren bir dizin.
İşlem hattını Dataflow'da çalıştırın
tf.Transform işlem hattını tanımladıktan sonra işlem hattını Dataflow'u kullanarak çalıştırırsınız. Aşağıdaki diyagram (şekil 4), örnekte açıklanan tf.Transform işlem hattının Veri Akışı yürütme grafiğini gösterir.
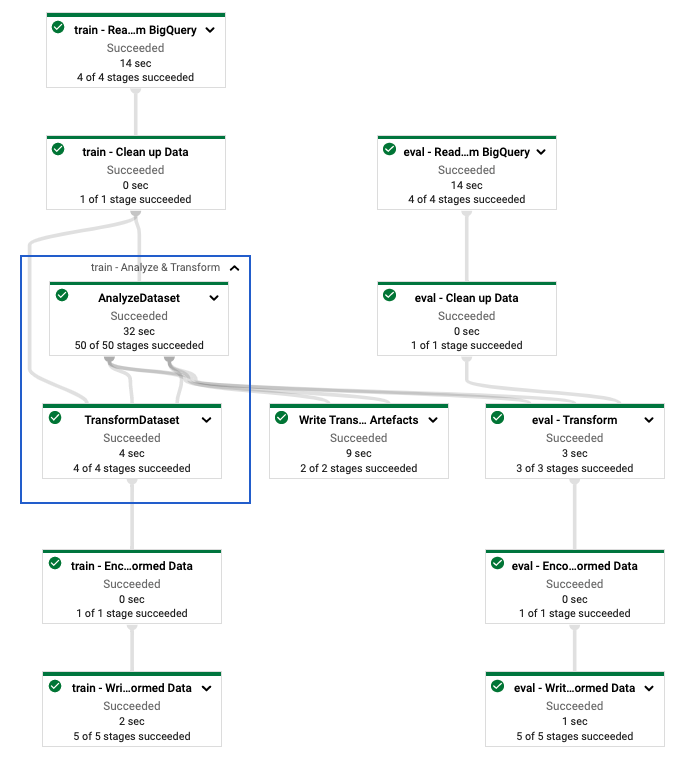
tf.Transform hattının veri akışı yürütme grafiği. Eğitim ve değerlendirme verilerini ön işlemek için Dataflow ardışık düzenini yürüttükten sonra not defterindeki son hücreyi çalıştırarak Bulut Depolama'da üretilen nesneleri keşfedebilirsiniz. Bu bölümdeki kod parçacıkları sonuçları gösterir; burada YOUR_BUCKET_NAME , Cloud Storage paketinizin adıdır.
TFRecord formatında dönüştürülen eğitim ve değerlendirme verileri aşağıdaki konumda saklanır:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
Dönüşüm eserleri aşağıdaki konumda üretilir:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
Aşağıdaki liste, üretilen veri nesnelerini ve yapıtları gösteren işlem hattının çıktısıdır:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
TensorFlow modelini uygulayın
Bu bölüm ve sonraki bölüm olan Tahminler için modeli eğitme ve kullanma , Not Defteri 2 için genel bakış ve bağlam sağlar. Dizüstü bilgisayar, bebek ağırlıklarını tahmin etmek için örnek bir ML modeli sağlar. Bu örnekte Keras API kullanılarak bir TensorFlow modeli uygulanmıştır. Model, daha önce açıklanan tf.Transform ön işleme ardışık düzeni tarafından üretilen verileri ve yapıtları kullanır.
Not Defteri 2'yi Çalıştır
JupyterLab arayüzünde Dosya > Yoldan aç öğesine tıklayın ve ardından aşağıdaki yolu girin:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbDüzenle > Tüm çıktıları temizle'yi tıklayın.
Gerekli paketleri yükle bölümünde,
pip install tensorflow-transformkomutunu çalıştırmak için ilk hücreyi çalıştırın.Çıktının son kısmı şu şekildedir:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.Çıktıdaki bağımlılık hatalarını göz ardı edebilirsiniz.
Çekirdek menüsünde Çekirdeği Yeniden Başlat öğesini seçin.
Yüklü paketleri onaylayın ve paketleri Dataflow kapsayıcılarına yüklemek için setup.py oluşturun bölümlerindeki hücreleri yürütün.
Genel bayrakları ayarla bölümünde,
PROJECTveBUCKETyanında,your-projectBulut proje kimliğinizle değiştirin ve ardından hücreyi yürütün.Geriye kalan tüm hücreleri not defterindeki son hücre aracılığıyla yürütün. Her hücrede ne yapılacağı hakkında bilgi için not defterindeki talimatlara bakın.
