
exampleGen TFX पाइपलाइन घटक डेटा को TFX पाइपलाइनों में अंतर्ग्रहण करता है। यह उदाहरण उत्पन्न करने के लिए बाहरी फ़ाइलों/सेवाओं का उपयोग करता है जिन्हें अन्य टीएफएक्स घटकों द्वारा पढ़ा जाएगा। यह सुसंगत और विन्यास योग्य विभाजन भी प्रदान करता है, और एमएल सर्वोत्तम अभ्यास के लिए डेटासेट में फेरबदल करता है।
- उपभोग: CSV,
TFRecord, Avro, Parquet और BigQuery जैसे बाहरी डेटा स्रोतों से डेटा। - उत्सर्जन:
tf.Exampleरिकॉर्ड,tf.SequenceExampleरिकॉर्ड, या प्रोटो प्रारूप, पेलोड प्रारूप पर निर्भर करता है।
उदाहरणजेन और अन्य घटक
exampleGen उन घटकों को डेटा प्रदान करता है जो TensorFlow डेटा वैलिडेशन लाइब्रेरी का उपयोग करते हैं, जैसे स्कीमजेन , स्टैटिस्टिक्सजेन और उदाहरण वैलिडेटर । यह ट्रांसफ़ॉर्म को डेटा भी प्रदान करता है, जो टेन्सरफ़्लो ट्रांसफ़ॉर्म लाइब्रेरी का उपयोग करता है, और अंततः अनुमान के दौरान लक्ष्य को तैनात करने के लिए उपयोग करता है।
डेटा स्रोत और प्रारूप
वर्तमान में टीएफएक्स की एक मानक स्थापना में इन डेटा स्रोतों और प्रारूपों के लिए पूर्ण उदाहरणजेन घटक शामिल हैं:
कस्टम निष्पादक भी उपलब्ध हैं जो इन डेटा स्रोतों और प्रारूपों के लिए exampleGen घटकों के विकास को सक्षम करते हैं:
कस्टम निष्पादकों के उपयोग और विकास के बारे में अधिक जानकारी के लिए स्रोत कोड में उपयोग के उदाहरण और इस चर्चा को देखें।
इसके अलावा, ये डेटा स्रोत और प्रारूप कस्टम घटक उदाहरण के रूप में उपलब्ध हैं:
अपाचे बीम द्वारा समर्थित डेटा प्रारूपों को अंतर्ग्रहण करना
अपाचे बीम डेटा स्रोतों और प्रारूपों की एक विस्तृत श्रृंखला से डेटा अंतर्ग्रहण का समर्थन करता है, ( नीचे देखें )। इन क्षमताओं का उपयोग TFX के लिए कस्टम exampleGen घटकों को बनाने के लिए किया जा सकता है, जो कि कुछ मौजूदा exampleGen घटकों द्वारा प्रदर्शित किया गया है ( नीचे देखें )।
उदाहरणजेन घटक का उपयोग कैसे करें
समर्थित डेटा स्रोतों (वर्तमान में, CSV फ़ाइलें, tf.Example , tf.SequenceExample और प्रोटो प्रारूप वाली TFRecord फ़ाइलें, और BigQuery क्वेरीज़ के परिणाम) के लिए exampleGen पाइपलाइन घटक का उपयोग सीधे तैनाती में किया जा सकता है और इसके लिए कम अनुकूलन की आवश्यकता होती है। उदाहरण के लिए:
example_gen = CsvExampleGen(input_base='data_root')
या सीधे tf.Example के साथ बाहरी TFRecord आयात करने के लिए नीचे जैसा:
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
अवधि, संस्करण और विभाजन
स्पैन प्रशिक्षण उदाहरणों का एक समूह है। यदि आपका डेटा फ़ाइल सिस्टम पर बना हुआ है, तो प्रत्येक स्पैन को एक अलग निर्देशिका में संग्रहीत किया जा सकता है। स्पैन के शब्दार्थ को टीएफएक्स में हार्डकोड नहीं किया गया है; एक स्पैन एक दिन के डेटा, एक घंटे के डेटा या किसी अन्य समूह के अनुरूप हो सकता है जो आपके कार्य के लिए सार्थक है।
