
Przegląd
Analiza modelu TensorFlow (TFMA) to biblioteka do przeprowadzania oceny modelu.
- Dla : Inżynierów uczenia maszynowego lub badaczy danych
- którzy : chcą analizować i rozumieć swoje modele TensorFlow
- jest to : samodzielna biblioteka lub komponent potoku TFX
- to : ocenia modele na dużych ilościach danych w sposób rozproszony na podstawie tych samych metryk zdefiniowanych podczas szkolenia. Te dane są porównywane na wycinkach danych i wizualizowane w notatnikach Jupyter lub Colab.
- w przeciwieństwie do : niektóre narzędzia do introspekcji modeli, takie jak tensorboard, które oferują introspekcję modeli
TFMA wykonuje swoje obliczenia w sposób rozproszony na dużych ilościach danych przy użyciu Apache Beam . W poniższych sekcjach opisano sposób konfigurowania podstawowego potoku oceny TFMA. Zobacz architekturę, aby uzyskać więcej szczegółów na temat podstawowej implementacji.
Jeśli chcesz po prostu wskoczyć i zacząć, sprawdź nasz notatnik colab .
Stronę tę można również wyświetlić na stronie tensorflow.org .
Obsługiwane typy modeli
TFMA została zaprojektowana do obsługi modeli opartych na tensorflow, ale można ją łatwo rozszerzyć, aby obsługiwała również inne frameworki. Historycznie rzecz biorąc, TFMA wymagała utworzenia EvalSavedModel do korzystania z TFMA, ale najnowsza wersja TFMA obsługuje wiele typów modeli w zależności od potrzeb użytkownika. Konfigurowanie EvalSavedModel powinno być wymagane tylko wtedy, gdy używany jest model oparty na tf.estimator i wymagane są niestandardowe metryki czasu szkolenia.
Należy pamiętać, że ponieważ TFMA działa teraz w oparciu o model obsługi, TFMA nie będzie już automatycznie oceniać metryk dodanych w czasie szkolenia. Wyjątkiem od tego przypadku jest użycie modelu keras, ponieważ keras zapisuje metryki używane wraz z zapisanym modelem. Jeśli jednak jest to trudne wymaganie, najnowsza wersja TFMA jest kompatybilna wstecz, tak że EvalSavedModel nadal może być uruchamiany w potoku TFMA.
Poniższa tabela podsumowuje domyślnie obsługiwane modele:
| Typ modelu | Metryki czasu szkolenia | Metryki po szkoleniu |
|---|---|---|
| TF2 (kery) | T* | Y |
| TF2 (ogólny) | Nie dotyczy | Y |
| EvalSavedModel (estymator) | Y | Y |
| Brak (pd.DataFrame itp.) | Nie dotyczy | Y |
- Metryki czasu treningu odnoszą się do metryk zdefiniowanych w czasie treningu i zapisanych wraz z modelem (model zapisany w TFMA EvalSavedModel lub keras). Metryki po szkoleniu odnoszą się do metryk dodanych za pośrednictwem
tfma.MetricConfig. - Ogólne modele TF2 to modele niestandardowe, które eksportują sygnatury, które można wykorzystać do wnioskowania i które nie są oparte ani na kerasach, ani na estymatorach.
Zobacz często zadawane pytania , aby uzyskać więcej informacji na temat ustawiania i konfigurowania różnych typów modeli.
Organizować coś
Przed uruchomieniem oceny wymagana jest niewielka konfiguracja. Najpierw należy zdefiniować obiekt tfma.EvalConfig , który udostępnia specyfikacje modelu, metryk i wycinków, które mają być oceniane. Po drugie należy utworzyć tfma.EvalSharedModel wskazujący rzeczywisty model (lub modele), który ma zostać użyty podczas oceny. Po ich zdefiniowaniu przeprowadza się ocenę poprzez wywołanie tfma.run_model_analysis z odpowiednim zbiorem danych. Więcej szczegółów znajdziesz w przewodniku konfiguracji .
Jeśli działasz w potoku TFX, zobacz przewodnik TFX, aby dowiedzieć się, jak skonfigurować TFMA do działania jako komponent oceniający TFX.
Przykłady
Ocena pojedynczego modelu
Poniżej zastosowano tfma.run_model_analysis do przeprowadzenia oceny udostępniającego modelu. Wyjaśnienie różnych niezbędnych ustawień można znaleźć w instrukcji konfiguracji .
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
W przypadku oceny rozproszonej skonstruuj potok Apache Beam przy użyciu rozproszonego modułu uruchamiającego. W przygotowaniu użyj tfma.ExtractEvaluateAndWriteResults do oceny i zapisania wyników. Wyniki można załadować do wizualizacji za pomocą tfma.load_eval_result .
Na przykład:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
Walidacja modelu
Aby przeprowadzić walidację modelu względem kandydata i linii bazowej, zaktualizuj konfigurację, aby uwzględnić ustawienie progu i przekaż dwa modele do tfma.run_model_analysis .
Na przykład:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
Wyobrażanie sobie
Wyniki oceny TFMA można wizualizować w notatniku Jupyter przy użyciu komponentów frontendowych zawartych w TFMA. Na przykład:
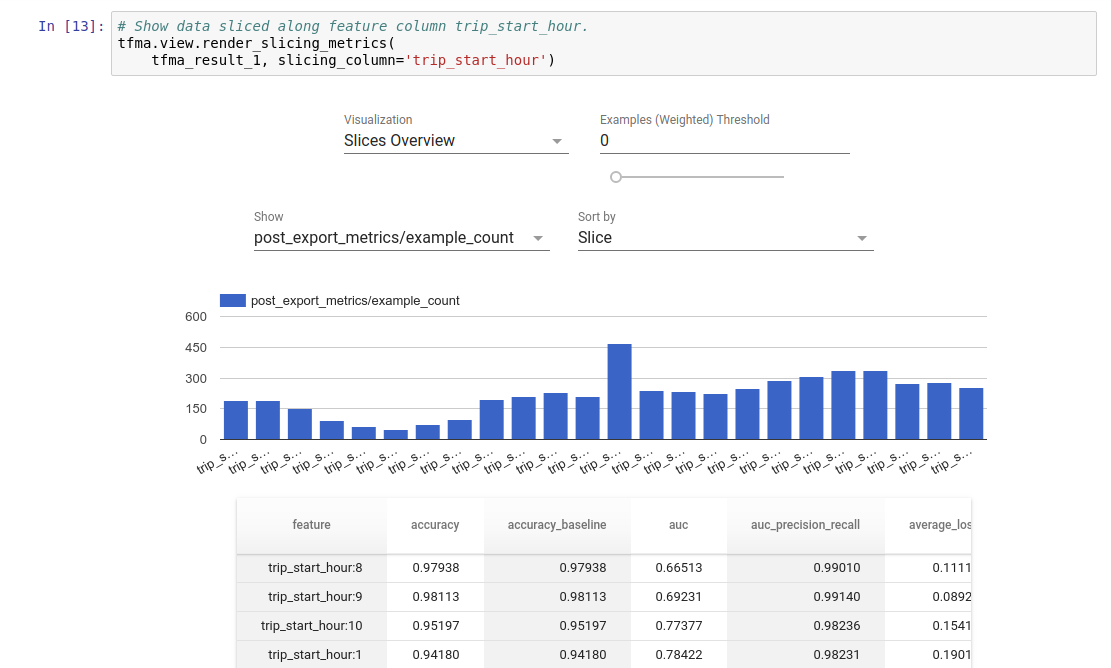 .
.