
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি দেখায় কিভাবে WAV ফরম্যাটে অডিও ফাইলগুলিকে প্রিপ্রসেস করতে হয় এবং দশটি ভিন্ন শব্দ শনাক্ত করার জন্য একটি বেসিক স্বয়ংক্রিয় স্পিচ রিকগনিশন (ASR) মডেল তৈরি ও প্রশিক্ষণ দেওয়া হয়। আপনি স্পিচ কমান্ড ডেটাসেটের একটি অংশ ব্যবহার করবেন ( ওয়ার্ডেন, 2018 ), যাতে কমান্ডের ছোট (এক সেকেন্ড বা কম) অডিও ক্লিপ থাকে, যেমন "ডাউন", "গো", "বাম", "না", " ডান", "থামুন", "আপ" এবং "হ্যাঁ"।
রিয়েল-ওয়ার্ল্ড স্পিচ এবং অডিও রিকগনিশন সিস্টেম জটিল। কিন্তু, MNIST ডেটাসেটের সাথে ইমেজ শ্রেণীবিভাগের মতো, এই টিউটোরিয়ালটি আপনাকে জড়িত কৌশলগুলির একটি প্রাথমিক ধারণা দেবে।
সেটআপ
প্রয়োজনীয় মডিউল এবং নির্ভরতা আমদানি করুন। মনে রাখবেন যে আপনি এই টিউটোরিয়ালে ভিজ্যুয়ালাইজেশনের জন্য seaborn ব্যবহার করবেন।
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
মিনি স্পিচ কমান্ড ডেটাসেট আমদানি করুন
ডেটা লোডিংয়ের সাথে সময় বাঁচাতে, আপনি স্পিচ কমান্ড ডেটাসেটের একটি ছোট সংস্করণের সাথে কাজ করবেন। আসল ডেটাসেটে 35টি ভিন্ন শব্দ বলার লোকের WAV (ওয়েভফর্ম) অডিও ফাইল ফরম্যাটে 105,000টিরও বেশি অডিও ফাইল রয়েছে। এই ডেটা Google দ্বারা সংগ্রহ করা হয়েছে এবং একটি CC BY লাইসেন্সের অধীনে প্রকাশিত হয়েছে৷
tf.keras.utils.get_file সহ ছোট স্পিচ কমান্ড ডেটাসেট ধারণকারী mini_speech_commands.zip ফাইলটি ডাউনলোড করুন এবং বের করুন :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
ডেটাসেটের অডিও ক্লিপগুলি প্রতিটি স্পিচ কমান্ডের সাথে সম্পর্কিত আটটি ফোল্ডারে সংরক্ষণ করা হয়: no , yes , down , go , left , up , right এবং stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
filenames নামক একটি তালিকায় অডিও ক্লিপগুলি বের করুন এবং এটিকে এলোমেলো করুন:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
যথাক্রমে 80:10:10 অনুপাত ব্যবহার করে প্রশিক্ষণ, বৈধতা এবং পরীক্ষা সেটে filenames বিভক্ত করুন:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
অডিও ফাইল এবং তাদের লেবেল পড়ুন
এই বিভাগে আপনি তরঙ্গরূপ এবং সংশ্লিষ্ট লেবেলগুলির জন্য ডিকোডেড টেনসর তৈরি করে ডেটাসেটটি প্রিপ্রসেস করবেন। মনে রাখবেন যে:
- প্রতিটি WAV ফাইলে প্রতি সেকেন্ডে নির্দিষ্ট সংখ্যক নমুনা সহ টাইম-সিরিজ ডেটা থাকে।
- প্রতিটি নমুনা সেই নির্দিষ্ট সময়ে অডিও সিগন্যালের প্রশস্ততা উপস্থাপন করে।
- একটি 16-বিট সিস্টেমে, মিনি স্পিচ কমান্ড ডেটাসেটের WAV ফাইলগুলির মতো, প্রশস্ততার মানগুলি -32,768 থেকে 32,767 পর্যন্ত।
- এই ডেটাসেটের নমুনা হার হল 16kHz।
