
|
|
|
 View source on GitHub
View source on GitHub
|
|
このノートブックでは、スペイン語から英語への翻訳を行う Sequence to Sequence (seq2seq) モデルを訓練します。このチュートリアルは、 Sequence to Sequence モデルの知識があることを前提にした上級編のサンプルです。
このノートブックのモデルを訓練すると、"¿todavia estan en casa?" のようなスペイン語の文を入力して、英訳: "are you still at home?" を得ることができます。
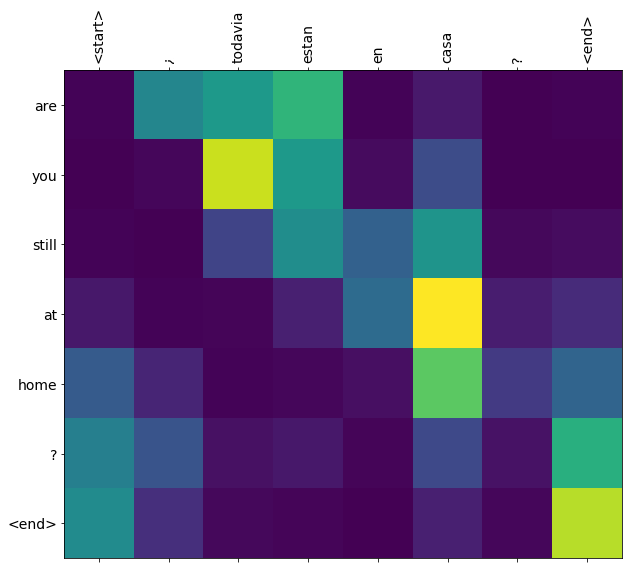
この翻訳品質はおもちゃとしてはそれなりのものですが、生成されたアテンションの図表の方が面白いかもしれません。これは、翻訳時にモデルが入力文のどの部分に注目しているかを表しています。
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
from sklearn.model_selection import train_test_split
import unicodedata
import re
import numpy as np
import os
import io
import time
2022-12-14 23:10:12.430372: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 23:10:12.430471: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 23:10:12.430481: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
データセットのダウンロードと準備
ここでは、http://www.manythings.org/anki/ で提供されている言語データセットを使用します。このデータセットには、次のような書式の言語翻訳ペアが含まれています。
May I borrow this book? ¿Puedo tomar prestado este libro?
さまざまな言語が用意されていますが、ここでは英語ースペイン語のデータセットを使用します。利便性を考えてこのデータセットは Google Cloud 上に用意してありますが、ご自分でダウンロードすることも可能です。データセットをダウンロードしたあと、データを準備するために下記のようないくつかの手順を実行します。
- それぞれの文ごとに、開始 と 終了 のトークンを付加する
- 特殊文字を除去して文をきれいにする
- 単語インデックスと逆単語インデックス(単語 → id と id → 単語のマッピングを行うディクショナリ)を作成する
- 最大長にあわせて各文をパディングする
# ファイルのダウンロード
path_to_zip = tf.keras.utils.get_file(
'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
extract=True)
path_to_file = os.path.dirname(path_to_zip)+"/spa-eng/spa.txt"
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip 2638744/2638744 [==============================] - 0s 0us/step
# ユニコードファイルを ascii に変換
def unicode_to_ascii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
def preprocess_sentence(w):
w = unicode_to_ascii(w.lower().strip())
# 単語とそのあとの句読点の間にスペースを挿入
# 例: "he is a boy." => "he is a boy ."
# 参照:- https://stackoverflow.com/questions/3645931/python-padding-punctuation-with-white-spaces-keeping-punctuation
w = re.sub(r"([?.!,¿])", r" \1 ", w)
w = re.sub(r'[" "]+', " ", w)
# (a-z, A-Z, ".", "?", "!", ",") 以外の全ての文字をスペースに置き換え
w = re.sub(r"[^a-zA-Z?.!,¿]+", " ", w)
w = w.rstrip().strip()
# 文の開始と終了のトークンを付加
# モデルが予測をいつ開始し、いつ終了すれば良いかを知らせるため
w = '<start> ' + w + ' <end>'
return w
en_sentence = u"May I borrow this book?"
sp_sentence = u"¿Puedo tomar prestado este libro?"