प्रत्येक स्पैन डेटा के कई संस्करण रख सकता है। उदाहरण देने के लिए, यदि आप खराब गुणवत्ता वाले डेटा को साफ़ करने के लिए किसी स्पैन से कुछ उदाहरण हटाते हैं, तो इसका परिणाम उस स्पैन का एक नया संस्करण हो सकता है। डिफ़ॉल्ट रूप से, TFX घटक एक अवधि के भीतर नवीनतम संस्करण पर काम करते हैं।
एक स्पैन के भीतर प्रत्येक संस्करण को कई स्प्लिट्स में विभाजित किया जा सकता है। स्पैन को विभाजित करने के लिए सबसे आम उपयोग-मामला इसे प्रशिक्षण और eval डेटा में विभाजित करना है।
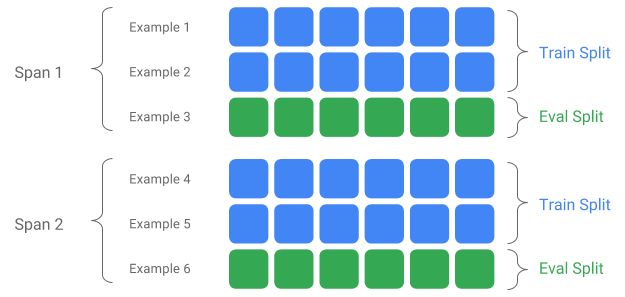
कस्टम इनपुट/आउटपुट विभाजन
ट्रेन/ईवल स्प्लिट अनुपात को अनुकूलित करने के लिए जिसे exampleGen आउटपुट देगा, exampleGen घटक के लिए output_config सेट करें। उदाहरण के लिए:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
ध्यान दें कि इस उदाहरण में hash_buckets कैसे सेट किए गए थे।
एक इनपुट स्रोत के लिए जो पहले ही विभाजित हो चुका है, exampleGen घटक के लिए input_config सेट करें:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
फ़ाइल आधारित उदाहरण जेन (उदाहरण के लिए CsvExampleGen और आयातExampleGen) के लिए, pattern एक ग्लोब सापेक्ष फ़ाइल पैटर्न है जो इनपुट बेस पथ द्वारा दी गई रूट निर्देशिका के साथ इनपुट फ़ाइलों पर मैप करता है। क्वेरी-आधारित उदाहरण जेन (उदाहरण के लिए BigQueryExampleGen, PrestoExampleGen) के लिए, pattern एक SQL क्वेरी है।
डिफ़ॉल्ट रूप से, संपूर्ण इनपुट बेस डीआईआर को एकल इनपुट स्प्लिट के रूप में माना जाता है, और ट्रेन और ईवल आउटपुट स्प्लिट 2:1 अनुपात के साथ उत्पन्न होता है।
कृपया exampleGen के इनपुट और आउटपुट स्प्लिट कॉन्फ़िगरेशन के लिए proto/example_gen.proto देखें। और कस्टम स्प्लिट्स डाउनस्ट्रीम का उपयोग करने के लिए डाउनस्ट्रीम घटक मार्गदर्शिका देखें।
विभाजन विधि
hash_buckets विभाजन विधि का उपयोग करते समय, संपूर्ण रिकॉर्ड के बजाय, उदाहरणों को विभाजित करने के लिए एक सुविधा का उपयोग किया जा सकता है। यदि कोई सुविधा मौजूद है, तो exampleGen विभाजन कुंजी के रूप में उस सुविधा के फ़िंगरप्रिंट का उपयोग करेगा।
इस सुविधा का उपयोग उदाहरणों के कुछ गुणों के संबंध में एक स्थिर विभाजन को बनाए रखने के लिए किया जा सकता है: उदाहरण के लिए, यदि "user_id" को विभाजन सुविधा नाम के रूप में चुना गया था, तो एक उपयोगकर्ता को हमेशा एक ही विभाजन में रखा जाएगा।
"फ़ीचर" का क्या अर्थ है और निर्दिष्ट नाम के साथ "फ़ीचर" का मिलान कैसे किया जाए, इसकी व्याख्या exampleGen कार्यान्वयन और उदाहरणों के प्रकार पर निर्भर करती है।
तैयार उदाहरणजेन कार्यान्वयन के लिए:
- यदि यह tf.Example उत्पन्न करता है, तो "फ़ीचर" का अर्थ tf.Example.features.feature में एक प्रविष्टि है।
- यदि यह tf.SequenceExample उत्पन्न करता है, तो "फ़ीचर" का अर्थ tf.SequenceExample.context.feature में एक प्रविष्टि है।
- केवल int64 और बाइट्स सुविधाएँ समर्थित हैं।
निम्नलिखित मामलों में, exampleGen रनटाइम त्रुटियाँ उत्पन्न करता है:
- उदाहरण में निर्दिष्ट सुविधा नाम मौजूद नहीं है.