tf.audio.decode_wav দ্বারা প্রত্যাবর্তিত টেনসরের আকৃতি হল [samples, channels] , যেখানে channels মনোর জন্য 1 বা স্টেরিওর জন্য 2 । মিনি স্পিচ কমান্ড ডেটাসেটে শুধুমাত্র মনো রেকর্ডিং থাকে।
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
এখন, একটি ফাংশন সংজ্ঞায়িত করা যাক যা ডেটাসেটের কাঁচা WAV অডিও ফাইলগুলিকে অডিও টেনসরে প্রিপ্রসেস করে:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
একটি ফাংশন সংজ্ঞায়িত করুন যা প্রতিটি ফাইলের জন্য প্যারেন্ট ডিরেক্টরি ব্যবহার করে লেবেল তৈরি করে:
- ফাইলের পাথগুলিকে
tf.RaggedTensors-এ বিভক্ত করুন (র্যাগড ডাইমেনশন সহ টেনসর - যার দৈর্ঘ্য ভিন্ন হতে পারে)।
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
আরেকটি হেল্পার ফাংশন সংজ্ঞায়িত করুন — get_waveform_and_label — যা সব একসাথে রাখে:
- ইনপুট হল WAV অডিও ফাইলের নাম।
- আউটপুট হল একটি টিপল যাতে তত্ত্বাবধানে শেখার জন্য প্রস্তুত অডিও এবং লেবেল টেনসর থাকে।
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
অডিও-লেবেল জোড়া বের করতে প্রশিক্ষণ সেট তৈরি করুন:
- আগে সংজ্ঞায়িত
get_waveform_and_labelব্যবহার করেDataset.from_tensor_slicesএবংDataset.mapসহ একটিtf.data.Datasetতৈরি করুন।
আপনি পরবর্তীতে একই পদ্ধতি ব্যবহার করে বৈধতা এবং পরীক্ষার সেট তৈরি করবেন।
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
আসুন কয়েকটি অডিও ওয়েভফর্ম প্লট করি:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()

তরঙ্গরূপগুলিকে বর্ণালীগ্রামে রূপান্তর করুন
ডেটাসেটের তরঙ্গরূপগুলি সময় ডোমেনে উপস্থাপিত হয়। এর পরে, আপনি ওয়েভফর্মগুলিকে স্পেকট্রোগ্রাম হিসাবে রূপান্তর করতে শর্ট-টাইম ফুরিয়ার ট্রান্সফর্ম (STFT) গণনা করে টাইম-ডোমেন সিগন্যাল থেকে টাইম-ফ্রিকোয়েন্সি-ডোমেন সিগন্যালে রূপান্তর করবেন, যা সময়ের সাথে সাথে ফ্রিকোয়েন্সি পরিবর্তনগুলি দেখায় এবং হতে পারে 2D চিত্র হিসাবে উপস্থাপিত। মডেলটি প্রশিক্ষণের জন্য আপনি আপনার নিউরাল নেটওয়ার্কে স্পেকট্রোগ্রাম চিত্রগুলিকে ফিড করবেন।
একটি ফুরিয়ার ট্রান্সফর্ম ( tf.signal.fft ) একটি সংকেতকে তার উপাদান ফ্রিকোয়েন্সিতে রূপান্তর করে, কিন্তু সর্বকালের তথ্য হারায়। তুলনামূলকভাবে, STFT ( tf.signal.stft ) সিগন্যালকে সময়ের উইন্ডোতে বিভক্ত করে এবং প্রতিটি উইন্ডোতে একটি ফুরিয়ার ট্রান্সফর্ম চালায়, কিছু সময়ের তথ্য সংরক্ষণ করে এবং একটি 2D টেনসর ফেরত দেয় যা আপনি স্ট্যান্ডার্ড কনভল্যুশন চালাতে পারেন।
ওয়েভফর্মকে স্পেকট্রোগ্রামে রূপান্তর করার জন্য একটি ইউটিলিটি ফাংশন তৈরি করুন:
- তরঙ্গরূপগুলি একই দৈর্ঘ্যের হওয়া দরকার, যাতে আপনি যখন সেগুলিকে বর্ণালীগ্রামে রূপান্তর করেন, ফলাফলগুলির একই মাত্রা থাকে। এটি এক সেকেন্ডের চেয়ে ছোট অডিও ক্লিপগুলিকে শূন্য-প্যাডিং করে করা যেতে পারে (