Model oluşturmaya genel bakış
Model oluşturma adımları aşağıdaki gibidir:
-
transformed_metadatadizininde depolanan şema bilgilerini kullanarak özellik sütunları oluşturun. - Özellik sütunlarını modele girdi olarak kullanarak Keras API ile geniş ve derin modeli oluşturun.
- Dönüşüm yapıtlarını kullanarak eğitim ve değerlendirme verilerini okumak ve ayrıştırmak için
tfrecords_input_fnişlevini oluşturun. - Modeli eğitin ve değerlendirin.
-
transform_fngrafiğinin eklendiği birserving_fnişlevi tanımlayarak eğitilen modeli dışarı aktarın. - Dışa aktarılan modeli,
saved_model_cliaracını kullanarak inceleyin. - Tahmin için dışa aktarılan modeli kullanın.
Bu belge modelin nasıl oluşturulacağını açıklamadığından modelin nasıl oluşturulduğunu veya eğitildiğini ayrıntılı olarak ele almaz. Ancak aşağıdaki bölümlerde, tf.Transform işlemi tarafından üretilen transform_metadata dizininde saklanan bilgilerin, modelin özellik sütunlarını oluşturmak için nasıl kullanıldığı gösterilmektedir. Belge ayrıca, model sunum için dışa aktarıldığında, yine tf.Transform işlemi tarafından üretilen transform_fn grafiğinin, serving_fn işlevinde nasıl kullanıldığını da gösterir.
Model eğitiminde oluşturulan dönüşüm yapıtlarını kullanın
TensorFlow modelini eğitirken, önceki veri işleme adımında üretilen dönüştürülmüş train ve eval nesnelerini kullanırsınız. Bu nesneler TFRecord formatında parçalanmış dosyalar olarak depolanır. Önceki adımda oluşturulan transformed_metadata dizinindeki şema bilgileri, eğitim ve değerlendirme için modele beslenmek üzere verilerin ( tf.train.Example nesneleri) ayrıştırılmasında faydalı olabilir.
Verileri ayrıştır
Modeli eğitim ve değerlendirme verileriyle beslemek için TFRecord formatındaki dosyaları okuduğunuz için, bir özellikler sözlüğü (tensörler) oluşturmak üzere dosyalardaki her tf.train.Example nesnesini ayrıştırmanız gerekir. Bu, model eğitimi ve değerlendirme arayüzü görevi gören özellik sütunları kullanılarak özelliklerin model giriş katmanına eşlenmesini sağlar. Verileri ayrıştırmak için önceki adımda oluşturulan yapıtlardan oluşturulan TFTransformOutput nesnesini kullanırsınız:
Grafiği kaydetme bölümünde açıklandığı gibi, önceki ön işleme adımında oluşturulan ve kaydedilen yapıtlardan bir
TFTransformOutputnesnesi oluşturun:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)TFTransformOutputnesnesinden birfeature_specnesnesini çıkarın:tf_transform_output.transformed_feature_spec()tf.train.Examplenesnesinde bulunan özellikleritfrecords_input_fnişlevinde olduğu gibi belirtmek içinfeature_specnesnesini kullanın:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
Özellik sütunlarını oluşturun
İşlem hattı, eğitim ve değerlendirme için model tarafından beklenen dönüştürülmüş verilerin şemasını açıklayan transformed_metadata dizininde şema bilgilerini üretir. Şema, aşağıdaki gibi özellik adını ve veri türünü içerir:
-
gestation_weeks_scaled(tür:FLOAT) -
is_male_index(tür:INT, is_categorical:True) -
is_multiple_index(tür:INT, is_categorical:True) -
mother_age_bucketized(tür:INT, is_categorical:True) -
mother_age_log(tür:FLOAT) -
mother_age_normalized(tür:FLOAT) -
mother_race_index(tür:INT, is_categorical:True) -
weight_pounds(tür:FLOAT)
Bu bilgiyi görmek için aşağıdaki komutları kullanın:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
Aşağıdaki kod, özellik sütunlarını oluşturmak için özellik adını nasıl kullandığınızı gösterir:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
Kod, sayısal özellikler için bir tf.feature_column.numeric_column sütunu ve kategorik özellikler için bir tf.feature_column.categorical_column_with_identity sütunu oluşturur.
Ayrıca bu serinin ilk bölümünde Seçenek C: TensorFlow'da açıklandığı gibi genişletilmiş özellik sütunları da oluşturabilirsiniz. Bu seri için kullanılan örnekte, mother_race_X_mother_age_bucketized adlı yeni bir özellik, tf.feature_column.crossed_column özellik sütununu kullanarak mother_race ve mother_age_bucketized özelliklerinin çaprazlanmasıyla oluşturulur. Bu çapraz özelliğin düşük boyutlu, yoğun temsili, tf.feature_column.embedding_column özellik sütunu kullanılarak oluşturulur.