- खाली सुविधा:
tf.train.Feature(). - गैर-समर्थित फ़ीचर प्रकार, उदाहरण के लिए, फ़्लोट फ़ीचर।
उदाहरणों में किसी सुविधा के आधार पर ट्रेन/ईवल स्प्लिट को आउटपुट करने के लिए, exampleGen घटक के लिए output_config सेट करें। उदाहरण के लिए:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
ध्यान दें कि इस उदाहरण में partition_feature_name कैसे सेट किया गया था।
अवधि
इनपुट ग्लोब पैटर्न में '{SPAN}' स्पेक का उपयोग करके स्पैन को पुनः प्राप्त किया जा सकता है:
- यह विशिष्टता अंकों से मेल खाती है और डेटा को प्रासंगिक स्पैन संख्याओं में मैप करती है। उदाहरण के लिए, 'data_{SPAN}-*.tfrecord' 'data_12-a.tfrecord', 'data_12-b.tfrecord' जैसी फ़ाइलें एकत्र करेगा।
- वैकल्पिक रूप से, इस विशिष्टता को मैप किए जाने पर पूर्णांकों की चौड़ाई के साथ निर्दिष्ट किया जा सकता है। उदाहरण के लिए, 'data_{SPAN:2}.file' 'data_02.file' और 'data_27.file' (क्रमशः Span-2 और Span-27 के लिए इनपुट के रूप में) जैसी फ़ाइलों पर मैप होता है, लेकिन 'data_1' पर मैप नहीं होता है। फ़ाइल' और न ही 'data_123.फ़ाइल'।
- जब SPAN स्पेक गायब होता है, तो इसे हमेशा Span '0' माना जाता है।
- यदि स्पैन निर्दिष्ट है, तो पाइपलाइन नवीनतम स्पैन को संसाधित करेगी, और स्पैन संख्या को मेटाडेटा में संग्रहीत करेगी।
उदाहरण के लिए, मान लें कि इनपुट डेटा हैं:
- '/tmp/span-1/ट्रेन/डेटा'
- '/tmp/span-1/eval/डेटा'
- '/tmp/span-2/ट्रेन/डेटा'
- '/tmp/span-2/eval/डेटा'
और इनपुट कॉन्फ़िगरेशन नीचे दिखाया गया है:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
पाइपलाइन को ट्रिगर करते समय, यह प्रक्रिया करेगा:
- '/tmp/span-2/train/data' ट्रेन विभाजन के रूप में
- '/tmp/span-2/eval/data' eval स्प्लिट के रूप में
स्पैन संख्या '2' के साथ। यदि बाद में '/tmp/span-3/...' तैयार है, तो बस पाइपलाइन को फिर से ट्रिगर करें और यह प्रसंस्करण के लिए स्पैन '3' उठाएगा। नीचे स्पैन स्पेक का उपयोग करने के लिए कोड उदाहरण दिखाया गया है:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
एक निश्चित अवधि को पुनः प्राप्त करने का कार्य रेंजकॉन्फिग के साथ किया जा सकता है, जिसका विवरण नीचे दिया गया है।
तारीख
यदि आपका डेटा स्रोत दिनांक के अनुसार फ़ाइल सिस्टम पर व्यवस्थित है, तो TFX सीधे संख्याओं को फैलाने के लिए दिनांक मैपिंग का समर्थन करता है। तिथियों से अवधियों तक मानचित्रण का प्रतिनिधित्व करने के लिए तीन विशिष्टताएँ हैं: {YYYY}, {MM} और {DD}:
- यदि कोई निर्दिष्ट किया गया है तो इनपुट ग्लोब पैटर्न में तीन विशिष्टताएँ पूरी तरह से मौजूद होनी चाहिए:
- या तो {SPAN} विशिष्टता या दिनांक विशिष्टताओं का यह सेट विशेष रूप से निर्दिष्ट किया जा सकता है।
- YYYY से वर्ष, MM से महीना और DD से महीने के दिन के साथ एक कैलेंडर तिथि की गणना की जाती है, फिर स्पैन संख्या की गणना यूनिक्स युग (यानी 1970-01-01) के बाद से दिनों की संख्या के रूप में की जाती है। उदाहरण के लिए, 'log-{YYYY} अवधि-17167.