print(preprocess_sentence(en_sentence))
print(preprocess_sentence(sp_sentence).encode('utf-8'))
<start> may i borrow this book ? <end> b'<start> \xc2\xbf puedo tomar prestado este libro ? <end>'
# 1. アクセント記号を除去
# 2. 文をクリーニング
# 3. [ENGLISH, SPANISH] の形で単語のペアを返す
def create_dataset(path, num_examples):
lines = io.open(path, encoding='UTF-8').read().strip().split('\n')
word_pairs = [[preprocess_sentence(w) for w in l.split('\t')] for l in lines[:num_examples]]
return zip(*word_pairs)
en, sp = create_dataset(path_to_file, None)
print(en[-1])
print(sp[-1])
<start> if you want to sound like a native speaker , you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo . <end> <start> si quieres sonar como un hablante nativo , debes estar dispuesto a practicar diciendo la misma frase una y otra vez de la misma manera en que un musico de banjo practica el mismo fraseo una y otra vez hasta que lo puedan tocar correctamente y en el tiempo esperado . <end>
def max_length(tensor):
return max(len(t) for t in tensor)
def tokenize(lang):
lang_tokenizer = tf.keras.preprocessing.text.Tokenizer(
filters='')
lang_tokenizer.fit_on_texts(lang)
tensor = lang_tokenizer.texts_to_sequences(lang)
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor,
padding='post')
return tensor, lang_tokenizer
def load_dataset(path, num_examples=None):
# クリーニングされた入力と出力のペアを生成
targ_lang, inp_lang = create_dataset(path, num_examples)
input_tensor, inp_lang_tokenizer = tokenize(inp_lang)
target_tensor, targ_lang_tokenizer = tokenize(targ_lang)
return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer
実験を速くするためデータセットのサイズを制限(オプション)
100,000 を超える文のデータセットを使って訓練するには長い時間がかかります。訓練を速くするため、データセットのサイズを 30,000 に制限することができます(もちろん、データが少なければ翻訳の品質は低下します)。
# このサイズのデータセットで実験
num_examples = 30000
input_tensor, target_tensor, inp_lang, targ_lang = load_dataset(path_to_file, num_examples)
# ターゲットテンソルの最大長を計算
max_length_targ, max_length_inp = max_length(target_tensor), max_length(input_tensor)
# 80-20で分割を行い、訓練用と検証用のデータセットを作成
input_tensor_train, input_tensor_val, target_tensor_train, target_tensor_val = train_test_split(input_tensor, target_tensor, test_size=0.2)
# 長さを表示
print(len(input_tensor_train), len(target_tensor_train), len(input_tensor_val), len(target_tensor_val))
24000 24000 6000 6000
def convert(lang, tensor):
for t in tensor:
if t!=0:
print ("%d ----> %s" % (t, lang.index_word[t]))
print ("Input Language; index to word mapping")
convert(inp_lang, input_tensor_train[0])
print ()
print ("Target Language; index to word mapping")
convert(targ_lang, target_tensor_train[0])
Input Language; index to word mapping 1 ----> <start> 4 ----> tom 7 ----> es 36 ----> muy 2138 ----> capaz 3 ----> . 2 ----> <end> Target Language; index to word mapping 1 ----> <start> 5 ----> tom 8 ----> is 48 ----> very 4910 ----> competent 3 ----> . 2 ----> <end>
tf.data データセットの作成
BUFFER_SIZE = len(input_tensor_train)
BATCH_SIZE = 64
steps_per_epoch = len(input_tensor_train)//BATCH_SIZE
embedding_dim = 256
units = 1024
vocab_inp_size = len(inp_lang.word_index)+1
vocab_tar_size = len(targ_lang.word_index)+1
dataset = tf.data.Dataset.from_tensor_slices((input_tensor_train, target_tensor_train)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
example_input_batch, example_target_batch = next(iter(dataset))
example_input_batch.shape, example_target_batch.shape
(TensorShape([64, 16]), TensorShape([64, 11]))
エンコーダー・デコーダーモデルの記述
TensorFlow の Neural Machine Translation (seq2seq) tutorial に記載されているアテンション付きのエンコーダー・デコーダーモデルを実装します。この例では、最新の API セットを使用します。このノートブックは、上記の seq2seq チュートリアルにある attention equations を実装します。下図は、入力の単語ひとつひとつにアテンション機構によって重みが割り当てられ、それを使ってデコーダーが文中の次の単語を予測することを示しています。下記の図と式は Luong の論文 にあるアテンション機構の例です。

入力がエンコーダーを通過すると、shape が (batch_size, max_length, hidden_size) のエンコーダー出力と、shape が (batch_size, hidden_size) のエンコーダーの隠れ状態が得られます。