tf.zerosব্যবহার করে)। -
tf.signal.stftকল করার সময়,frame_lengthএবংframe_stepপ্যারামিটারগুলি বেছে নিন যাতে জেনারেট করা স্পেকট্রোগ্রাম "ইমেজ" প্রায় বর্গাকার হয়। STFT প্যারামিটার পছন্দ সম্পর্কে আরও তথ্যের জন্য, অডিও সিগন্যাল প্রসেসিং এবং STFT সম্পর্কিত এই Coursera ভিডিওটি দেখুন। - STFT জটিল সংখ্যার একটি বিন্যাস তৈরি করে যা পরিমাপ এবং পর্বের প্রতিনিধিত্ব করে। যাইহোক, এই টিউটোরিয়ালে আপনি শুধুমাত্র মাত্রা ব্যবহার করবেন, যা আপনি
tf.signal.stftএর আউটপুটেtf.absপ্রয়োগ করে বের করতে পারবেন।
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
এর পরে, ডেটা অন্বেষণ শুরু করুন। একটি উদাহরণের টেনসরাইজড ওয়েভফর্ম এবং সংশ্লিষ্ট স্পেকট্রোগ্রামের আকারগুলি মুদ্রণ করুন এবং মূল অডিওটি চালান:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
এখন, একটি স্পেকট্রোগ্রাম প্রদর্শনের জন্য একটি ফাংশন সংজ্ঞায়িত করুন:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
সময়ের সাথে উদাহরণের তরঙ্গরূপ এবং সংশ্লিষ্ট বর্ণালীগ্রাম (সময়ের সাথে ফ্রিকোয়েন্সি) প্লট করুন:
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()

এখন, একটি ফাংশন সংজ্ঞায়িত করুন যা ওয়েভফর্ম ডেটাসেটকে স্পেকট্রোগ্রাম এবং তাদের সংশ্লিষ্ট লেবেলগুলিকে পূর্ণসংখ্যা আইডি হিসাবে রূপান্তরিত করে:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
Dataset.map দিয়ে ডেটাসেটের উপাদান জুড়ে get_spectrogram_and_label_id ম্যাপ করুন :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
ডেটাসেটের বিভিন্ন উদাহরণের জন্য স্পেকট্রোগ্রামগুলি পরীক্ষা করুন:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()

মডেল তৈরি এবং প্রশিক্ষণ
যাচাইকরণ এবং পরীক্ষার সেটগুলিতে প্রশিক্ষণ সেট প্রিপ্রসেসিং পুনরাবৃত্তি করুন:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
মডেল প্রশিক্ষণের জন্য ব্যাচ প্রশিক্ষণ এবং বৈধতা সেট:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
মডেল প্রশিক্ষণের সময় পড়ার বিলম্ব কমাতে Dataset.cache এবং Dataset.prefetch অপারেশন যোগ করুন:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
মডেলটির জন্য, আপনি একটি সাধারণ কনভোলিউশনাল নিউরাল নেটওয়ার্ক (CNN) ব্যবহার করবেন, যেহেতু আপনি অডিও ফাইলগুলিকে স্পেকট্রোগ্রাম ছবিতে রূপান্তরিত করেছেন।
আপনার tf.keras.Sequential মডেল নিম্নলিখিত Keras প্রিপ্রসেসিং স্তরগুলি ব্যবহার করবে:
-
tf.keras.layers.Resizing: মডেলটিকে দ্রুত প্রশিক্ষণের জন্য সক্ষম করার জন্য ইনপুট কমিয়ে আনার জন্য। -
