
निष्पक्षता संकेतक को व्यापक टेन्सरफ़्लो टूलकिट के साथ साझेदारी में निष्पक्षता संबंधी चिंताओं के लिए मॉडलों के मूल्यांकन और सुधार में टीमों का समर्थन करने के लिए डिज़ाइन किया गया है। यह टूल वर्तमान में हमारे कई उत्पादों द्वारा आंतरिक रूप से सक्रिय रूप से उपयोग किया जाता है, और अब आपके स्वयं के उपयोग के मामलों में प्रयास करने के लिए बीटा में उपलब्ध है।
निष्पक्षता संकेतक क्या है?
निष्पक्षता संकेतक एक पुस्तकालय है जो बाइनरी और मल्टीक्लास क्लासिफायर के लिए सामान्य रूप से पहचाने जाने वाले निष्पक्षता मेट्रिक्स की आसान गणना को सक्षम बनाता है। निष्पक्षता संबंधी चिंताओं के मूल्यांकन के लिए कई मौजूदा उपकरण बड़े पैमाने के डेटासेट और मॉडल पर अच्छी तरह से काम नहीं करते हैं। Google में, हमारे लिए ऐसे उपकरण होना महत्वपूर्ण है जो अरबों-उपयोगकर्ता प्रणालियों पर काम कर सकें। निष्पक्षता संकेतक आपको किसी भी आकार के उपयोग के मामले में मूल्यांकन करने की अनुमति देंगे।
विशेष रूप से, निष्पक्षता संकेतक में निम्नलिखित की क्षमता शामिल है:
- डेटासेट के वितरण का मूल्यांकन करें
- उपयोगकर्ताओं के परिभाषित समूहों के आधार पर मॉडल प्रदर्शन का मूल्यांकन करें
- आत्मविश्वास अंतराल और कई सीमाओं पर मूल्यांकन के साथ अपने परिणामों के बारे में आश्वस्त महसूस करें
- मूल कारणों और सुधार के अवसरों का पता लगाने के लिए अलग-अलग हिस्सों में गहराई से उतरें
पिप पैकेज डाउनलोड में शामिल हैं:
- टेन्सरफ़्लो डेटा सत्यापन (TFDV)
- टेन्सरफ्लो मॉडल विश्लेषण (टीएफएमए)
- निष्पक्षता संकेतक
- व्हाट-इफ़ टूल (WIT)
टेन्सरफ़्लो मॉडल के साथ निष्पक्षता संकेतक का उपयोग करना
डेटा
टीएफएमए के साथ निष्पक्षता संकेतक चलाने के लिए, सुनिश्चित करें कि मूल्यांकन डेटासेट उन सुविधाओं के लिए लेबल किया गया है जिन्हें आप काटना चाहते हैं। यदि आपके पास अपनी निष्पक्षता संबंधी चिंताओं के लिए सटीक स्लाइस सुविधाएँ नहीं हैं, तो आप एक मूल्यांकन सेट ढूंढने का प्रयास कर सकते हैं जो ऐसा करता है, या अपने फीचर सेट के भीतर प्रॉक्सी सुविधाओं पर विचार कर सकते हैं जो परिणाम असमानताओं को उजागर कर सकते हैं। अतिरिक्त मार्गदर्शन के लिए, यहां देखें।
नमूना
आप अपना मॉडल बनाने के लिए टेन्सरफ़्लो एस्टिमेटर क्लास का उपयोग कर सकते हैं। केरास मॉडलों के लिए समर्थन जल्द ही टीएफएमए में आ रहा है। यदि आप केरास मॉडल पर टीएफएमए चलाना चाहते हैं, तो कृपया नीचे "मॉडल-एग्नोस्टिक टीएफएमए" अनुभाग देखें।
आपके अनुमानक को प्रशिक्षित करने के बाद, आपको मूल्यांकन उद्देश्यों के लिए एक सहेजे गए मॉडल को निर्यात करने की आवश्यकता होगी। अधिक जानने के लिए, टीएफएमए गाइड देखें।
स्लाइस कॉन्फ़िगर करना
इसके बाद, उन स्लाइस को परिभाषित करें जिनका आप मूल्यांकन करना चाहते हैं:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur color’])
]
यदि आप इंटरसेक्शनल स्लाइस (उदाहरण के लिए, फर का रंग और ऊंचाई दोनों) का मूल्यांकन करना चाहते हैं, तो आप निम्नलिखित सेट कर सकते हैं:
slice_spec = [
tfma.slicer.SingleSliceSpec(columns=[‘fur_color’, ‘height’])
]`
निष्पक्षता मेट्रिक्स की गणना करें
metrics_callback सूची में निष्पक्षता संकेतक कॉलबैक जोड़ें। कॉलबैक में, आप उन सीमाओं की एक सूची परिभाषित कर सकते हैं जिन पर मॉडल का मूल्यांकन किया जाएगा।
from tensorflow_model_analysis.addons.fairness.post_export_metrics import fairness_indicators
# Build the fairness metrics. Besides the thresholds, you also can config the example_weight_key, labels_key here. For more details, please check the api.