下記に実装されている式を示します。


このチュートリアルでは、エンコーダーでは Bahdanau attention を使用します。簡略化した式を書く前に、表記方法を定めましょう。
- FC = 全結合 (Dense) レイヤー
- EO = エンコーダーの出力
- H = 隠れ状態
- X = デコーダーへの入力
擬似コードは下記のとおりです。
score = FC(tanh(FC(EO) + FC(H)))attention weights = softmax(score, axis = 1)softmax は既定では最後の軸に対して実行されますが、スコアの shape が (batch_size, max_length, hidden_size) であるため、最初の軸 に適用します。max_lengthは入力の長さです。入力それぞれに重みを割り当てようとしているので、softmax はその軸に適用されなければなりません。context vector = sum(attention weights * EO, axis = 1). 上記と同様の理由で axis = 1 に設定しています。embedding output= デコーダーへの入力 X は Embedding レイヤーを通して渡されます。merged vector = concat(embedding output, context vector)- この結合されたベクトルがつぎに GRU に渡されます。
それぞれのステップでのベクトルの shape は、コードのコメントに指定されています。
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.enc_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state = hidden)
return output, state
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.enc_units))
encoder = Encoder(vocab_inp_size, embedding_dim, units, BATCH_SIZE)
# サンプル入力
sample_hidden = encoder.initialize_hidden_state()
sample_output, sample_hidden = encoder(example_input_batch, sample_hidden)
print ('Encoder output shape: (batch size, sequence length, units) {}'.format(sample_output.shape))
print ('Encoder Hidden state shape: (batch size, units) {}'.format(sample_hidden.shape))
Encoder output shape: (batch size, sequence length, units) (64, 16, 1024) Encoder Hidden state shape: (batch size, units) (64, 1024)
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
# hidden shape == (batch_size, hidden size)
# hidden_with_time_axis shape == (batch_size, 1, hidden size)
# スコアを計算するためにこのように加算を実行する
hidden_with_time_axis = tf.expand_dims(query, 1)
# score shape == (batch_size, max_length, 1)
# スコアを self.V に適用するために最後の軸は 1 となる
# self.V に適用する前のテンソルの shape は (batch_size, max_length, units)
score = self.V(tf.nn.tanh(
self.W1(values) + self.W2(hidden_with_time_axis)))
# attention_weights の shape == (batch_size, max_length, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# context_vector の合計後の shape == (batch_size, hidden_size)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
attention_layer = BahdanauAttention(10)
attention_result, attention_weights = attention_layer(sample_hidden, sample_output)
print("Attention result shape: (batch size, units) {}".format(attention_result.shape))
print("Attention weights shape: (batch_size, sequence_length, 1) {}".format(attention_weights.shape))
Attention result shape: (batch size, units) (64, 1024) Attention weights shape: (batch_size, sequence_length, 1) (64, 16, 1)
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
self.fc = tf.keras.layers.Dense(vocab_size)
# アテンションのため
self.attention = BahdanauAttention(self.dec_units)
def call(self, x, hidden, enc_output):
# enc_output の shape == (batch_size, max_length, hidden_size)
context_vector, attention_weights = self.attention(hidden, enc_output)
# 埋め込み層を通過したあとの x の shape == (batch_size, 1, embedding_dim)
x = self.embedding(x)
# 結合後の x の shape == (batch_size, 1, embedding_dim + hidden_size)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# 結合したベクトルを GRU 層に渡す
output, state = self.gru(x)
# output shape == (batch_size * 1, hidden_size)
output = tf.reshape(output, (-1, output.shape[2]))
# output shape == (batch_size, vocab)
x = self.fc(output)
return x, state, attention_weights
decoder = Decoder(vocab_tar_size, embedding_dim, units, BATCH_SIZE)
sample_decoder_output, _, _ = decoder(tf.random.uniform((64, 1)),
sample_hidden, sample_output)
print ('Decoder output shape: (batch_size, vocab size) {}'.format(sample_decoder_output.shape))
Decoder output shape: (batch_size, vocab size) (64, 4935)
オプティマイザと損失関数の定義
optimizer = tf.keras.optimizers.Adam()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
チェックポイント(オブジェクトベースの保存)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(optimizer=optimizer,