- यदि दिनांक विनिर्देशों का यह सेट निर्दिष्ट किया गया है, तो पाइपलाइन नवीनतम नवीनतम तिथि को संसाधित करेगी, और मेटाडेटा में संबंधित स्पैन संख्या को संग्रहीत करेगी।
उदाहरण के लिए, मान लें कि इनपुट डेटा कैलेंडर तिथि के अनुसार व्यवस्थित है:
- '/tmp/1970-01-02/ट्रेन/डेटा'
- '/tmp/1970-01-02/eval/डेटा'
- '/tmp/1970-01-03/ट्रेन/डेटा'
- '/tmp/1970-01-03/eval/डेटा'
और इनपुट कॉन्फ़िगरेशन नीचे दिखाया गया है:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
पाइपलाइन को ट्रिगर करते समय, यह प्रक्रिया करेगा:
- ट्रेन विभाजन के रूप में '/tmp/1970-01-03/ट्रेन/डेटा'
- '/tmp/1970-01-03/eval/data' eval स्प्लिट के रूप में
स्पैन संख्या '2' के साथ। यदि बाद में '/tmp/1970-01-04/...' तैयार है, तो बस पाइपलाइन को फिर से ट्रिगर करें और यह प्रसंस्करण के लिए स्पैन '3' उठाएगा। नीचे दिनांक विवरण का उपयोग करने के लिए कोड उदाहरण दिखाया गया है:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
संस्करण
इनपुट ग्लोब पैटर्न में '{VERSION}' विशिष्टता का उपयोग करके संस्करण पुनर्प्राप्त किया जा सकता है:
- यह विशिष्टता अंकों से मेल खाती है और डेटा को SPAN के अंतर्गत प्रासंगिक संस्करण संख्याओं में मैप करती है। ध्यान दें कि संस्करण विशिष्टता का उपयोग स्पैन या दिनांक विशिष्टता के साथ संयोजन में किया जा सकता है।
- इस विशिष्टता को SPAN युक्ति की तरह ही चौड़ाई के साथ वैकल्पिक रूप से निर्दिष्ट किया जा सकता है। उदाहरण के लिए 'span-{SPAN}/संस्करण-{संस्करण:4}/डेटा-*'।
- जब संस्करण विशिष्टता गायब है, तो संस्करण कोई नहीं पर सेट है।
- यदि SPAN और संस्करण दोनों निर्दिष्ट हैं, तो पाइपलाइन नवीनतम अवधि के लिए नवीनतम संस्करण को संसाधित करेगी, और संस्करण संख्या को मेटाडेटा में संग्रहीत करेगी।
- यदि संस्करण निर्दिष्ट है, लेकिन स्पैन (या दिनांक विवरण) नहीं है, तो एक त्रुटि उत्पन्न होगी।
उदाहरण के लिए, मान लें कि इनपुट डेटा हैं:
- '/tmp/span-1/ver-1/ट्रेन/डेटा'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/ट्रेन/डेटा'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/ट्रेन/डेटा'
- '/tmp/span-2/ver-2/eval/data'
और इनपुट कॉन्फ़िगरेशन नीचे दिखाया गया है:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
पाइपलाइन को ट्रिगर करते समय, यह प्रक्रिया करेगा:
- '/tmp/span-2/ver-2/train/data' ट्रेन विभाजन के रूप में
- '/tmp/span-2/ver-2/eval/data' eval स्प्लिट के रूप में
स्पैन संख्या '2' और संस्करण संख्या '2' के साथ। यदि बाद में '/tmp/span-2/ver-3/...' तैयार है, तो बस पाइपलाइन को फिर से ट्रिगर करें और यह प्रसंस्करण के लिए स्पैन '2' और संस्करण '3' उठाएगा। नीचे संस्करण विशिष्टता का उपयोग करने के लिए कोड उदाहरण दिखाया गया है:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
रेंज कॉन्फिग
टीएफएक्स रेंज कॉन्फ़िगरेशन का उपयोग करके फ़ाइल-आधारित उदाहरणजेन में एक विशिष्ट स्पैन की पुनर्प्राप्ति और प्रसंस्करण का समर्थन करता है, विभिन्न टीएफएक्स इकाइयों के लिए श्रेणियों का वर्णन करने के लिए उपयोग किया जाने वाला एक सार कॉन्फ़िगरेशन। एक विशिष्ट स्पैन को पुनः प्राप्त करने के लिए, फ़ाइल-आधारित उदाहरणजेन घटक के लिए range_config सेट करें। उदाहरण के लिए, मान लें कि इनपुट डेटा हैं:
- '/tmp/span-01/ट्रेन/डेटा'
- '/tmp/span-01/eval/डेटा'
- '/tmp/span-02/ट्रेन/डेटा'
- '/tmp/span-02/eval/data'
स्पैन '1' के साथ डेटा को विशेष रूप से पुनर्प्राप्त और संसाधित करने के लिए, हम इनपुट कॉन्फिगरेशन के अलावा एक रेंज कॉन्फिगरेशन निर्दिष्ट करते हैं। ध्यान दें कि exampleGen केवल सिंगल-स्पैन स्टैटिक रेंज (विशिष्ट व्यक्तिगत स्पैन के प्रसंस्करण को निर्दिष्ट करने के लिए) का समर्थन करता है। इस प्रकार, स्टेटिकरेंज के लिए, स्टार्ट_स्पैन_नंबर को एंड_स्पैन_नंबर के बराबर होना चाहिए। शून्य-पैडिंग के लिए प्रदान किए गए स्पैन और स्पैन चौड़ाई की जानकारी (यदि प्रदान की गई है) का उपयोग करते हुए, उदाहरणजेन वांछित स्पैन संख्या के साथ प्रदान किए गए विभाजन पैटर्न में स्पैन स्पेक को बदल देगा। उपयोग का एक उदाहरण नीचे दिखाया गया है:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
रेंज कॉन्फ़िगरेशन का उपयोग विशिष्ट तिथियों को संसाधित करने के लिए भी किया जा सकता है, यदि स्पैन स्पेक के बजाय दिनांक स्पेक का उपयोग किया जाता है। उदाहरण के लिए, मान लें कि इनपुट डेटा कैलेंडर तिथि के अनुसार व्यवस्थित है:
- '/tmp/1970-01-02/ट्रेन/डेटा'
- '/tmp/1970-01-02/eval/डेटा'
- '/tmp/1970-01-03/ट्रेन/डेटा'
- '/tmp/1970-01-03/eval/डेटा'
2 जनवरी 1970 को डेटा को विशेष रूप से पुनः प्राप्त करने और संसाधित करने के लिए, हम निम्नलिखित कार्य करते हैं:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
कस्टम उदाहरणजनरल
यदि वर्तमान में उपलब्ध exampleGen घटक आपकी आवश्यकताओं के अनुरूप नहीं हैं, तो आप एक कस्टम exampleGen बना सकते हैं, जो आपको विभिन्न डेटा स्रोतों या विभिन्न डेटा प्रारूपों से पढ़ने में सक्षम करेगा।
फ़ाइल-आधारित उदाहरणजन अनुकूलन (प्रायोगिक)
सबसे पहले, एक कस्टम बीम PTransform के साथ BaseExampleGenExecutor का विस्तार करें, जो आपके ट्रेन/ईवल इनपुट स्प्लिट से TF उदाहरणों में रूपांतरण प्रदान करता है। उदाहरण के लिए, CsvExampleGen निष्पादक इनपुट CSV स्प्लिट से TF उदाहरणों में रूपांतरण प्रदान करता है।
फिर, उपरोक्त निष्पादक के साथ एक घटक बनाएं, जैसा कि CsvExampleGen घटक में किया गया है। वैकल्पिक रूप से, एक कस्टम निष्पादक को मानक exampleGen घटक में पास करें जैसा कि नीचे दिखाया गया है।
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
अब, हम इस पद्धति का उपयोग करके एवरो और पैरक्वेट फ़ाइलों को पढ़ने का भी समर्थन करते हैं।
अतिरिक्त डेटा प्रारूप
अपाचे बीम कई अतिरिक्त डेटा प्रारूपों को पढ़ने का समर्थन करता है। बीम I/O ट्रांसफॉर्म के माध्यम से। आप एवरो उदाहरण के समान पैटर्न का उपयोग करके बीम I/O ट्रांसफ़ॉर्म का लाभ उठाकर कस्टम उदाहरणजेन घटक बना सकते हैं
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
इस लेखन के समय बीम पायथन एसडीके के लिए वर्तमान में समर्थित प्रारूप और डेटा स्रोतों में शामिल हैं:
- अमेज़न S3
- अपाचे एवरो
- अपाचे Hadoop
- अपाचे काफ्का
- अपाचे लकड़ी की छत
- गूगल क्लाउड बिगक्वेरी
- गूगल क्लाउड बिगटेबल
- Google क्लाउड डेटास्टोर