metrics_callbacks = \
[tfma.post_export_metrics.fairness_indicators(thresholds=[0.1, 0.3,
0.5, 0.7, 0.9])]
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path=tfma_export_dir,
add_metrics_callbacks=metrics_callbacks)
कॉन्फ़िगरेशन चलाने से पहले, निर्धारित करें कि आप कॉन्फिडेंस अंतराल की गणना सक्षम करना चाहते हैं या नहीं। कॉन्फिडेंस अंतराल की गणना पॉइसन बूटस्ट्रैपिंग का उपयोग करके की जाती है और 20 से अधिक नमूनों की पुनर्गणना की आवश्यकता होती है।
compute_confidence_intervals = True
TFMA मूल्यांकन पाइपलाइन चलाएँ:
validate_dataset = tf.data.TFRecordDataset(filenames=[validate_tf_file])
# Run the fairness evaluation.
with beam.Pipeline() as pipeline:
_ = (
pipeline
| beam.Create([v.numpy() for v in validate_dataset])
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
slice_spec=slice_spec,
compute_confidence_intervals=compute_confidence_intervals,
output_path=tfma_eval_result_path)
)
eval_result = tfma.load_eval_result(output_path=tfma_eval_result_path)
निष्पक्षता संकेतक प्रस्तुत करें