encoder=encoder,
decoder=decoder)
訓練
- 入力 を エンコーダー に通すと、エンコーダー出力 と エンコーダーの隠れ状態 が返される
- エンコーダーの出力とエンコーダーの隠れ状態、そしてデコーダーの入力(これが 開始トークン)がデコーダーに渡される
- デコーダーは 予測値 と デコーダーの隠れ状態 を返す
- つぎにデコーダーの隠れ状態がモデルに戻され、予測値が損失関数の計算に使用される
- デコーダーへの次の入力を決定するために Teacher Forcing が使用される
- Teacher Forcing は、正解単語 をデコーダーの 次の入力 として使用するテクニックである
- 最後に勾配を計算し、それをオプティマイザに与えて誤差逆伝播を行う
@tf.function
def train_step(inp, targ, enc_hidden):
loss = 0
with tf.GradientTape() as tape:
enc_output, enc_hidden = encoder(inp, enc_hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([targ_lang.word_index['<start>']] * BATCH_SIZE, 1)
# Teacher Forcing - 正解値を次の入力として供給
for t in range(1, targ.shape[1]):
# passing enc_output to the decoder
predictions, dec_hidden, _ = decoder(dec_input, dec_hidden, enc_output)
loss += loss_function(targ[:, t], predictions)
# Teacher Forcing を使用
dec_input = tf.expand_dims(targ[:, t], 1)
batch_loss = (loss / int(targ.shape[1]))
variables = encoder.trainable_variables + decoder.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return batch_loss
EPOCHS = 10
for epoch in range(EPOCHS):
start = time.time()
enc_hidden = encoder.initialize_hidden_state()
total_loss = 0
for (batch, (inp, targ)) in enumerate(dataset.take(steps_per_epoch)):
batch_loss = train_step(inp, targ, enc_hidden)
total_loss += batch_loss
if batch % 100 == 0:
print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,
batch,
batch_loss.numpy()))
# 2 エポックごとにモデル(のチェックポイント)を保存
if (epoch + 1) % 2 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print('Epoch {} Loss {:.4f}'.format(epoch + 1,
total_loss / steps_per_epoch))
print('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
Epoch 1 Batch 0 Loss 4.7353 Epoch 1 Batch 100 Loss 2.3236 Epoch 1 Batch 200 Loss 1.6937 Epoch 1 Batch 300 Loss 1.7070 Epoch 1 Loss 2.0369 Time taken for 1 epoch 38.7444052696228 sec Epoch 2 Batch 0 Loss 1.6072 Epoch 2 Batch 100 Loss 1.4702 Epoch 2 Batch 200 Loss 1.4290 Epoch 2 Batch 300 Loss 1.3025 Epoch 2 Loss 1.4043 Time taken for 1 epoch 21.323351621627808 sec Epoch 3 Batch 0 Loss 1.0264 Epoch 3 Batch 100 Loss 1.0971 Epoch 3 Batch 200 Loss 0.9568 Epoch 3 Batch 300 Loss 0.8830 Epoch 3 Loss 0.9820 Time taken for 1 epoch 20.229315757751465 sec Epoch 4 Batch 0 Loss 0.7010 Epoch 4 Batch 100 Loss 0.7372 Epoch 4 Batch 200 Loss 0.6545 Epoch 4 Batch 300 Loss 0.5471 Epoch 4 Loss 0.6590 Time taken for 1 epoch 20.86075496673584 sec Epoch 5 Batch 0 Loss 0.3788 Epoch 5 Batch 100 Loss 0.4551 Epoch 5 Batch 200 Loss 0.5846 Epoch 5 Batch 300 Loss 0.4743 Epoch 5 Loss 0.4479 Time taken for 1 epoch 20.013705730438232 sec Epoch 6 Batch 0 Loss 0.3106 Epoch 6 Batch 100 Loss 0.2062 Epoch 6 Batch 200 Loss 0.3290 Epoch 6 Batch 300 Loss 0.3195 Epoch 6 Loss 0.3081 Time taken for 1 epoch 20.81093120574951 sec Epoch 7 Batch 0 Loss 0.2261 Epoch 7 Batch 100 Loss 0.3102 Epoch 7 Batch 200 Loss 0.1855 Epoch 7 Batch 300 Loss 0.2770 Epoch 7 Loss 0.2200 Time taken for 1 epoch 20.144649267196655 sec Epoch 8 Batch 0 Loss 0.1757 Epoch 8 Batch 100 Loss 0.1824 Epoch 8 Batch 200 Loss 0.1366 Epoch 8 Batch 300 Loss 0.1332 Epoch 8 Loss 0.1618 Time taken for 1 epoch 20.600513696670532 sec Epoch 9 Batch 0 Loss 0.1050 Epoch 9 Batch 100 Loss 0.1242 Epoch 9 Batch 200 Loss 0.1232 Epoch 9 Batch 300 Loss 0.1080 Epoch 9 Loss 0.1271 Time taken for 1 epoch 20.18126344680786 sec Epoch 10 Batch 0 Loss 0.0934 Epoch 10 Batch 100 Loss 0.1031 Epoch 10 Batch 200 Loss 0.1194 Epoch 10 Batch 300 Loss 0.1105 Epoch 10 Loss 0.1017 Time taken for 1 epoch 20.478492975234985 sec
翻訳
- 評価関数は、Teacher Forcing を使わないことを除いては、訓練ループと同様である。タイムステップごとのデコーダーへの入力は、過去の予測値に加えて、隠れ状態とエンコーダーのアウトプットである。
- モデルが 終了トークン を予測したら、予測を停止する。
- また、タイムステップごとのアテンションの重み を保存する。
def evaluate(sentence):
attention_plot = np.zeros((max_length_targ, max_length_inp))
sentence = preprocess_sentence(sentence)