Aşağıdaki diyagram, şekil 5, dönüştürülmüş verileri ve dönüştürülmüş meta verilerin TensorFlow modelini tanımlamak ve eğitmek için nasıl kullanıldığını gösterir:

Tahmini sunmak için modeli dışa aktarın
TensorFlow modelini Keras API ile eğittikten sonra eğitilen modeli bir SavedModel nesnesi olarak dışarı aktarırsınız, böylece tahmin için yeni veri noktaları sunabilir. Modeli dışa aktardığınızda arayüzünü, yani sunum sırasında beklenen giriş özellikleri şemasını tanımlamanız gerekir. Bu giriş özellikleri şeması, aşağıdaki kodda gösterildiği gibi serving_fn işlevinde tanımlanmıştır:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
Sunum sırasında model, veri noktalarının ham formda olmasını (yani dönüşümlerden önceki ham özelliklerin) bekler. Bu nedenle, serving_fn işlevi ham özellikleri alır ve bunları Python sözlüğü olarak bir features nesnesinde saklar. Ancak daha önce tartışıldığı gibi eğitilen model, dönüştürülmüş şemadaki veri noktalarını bekler. Ham özellikleri, model arayüzünün beklediği transformed_features nesnelerine dönüştürmek için, kaydedilen transform_fn grafiğini features nesnesine aşağıdaki adımlarla uygularsınız:
Önceki ön işleme adımında oluşturulan ve kaydedilen yapıtlardan
TFTransformOutputnesnesini oluşturun:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)TFTransformOutputnesnesinden birTransformFeaturesLayernesnesi oluşturun:model.tft_layer = tf_transform_output.transform_features_layer()TransformFeaturesLayernesnesini kullanaraktransform_fngrafiğini uygulayın:transformed_features = model.tft_layer(features)
Aşağıdaki diyagram (Şekil 6), bir modeli sunum için dışa aktarmanın son adımını göstermektedir:

transform_fn grafiği eklenmiş olarak sunum için modelin dışa aktarılması. Tahminler için modeli eğitin ve kullanın
Not defterinin hücrelerini çalıştırarak modeli yerel olarak eğitebilirsiniz. Vertex AI Training'i kullanarak kodu nasıl paketleyeceğinize ve modelinizi geniş ölçekte nasıl eğiteceğinize ilişkin örnekler için Google Cloud cloudml-samples GitHub deposundaki örneklere ve kılavuzlara bakın.
Dışa aktarılan SavedModel nesnesini, saved_model_cli aracını kullanarak incelediğinizde, aşağıdaki örnekte gösterildiği gibi, imza tanımı signature_def inputs öğelerinin ham özellikleri içerdiğini görürsünüz:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
Dizüstü bilgisayarın geri kalan hücreleri, dışa aktarılan modelin yerel bir tahmin için nasıl kullanılacağını ve modelin Vertex AI Prediction kullanılarak bir mikro hizmet olarak nasıl dağıtılacağını gösterir. Her iki durumda da giriş (örnek) veri noktasının ham şemada olduğunu vurgulamak önemlidir.
Temizlemek
Bu eğitimde kullanılan kaynaklar için Google Cloud hesabınıza ek ücret yansıtılmasını önlemek amacıyla kaynakları içeren projeyi silin.
Projeyi sil
Google Cloud konsolunda Kaynakları yönet sayfasına gidin.
Proje listesinde silmek istediğiniz projeyi seçin ve ardından Sil öğesine tıklayın.
İletişim kutusunda proje kimliğini yazın ve ardından projeyi silmek için Kapat'a tıklayın.
Sırada ne var
- Google Cloud'da makine öğrenimine yönelik veri ön işleme kavramları, zorlukları ve seçenekleri hakkında bilgi edinmek için bu serinin ilk makalesi olan Makine Öğrenimi için Veri ön işleme: seçenekler ve öneriler'e bakın.
- Dataflow'da bir tf.Transform işlem hattının nasıl uygulanacağı, paketleneceği ve çalıştırılacağı hakkında daha fazla bilgi için Census Veri Kümesiyle geliri tahmin etme örneğine bakın.
- Google Cloud'da TensorFlow ile ML'de Coursera uzmanlığını edinin.
- ML Kuralları'nda makine öğrenimi mühendisliğine yönelik en iyi uygulamalar hakkında bilgi edinin.
- Daha fazla referans mimari, diyagram ve en iyi uygulama için Bulut Mimarisi Merkezi'ni keşfedin.