from tensorflow_model_analysis.addons.fairness.view import widget_view
widget_view.render_fairness_indicator(eval_result=eval_result)
निष्पक्षता संकेतकों का उपयोग करने के लिए युक्तियाँ:
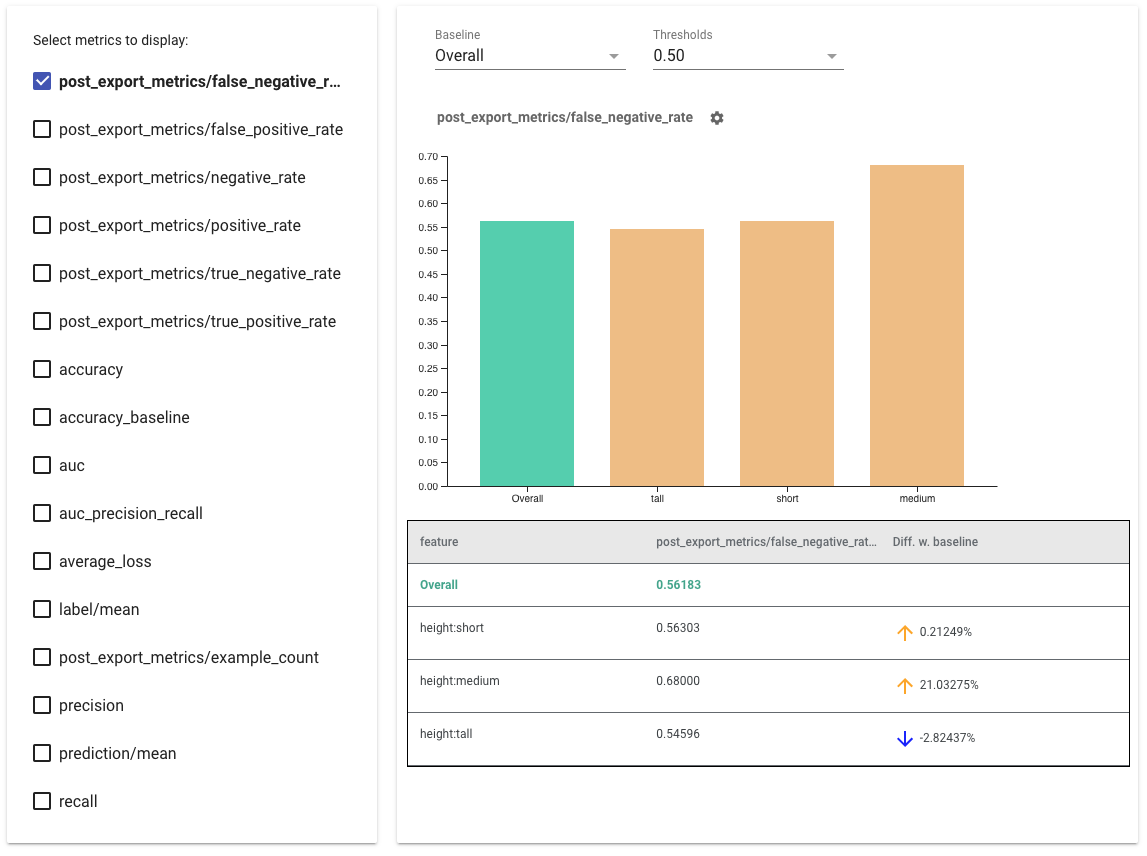
- बाईं ओर के बक्सों को चेक करके प्रदर्शित करने के लिए मेट्रिक्स का चयन करें । प्रत्येक मेट्रिक्स के लिए अलग-अलग ग्राफ़ क्रम में विजेट में दिखाई देंगे।
- ड्रॉपडाउन चयनकर्ता का उपयोग करके बेसलाइन स्लाइस, ग्राफ़ पर पहली बार बदलें । डेल्टा की गणना इस आधारभूत मान से की जाएगी।
- ड्रॉपडाउन चयनकर्ता का उपयोग करके सीमाएँ चुनें । आप एक ही ग्राफ़ पर एकाधिक सीमाएँ देख सकते हैं। चयनित थ्रेशोल्ड को बोल्ड कर दिया जाएगा, और आप इसे अन-चयनित करने के लिए बोल्ड किए गए थ्रेशोल्ड पर क्लिक कर सकते हैं।
- उस स्लाइस की मेट्रिक्स देखने के लिए बार पर होवर करें ।
- "डिफ़ डब्ल्यू बेसलाइन" कॉलम का उपयोग करके बेसलाइन के साथ असमानताओं की पहचान करें , जो वर्तमान स्लाइस और बेसलाइन के बीच प्रतिशत अंतर की पहचान करता है।
- व्हाट-इफ़ टूल का उपयोग करके किसी स्लाइस के डेटा बिंदुओं का गहराई से अन्वेषण करें । उदाहरण के लिए यहां देखें.