inputs = [inp_lang.word_index[i] for i in sentence.split(' ')]
inputs = tf.keras.preprocessing.sequence.pad_sequences([inputs],
maxlen=max_length_inp,
padding='post')
inputs = tf.convert_to_tensor(inputs)
result = ''
hidden = [tf.zeros((1, units))]
enc_out, enc_hidden = encoder(inputs, hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([targ_lang.word_index['<start>']], 0)
for t in range(max_length_targ):
predictions, dec_hidden, attention_weights = decoder(dec_input,
dec_hidden,
enc_out)
# 後ほどプロットするためにアテンションの重みを保存
attention_weights = tf.reshape(attention_weights, (-1, ))
attention_plot[t] = attention_weights.numpy()
predicted_id = tf.argmax(predictions[0]).numpy()
result += targ_lang.index_word[predicted_id] + ' '
if targ_lang.index_word[predicted_id] == '<end>':
return result, sentence, attention_plot
# 予測された ID がモデルに戻される
dec_input = tf.expand_dims([predicted_id], 0)
return result, sentence, attention_plot
# アテンションの重みをプロットする関数
def plot_attention(attention, sentence, predicted_sentence):
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(1, 1, 1)
ax.matshow(attention, cmap='viridis')
fontdict = {'fontsize': 14}
ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90)
ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
def translate(sentence):
result, sentence, attention_plot = evaluate(sentence)
print('Input: %s' % (sentence))
print('Predicted translation: {}'.format(result))
attention_plot = attention_plot[:len(result.split(' ')), :len(sentence.split(' '))]
plot_attention(attention_plot, sentence.split(' '), result.split(' '))
最後のチェックポイントを復元しテストする
# checkpoint_dir の中の最後のチェックポイントを復元
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.checkpoint.checkpoint.CheckpointLoadStatus at 0x7f70c1e58f10>
translate(u'hace mucho frio aqui.')
Input: <start> hace mucho frio aqui . <end> Predicted translation: it s very cold here . <end> /tmpfs/tmp/ipykernel_146998/2662029192.py:9: UserWarning: FixedFormatter should only be used together with FixedLocator ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90) /tmpfs/tmp/ipykernel_146998/2662029192.py:10: UserWarning: FixedFormatter should only be used together with FixedLocator ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)

translate(u'esta es mi vida.')
Input: <start> esta es mi vida . <end> Predicted translation: this is my life . <end> /tmpfs/tmp/ipykernel_146998/2662029192.py:9: UserWarning: FixedFormatter should only be used together with FixedLocator ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90) /tmpfs/tmp/ipykernel_146998/2662029192.py:10: UserWarning: FixedFormatter should only be used together with FixedLocator ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)

translate(u'¿todavia estan en casa?')
Input: <start> ¿ todavia estan en casa ? <end> Predicted translation: are you still at home ? <end> /tmpfs/tmp/ipykernel_146998/2662029192.py:9: UserWarning: FixedFormatter should only be used together with FixedLocator ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90) /tmpfs/tmp/ipykernel_146998/2662029192.py:10: UserWarning: FixedFormatter should only be used together with FixedLocator ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)

# 翻訳あやまりの例
translate(u'trata de averiguarlo.')
Input: <start> trata de averiguarlo . <end> Predicted translation: try to figure it out . <end> /tmpfs/tmp/ipykernel_146998/2662029192.py:9: UserWarning: FixedFormatter should only be used together with FixedLocator ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90) /tmpfs/tmp/ipykernel_146998/2662029192.py:10: UserWarning: FixedFormatter should only be used together with FixedLocator ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)

次のステップ
- 異なるデータセットをダウンロードして翻訳の実験を行ってみよう。たとえば英語からドイツ語や、英語からフランス語。
- もっと大きなデータセットで訓練を行ったり、もっと多くのエポックで訓練を行ったりしてみよう。