tf.keras.layers.Normalization: চিত্রের প্রতিটি পিক্সেলকে তার গড় এবং আদর্শ বিচ্যুতির উপর ভিত্তি করে স্বাভাবিক করার জন্য।
Normalization স্তরের জন্য, সামগ্রিক পরিসংখ্যান (অর্থাৎ গড় এবং মানক বিচ্যুতি) গণনা করার জন্য এর adapt পদ্ধতিকে প্রথমে প্রশিক্ষণের ডেটাতে কল করতে হবে।
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
অ্যাডাম অপ্টিমাইজার এবং ক্রস-এনট্রপি লস দিয়ে কেরাস মডেল কনফিগার করুন:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
প্রদর্শনের উদ্দেশ্যে মডেলটিকে 10টি যুগের বেশি প্রশিক্ষণ দিন:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
আসুন প্রশিক্ষণের সময় আপনার মডেলটি কীভাবে উন্নত হয়েছে তা পরীক্ষা করতে প্রশিক্ষণ এবং বৈধতা হারানোর বক্ররেখা প্লট করি:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

মডেল কর্মক্ষমতা মূল্যায়ন
পরীক্ষা সেটে মডেলটি চালান এবং মডেলের কর্মক্ষমতা পরীক্ষা করুন:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
একটি বিভ্রান্তি ম্যাট্রিক্স প্রদর্শন করুন
পরীক্ষা সেটের প্রতিটি কমান্ডকে মডেলটি কতটা ভালোভাবে শ্রেণীবদ্ধ করেছে তা পরীক্ষা করতে একটি বিভ্রান্তি ম্যাট্রিক্স ব্যবহার করুন:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()

একটি অডিও ফাইলে অনুমান চালান
অবশেষে, "না" বলার একটি ইনপুট অডিও ফাইল ব্যবহার করে মডেলের ভবিষ্যদ্বাণী আউটপুট যাচাই করুন। আপনার মডেল কতটা ভালো কাজ করে?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
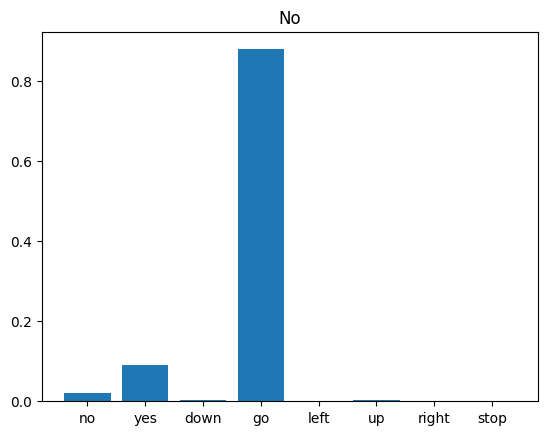
আউটপুট প্রস্তাবিত হিসাবে, আপনার মডেল অডিও কমান্ড "না" হিসাবে স্বীকৃত করা উচিত ছিল.
পরবর্তী পদক্ষেপ
এই টিউটোরিয়ালটি দেখানো হয়েছে কিভাবে TensorFlow এবং Python এর সাথে একটি কনভোল্যুশনাল নিউরাল নেটওয়ার্ক ব্যবহার করে সহজ অডিও শ্রেণীবিভাগ/স্বয়ংক্রিয় স্পিচ রিকগনিশন করা যায়। আরও জানতে, নিম্নলিখিত সংস্থানগুলি বিবেচনা করুন:
- YAMNet টিউটোরিয়াল সহ সাউন্ড ক্লাসিফিকেশন দেখায় কিভাবে অডিও ক্লাসিফিকেশনের জন্য ট্রান্সফার লার্নিং ব্যবহার করতে হয়।
- কাগলের টেনসরফ্লো স্পিচ রিকগনিশন চ্যালেঞ্জের নোটবুক।
- TensorFlow.js - ট্রান্সফার লার্নিং কোডল্যাব ব্যবহার করে অডিও স্বীকৃতি শেখায় কিভাবে অডিও শ্রেণীবিভাগের জন্য আপনার নিজস্ব ইন্টারেক্টিভ ওয়েব অ্যাপ তৈরি করতে হয়।
- arXiv-এ সঙ্গীত তথ্য পুনরুদ্ধারের জন্য গভীর শিক্ষার উপর একটি টিউটোরিয়াল (Choi et al., 2017)।
- আপনার নিজস্ব অডিও-ভিত্তিক প্রকল্পগুলিতে সহায়তা করার জন্য অডিও ডেটা প্রস্তুতি এবং বৃদ্ধির জন্য TensorFlow-এর অতিরিক্ত সমর্থন রয়েছে।
- লাইব্রোসা লাইব্রেরি ব্যবহার করার কথা বিবেচনা করুন - সঙ্গীত এবং অডিও বিশ্লেষণের জন্য একটি পাইথন প্যাকেজ।