एकाधिक मॉडलों के लिए निष्पक्षता संकेतक प्रस्तुत करना
निष्पक्षता संकेतक का उपयोग मॉडलों की तुलना करने के लिए भी किया जा सकता है। एकल eval_result में पास होने के बजाय, एक मल्टी_eval_results ऑब्जेक्ट में पास करें, जो एक शब्दकोश है जो दो मॉडल नामों को eval_result ऑब्जेक्ट में मैप करता है।
from tensorflow_model_analysis.addons.fairness.view import widget_view
eval_result1 = tfma.load_eval_result(...)
eval_result2 = tfma.load_eval_result(...)
multi_eval_results = {"MyFirstModel": eval_result1, "MySecondModel": eval_result2}
widget_view.render_fairness_indicator(multi_eval_results=multi_eval_results)
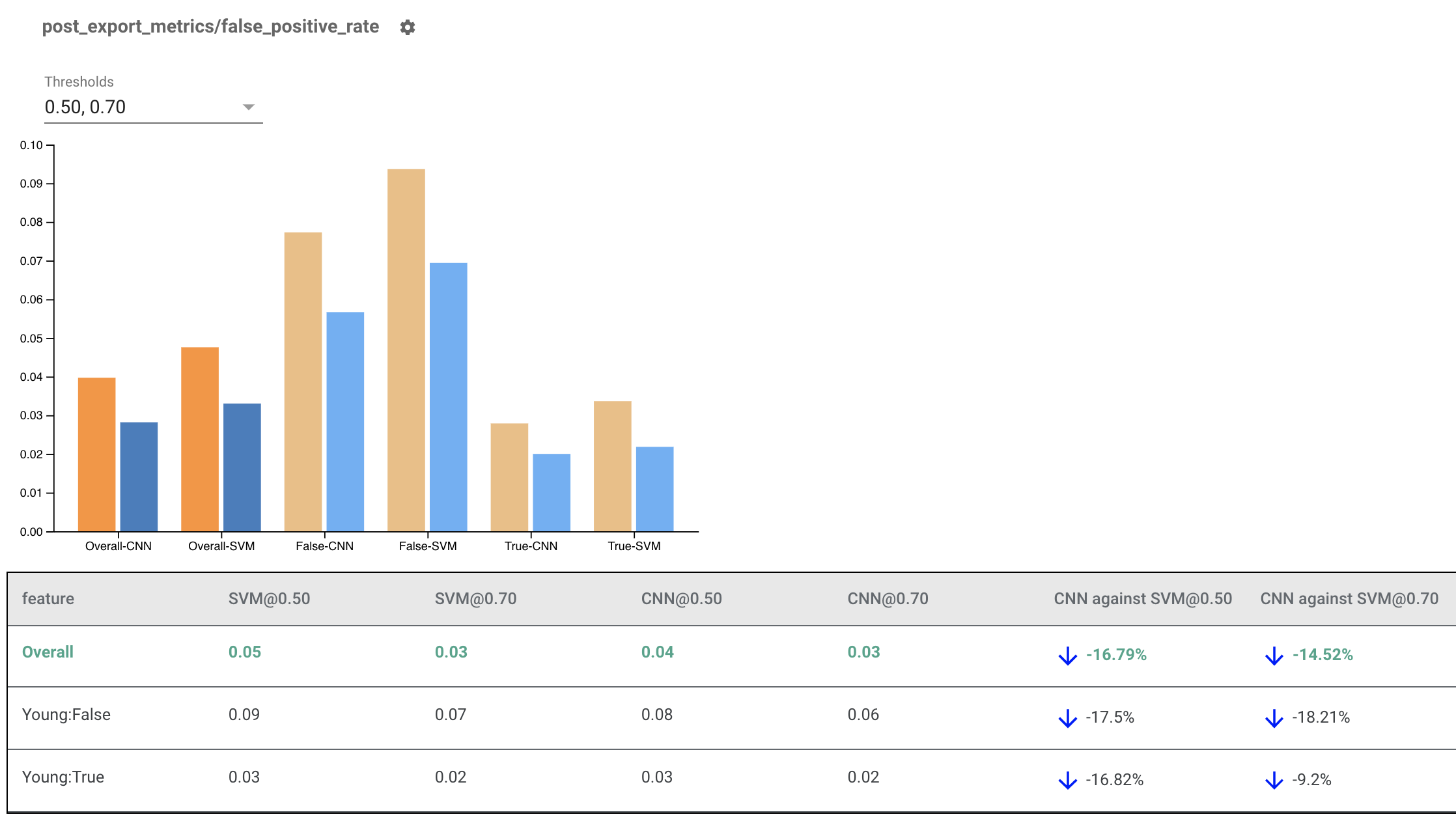
मॉडल तुलना का उपयोग थ्रेशोल्ड तुलना के साथ किया जा सकता है। उदाहरण के लिए, आप अपने निष्पक्षता मेट्रिक्स के लिए इष्टतम संयोजन खोजने के लिए थ्रेशोल्ड के दो सेटों पर दो मॉडलों की तुलना कर सकते हैं।
गैर-टेंसरफ्लो मॉडल के साथ निष्पक्षता संकेतक का उपयोग करना
विभिन्न मॉडल और वर्कफ़्लो वाले ग्राहकों को बेहतर समर्थन देने के लिए, हमने एक मूल्यांकन लाइब्रेरी विकसित की है जो मूल्यांकन किए जा रहे मॉडल के प्रति अज्ञेयवादी है।
जो कोई भी अपने मशीन लर्निंग सिस्टम का मूल्यांकन करना चाहता है, वह इसका उपयोग कर सकता है, खासकर यदि आपके पास गैर-टेन्सरफ्लो आधारित मॉडल हैं। अपाचे बीम पायथन एसडीके का उपयोग करके, आप एक स्टैंडअलोन टीएफएमए मूल्यांकन बाइनरी बना सकते हैं और फिर इसे अपने मॉडल का विश्लेषण करने के लिए चला सकते हैं।
डेटा
यह चरण वह डेटासेट प्रदान करना है जिस पर आप मूल्यांकन चलाना चाहते हैं। यह tf.Example प्रोटो प्रारूप में होना चाहिए जिसमें लेबल, पूर्वानुमान और अन्य सुविधाएं हों जिन्हें आप काटना चाहें।
tf.Example {
features {
feature {
key: "fur_color" value { bytes_list { value: "gray" } }
}
feature {
key: "height" value { bytes_list { value: "tall" } }
}
feature {
key: "prediction" value { float_list { value: 0.9 } }
}
feature {
key: "label" value { float_list { value: 1.0 } }
}
}
}
नमूना