- Google क्लाउड पब/उप
- गूगल क्लाउड स्टोरेज (जीसीएस)
- MongoDB
नवीनतम सूची के लिए बीम दस्तावेज़ देखें।
क्वेरी-आधारित उदाहरणजन अनुकूलन (प्रायोगिक)
सबसे पहले, BaseExampleGenExecutor को एक कस्टम बीम PTransform के साथ विस्तारित करें, जो बाहरी डेटा स्रोत से पढ़ता है। फिर, QueryBasedExampleGen का विस्तार करके एक सरल घटक बनाएं।
इसके लिए अतिरिक्त कनेक्शन कॉन्फ़िगरेशन की आवश्यकता हो भी सकती है और नहीं भी। उदाहरण के लिए, BigQuery निष्पादक एक डिफ़ॉल्ट बीम.io कनेक्टर का उपयोग करके पढ़ता है, जो कनेक्शन कॉन्फ़िगरेशन विवरण को सारगर्भित करता है। प्रेस्टो निष्पादक को इनपुट के रूप में एक कस्टम बीम PTransform और एक कस्टम कनेक्शन कॉन्फ़िगरेशन प्रोटोबफ़ की आवश्यकता होती है।
यदि कस्टम उदाहरणजेन घटक के लिए कनेक्शन कॉन्फ़िगरेशन की आवश्यकता है, तो एक नया प्रोटोबफ़ बनाएं और इसे कस्टम_कॉन्फिग के माध्यम से पास करें, जो अब एक वैकल्पिक निष्पादन पैरामीटर है। कॉन्फ़िगर किए गए घटक का उपयोग कैसे करें इसका एक उदाहरण नीचे दिया गया है।
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
उदाहरणजेन डाउनस्ट्रीम घटक
डाउनस्ट्रीम घटकों के लिए कस्टम स्प्लिट कॉन्फ़िगरेशन समर्थित है।
सांख्यिकीजनरल
डिफ़ॉल्ट व्यवहार सभी विभाजनों के लिए आँकड़े तैयार करना है।
किसी भी विभाजन को बाहर करने के लिए, स्टैटिस्टिक्सजेन घटक के लिए exclude_splits सेट करें। उदाहरण के लिए:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
स्कीमजेन
डिफ़ॉल्ट व्यवहार सभी विभाजनों के आधार पर एक स्कीमा उत्पन्न करना है।
किसी भी विभाजन को बाहर करने के लिए, SchemaGen घटक के लिए exclude_splits सेट करें। उदाहरण के लिए:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
उदाहरण सत्यापनकर्ता
डिफ़ॉल्ट व्यवहार एक स्कीमा के विरुद्ध इनपुट उदाहरणों पर सभी विभाजनों के आँकड़ों को मान्य करना है।
किसी भी विभाजन को बाहर करने के लिए, exampleValidator घटक के लिए exclude_splits सेट करें। उदाहरण के लिए:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
परिवर्तन
डिफ़ॉल्ट व्यवहार 'ट्रेन' विभाजन से मेटाडेटा का विश्लेषण और उत्पादन करना और सभी विभाजनों को बदलना है।
विश्लेषण स्प्लिट्स और ट्रांसफ़ॉर्म स्प्लिट्स को निर्दिष्ट करने के लिए, ट्रांसफ़ॉर्म घटक के लिए splits_config सेट करें। उदाहरण के लिए:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
ट्रेनर और ट्यूनर
डिफ़ॉल्ट व्यवहार 'ट्रेन' स्प्लिट पर ट्रेन करना और 'ईवल' स्प्लिट पर मूल्यांकन करना है।
ट्रेन स्प्लिट्स को निर्दिष्ट करने और स्प्लिट्स का मूल्यांकन करने के लिए, ट्रेनर घटक के लिए train_args और eval_args सेट करें। उदाहरण के लिए:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
मूल्यांकनकर्ता
डिफ़ॉल्ट व्यवहार 'eval' विभाजन पर गणना की गई मेट्रिक्स प्रदान करता है।
कस्टम स्प्लिट्स पर मूल्यांकन आँकड़ों की गणना करने के लिए, मूल्यांकनकर्ता घटक के लिए example_splits सेट करें। उदाहरण के लिए:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
अधिक विवरण CsvExampleGen API संदर्भ , FileBasedExampleGen API कार्यान्वयन और आयातExampleGen API संदर्भ में उपलब्ध हैं।