किसी मॉडल को निर्दिष्ट करने के बजाय, आप पार्स करने के लिए एक मॉडल अज्ञेयवादी ईवल कॉन्फ़िगरेशन और एक्सट्रैक्टर बनाते हैं और मेट्रिक्स की गणना करने के लिए TFMA को आवश्यक डेटा प्रदान करते हैं। मॉडलएग्नोस्टिक कॉन्फिग स्पेक इनपुट उदाहरणों से उपयोग की जाने वाली सुविधाओं, भविष्यवाणियों और लेबल को परिभाषित करता है।
इसके लिए, लेबल और पूर्वानुमान कुंजियों और फीचर के डेटा प्रकार का प्रतिनिधित्व करने वाले मानों सहित सभी सुविधाओं का प्रतिनिधित्व करने वाली कुंजियों के साथ एक फीचर मानचित्र बनाएं।
feature_map[label_key] = tf.FixedLenFeature([], tf.float32, default_value=[0])
लेबल कुंजियों, पूर्वानुमान कुंजियों और फ़ीचर मानचित्र का उपयोग करके एक मॉडल अज्ञेयवादी कॉन्फ़िगरेशन बनाएं।
model_agnostic_config = model_agnostic_predict.ModelAgnosticConfig(
label_keys=list(ground_truth_labels),
prediction_keys=list(predition_labels),
feature_spec=feature_map)
मॉडल एग्नोस्टिक एक्सट्रैक्टर स्थापित करें
एक्सट्रैक्टर का उपयोग मॉडल अज्ञेयवादी कॉन्फ़िगरेशन का उपयोग करके इनपुट से सुविधाओं, लेबल और भविष्यवाणियों को निकालने के लिए किया जाता है। और यदि आप अपने डेटा को स्लाइस करना चाहते हैं, तो आपको स्लाइस कुंजी विनिर्देश को भी परिभाषित करने की आवश्यकता है, जिसमें उन कॉलमों के बारे में जानकारी शामिल है जिन पर आप स्लाइस करना चाहते हैं।
model_agnostic_extractors = [
model_agnostic_extractor.ModelAgnosticExtractor(
model_agnostic_config=model_agnostic_config, desired_batch_size=3),
slice_key_extractor.SliceKeyExtractor([
slicer.SingleSliceSpec(),
slicer.SingleSliceSpec(columns=[‘height’]),
])
]
निष्पक्षता मेट्रिक्स की गणना करें
EvalSharedModel के भाग के रूप में, आप वे सभी मीट्रिक प्रदान कर सकते हैं जिनके आधार पर आप अपने मॉडल का मूल्यांकन कराना चाहते हैं। मेट्रिक्स को मेट्रिक्स कॉलबैक के रूप में प्रदान किया जाता है जैसे कि पोस्ट_एक्सपोर्ट_मेट्रिक्स या फेयरनेस_इंडिकेटर्स में परिभाषित किया गया है।
metrics_callbacks.append(
post_export_metrics.fairness_indicators(
thresholds=[0.5, 0.9],
target_prediction_keys=[prediction_key],
labels_key=label_key))
यह एक construct_fn भी लेता है जिसका उपयोग मूल्यांकन करने के लिए टेंसरफ़्लो ग्राफ़ बनाने के लिए किया जाता है।
eval_shared_model = types.EvalSharedModel(
add_metrics_callbacks=metrics_callbacks,
construct_fn=model_agnostic_evaluate_graph.make_construct_fn(
add_metrics_callbacks=metrics_callbacks,
fpl_feed_config=model_agnostic_extractor
.ModelAgnosticGetFPLFeedConfig(model_agnostic_config)))
एक बार सब कुछ सेट हो जाने पर, मॉडल का मूल्यांकन करने के लिए model_eval_lib द्वारा प्रदान किए गए ExtractEvaluate या ExtractEvaluateAndWriteResults फ़ंक्शन में से किसी एक का उपयोग करें।
_ = (
examples |
'ExtractEvaluateAndWriteResults' >>
model_eval_lib.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
output_path=output_path,
extractors=model_agnostic_extractors))
eval_result = tensorflow_model_analysis.load_eval_result(output_path=tfma_eval_result_path)
अंत में, ऊपर दिए गए "निष्पक्षता संकेतक प्रस्तुत करें" अनुभाग के निर्देशों का उपयोग करके निष्पक्षता संकेतक प्रस्तुत करें।
और ज्यादा उदाहरण
निष्पक्षता संकेतक उदाहरण निर्देशिका में कई उदाहरण हैं:
- Fairness_Indicator_Example_Colab.ipynb , TensorFlow मॉडल विश्लेषण में फेयरनेस संकेतक का अवलोकन देता है और वास्तविक डेटासेट के साथ इसका उपयोग कैसे करें। यह नोटबुक TensorFlow डेटा वैलिडेशन और व्हाट-इफ़ टूल , TensorFlow मॉडल का विश्लेषण करने के लिए दो टूल, जो निष्पक्षता संकेतक के साथ पैक किए गए हैं, के बारे में भी बताता है।
- Fairness_Indicator_on_TF_Hub.ipynb दर्शाता है कि विभिन्न टेक्स्ट एम्बेडिंग पर प्रशिक्षित मॉडलों की तुलना करने के लिए फेयरनेस संकेतक का उपयोग कैसे करें। यह नोटबुक मॉडल घटकों को प्रकाशित करने, खोजने और पुन: उपयोग करने के लिए TensorFlow हब , TensorFlow की लाइब्रेरी से टेक्स्ट एम्बेडिंग का उपयोग करता है।
- Fairness_Indicator_TensorBoard_Plugin_Example_Colab.ipynb दर्शाता है कि TensorBoard में फेयरनेस संकेतकों को कैसे देखा जाए।